
Postdoctoral fellow at @VectorInst. ML PhD at UBC. Mathematical and computational structures for ML. Geometric and algebraic methods.
Joined August 2020
- Tweets 113
- Following 40
- Followers 312
- Likes 96
30 Photos and videos











Pinned Tweet

16 Jul 2024
#ICML2024
Can We Remove the Square-Root in Adaptive Methods?
arxiv.org/abs/2402.03496
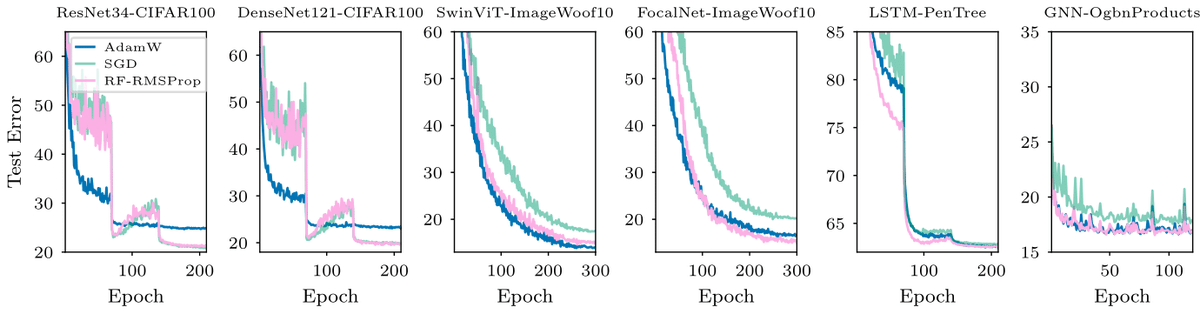
Root-free (RF) methods are better on CNNs and competitive on Transformers compared to root-based methods (AdamW)
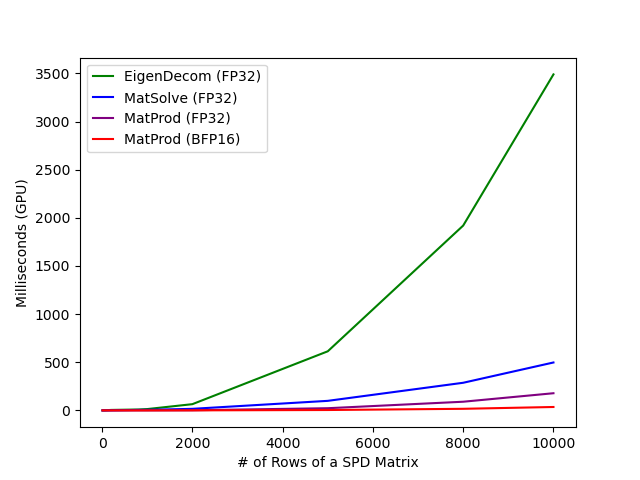
Removing the root makes matrix methods faster: Root-free Shampoo in BFloat16 /1
9
16
61
12,798
Jun 12
On one hand, it is essential to tune baseline methods well on a model. On the other hand, it may be better to avoid using a model/architecture that has been modified and optimized for a single method for 1.5 years.
Jun 11

I just submitted a PR to modded-nanogpt with better hyperparams. With them, Muon can reach the target loss after 3250 steps instead of 3325.
Always tune your baseline well when doing research. Weak baselines can make any idea look promising
1
5
1,169
May 3
We will make Shampoo/SOAP, including KL-Shampoo/KL-SOAP, faster. Our goal is to match Muon's runtime while maintaining Shampoo/SOAP's strong per-step performance. Stay tuned for new updates.
May 2

KL Shampoo and KL SOAP outperform their non-KL counterparts by learning the preconditioners compositionally, so that each stage corrects what remains after the last.
Available in HeavyBall 3.1.1, with major PSGD stability backports.
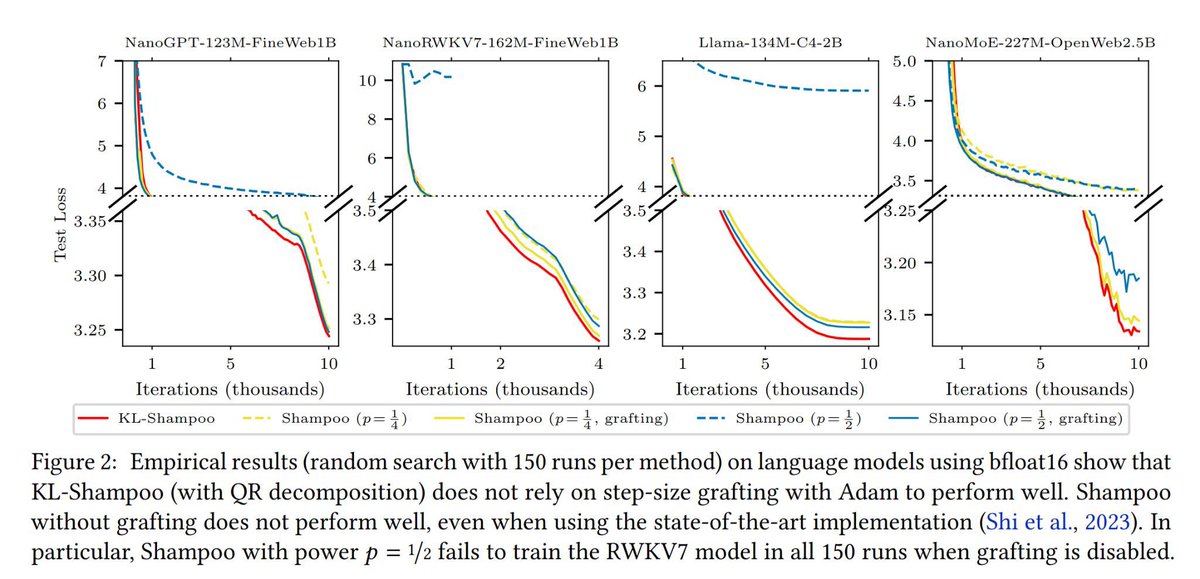
1
4
46
3,062
May 28
Some initial steps to make Shampoo and SOAP faster arxiv.org/abs/2605.26327 We are working on further improvements.
1
1
52
Wu Lin retweeted
Apr 19
@weijie444 Looks like a KFAC-based method with modern clipping? G(ZZ^T)^{-1} is known as the FOOF update arxiv.org/abs/2201.12250 while msgn() can be interpreted as "generalized (preconditioned) gradient norm clipping" arxiv.org/abs/2506.01913 .
Apr 16

We released "The Newton--Muon Optimizer" . We show that Muon is secretly an implicit Newton method, and use this insight to build a better one. 1/n
Paper: arxiv.org/abs/2604.01472
2
6
52
5,644
3 Dec 2025
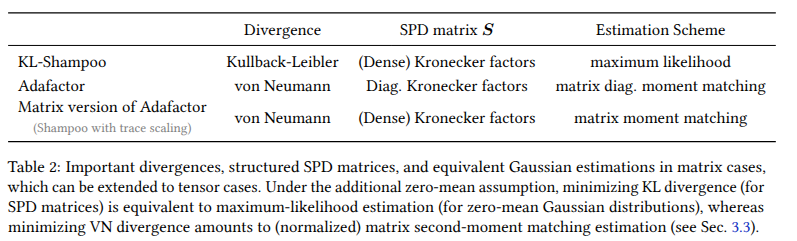
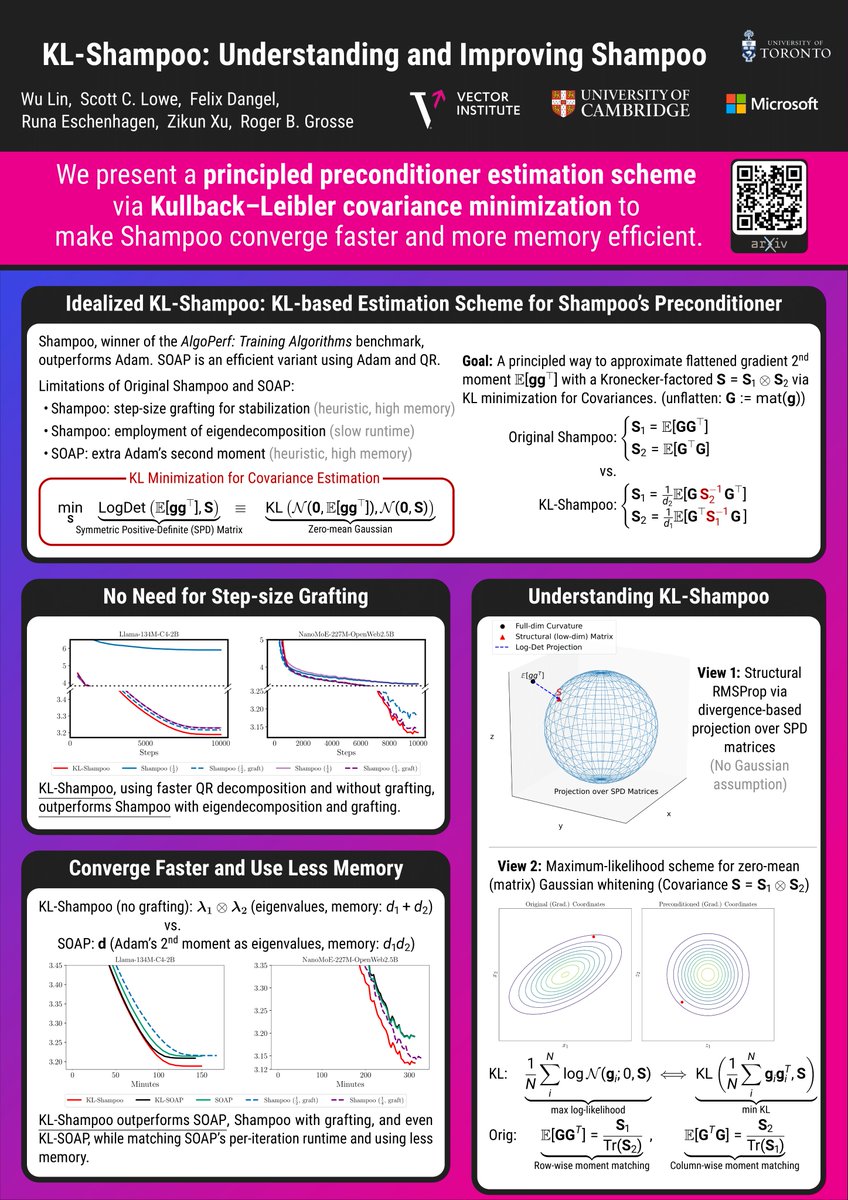
Within an information-geometric framework, we reconnect Shampoo/SOAP with both classical quasi-Newton ideas and Gaussian whitening, and develop practical methods that naturally handle tensor-valued weights in language model pre-training. arxiv.org/abs/2509.03378 opt-ml workshop
1
7
8
1,079
3 Dec 2025
This work builds on my ICML 2019 paper (with @MarkSchmidtUBC and @EmtiyazKhan), extending a variational Bayes-based geometric framework to modern NN optimization. It can be used to design methods for Bayesian inference, numerical optimization, and gradient-free optimization.
1
3
125
3 Dec 2025
This work is a joint effort with Scott C. Lowe, @f_dangel, @runame_, Zikun Xu, and @RogerGrosse.
Stay tuned for more updates coming soon.
4
112
Wu Lin retweeted

20 Nov 2025
1/9 In practice, the Shampoo optimizer crucially relies on several heuristics.
In our NeurIPS 2025 spotlight paper, we investigate the role of learning rate grafting and infrequent preconditioner updates in Shampoo by decomposing its preconditioner.
arxiv.org/abs/2506.03595

3
21
91
13,251
Wu Lin retweeted

27 Nov 2024
Huge thanks to my amazing collaborators. This project was led by @juhanbae along with @LinYorker and @RogerGrosse.
Supported (indirectly) by @Anthropic, @NVIDIA, @VectorInst, @UofTCompSci/@UofTArtSci/@UofT

1
7
532
Wu Lin retweeted

10 Nov 2024
Are you LoRA fine-tuning LLMs and looking for easy ways to get improvements in accuracy? And also Bayesian uncertainty on top for free?
Then check our recent work, accepted @neurips24fitml workshop!
arxiv.org/abs/2411.04421
7
16
61
7,435
5 Oct 2024
Natural gradient descent: (steepest) gradient descent under a norm induced by the Fisher matrix yorkerlin.github.io/posts/20…
Riemannian gradient descent (with geodesic retraction) : gradient descent in Riemannian normal coordinate
4 Oct 2024

At Maximum Likelihood Estimator:
Key property:
observed Fisher information = Fisher information
2nd order Taylor expansion of likelihood:
- likelihood curvature = Fisher information
- radius of osculating circle=Variance of MLE for large sample size

1
5
37
4,124
6 Sep 2024
Some hardcore theory people complain that "second-order" methods in DL do not have a superlinear convergence rate. At the same time, they are happy to consider SGD a first-order method with only a sublinear rate.
2
127