
Helping you become a great engineer. System design made simple.
Joined April 2024
- Tweets 538
- Following 2
- Followers 10,318
- Likes 886
46 Photos and videos






Level Up Coding retweeted

Jun 12
One of the more interesting case studies I've read recently.
The 76% headline is eye-catching, but the more interesting story is the pattern underneath.
We're getting closer to production systems that can operate, troubleshoot, and heal themselves.
Worth reading in full.
Jun 11

We ran an experiment. We pointed Antimetal at our own production environment, emitting 3,000 error logs a day, with no prior guidance.
It cut our error volume by 76% in a single day.
It found six unique problems, including one we'd misdiagnosed for weeks. It diagnosed and triaged each one, resolved it, and monitored the fix to confirm stability.
Production that runs itself is no longer hypothetical.
antimetal.com/blog/clearing-…
1
5
13
2,752

Jun 10
OAuth 2.0 clearly explained.
Full breakdown (with visuals) here: lucode.co/oauth-lil1nlsm
5
25
14,681
Level Up Coding retweeted
Jun 8
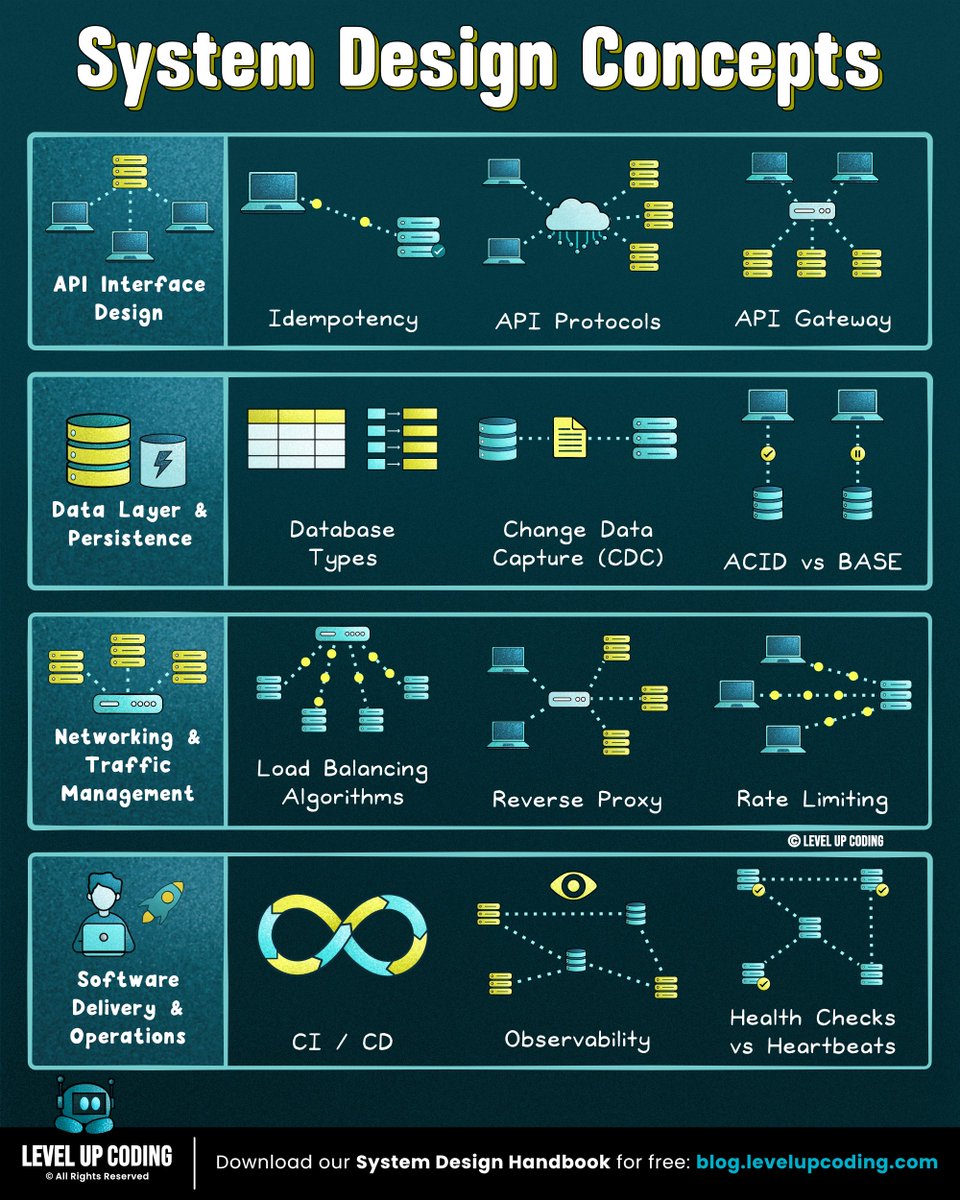
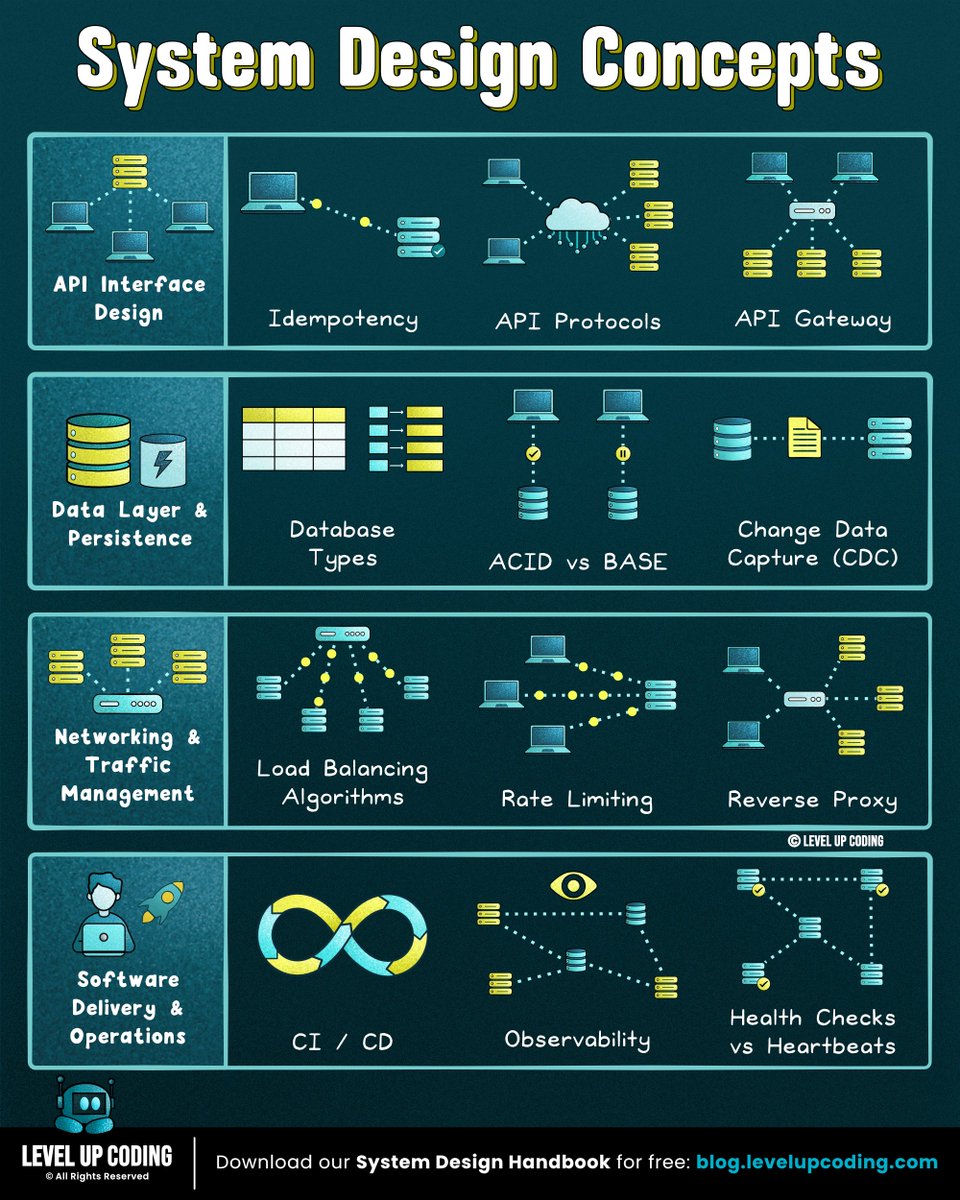
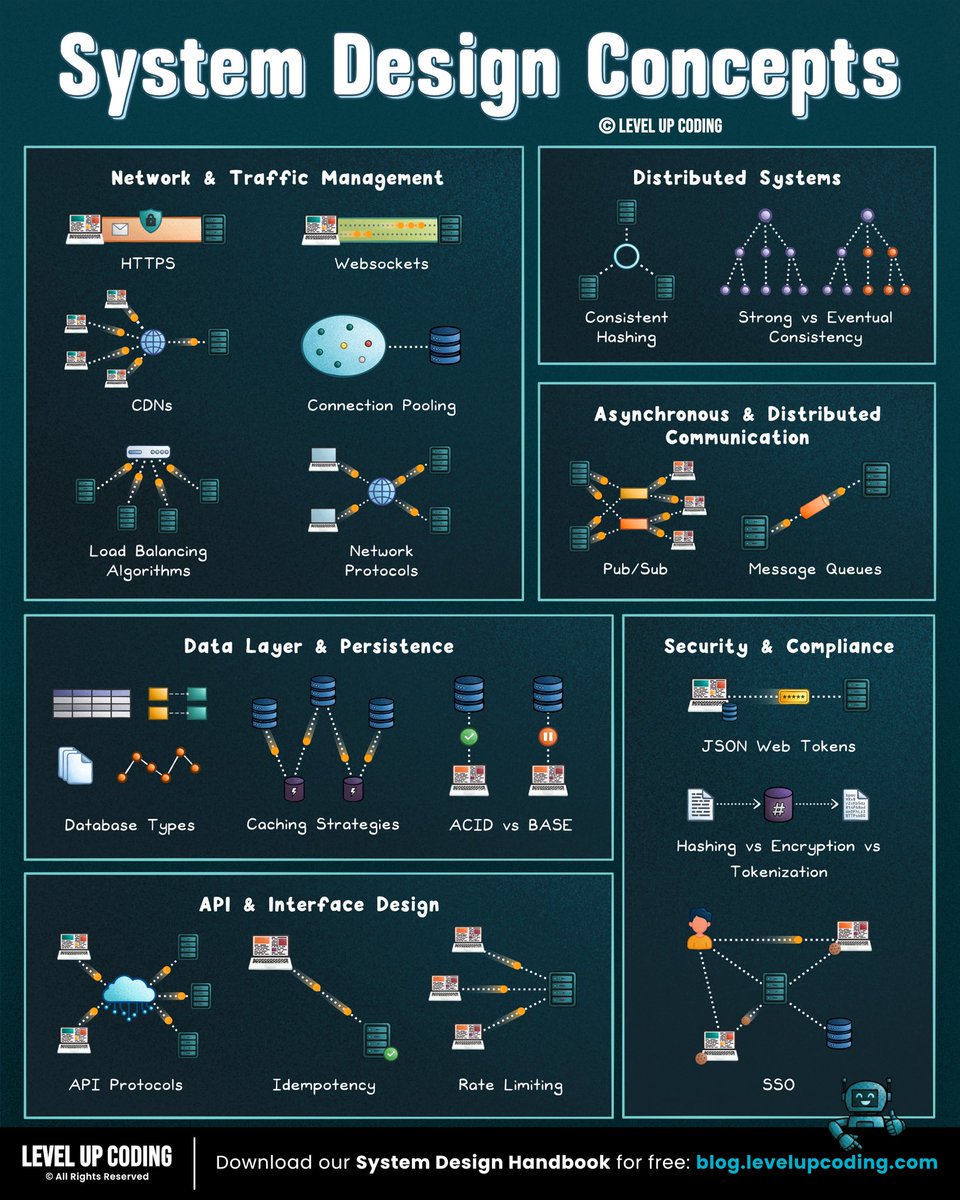
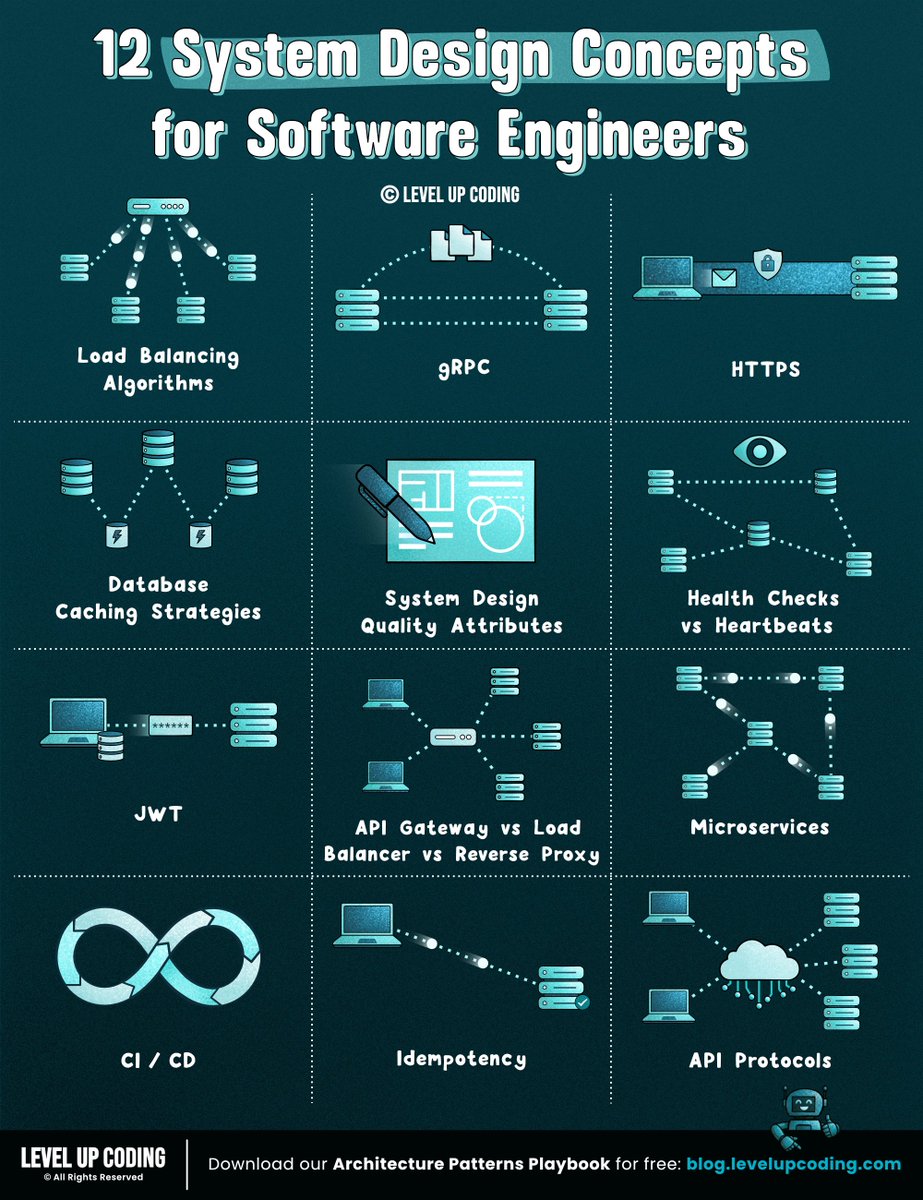
35 system design concepts developers should know:
1. Event-driven architecture
↳ lucode.co/event-driven-archi…
2. Redis
↳ lucode.co/redis-explained-li…
3. gRPC
↳ lucode.co/grpc-explained-lil…
4. Database types
↳ lucode.co/database-types-lil…
5. Circuit breakers
↳ lucode.co/circuit-breakers-l…
6. ACID vs BASE
↳ lucode.co/acid-vs-base-lil1n…
7. Rate limiting
↳ lucode.co/rate-limiting-lil1…
PS - if you want a structured path, get my free 142-page System Design Handbook when you join my free weekly newsletter → lucode.co/system-design-hand…
8. Microservices
↳ lucode.co/microservices-lil1…
9. System design quality attributes
↳ lucode.co/system-design-qual…
10. CAP theorem
↳ lucode.co/cap-theorem-lil1nl…
11. Idempotency
↳ lucode.co/idempotency-in-api…
12. REST APIs
↳ lucode.co/rest-api-protocol-…
13. Sync vs Async
↳ lucode.co/sync-vs-async-lil1…
14. Network protocols
↳ lucode.co/network-protocols-…
15. Change Data Capture (CDC)
↳ lucode.co/change-data-captur…
16. CI/CD pipelines
↳ lucode.co/ci-cd-lil1nlsm
17. SSO (single sign-on)
↳ lucode.co/sso-single-sign-on…
18. JWT
↳ lucode.co/json-web-token-jwt…
19. Health checks vs heartbeats
↳ lucode.co/health-checks-vs-h…
20. API gateway vs load balancer vs reverse proxy
↳ lucode.co/api-gateway-vs-lb-…
21. HTTPS
↳ lucode.co/https-explained-li…
22. Load balancing algorithms
↳ lucode.co/load-balancing-alg…
23. Database caching
↳ lucode.co/database-caching-s…
24. API protocols
↳ lucode.co/api-architecture-s…
25. CDN
↳ lucode.co/cdn-lil1nlsm
26. Database indexing
↳ lucode.co/database-indexing-…
27. Message Queues
↳ lucode.co/message-queues-lil…
28. Hashing vs encryption vs tokenization
↳ lucode.co/hashing-vs-encrypt…
29. Service Discovery
↳ lucode.co/service-discovery-…
30. Pub/Sub
↳ lucode.co/pub-sub-lil1nlsm
31. Connection pooling
↳ lucode.co/connection-pooling…
32. Forward proxy vs reverse proxy
↳ lucode.co/forward-vs-reverse…
33. Consistent hashing
↳ lucode.co/consistent-hashing…
34. SQL vs NoSQL
↳ lucode.co/sql-vs-nosql-lil1n…
35. Observability
↳ lucode.co/observability-clea…
What else should be on the list?
——
🔖 Save for later.
♻️ Repost to help others learn and grow.
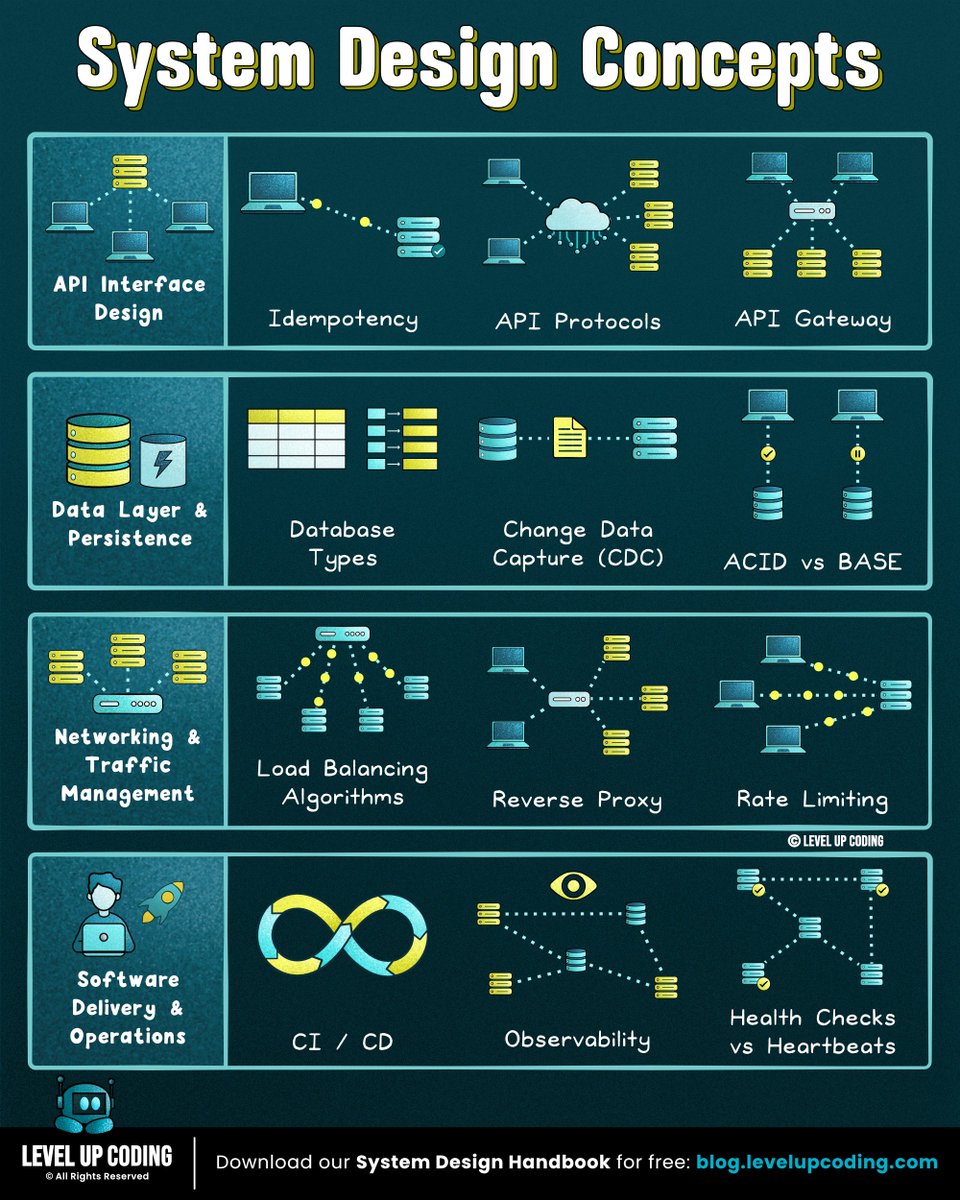

35 system design concepts developers should know:
1) Microservices: lucode.co/microservices-lil1…
2) System design quality attributes: lucode.co/system-design-qual…
3) Observability: lucode.co/observability-clea…
4) CAP theorem: lucode.co/cap-theorem-lil1nl…
5) Idempotency: lucode.co/idempotency-in-api…
6) REST APIs: lnkd.in/gi5zd2jR
7) Sync vs Async: lnkd.in/gG-EnbA9
8) Event-driven architecture: lucode.co/event-driven-archi…
9) Redis: lucode.co/redis-explained-li…
10) gRPC: lucode.co/grpc-explained-lil…
11) Database types: lucode.co/database-types-lil…
12) Circuit breakers: lucode.co/circuit-breakers-l…
13) ACID vs BASE: lucode.co/acid-vs-base-lil1n…
14) Rate limiting: lucode.co/rate-limiting-lil1…
15) Network protocols: lucode.co/network-protocols-…
16) Change Data Capture (CDC): lucode.co/change-data-captur…
17) CI/CD pipelines: lucode.co/ci-cd-lil1nlsm
18) SSO (single sign-on): lnkd.in/gXdVyqBg
19) JWT: lucode.co/json-web-token-jwt…
20) Health checks vs heartbeats: lucode.co/health-checks-vs-h…
21) API gateway vs load balancer vs reverse proxy: lucode.co/api-gateway-vs-lb-…
22) HTTPS: lucode.co/https-explained-li…
23) Load balancing algorithms: lucode.co/load-balancing-alg…
24) Database caching: lucode.co/database-caching-s…
25) API protocols: lucode.co/api-architecture-s…
26) CDN: lucode.co/cdn-lil1nlsm
27) Database indexing: lucode.co/database-indexing-…
28) Message Queues: lucode.co/message-queues-lil…
29) Hashing vs encryption vs tokenization: lnkd.in/gfqGYQnq
30) Service Discovery: lucode.co/service-discovery-…
31) Pub/Sub: lucode.co/pub-sub-lil1nlsm
32) Connection pooling: lucode.co/connection-pooling…
33) Forward proxy vs reverse proxy: lucode.co/forward-vs-reverse…
34) SQL vs NoSQL:lucode.co/sql-vs-nosql-lil1n…
35) Consistent hashing: lucode.co/consistent-hashing…
What else should be on the list?
🔖 Save for later.
♻️ Repost to help others learn and grow.
8
168
752
39,688
35 system design concepts developers should know:
1) Microservices: lucode.co/microservices-lil1…
2) System design quality attributes: lucode.co/system-design-qual…
3) Observability: lucode.co/observability-clea…
4) CAP theorem: lucode.co/cap-theorem-lil1nl…
5) Idempotency: lucode.co/idempotency-in-api…
6) REST APIs: lnkd.in/gi5zd2jR
7) Sync vs Async: lnkd.in/gG-EnbA9
8) Event-driven architecture: lucode.co/event-driven-archi…
9) Redis: lucode.co/redis-explained-li…
10) gRPC: lucode.co/grpc-explained-lil…
11) Database types: lucode.co/database-types-lil…
12) Circuit breakers: lucode.co/circuit-breakers-l…
13) ACID vs BASE: lucode.co/acid-vs-base-lil1n…
14) Rate limiting: lucode.co/rate-limiting-lil1…
15) Network protocols: lucode.co/network-protocols-…
16) Change Data Capture (CDC): lucode.co/change-data-captur…
17) CI/CD pipelines: lucode.co/ci-cd-lil1nlsm
18) SSO (single sign-on): lnkd.in/gXdVyqBg
19) JWT: lucode.co/json-web-token-jwt…
20) Health checks vs heartbeats: lucode.co/health-checks-vs-h…
21) API gateway vs load balancer vs reverse proxy: lucode.co/api-gateway-vs-lb-…
22) HTTPS: lucode.co/https-explained-li…
23) Load balancing algorithms: lucode.co/load-balancing-alg…
24) Database caching: lucode.co/database-caching-s…
25) API protocols: lucode.co/api-architecture-s…
26) CDN: lucode.co/cdn-lil1nlsm
27) Database indexing: lucode.co/database-indexing-…
28) Message Queues: lucode.co/message-queues-lil…
29) Hashing vs encryption vs tokenization: lnkd.in/gfqGYQnq
30) Service Discovery: lucode.co/service-discovery-…
31) Pub/Sub: lucode.co/pub-sub-lil1nlsm
32) Connection pooling: lucode.co/connection-pooling…
33) Forward proxy vs reverse proxy: lucode.co/forward-vs-reverse…
34) SQL vs NoSQL:lucode.co/sql-vs-nosql-lil1n…
35) Consistent hashing: lucode.co/consistent-hashing…
What else should be on the list?
🔖 Save for later.
♻️ Repost to help others learn and grow.
6
55
222
48,119
Level Up Coding retweeted
Jun 5
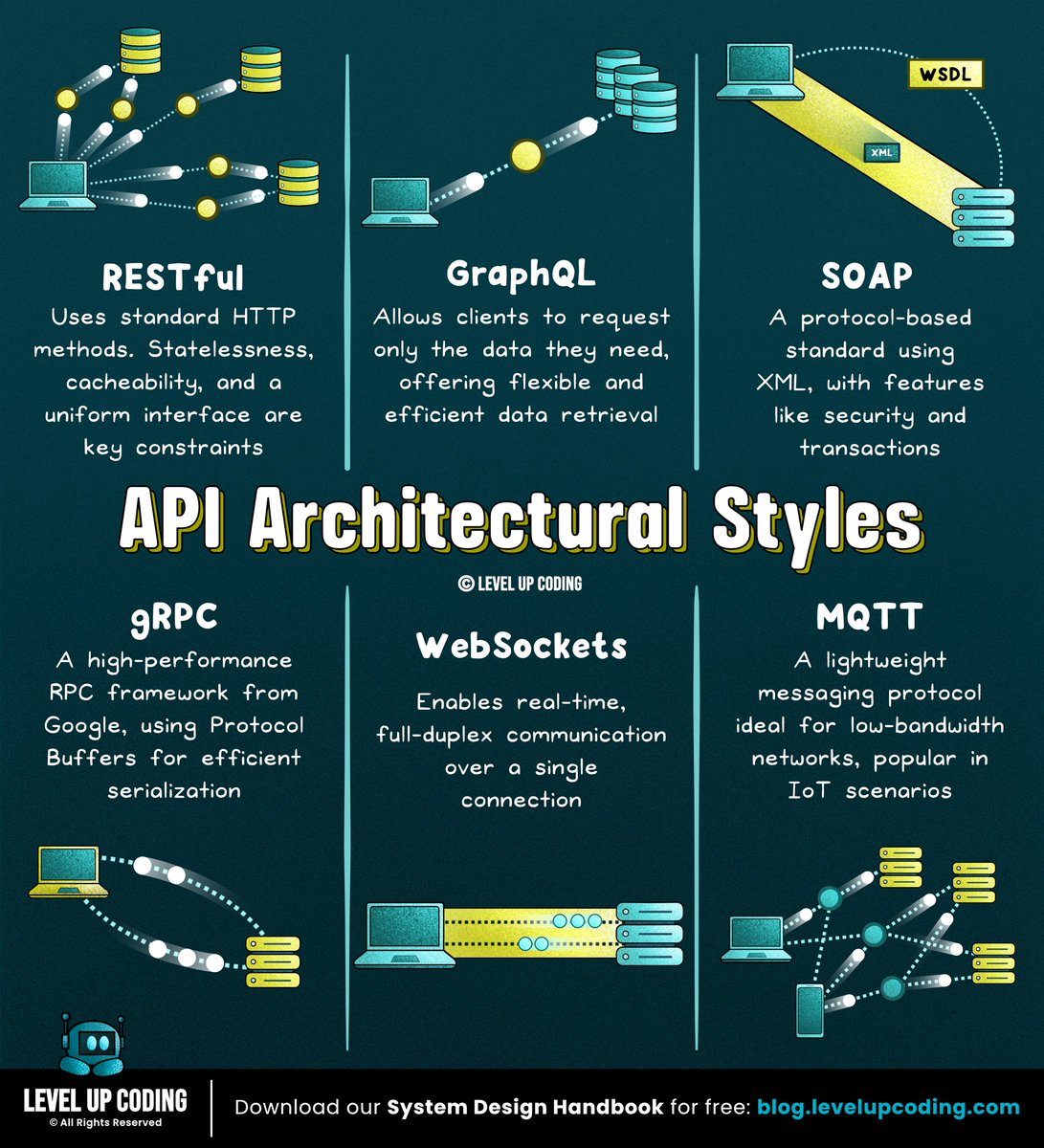
6 API architecture styles every developer should know:
1. REST
↳ lucode.co/rest-api-protocol-…
2. gRPC
↳ lucode.co/grpc-api-protocol-…
3. WebSockets
↳ lucode.co/websockets-api-pro…
4. GraphQL
↳ lucode.co/rest-vs-graphql-vs…
5. SOAP
↳ lucode.co/soap-api-protocol-…
6. MQTT
↳ lucode.co/soap-api-protocol-…
What else would you add?
👋 PS: Want to improve at system design? Download my free System Design Handbook and join 34,000 engineers who get my free weekly newsletter → lucode.co/system-design-hand…
🔖 Save for later
♻️ Repost to help others learn system APIs.
➕ Follow me ( Nikki Siapno ) turn on notifications.

9
116
592
26,682
6 API Architecture Styles Developers Should Know
3
9
41
29,605
9 Database Types Developers Should Know
May 29

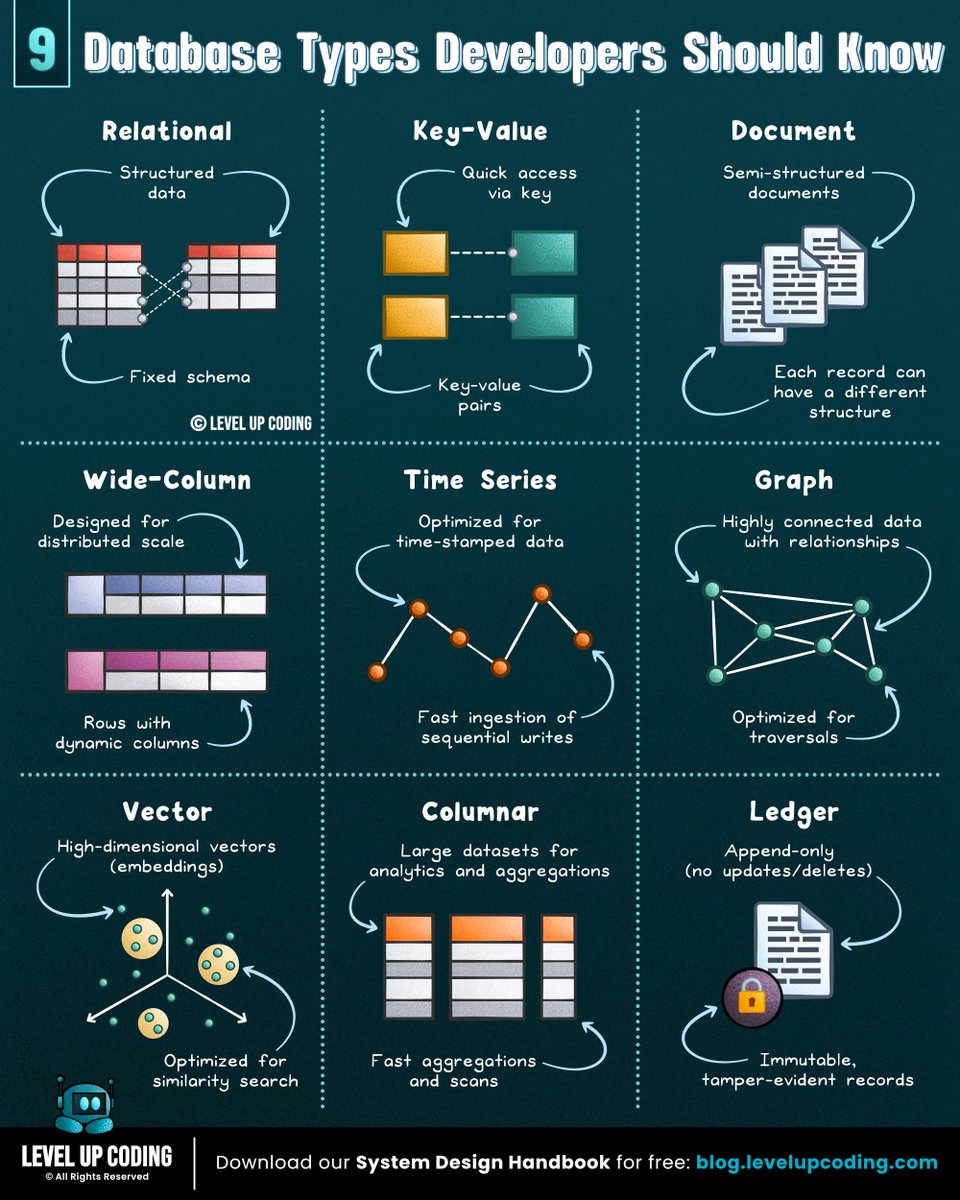
9 database types explained in one sentence:
1) 𝗥𝗲𝗹𝗮𝘁𝗶𝗼𝗻𝗮𝗹
↳ Stores structured data in tables with predefined schemas & SQL queries.
2) 𝗞𝗲𝘆-𝗩𝗮𝗹𝘂𝗲
↳ Stores simple key-value pairs for ultra-fast lookups & caching.
3) 𝗗𝗼𝗰𝘂𝗺𝗲𝗻𝘁
↳ Stores data as JSON-like documents with flexible, nested structures.
4) 𝗪𝗶𝗱𝗲-𝗖𝗼𝗹𝘂𝗺𝗻
↳ Stores data in flexible column families for large-scale distributed workloads.
5) 𝗧𝗶𝗺𝗲-𝗦𝗲𝗿𝗶𝗲𝘀
↳ Stores time-stamped data for real-time metrics, logs, events, & telemetry.
6) 𝗚𝗿𝗮𝗽𝗵
↳ Stores relationships between entities to query connected data efficiently.
7) 𝗩𝗲𝗰𝘁𝗼𝗿
↳ Stores embeddings to enable similarity search & AI-powered retrieval.
8) 𝗖𝗼𝗹𝘂𝗺𝗻𝗮𝗿
↳ Stores data by columns instead of rows to optimize analytical queries.
9) 𝗦𝗲𝗮𝗿𝗰𝗵
↳ Stores indexed text and structured data to enable fast full-text and relevance-based queries.
Most modern systems use several of these together.
As systems become more real-time and AI-driven, the need for time-series infrastructure has grown significantly.
I like using TimescaleDB by Tiger Data because it keeps the simplicity of Postgres while making it much easier to work with large volumes of time-series and real-time data.
Try Tiger Data free with my link below. You'll get a $1,000 30-day credit, no credit card required. It takes just a few minutes to get started, and you can use the credit to build and experiment with whatever you want (new accounts only).
Try it here (for free) → lucode.co/postgres-time-seri…
What else would you add?
——
♻️ Repost to help others learn and grow.
🙏 Thanks to @TigerDatabase for sponsoring this post.
➕ Follow me ( Nikki Siapno ) turn on notifications.
14
50
5,456
Level Up Coding retweeted
Jun 1
Database types cheat sheet.

May 29
9 database types explained in one sentence:
1) 𝗥𝗲𝗹𝗮𝘁𝗶𝗼𝗻𝗮𝗹
↳ Stores structured data in tables with predefined schemas & SQL queries.
2) 𝗞𝗲𝘆-𝗩𝗮𝗹𝘂𝗲
↳ Stores simple key-value pairs for ultra-fast lookups & caching.
3) 𝗗𝗼𝗰𝘂𝗺𝗲𝗻𝘁
↳ Stores data as JSON-like documents with flexible, nested structures.
4) 𝗪𝗶𝗱𝗲-𝗖𝗼𝗹𝘂𝗺𝗻
↳ Stores data in flexible column families for large-scale distributed workloads.
5) 𝗧𝗶𝗺𝗲-𝗦𝗲𝗿𝗶𝗲𝘀
↳ Stores time-stamped data for real-time metrics, logs, events, & telemetry.
6) 𝗚𝗿𝗮𝗽𝗵
↳ Stores relationships between entities to query connected data efficiently.
7) 𝗩𝗲𝗰𝘁𝗼𝗿
↳ Stores embeddings to enable similarity search & AI-powered retrieval.
8) 𝗖𝗼𝗹𝘂𝗺𝗻𝗮𝗿
↳ Stores data by columns instead of rows to optimize analytical queries.
9) 𝗦𝗲𝗮𝗿𝗰𝗵
↳ Stores indexed text and structured data to enable fast full-text and relevance-based queries.
Most modern systems use several of these together.
As systems become more real-time and AI-driven, the need for time-series infrastructure has grown significantly.
I like using TimescaleDB by Tiger Data because it keeps the simplicity of Postgres while making it much easier to work with large volumes of time-series and real-time data.
Try Tiger Data free with my link below. You'll get a $1,000 30-day credit, no credit card required. It takes just a few minutes to get started, and you can use the credit to build and experiment with whatever you want (new accounts only).
Try it here (for free) → lucode.co/postgres-time-seri…
What else would you add?
——
♻️ Repost to help others learn and grow.
🙏 Thanks to @TigerDatabase for sponsoring this post.
➕ Follow me ( Nikki Siapno ) turn on notifications.
4
14
69
5,765
Level Up Coding retweeted
May 29
9 database types explained in one sentence:
1) 𝗥𝗲𝗹𝗮𝘁𝗶𝗼𝗻𝗮𝗹
↳ Stores structured data in tables with predefined schemas & SQL queries.
2) 𝗞𝗲𝘆-𝗩𝗮𝗹𝘂𝗲
↳ Stores simple key-value pairs for ultra-fast lookups & caching.
3) 𝗗𝗼𝗰𝘂𝗺𝗲𝗻𝘁
↳ Stores data as JSON-like documents with flexible, nested structures.
4) 𝗪𝗶𝗱𝗲-𝗖𝗼𝗹𝘂𝗺𝗻
↳ Stores data in flexible column families for large-scale distributed workloads.
5) 𝗧𝗶𝗺𝗲-𝗦𝗲𝗿𝗶𝗲𝘀
↳ Stores time-stamped data for real-time metrics, logs, events, & telemetry.
6) 𝗚𝗿𝗮𝗽𝗵
↳ Stores relationships between entities to query connected data efficiently.
7) 𝗩𝗲𝗰𝘁𝗼𝗿
↳ Stores embeddings to enable similarity search & AI-powered retrieval.
8) 𝗖𝗼𝗹𝘂𝗺𝗻𝗮𝗿
↳ Stores data by columns instead of rows to optimize analytical queries.
9) 𝗦𝗲𝗮𝗿𝗰𝗵
↳ Stores indexed text and structured data to enable fast full-text and relevance-based queries.
Most modern systems use several of these together.
As systems become more real-time and AI-driven, the need for time-series infrastructure has grown significantly.
I like using TimescaleDB by Tiger Data because it keeps the simplicity of Postgres while making it much easier to work with large volumes of time-series and real-time data.
Try Tiger Data free with my link below. You'll get a $1,000 30-day credit, no credit card required. It takes just a few minutes to get started, and you can use the credit to build and experiment with whatever you want (new accounts only).
Try it here (for free) → lucode.co/postgres-time-seri…
What else would you add?
——
♻️ Repost to help others learn and grow.
🙏 Thanks to @TigerDatabase for sponsoring this post.
➕ Follow me ( Nikki Siapno ) turn on notifications.
5
49
242
19,456
Level Up Coding retweeted
May 29
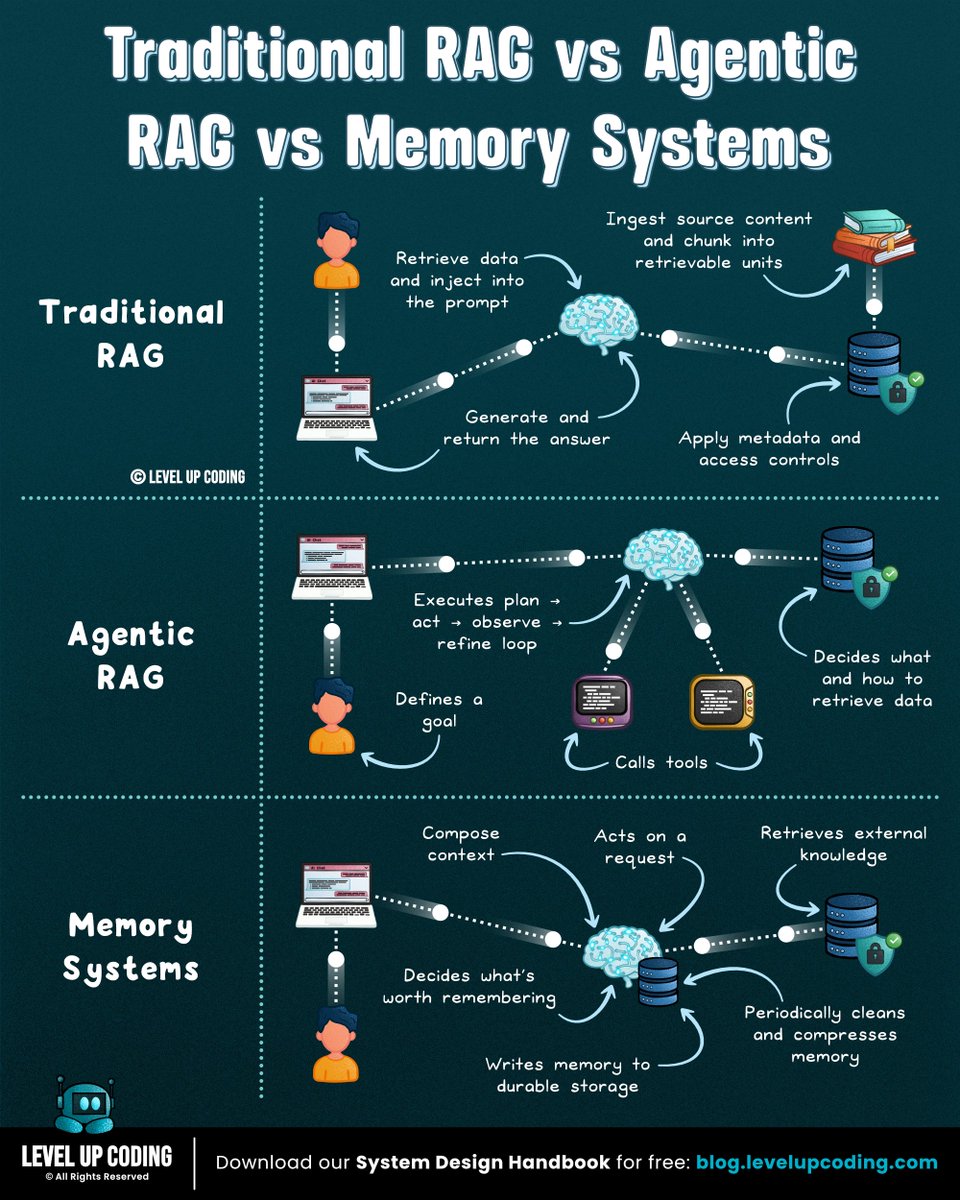
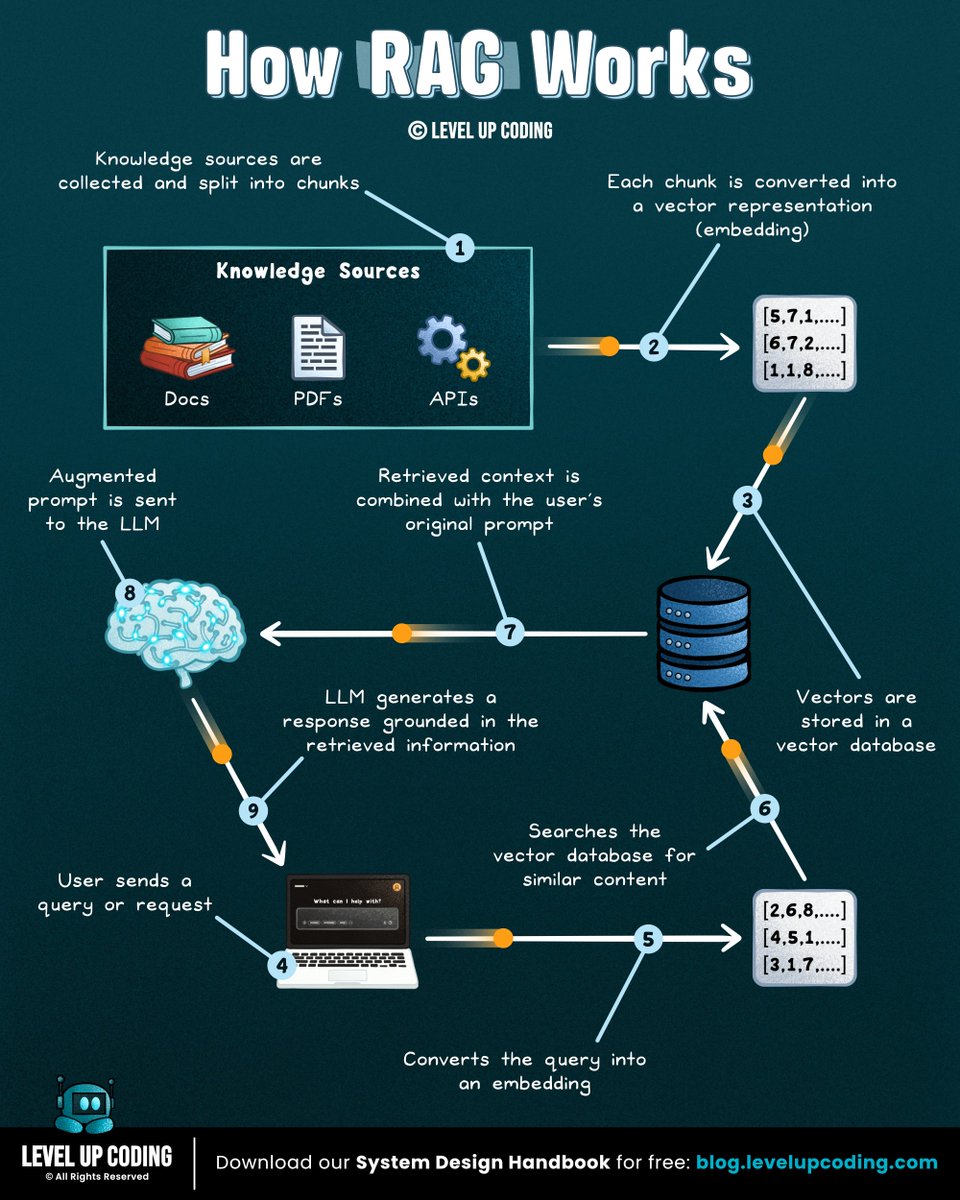
How RAG works.
May 27
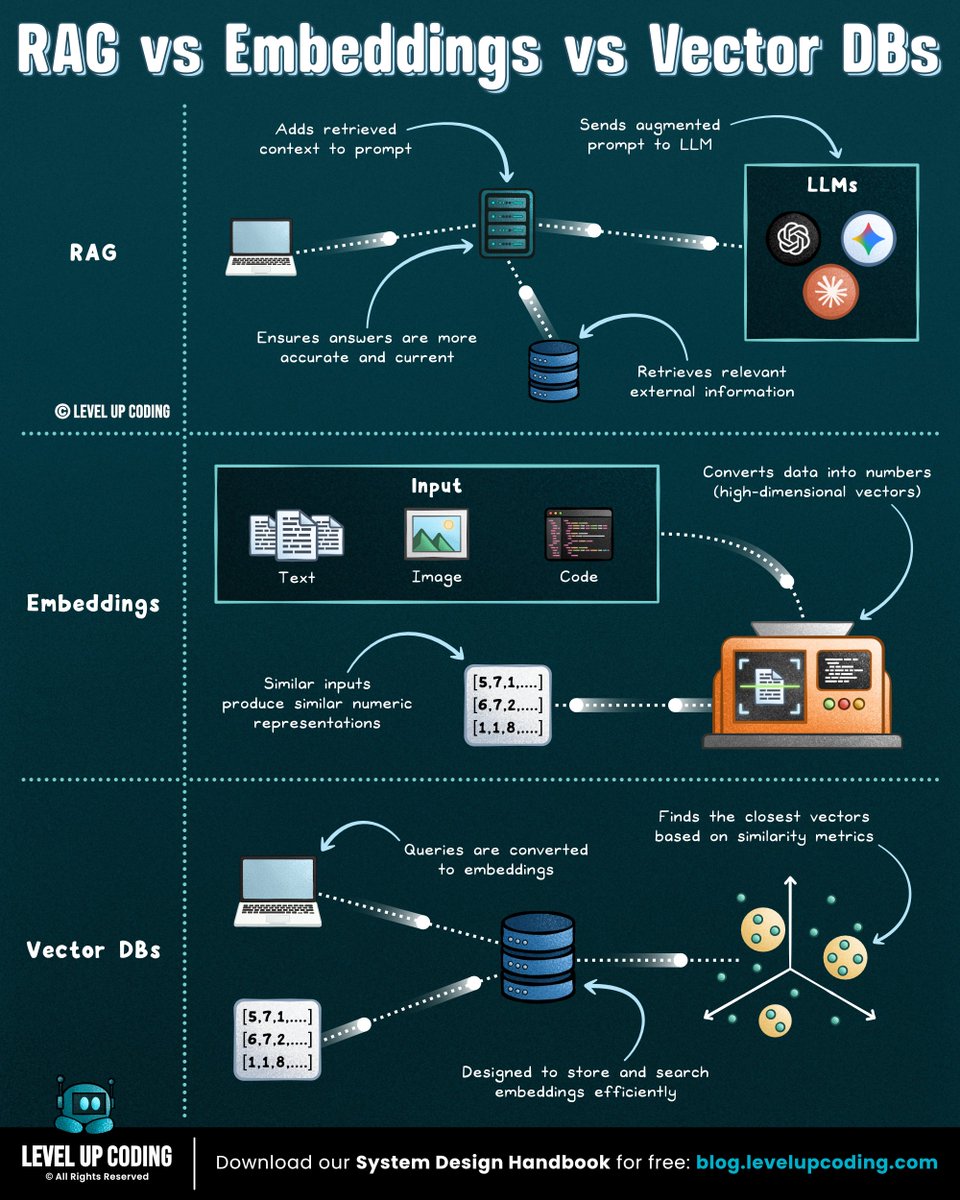
RAG vs Embeddings vs Vector Databases
𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀 turn data into numbers that capture meaning. Similar ideas end up close together, which makes semantic search possible.
𝗩𝗲𝗰𝘁𝗼𝗿 𝗱𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀 store and search embeddings. They help systems find information by meaning, not just exact keywords.
𝗥𝗔𝗚 uses retrieval to improve generation. It finds relevant context, adds it to the prompt, and helps the model answer with external knowledge.
Each one solves different parts of the same problem: helping AI systems use external knowledge.
↳ Without embeddings, the system cannot compare meaning.
↳ Without a vector database, retrieval becomes hard to scale.
↳ Without RAG, retrieval is not integrated into the model’s response.
These same concepts are key foundational building blocks for memory-aware AI agents.
If you're learning agent memory, here's a great breakdown → lucode.co/agent-memory-artic…
And if you want to go deeper into unified memory systems for agents, here's a more advanced deep dive → lucode.co/unified-memory-cor…
What else would you add?
——
♻️ Repost to help others learn and grow.
🙏 Thanks to @OracleDevs for sponsoring this post.
➕ Follow me ( Nikki Siapno ) to improve at AI engineering.
4
40
225
10,043
Level Up Coding retweeted
May 27
RAG vs Embeddings vs Vector Databases
𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀 turn data into numbers that capture meaning. Similar ideas end up close together, which makes semantic search possible.
𝗩𝗲𝗰𝘁𝗼𝗿 𝗱𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀 store and search embeddings. They help systems find information by meaning, not just exact keywords.
𝗥𝗔𝗚 uses retrieval to improve generation. It finds relevant context, adds it to the prompt, and helps the model answer with external knowledge.
Each one solves different parts of the same problem: helping AI systems use external knowledge.
↳ Without embeddings, the system cannot compare meaning.
↳ Without a vector database, retrieval becomes hard to scale.
↳ Without RAG, retrieval is not integrated into the model’s response.
These same concepts are key foundational building blocks for memory-aware AI agents.
If you're learning agent memory, here's a great breakdown → lucode.co/agent-memory-artic…
And if you want to go deeper into unified memory systems for agents, here's a more advanced deep dive → lucode.co/unified-memory-cor…
What else would you add?
——
♻️ Repost to help others learn and grow.
🙏 Thanks to @OracleDevs for sponsoring this post.
➕ Follow me ( Nikki Siapno ) to improve at AI engineering.
8
21
78
14,854
Level Up Coding retweeted
May 26
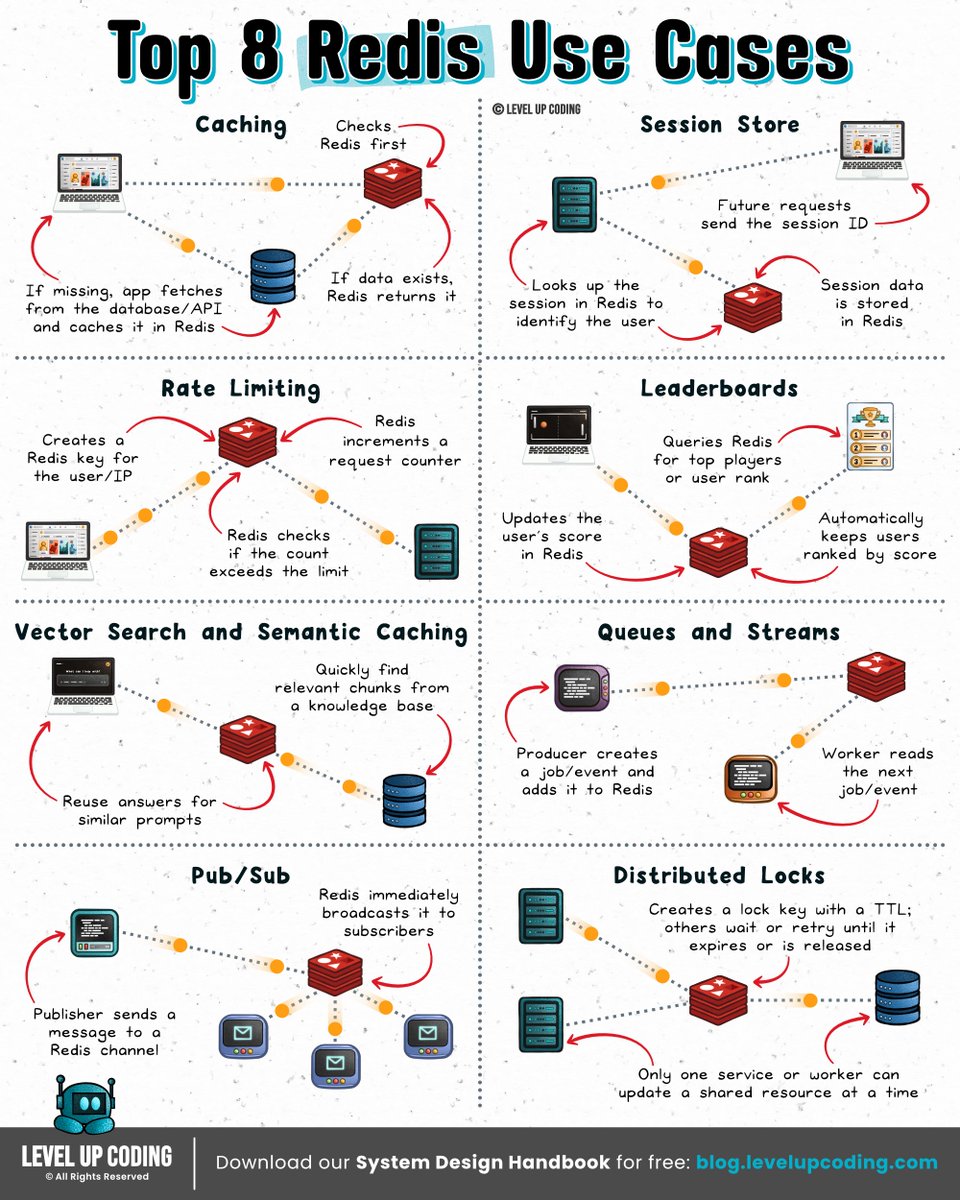
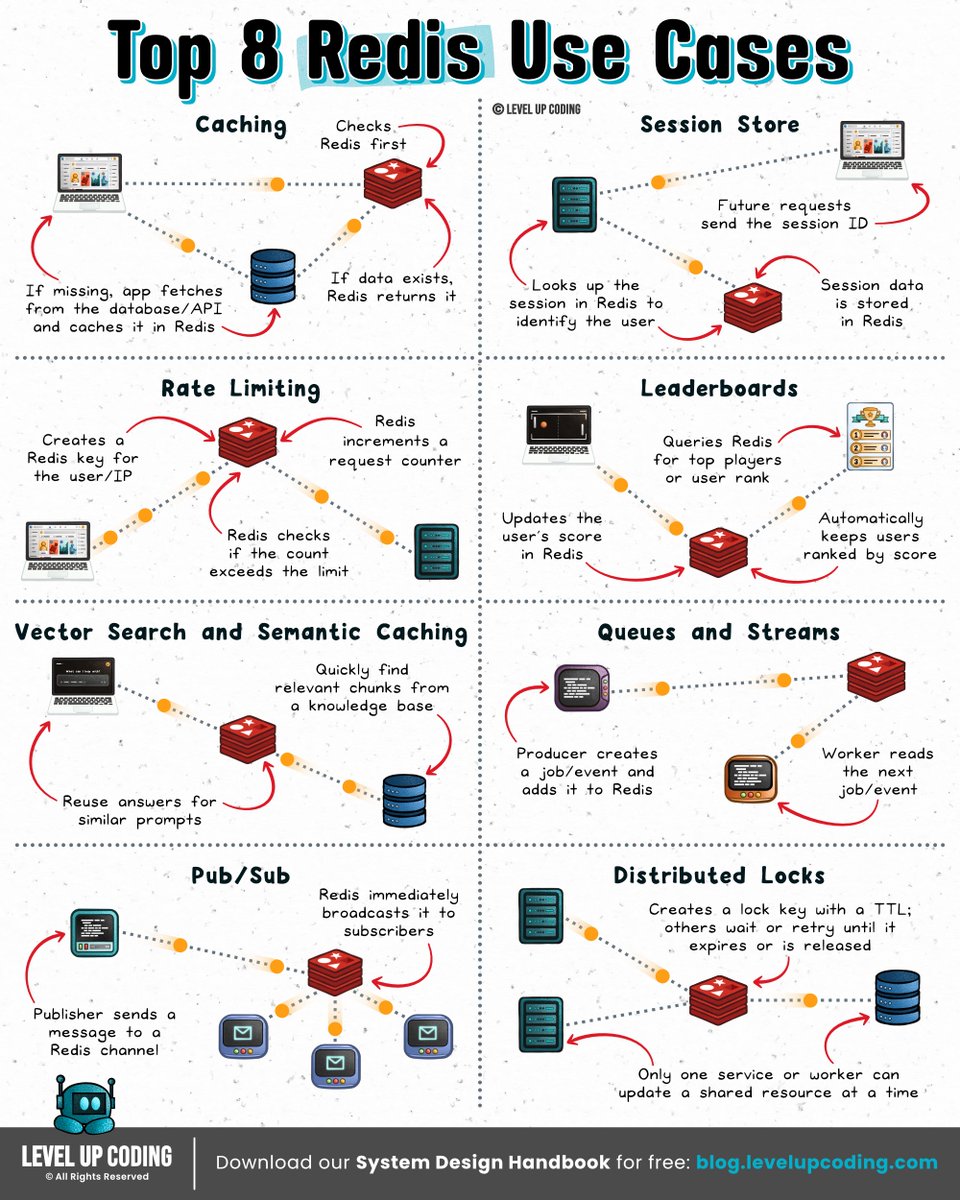
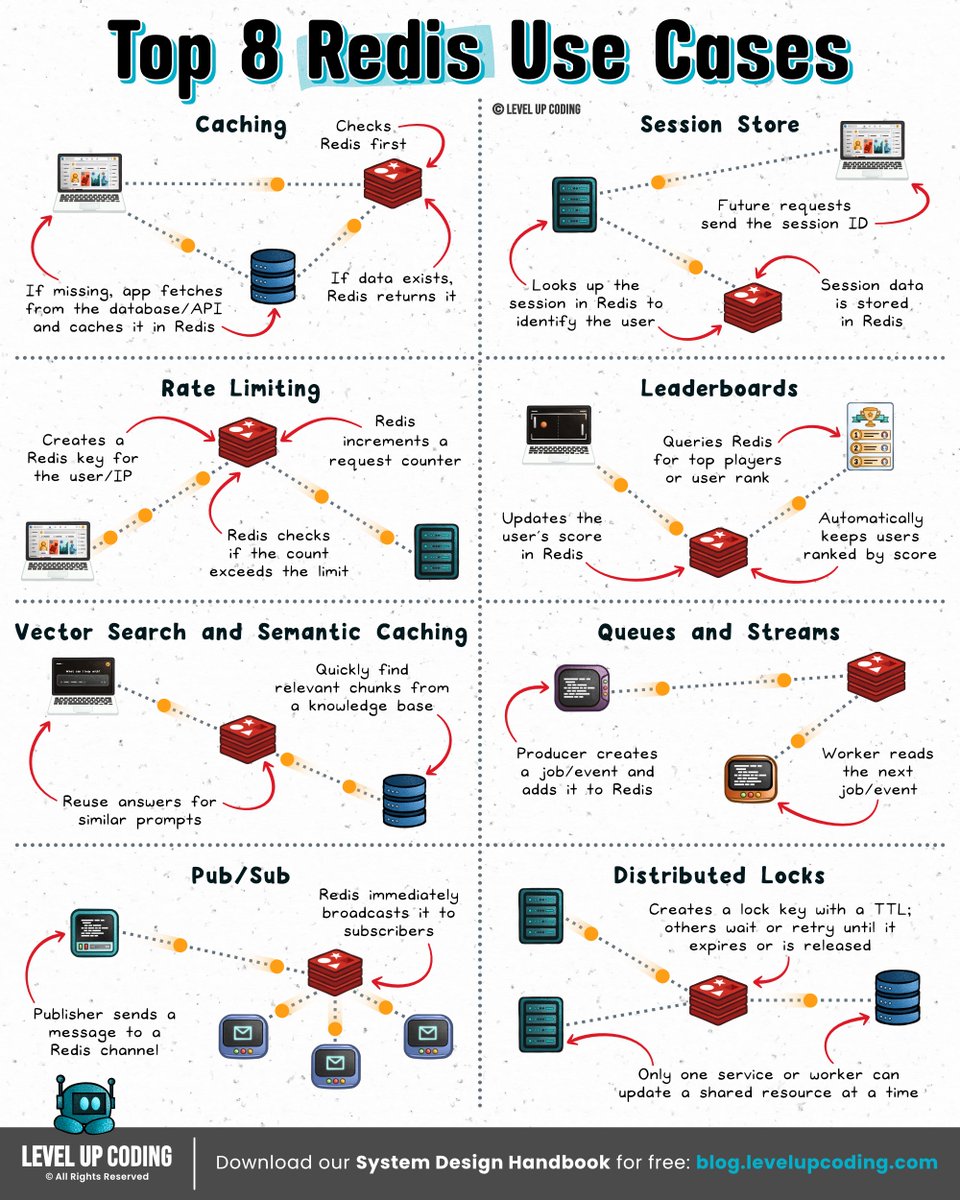
Top 8 Redis Use Cases
May 25
Top 8 Redis Use Cases.
Redis is often introduced as a cache, but real systems use it for much more than speeding up database reads.
That same need for fast, real-time data access is also why Redis is expanding further into AI infrastructure with Redis Iris, a context engine for AI agents that acts as a context and memory retrieval system.
Learn more here → lucode.co/redis-iris-z17xd
1) 𝗖𝗮𝗰𝗵𝗶𝗻𝗴
↳ Store hot data close to the application to reduce database load and latency.
2) 𝗦𝗲𝘀𝘀𝗶𝗼𝗻𝘀
↳ Keep per-user or per-agent state in Redis so application servers can remain stateless.
3) 𝗥𝗮𝘁𝗲 𝗹𝗶𝗺𝗶𝘁𝗶𝗻𝗴
↳ Track request counts across distributed services, API calls, tool usage, and model calls.
4) 𝗟𝗲𝗮𝗱𝗲𝗿𝗯𝗼𝗮𝗿𝗱𝘀
↳ Use sorted sets to maintain live rankings without recomputing results.
5) 𝗩𝗲𝗰𝘁𝗼𝗿 𝘀𝗲𝗮𝗿𝗰𝗵 & 𝘀𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗰𝗮𝗰𝗵𝗶𝗻𝗴
↳ Store embeddings, retrieve semantically similar data, and reuse responses across similar AI queries.
6) 𝗤𝘂𝗲𝘂𝗲𝘀 & 𝗦𝘁𝗿𝗲𝗮𝗺𝘀
↳ Queue work, process events asynchronously, coordinate agent tasks, and track consumer progress.
7) 𝗣𝘂𝗯/𝗦𝘂𝗯
↳ Fan out real-time messages when durability and replay aren’t required.
8) 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗹𝗼𝗰𝗸𝘀
↳ Prevent multiple workers or agents from modifying the same resource at the same time.
Redis has quietly evolved from “just a cache” into infrastructure for real-time coordination, retrieval, streaming, memory, and increasingly AI workloads.
That evolution is reflected in their new context engine launch, focused on delivering live, agent-ready context for AI systems operating across fragmented data sources.
Explore it here → lucode.co/redis-iris-z18xd
What else would you add?
——
♻️ Repost to help others learn and grow.
🙏 Thanks to @Redisinc for sponsoring this post.
➕ Follow me ( Nikki Siapno ) turn on notifications.
3
12
43
5,296
May 26
Top 8 Redis Use Cases:
1) 𝗖𝗮𝗰𝗵𝗶𝗻𝗴
↳ Store hot data close to the application to reduce database load and latency.
2) 𝗦𝗲𝘀𝘀𝗶𝗼𝗻𝘀
↳ Keep per-user or per-agent state in Redis so application servers can remain stateless.
3) 𝗥𝗮𝘁𝗲 𝗹𝗶𝗺𝗶𝘁𝗶𝗻𝗴
↳ Track request counts across distributed services, API calls, tool usage, and model calls.
4) 𝗟𝗲𝗮𝗱𝗲𝗿𝗯𝗼𝗮𝗿𝗱𝘀
↳ Use sorted sets to maintain live rankings without recomputing results.
5) 𝗩𝗲𝗰𝘁𝗼𝗿 𝘀𝗲𝗮𝗿𝗰𝗵 & 𝘀𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗰𝗮𝗰𝗵𝗶𝗻𝗴
↳ Store embeddings, retrieve semantically similar data, and reuse responses across similar AI queries.
6) 𝗤𝘂𝗲𝘂𝗲𝘀 & 𝗦𝘁𝗿𝗲𝗮𝗺𝘀
↳ Queue work, process events asynchronously, coordinate agent tasks, and track consumer progress.
7) 𝗣𝘂𝗯/𝗦𝘂𝗯
↳ Fan out real-time messages when durability and replay aren’t required.
8) 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗹𝗼𝗰𝗸𝘀
↳ Prevent multiple workers or agents from modifying the same resource at the same time.
Redis has quietly evolved from “just a cache” into infrastructure for real-time coordination, retrieval, streaming, memory, and increasingly AI workloads.
That evolution is reflected in their new context engine launch, focused on delivering live, agent-ready context for AI systems operating across fragmented data sources.
Explore it here → lucode.co/redis-iris-z18xd
What else would you add?
♻️ Repost to help others learn and grow.
🙏 Thanks to @Redisinc for sponsoring this post.
May 25
Top 8 Redis Use Cases.
Redis is often introduced as a cache, but real systems use it for much more than speeding up database reads.
That same need for fast, real-time data access is also why Redis is expanding further into AI infrastructure with Redis Iris, a context engine for AI agents that acts as a context and memory retrieval system.
Learn more here → lucode.co/redis-iris-z17xd
1) 𝗖𝗮𝗰𝗵𝗶𝗻𝗴
↳ Store hot data close to the application to reduce database load and latency.
2) 𝗦𝗲𝘀𝘀𝗶𝗼𝗻𝘀
↳ Keep per-user or per-agent state in Redis so application servers can remain stateless.
3) 𝗥𝗮𝘁𝗲 𝗹𝗶𝗺𝗶𝘁𝗶𝗻𝗴
↳ Track request counts across distributed services, API calls, tool usage, and model calls.
4) 𝗟𝗲𝗮𝗱𝗲𝗿𝗯𝗼𝗮𝗿𝗱𝘀
↳ Use sorted sets to maintain live rankings without recomputing results.
5) 𝗩𝗲𝗰𝘁𝗼𝗿 𝘀𝗲𝗮𝗿𝗰𝗵 & 𝘀𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗰𝗮𝗰𝗵𝗶𝗻𝗴
↳ Store embeddings, retrieve semantically similar data, and reuse responses across similar AI queries.
6) 𝗤𝘂𝗲𝘂𝗲𝘀 & 𝗦𝘁𝗿𝗲𝗮𝗺𝘀
↳ Queue work, process events asynchronously, coordinate agent tasks, and track consumer progress.
7) 𝗣𝘂𝗯/𝗦𝘂𝗯
↳ Fan out real-time messages when durability and replay aren’t required.
8) 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗹𝗼𝗰𝗸𝘀
↳ Prevent multiple workers or agents from modifying the same resource at the same time.
Redis has quietly evolved from “just a cache” into infrastructure for real-time coordination, retrieval, streaming, memory, and increasingly AI workloads.
That evolution is reflected in their new context engine launch, focused on delivering live, agent-ready context for AI systems operating across fragmented data sources.
Explore it here → lucode.co/redis-iris-z18xd
What else would you add?
——
♻️ Repost to help others learn and grow.
🙏 Thanks to @Redisinc for sponsoring this post.
➕ Follow me ( Nikki Siapno ) turn on notifications.
2
13
61
5,028
Level Up Coding retweeted
May 25
Top 8 Redis Use Cases.
Redis is often introduced as a cache, but real systems use it for much more than speeding up database reads.
That same need for fast, real-time data access is also why Redis is expanding further into AI infrastructure with Redis Iris, a context engine for AI agents that acts as a context and memory retrieval system.
Learn more here → lucode.co/redis-iris-z17xd
1) 𝗖𝗮𝗰𝗵𝗶𝗻𝗴
↳ Store hot data close to the application to reduce database load and latency.
2) 𝗦𝗲𝘀𝘀𝗶𝗼𝗻𝘀
↳ Keep per-user or per-agent state in Redis so application servers can remain stateless.
3) 𝗥𝗮𝘁𝗲 𝗹𝗶𝗺𝗶𝘁𝗶𝗻𝗴
↳ Track request counts across distributed services, API calls, tool usage, and model calls.
4) 𝗟𝗲𝗮𝗱𝗲𝗿𝗯𝗼𝗮𝗿𝗱𝘀
↳ Use sorted sets to maintain live rankings without recomputing results.
5) 𝗩𝗲𝗰𝘁𝗼𝗿 𝘀𝗲𝗮𝗿𝗰𝗵 & 𝘀𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗰𝗮𝗰𝗵𝗶𝗻𝗴
↳ Store embeddings, retrieve semantically similar data, and reuse responses across similar AI queries.
6) 𝗤𝘂𝗲𝘂𝗲𝘀 & 𝗦𝘁𝗿𝗲𝗮𝗺𝘀
↳ Queue work, process events asynchronously, coordinate agent tasks, and track consumer progress.
7) 𝗣𝘂𝗯/𝗦𝘂𝗯
↳ Fan out real-time messages when durability and replay aren’t required.
8) 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗹𝗼𝗰𝗸𝘀
↳ Prevent multiple workers or agents from modifying the same resource at the same time.
Redis has quietly evolved from “just a cache” into infrastructure for real-time coordination, retrieval, streaming, memory, and increasingly AI workloads.
That evolution is reflected in their new context engine launch, focused on delivering live, agent-ready context for AI systems operating across fragmented data sources.
Explore it here → lucode.co/redis-iris-z18xd
What else would you add?
——
♻️ Repost to help others learn and grow.
🙏 Thanks to @Redisinc for sponsoring this post.
➕ Follow me ( Nikki Siapno ) turn on notifications.
3
44
199
17,952
May 25
They added Cursor to Jira 🙌
Learn more here: lucode.co/cursor-jira-z7xd
May 21
AI coding agents are only as good as the context they have.
Atlassian just solved that with Cursor in Jira.
Context is what makes agents actually useful.
Atlassian holds the full context of work: tickets, specs, decisions, and the teams behind it all.
This release means:
→ All Atlassian context
→ No context or tool switching required
→ Update Jira directly from Cursor
Anyone on the team can go from ticket to merge-ready PR without switching tools.
Agents and humans operate from the same source of truth.
Jira becomes the orchestration layer for humans agents.
I think this is a big step towards scalable agent orchestration.
Great release @Atlassian, @Jira, @TYehoshua.
Thanks to Atlassian for giving me early access to this announcement and for your partnership. #AtlassianPartner #Ad
lucode.co/cursor-jira-z7xd
1
3
7
3,596
Level Up Coding retweeted
May 21
AI coding agents are only as good as the context they have.
Atlassian just solved that with Cursor in Jira.
Context is what makes agents actually useful.
Atlassian holds the full context of work: tickets, specs, decisions, and the teams behind it all.
This release means:
→ All Atlassian context
→ No context or tool switching required
→ Update Jira directly from Cursor
Anyone on the team can go from ticket to merge-ready PR without switching tools.
Agents and humans operate from the same source of truth.
Jira becomes the orchestration layer for humans agents.
I think this is a big step towards scalable agent orchestration.
Great release @Atlassian, @Jira, @TYehoshua.
Thanks to Atlassian for giving me early access to this announcement and for your partnership. #AtlassianPartner #Ad
lucode.co/cursor-jira-z7xd
4
4
20
7,273
Level Up Coding retweeted
May 21
Context has become one of the biggest challenges with AI coding.
Cursor in Jira makes the workflow context-rich for agents. Jira becomes the orchestration layer for humans agents.
I think this is a very useful direction.
Check it out → lucode.co/cursor-in-jira #Ad

May 20

We continue to make @Atlassian tools the place for AI-driven software teams. Teams in Jira can now directly assign any work item to @cursor_ai and a cloud agent will get to work. And it works both ways. If you're working with Cursor in your IDE or terminal, you can keep your teams fully up to date in Jira with our native Teamwork Graph CLI.
Context is instantly shared, so there is less tool switching and more time in flow. It's now available with every paid Jira subscription. More here: atlassian.com/blog/company-n…
5
3
19
4,214
Level Up Coding retweeted
May 20
CI/CD pipeline in under 2 mins:
A CI/CD pipeline is an automated workflow that facilitates continuous integration (CI) and continuous delivery or deployment (CD) by managing code building, testing, and release processes.
It integrates the various stages of the software development lifecycle (SDLC) into a seamless, repeatable process.
These stages include source code management, automated testing, artifact creation, and deployment orchestration.
Continuous ‘delivery’ and ‘deployment’ are sometimes used synonymously.
But there is a clear and important distinction between the two.
Delivery is about ensuring the software can be released at any time.
It requires manual intervention to deploy to production.
Deployment, on the other hand, does the release through automated workflows.
Learn more here: lucode.co/ci-cd-explained-li…
What else would you add?
♻️ Repost to help others learn CI/CD.
➕ Follow me ( Nikki Siapno ) to improve at system design.

10
82
346
12,076
Level Up Coding retweeted
May 19
AI Application Stack.

May 13
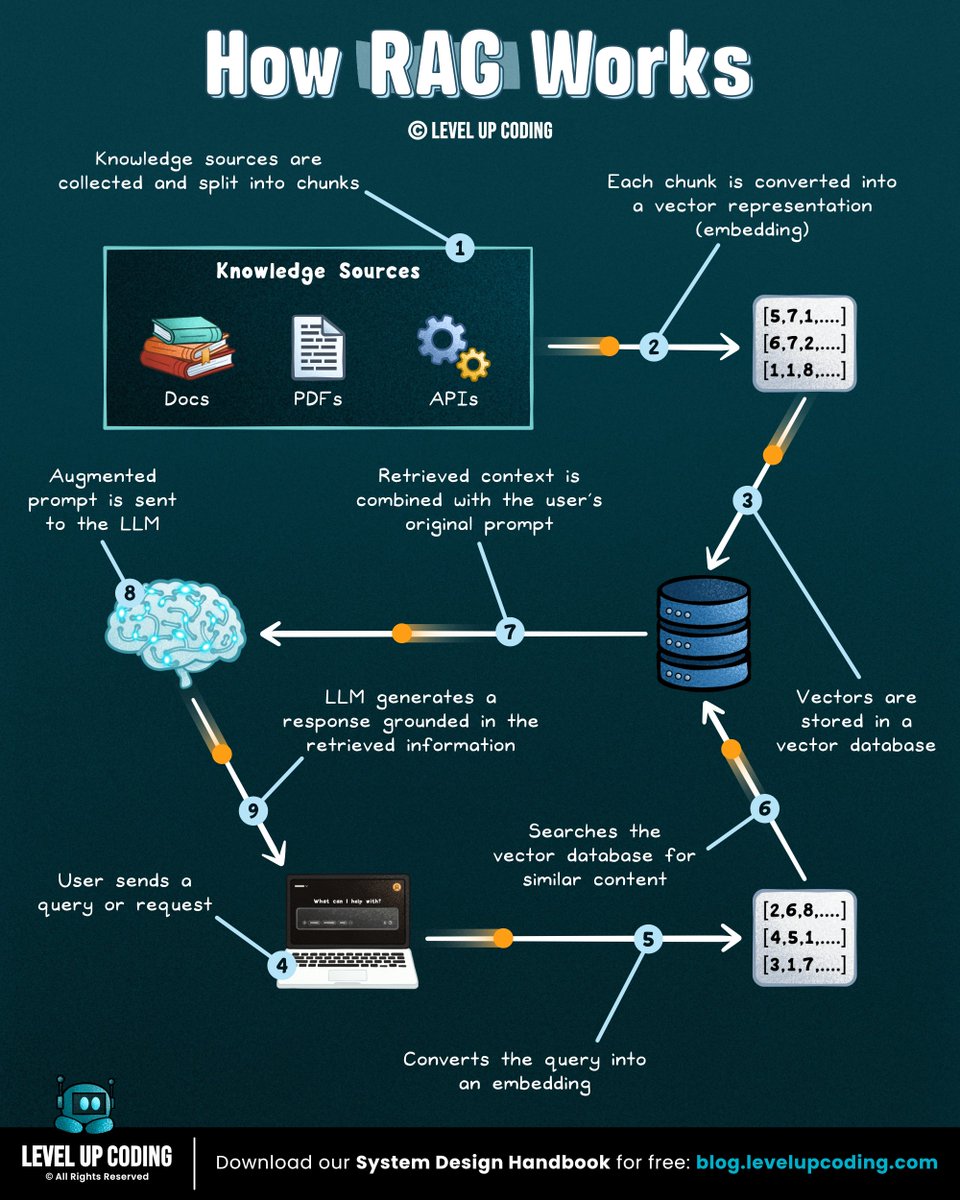
How RAG actually works
(clearly explained in under 2 mins):
RAG (Retrieval-Augmented Generation) is a system that retrieves relevant data and feeds it into an LLM before generating a response.
It lets models answer questions using external knowledge, not just what they were trained on.
If you’re building with these patterns, here's a great guide on scaling multi-agent RAG systems: lucode.co/multi-agent-rag-vi…
Here’s a simple mental model to understand it:
𝟭) 𝗗𝗮𝘁𝗮 𝗶𝘀 𝗶𝗻𝗴𝗲𝘀𝘁𝗲𝗱
↳ Documents (PDFs, docs, APIs) are collected and split into chunks
↳ Each chunk is cleaned and formatted ready for embedding
𝟮) 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀 𝗮𝗿𝗲 𝗰𝗿𝗲𝗮𝘁𝗲𝗱
↳ Each chunk is converted into a vector representation
↳ Similar meaning → closer vectors
𝟯) 𝗗𝗮𝘁𝗮 𝗶𝘀 𝘀𝘁𝗼𝗿𝗲𝗱
↳ Vectors are stored in a vector database
↳ Enables fast similarity search across large datasets
𝟰) 𝗥𝗲𝗹𝗲𝘃𝗮𝗻𝘁 𝗰𝗼𝗻𝘁𝗲𝘅𝘁 𝗶𝘀 𝗿𝗲𝘁𝗿𝗶𝗲𝘃𝗲𝗱
↳ The user's query is converted into an embedding (vector representation)
↳ The system compares it against stored vectors and retrieves the most relevant chunks
𝟱) 𝗧𝗵𝗲 𝗟𝗟𝗠 𝗴𝗲𝗻𝗲𝗿𝗮𝘁𝗲𝘀 𝘁𝗵𝗲 𝗮𝗻𝘀𝘄𝗲𝗿
↳ The query retrieved context are combined into a prompt
↳ The model generates a grounded response
That's the foundation of RAG. There are several types of RAG, each designed for different use cases and levels of complexity.
If you’re curious what this actually looks like in practice (beyond diagrams), this repo is a great place to start: lucode.co/ai-developer-hub-o…
It has:
↳ E2E implementations of RAG, AI applications, agents, and systems
↳ Resources covering AI agent architecture, reasoning strategies, and memory systems.
↳ Hands-on workshops and guided learning
Start it to keep it bookmarked. This repo will keep growing, and you'll want it on hand as you build.
What else would you add?
——
♻️ Repost to help others learn AI engineering.
🙏 Thanks to @Oracle for sponsoring this post.
➕ Follow me ( Nikki Siapno ) to improve at AI engineering.
6
62
297
17,369
May 19
If you want to grow as a software engineer,
try these newsletters (all free):
1. System Design
↳ lucode.co/system-design-luc-…
2. Engineering Leadership
↳ lucode.co/engineering-leader…
3. Insider Knowledge Big Tech
↳ lucode.co/pragmatic-engineer…
4. AI Engineering
↳ lucode.co/ai-native-nltf1li
5. Engineering Career Growth
↳ lucode.co/high-growth-engine…
6. DSA & System Design
↳ lucode.co/algomaster-nltf1li
7. Frontend & Software Design
↳ lucode.co/t-shaped-dev-nltf1…
8. Software Architecture
↳ lucode.co/system-design-clas…
9. Engineering & Leadership Insights
↳ lucode.co/tech-world-with-mi…
10. .NET & Architecture
↳ lucode.co/dotnet-and-archite…
11/ AWS & Cloud
↳ lucode.co/aws-fundamentals-n…
12. Weekly Curated Tech Articles
↳ lucode.co/hungry-minds-nltf1…
What other newsletters should be on this list?
👋 PS: Want to improve at system design? Download my free System Design Handbook and join 33,000 engineers who get my free weekly newsletter → lucode.co/system-design-hand…
♻️ Repost to help others learn and grow.
May 18
If you want to grow as a developer,
try these newsletters (all free):
1) System Design
↳ lucode.co/system-design-luc-…
2) Engineering Leadership
↳ lucode.co/engineering-leader…
3) Insider Knowledge Big Tech
↳ lucode.co/pragmatic-engineer…
4) AI Engineering
↳ lucode.co/ai-native-nltf1li
5) Engineering Career Growth
↳ lucode.co/high-growth-engine…
6) DSA & System Design
↳ lucode.co/algomaster-nltf1li
7) Frontend & Software Design
↳ lucode.co/t-shaped-dev-nltf1…
8) Software Architecture
↳ lucode.co/system-design-clas…
9) Engineering & Leadership Insights
↳ lucode.co/tech-world-with-mi…
10) .NET & Architecture
↳ lucode.co/dotnet-and-archite…
11) AWS & Cloud
↳ lucode.co/aws-fundamentals-n…
12) Weekly Curated Tech Articles
↳ lucode.co/hungry-minds-nltf1…
What other newsletters should be on this list?
——
👋 PS: Want to improve at system design? Download my free System Design Handbook and join 33,000 engineers who get my free weekly newsletter → lucode.co/system-design-hand…
——
♻️ Repost to help others learn and grow.
➕ Follow me ( Nikki Siapno ) to improve at system design.

3
7
40
5,185