
Inference Engineering @Microsoft
Joined April 2017
- Tweets 1,998
- Following 466
- Followers 802
- Likes 3,518
146 Photos and videos













May 30
Yet another misleading benchmark (batch size of 1).
May 29

At 3,000 tokens/s, your budget per token is 333 microseconds. A basic kernel launch is 4.5µs. Kog hit 3k tok/s on standard GPUs by dropping PyTorch and writing a persistent monokernel in raw assembly. The CPU scheduler is officially the enemy ✨
1
114
May 22
Out of all the MLSYS happy hours, OpenAI’s one was probably the top 1, together AI’s was also dope!
2
121
May 18
I’m at MLSys this week! feel free to come say hi if you want to chat about inference, GPU programming or ml systems
6
180
May 16
Unrolling a single mfma loop produced 17% perf gain 🤯🤯 I’ll never underestimate the power of unrolling ever again
2
252
May 14
Agentic coding is like makeup, a lot of engineers started believing they’re naturally that good.
4
108
May 13
Im glad my feed no longer shows these cringe meta expressions such as:
Ngmi
Lfggg
We’re so back
We’re cooked
And the list goes on..
80
May 4
Its more interesting when you know what he’s referring to at the end

Ilya Sutskever just told the AI industry why scaling is finished.
One word built it. One word is about to break it.
Sutskever: “Scaling is just one word, but it’s such a powerful word because it informs people what to do.”
For five years, that single word replaced an entire research culture.
Nobody needed breakthroughs. They needed bigger checks.
Sutskever: “If you mix some compute with some data into a neural net of a certain size, you will get results, and you will know that it will be better if you just scale the recipe up.”
That’s not science. That’s a recipe.
Sutskever: “Companies love this because it gives you a very low risk way of investing your resources.”
The most transformative technology in human history ran on the same logic used to franchise a restaurant chain.
More locations. More ingredients. Same recipe. Predictable returns.
You didn’t need researchers who could see around corners.
You needed accountants who could approve purchase orders.
But recipes expire.
Sutskever: “At some point though, pre-training will run out of data. The data is very clearly finite.”
Five years of infrastructure. Five years of hiring. Five years of investor decks.
All built on top of something temporary.
Sutskever: “I don’t think that’s true.”
The co-founder of OpenAI. The mind behind the breakthroughs that made this entire era possible.
Saying more money won’t solve it.
Sutskever: “In some sense we are back to the age of research.”
Most of the companies racing to build AGI were never research companies.
They were scaling companies.
They hired for execution. Not discovery. They optimized for throughput. Not insight.
The talent pipelines. The investor pitches. The board decks.
All built around one assumption.
That the recipe would never expire.
It’s expiring.
And the companies that spent five years perfecting the art of spending money are about to discover something.
The next era demands what capital can’t purchase.
An original idea.
2
134



Apr 30
There should be a standard for layout contracts, repacking wgmma optimzied layouts to mfma optimized layouts is a nightmare.
It would be ideal if there’s a standard to at least repack every layout to a row major one then, it would also be cool to have a portable decode function with different layouts for the same hardware and tune against…
83
Apr 25
In 6 months, all cuda/hip dsls, as well as frameworks like triton and gluon, will primarily be used as hardware abstraction layers for cross-vendor and custom-chip support. Most highly optimized kernels will instead be written directly in low level cuda and hip.
In 1 year, llms will be able to one shot instruction level kernels of custom silicon by ingesting the docs in the context.
5
98
Mar 28
My team at Microsoft is still hiring inference engineers, we have positions from mid to principal levels.
You’ll get to work directly on OpenAI models (gpt 5.4 ) and optimize them for different workloads.
You’ll get to work on the latest hardware out there, GB300s, H200s, MI300X
Dm me for direct referral
4
272
Mar 7
How do you entertain yourself while waiting for your codex-5.4-X-Mega-High-Thinking to finish its task?
2
358
Mar 5
Is it ever legal to leave a printf in a cuda kernel if it resolves a heisenbug?
1
2
290
Feb 21
Is there a way to have one agent act as an orchestrator so you only talk to that agent, and it then manages the other 4-5 agents, gives you status updates on each, and dispatches tasks to them?
1
2
250
Feb 19
It’s incredible how startups invest months in developing these ideas only to be surpassed by the big boys when they finally have the opportunity to create a significantly better product in a shorter timeframe
Feb 19

Today, we’re introducing Pomelli’s latest feature update, ‘Photoshoot’
With Photoshoot, you can start from a single image of your product and easily create high quality, customized product shots to elevate your marketing.
Available free of charge in the US, Canada, Australia & New Zealand! Get started with Pomelli today at labs.google/pomelli
2
347
Feb 8
I've seen a lot of tweet asking about how this was done, my theory (which is based on the good intention that making it 2.5x fast is actually bringing the price up) is:
Let's say a single replica can handle X amount of users, and they were serving 6k max batch size on that replica, in that case let's assume this produces 100 ms TBT.
Then they would spin up 3 replicas and cap the max batch size to 2k, this will serve the same amount of users but it will bring down the TBT to 40ms (33ms 7ms fixed overhead), and since you're running 3 replicas the price will go up, so they decided to provide this premium service for users for a premium price, so realistically they are getting 2x more profit per token with this strategy, but it limits the amount of users they can serve because users/replica rate is lower.

Our teams have been building with a 2.5x-faster version of Claude Opus 4.6.
We’re now making it available as an early experiment via Claude Code and our API.
7
880
Feb 4
Probably possible for quantization kernels, I’m sure gemms are no where near in performance, also I don’t think triton uses tensor memory (tcgen05.mma) that’s the reason gluon was introduced!
Feb 4

many people may not be aware that 'smartly' written triton (in less than 100 lines) can achieve the same speed as a CUDA kernel that contains more than 1000 lines of code
should i write a blog post on this?
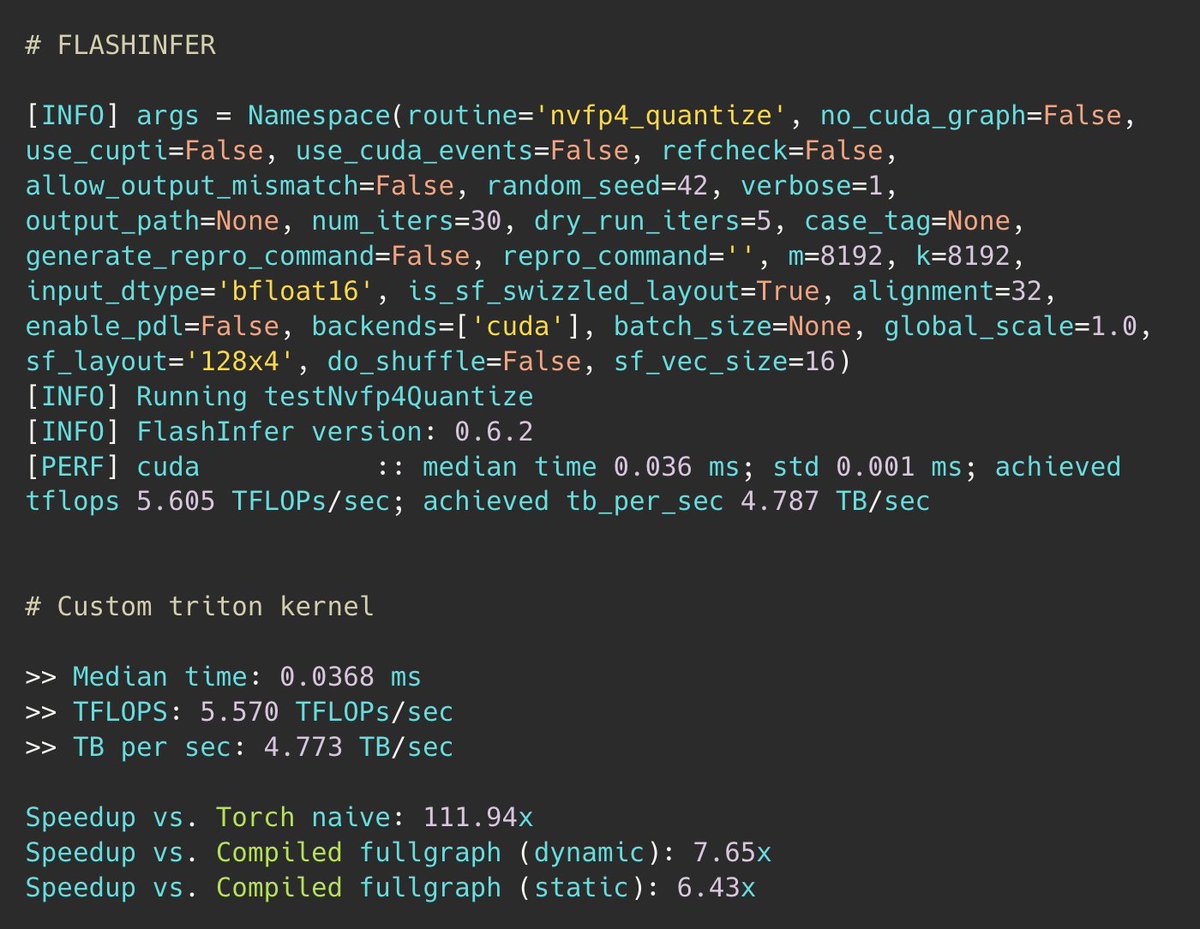
1
9
1,630