
大數軟體有限公司 (LargitData Inc) 是一家提供人工智慧(AI)、輿情大數據(Big Data)在雲平台(Cloud)的AI 與大數據分析公司,主要產品包含:RAGi 企業級AI 決策平台、AIMochi - 會議智慧助理與 InfomIner即時輿情分析分析平台。
Joined December 2021
- Tweets 2,486
- Following 518
- Followers 493
- Likes 20,845
835 Photos and videos






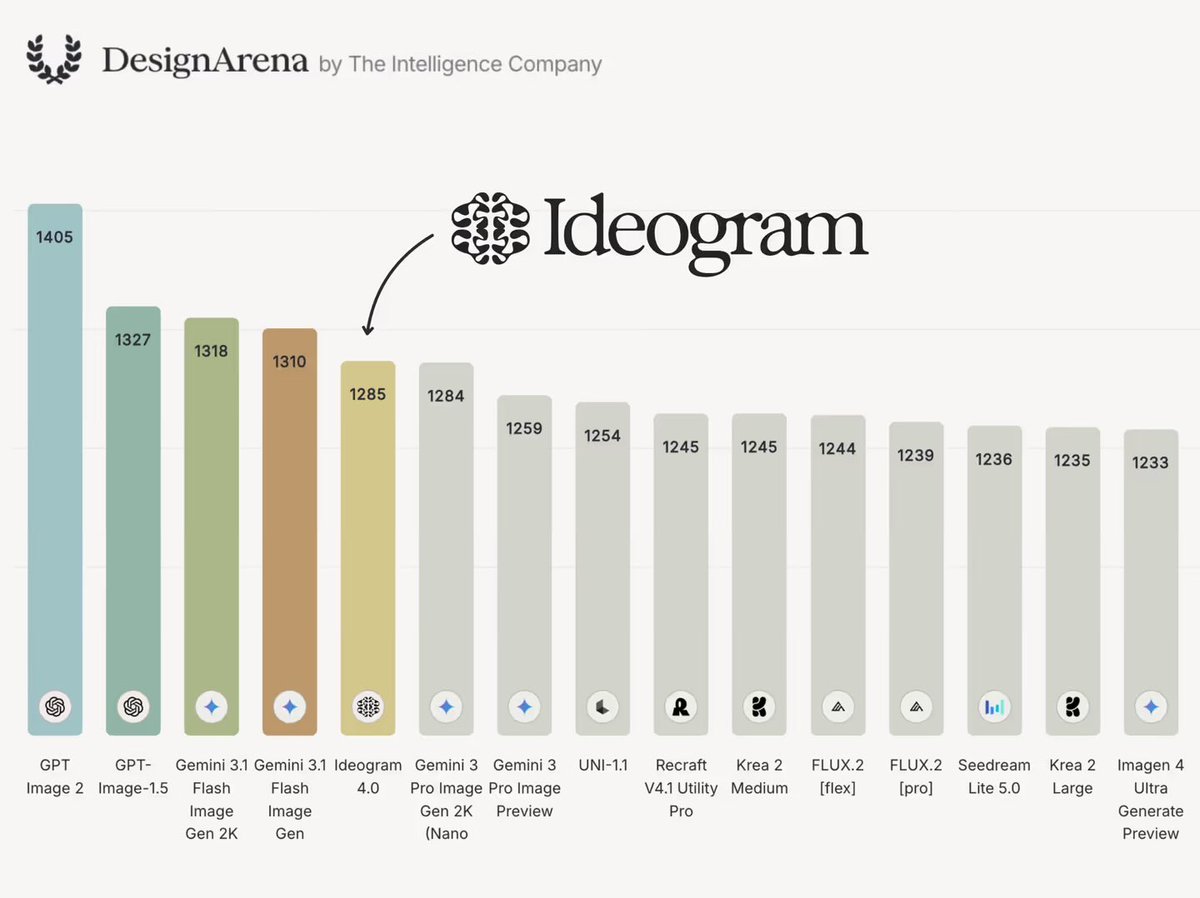


把 Transformer 直接刻進晶片裡?!
gateGPT 這開源專案把 Karpathy 的 nanoGPT 用硬體語言重寫,讓它完全跑在 1 塊 Xilinx Virtex-5 FPGA 上,不靠 CPU 也不靠 GPU,實現每秒 5 到 6 萬的 Token 生成速度。
這顆模型刻意做得很小,只有單層 Transformer,全部都用整數精度,才塞得進有限的硬體資源。作者沒有把所有邏輯寫死成一坨巨大的電路,而是設計了一個像「指令表」的排程器,一步一步指揮各個運算單元輪流工作,大家共用同一塊記憶體當作草稿紙。
一開始的版本每秒只有 2,400 個 Token,作者一路調校到接近 7 萬,整整快了 28 倍,其中最有效的一招是 KV 快取,簡單說就是每生成一個字時,只算新增的部分,不用把前面整段重新算一遍,光這招就快了 3 倍多。
不過也不是一帆風順。在電腦模擬時一切正常,一上真實的板子卻直接當機。追查後發現,是合成工具偷偷把某些資料區塊清成 0,又把一個還在用的暫存器當成沒用的刪掉,這 2 個問題在模擬裡完全看不出來。代表當模擬跑得過時,不見得東西真的會動。
1
33
8

Jun 14
懊悔 Fable 5 沒用兩天就下架了嗎?來看看 Fusion 吧!
Openrouter 推出新服務 Fusion,顧名思義就是把多個模型的輸出融合成單一答案。使用者選定一組參與模型,再指定一個裁判模型負責整合彼此的結果。
團隊採用 Perplexity 設計的 DRACO 深度研究基準評分後顯示:
1. 模型組隊穩定優於單一模型。Fable 5 與 GPT-5.5 融合後拿下69%,超越任何單獨模型,連 Fable 5 單獨的65.3%都被超越。
2. 一組便宜模型(Gemini 3 Flash、Kimi K2.6、DeepSeek V4 Pro)竟然擊敗了 GPT-5.5 與 Opus 4.8,分數逼近 Fable 5 僅差約一個百分點,成本卻只有一半。
更有趣的是自我融合實驗。把 Opus 4.8 與自己組成兩人小組,分數從單模型的58.8%跳升到65.5%,提升6.7個百分點。這說明 Fusion 的增益有相當一部分來自整合這個步驟本身,而非單純混搭不同架構。同一道題跑兩次,會走出不同的推理路徑與工具呼叫,差異本身就是價值。
原來三個臭皮匠還真的能勝過一個諸葛亮!
1
3
535
Jun 13
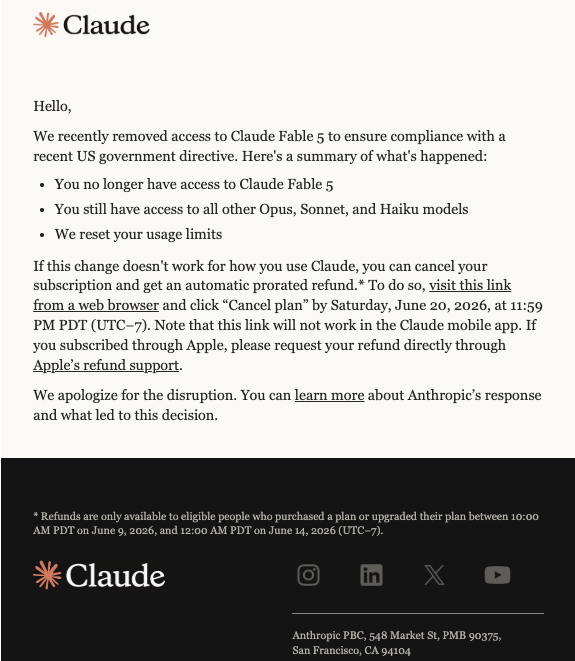
好消息,Anthropic 公布了 Fable 5 被停用的補償方案。
由於 Fable 5 遭停用,Anthropic 提供退費。受影響的訂閱戶,可在台灣時間 2026 年 6 月 21 日(星期日)下午 2:59 前,用網頁瀏覽器登入並點「取消方案」,系統會自動按比例退費。
用 App 訂閱的人比較麻煩,得另外找 Apple 處理。
另外提醒一下,既然是按比例退費,可能不行大燒特燒一波再取消,大家自己拿捏。
1
1
167
Jun 13
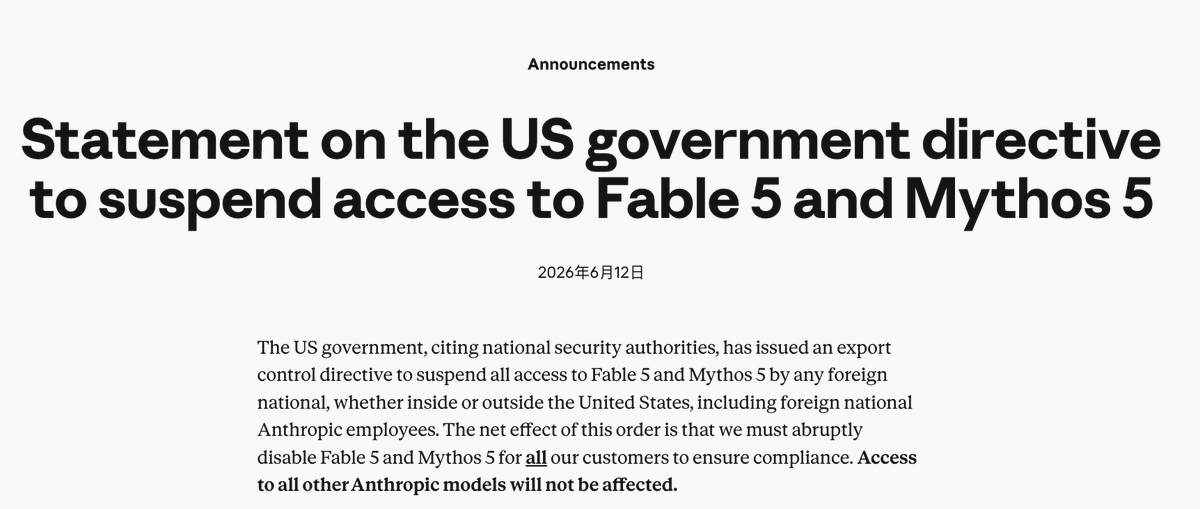
不能用 Fable 5 了?!
美國政府以國家安全為由發出出口管制指令,禁止所有外國人士存取 Fable 5 與 Mythos 5,Anthropic 被迫對全體客戶停用這兩款模型,其餘模型不受影響。
起因據說跟一項繞過 Fable 5 防護的越獄手法有關,不過 Anthropic 反駁那只能找出少數已知的輕微漏洞,其他公開模型沒越獄也做得到同樣的事。
剛剛用的確掰掰... 還沒升級方案的人就別操心了
135
Jun 12
如何讓AI自己做AI研究,但不作弊?
Recursive近日發表了自動化AI研究系統的成果,在固定預算語言模型訓練、小模型訓練速度、GPU kernel優化三項基準上刷新SOTA。
但亮點是他們怎麼面對reward hacking。當你給AI一個分數去優化,它有時不會真的把事情做好,而是鑽評測的漏洞,做出分數很高、卻違背任務本意的解法。三項基準都遇到這個問題,在GPU kernel優化上特別嚴重:有些解法不是真的變快,而是把答案存起來重複使用,或利用計時工具的細節讓自己看起來很快。
解法是把嚴格的自動化檢查內化進迴圈:搜尋變強,評估器就必須跟著變強。換句話說,這是雙迴圈:agent在一側演化,evaluator在另一側跟著演化,兩邊共同升級。
成果有多驚人?在NanoGPT Speedrun這成熟基準上,系統仍然把訓練時間從79.7秒壓到77.5秒。在NanoChat Autoresearch上,系統甚至超越了目前社群最佳解。而在SOL-ExecBench上,系統在235個kernel任務中拿下0.754的平均分數,將與硬體極限的差距縮小了18%。
1
140
Jun 11
一行指令,就能即時取得免費 GPU?!
Google 推出 Colab CLI,包含四大功能:
1. 即時配置GPU:透過一行指令,例如 colab --gpu T4 就可取得免費 GPU
2. 遠端執行:用 colab exec 把本機的 Python 或完整 ML 管線直接丟到 Colab 運行
3. 取回資料:透過 colab download 與 colab log 取回模型、資料集,以及可replay的 ipynb 紀錄
4. 互動存取:用 colab repl 或 colab console 直接進入遠端環境操作
此外 Colab CLI 完整融入標準終端機環境,任何具終端機存取能力的 Agent 都能直接使用。官方還附上一份 skill,讓 Agent 立刻理解如何呼叫這些指令。
官方示範了一個實際案例:用 QLoRA 微調 Gemma 3-1B。開發者只要對 Agent 下一句自然語言指令,Agent 便會自動配置 T4 GPU、安裝套件、遠端執行微調腳本、下載產出的權重,最後關閉環境。將運算全部交給雲端,訓練完還能拉回本機端服務。
1
1
3
167
Jun 10
燒 Token 神器 Fable 5 來了,但真的這麼厲害嗎?
有 Anthropic 工程師分享了在 Loop Engineering 上的實測心得,發現兩個亮點:
1. 自我修正:只要先設好目標或評分標準,在環境裝上回饋機制,它就能自己執行、看回饋、修正,一輪一輪做到達標為止。在機器學習挑戰中, Fable 5 敢大改架構,它甚至願意賭一些一開始會讓分數變差的方向(例如模型量化),但不因短期退步就收手,最後取得重大進展,訓練成效大約是Opus 4.7的六倍。反觀Opus 4.7只敢微調幾個數值,格局小很多。
2. 記憶:Fable 5會把這次學到的東西寫下來,下次再拿出來用,等於把好幾次對話串成一個大迴圈。好的記憶會經過五步:犯錯先記下、追查原因、確認真的是這樣、整理成通則、之後直接查而不用重想一遍。Sonnet 4.6 通常只做到第一步記錄,Opus 4.7會驗證但做得不多,Fable 5則常常五步走完,最強的時候有73%都驗證過,還能把心得整理成通則,讓之後的任務更省力。
所以 Fable 5 不只是更會解題,更會自己累積經驗、自己變強,這是與前幾代模型最關鍵的差異。

6
1,293
什麼是迴圈工程?!
當龍蝦之父 Peter Steinberger 說:別再一個個指令地催你的 coding agent,你該設計一套會自動催它的迴圈。Claude Code 之父 Boris Cherny 不約而同地說,自己早已不親手下指令,而是讓迴圈自動 prompt Claude、判斷下一步,工作變成「寫迴圈」。
迴圈工程的概念於是成形:把親自對 agent 下 Prompt 的那個你換掉,改由系統去做。迴圈是一個遞迴目標,你只要定義目的,由 AI 反覆迭代直到完成。
它由五個零件加一份記憶構成:
1. automation,讓任務按時觸發、自行發掘與分類
2. worktree,使多個代理人平行作業而不互相干擾
3. skills,把專案知識寫在外部,避免代理人每次重新猜測
4. plugins 與 connectors,透過 MCP 串接既有工具與服務
5. sub-agents,讓提出方案者與審查者分離,避免模型替自己的作業打分數。
最後還需要一個外部記憶,例如 markdown,因為模型在每次執行間會遺忘,記憶必須存於磁碟而非上下文之中。
不過作者呼籲,雖然迴圈會改變工作,卻不會替代人的責任。無人看管的迴圈,也會無人看管地犯錯。理解力會在不知不覺間退化,迴圈交付得越快,人與程式碼之間的落差越大。最危險的是放棄判斷、全盤接受迴圈給出的結果。
雖然都跑迴圈,有人用來加速自己理解的工作,有人用來逃避理解。迴圈本身沒有差別,但迴圈製作者的經驗決定了迴圈的品質與效果。
2
1
258
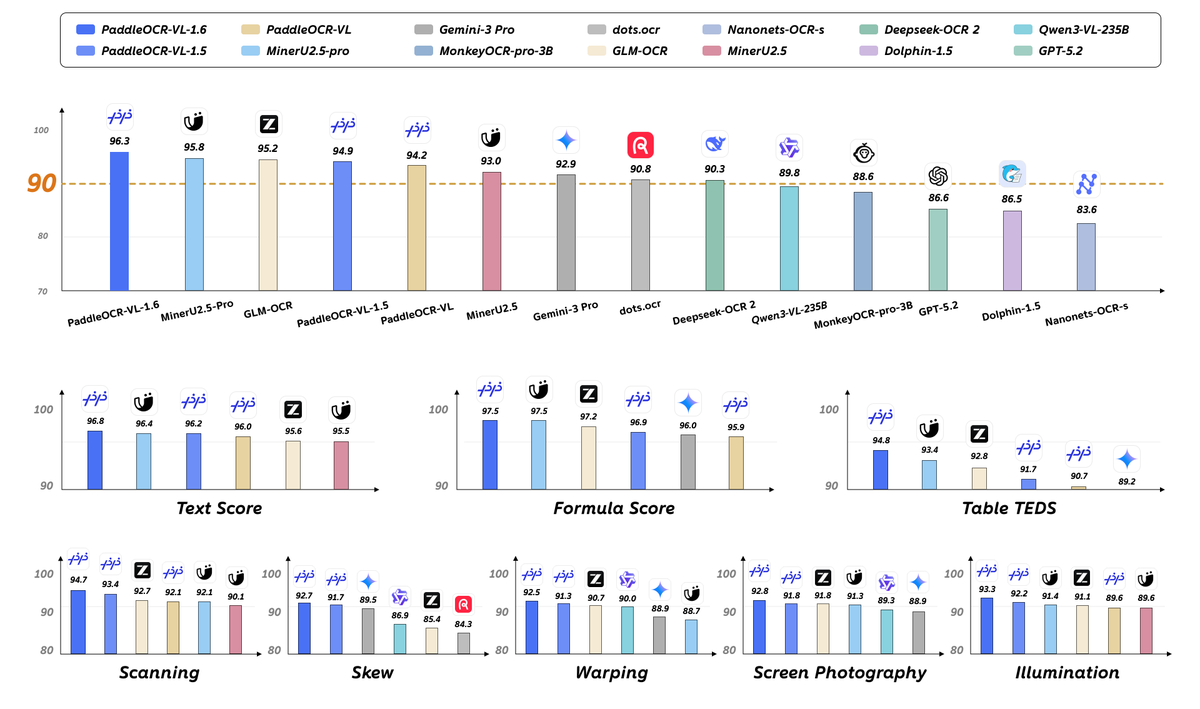
最新最強的 OCR 模型 PaddleOCR-VL-1.6 正式發布!
此次 1.6 版是建立在 1.5 之上的升級版,雖然只有 0.9B 大小,卻在權威評測集 OmniDocBench v1.6 上取得 96.33% 的全新 SOTA,同時刷新 OmniDocBench v1.5 與 Real5-OmniDocBench 紀錄,文本、公式、表格三大任務全面領先開源與閉源方案,表現甚至與 Gemini-3 Pro、Qwen3-VL-235B 等模型相當。
這次升級的關鍵不在模型結構,而在資料與訓練。其一是區域感知的資料優化框架,先從前一代找出表現不足的弱區,再針對這些區域精準補強,並提升監督訊號的可靠度。其二是漸進式後訓練配方,結合精選資料與強化學習,分階段把效能往上推。
能力面上,1.6 在複雜表格、中文古籍、生僻字識別有顯著提升,印章、Spotting、圖表解析等場景也同步增強。最實用的一點是,模型架構與 1.5 完全相容,零成本即換即用,更換權重即可升級,推論速度也不變。
1
113
利用 TurboQuant 縮小 RAG 索引,還能加速搜尋速度?!
原本一千萬筆文件以 float32 儲存要佔 31 GB 記憶體,採用 Google TurboQuant 演算法的 turbovec 只需 4 GB 就能裝下,搜尋還比 FAISS 更快。
原理是參照 TurboQuant 技術先把向量正規化,再乘上隨機正交矩陣旋轉,旋轉後每個座標都服從可預測的分布,於是能事先用 Lloyd-Max 算出最佳分桶並做 bit-packing。1536 維可從 6144 bytes 壓到 384 bytes,達成 16 倍壓縮。
作者手寫了 NEON 與 AVX-512BW 的 SIMD kernel,ARM 上比 FAISS FastScan 快 12 到 20%。
1
1
103
專案位置
github.com/RyanCodrai/turbov…
原始論文
arxiv.org/abs/2504.19874
徵 AI 自動化資料工程實習生中
104.com.tw/job/91usj
21
Google 釋出了更省記憶體的 Gemma 4 QAT 權重!
QAT(量化感知訓練)在訓練階段就模擬量化過程,把模型壓到 4-bit 時能把品質損失降到最低。官方主打讓 Gemma 4 能用在手機與消費級顯卡,最小的 E2B 記憶體甚至壓到 1GB 以下。
那跑起來如何?我們在 H200 上拿 FP8 加 MTP、純 QAT W4A16、以及 QAT 搭配 QAT MTP 做測試:
記憶體差距相當明顯,FP8 加 MTP 載入模型要 32.59 GiB,換成 QAT 後載入只要約 20 GiB,32K 長度的併發能力也從 1.52 倍提升到 2.74 倍。
速度則要看有沒有開 MTP。純 QAT 256 prompt 單併發只剩 70.8 tok/s,但加上 QAT 的 MTP assistant 後,decode 速度就接近 FP8 加 MTP 的水準,2048 單併發甚至來到 184 tok/s。測試期間 draft acceptance 多次落在 91.8% 到 100%,代表搭配相當穩定。
所以想在地端部署服務的朋友們,記得 QAT 要搭配 MTP,才能又省又快!
1
2
188
原始文章
blog.google/innovation-and-a…
模型位置
huggingface.co/collections/g…
徵 AI 自動化資料工程實習生中
104.com.tw/job/91usj
36