
Photos and videos

Apr 16
Great deep dive into DSA and the economics of serving long-context models!
Apr 15

deepdive into the economics of DeepSeek Sparse Attention (DSA) and how it affects the profit margins of serving a Claude-Code-like products
link in the thread 1/x

1
4
264
Lukas Blübaum retweeted

Feb 24
Last week we explored NVIDIA's CuTe layouts. Today, we put that theory into practice. Part 2 is out now! Most CuTe examples skip straight to highly optimized code without explaining the reasoning. Join me as we build a MM kernel with CuTe, that can beat cuBLAS in certain cases 🧵
3
22
190
7,980
Lukas Blübaum retweeted
Feb 19
NVIDIA’s CuTe layouts are gaining traction. I wanted to see why everyone loves them. The basics were easy, but intermediate resources beyond matrix algebra were scarce. So I wrote a blog post sharing my journey, building up to a GEMM kernel that can beat cuBLAS 🧵
6
11
117
13,330
Lukas Blübaum retweeted

2 Dec 2025
You can combine Penny and Alpha-MoE to get a 30% throughput increase on average for running DeepSeek compared to current SGLang.
I believe that this is the fastest DeepSeek implementation for low scale deployments(tested on 16xH100)

1 Dec 2025

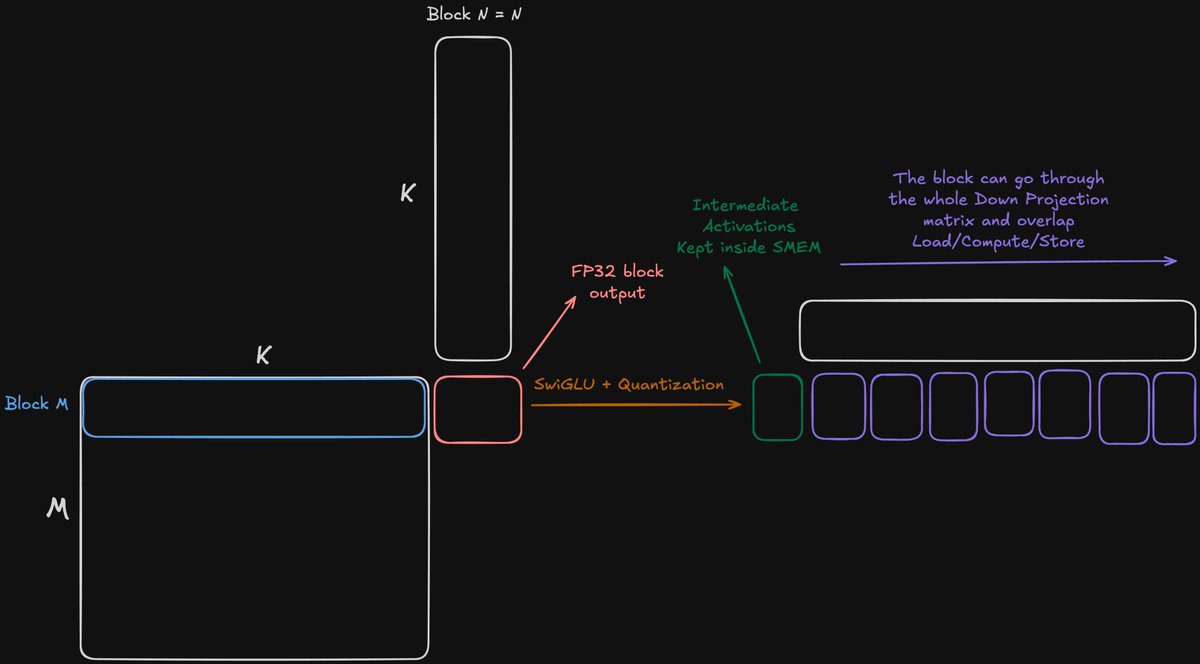
Releasing Alpha-MoE: Megakernel for fast Tensor Parallel Inference!
Up to 200% faster execution of MoE layer in SGLang, with 17% higher average throughput on Qwen3-Next-80B, and 10% higher average throughput on DeepSeek
Proud to showcase my recent work at @Aleph__Alpha🧵
1
3
39
2,666
Lukas Blübaum retweeted

1 Dec 2025
Introducing Alpha-MoE: A fused megakernel for faster tensor parallel inference. With up to 200% speedups for MoE models in TP deployments. Optimized for Hopper. Built for sovereignty and scale.
aleph-alpha.com/alpha-moe-a-…

4
19
124
9,083
Lukas Blübaum retweeted
1 Dec 2025
Releasing Alpha-MoE: Megakernel for fast Tensor Parallel Inference!
Up to 200% faster execution of MoE layer in SGLang, with 17% higher average throughput on Qwen3-Next-80B, and 10% higher average throughput on DeepSeek
Proud to showcase my recent work at @Aleph__Alpha🧵
12
33
322
52,024
26 Nov 2025
Amazing blogpost if you want to learn about RL infrastructure:
26 Nov 2025
RL is cool, but what do you actually need to know about hardware and infra to predict its future? Check out our new piece on tensoreconomics:
1
1
59
Lukas Blübaum retweeted

4 Sep 2025
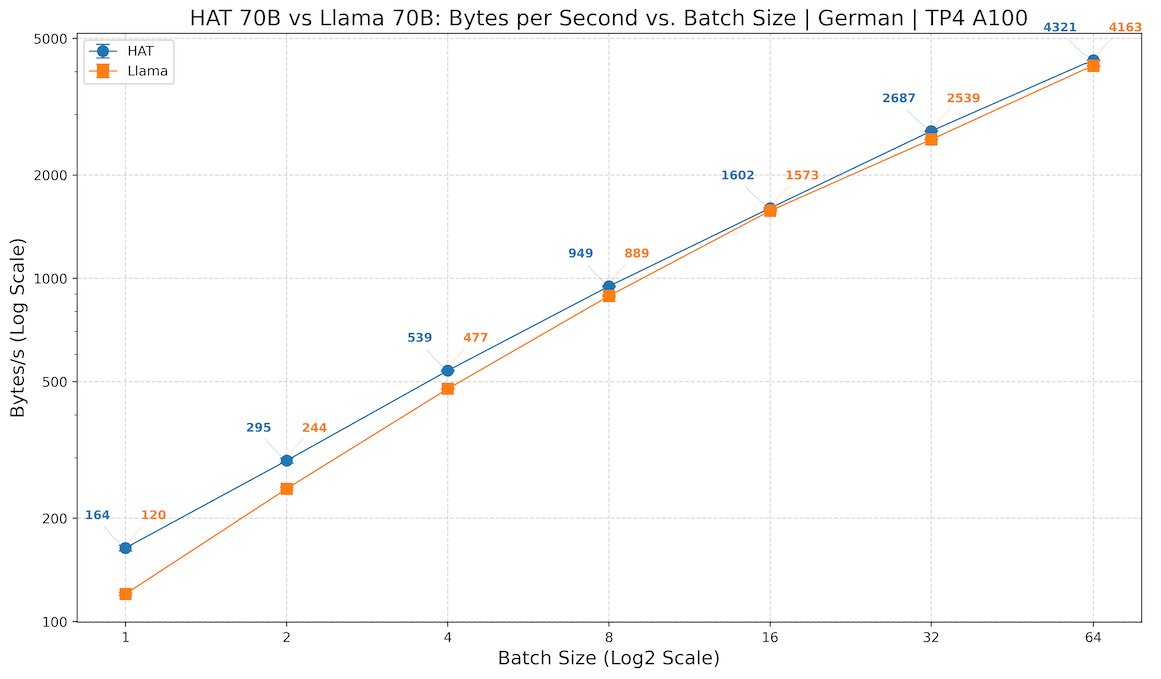
First high-performance inference for hierarchical byte models.
@LukasBluebaum and I developed batched inference for tokenizer-free HAT (Hierarchical Autoregressive Transformers) models, developed by @Aleph__Alpha Research. In some settings, we outcompete the baseline Llama.🧵
2
7
27
3,680