
I make videos for #DataNerds 🤓
Joined December 2021
- Tweets 437
- Following 147
- Followers 4,148
- Likes 1,101
134 Photos and videos











Jun 3
Data Nerds! It's only taken me over 2 years, but I finally launched my FREE Data Analyst Bootcamp!
This 35-hour video is what I wish I'd had when I got started; it's for those with no degree or experience, helping one go from zero to job-ready.
For this bootcamp, we’re focusing on the top 4 demanded skills for a Data Analyst
1️⃣ SQL (45% of job postings)
2️⃣ Excel (32%)
3️⃣ Python (31%)
4️⃣ Power BI (28%)
But here's what makes this more than just a "How-To" video. It's not about the tools. The real work is learning how to be a data analyst and actually perform the analytics. The tools? They're just a necessity to facilitate it.
And the best way to learn all that? You build it:
🛠 6 hands-on portfolio projects (because employers want experience)
🤖 AI built into your workflow to learn and work efficiently
🐙 GitHub to share everything you build
So you finish each skill with something real to show, not just a "completed" badge.
Now the real talk. I pulled the numbers from my own course-takers on how long each skill will take to learn:
🐘 SQL ~3 months
❎ Excel ~3 months
📊 Power BI ~2 months
🐍 Python ~6 months
Realistically, that's 8 to 12 months to transition if you're doing this part-time.
Alright, let's get to building. 🤙
17
44
295
9,449
May 15
Data Nerds! I ranked every data engineering tool by how often it shows up in 4M job postings. 📊
But here's the catch 😳.
Some critical skills show up way less than they should because they're often assumed to be foundational skills for jobs. (e.g., Skills like Bash/Terminal for running pipelines)
Anyway, here's the breakdown of the tiers 👇 (Note: % = how often each tool appears in DE job postings)
🔴 S TIER — Non-Negotiable
The core skills needed for any DE job. Don't apply without these:
📊 SQL (~68%) — every warehouse runs on it. Query, transform, and model data.
🐍 Python (~67%) — the pipeline language. Ingestion, automation, APIs, glue between systems.
⌨️ Terminal/Bash (~11%) — every tool you'll use runs from here. This is highly undervalued in postings.
📁 Git (~11%) — version control. Every team uses it. Same posting-% caveat as Bash.
☁️ One cloud platform warehouse (~26-46%) — AWS Redshift, GCP BigQuery, or Azure Synapse. Combined cloud presence is in nearly every posting.
Start with SQL, then Python. Everything else you absorb alongside them.
🟠 A TIER — Job-Ready Foundation
The tool that closes the gap from "learning DE" to "hireable for modern stacks":
🪛 dbt (~10%) — only 10% of all DE postings, but 36% in Analytics Engineer (AE) roles.
That's not a niche, it's a leading indicator. AE is the new hybrid role modern data teams are hiring for: part analyst, part engineer.
✅ Land the job with S A. Pass the interview with conceptual knowledge of B Tier 👇
🟡 B TIER — Interview-Aware
Know what they solve. Don't expect to code from scratch:
⚙️ Airflow (~17%) — orchestration. Built on DAGs (directed acyclic graphs).
⚡ Spark (~38%) — distributed computing for processing large datasets.
🌊 Kafka (~19%) — real-time event streaming between systems.
All these depend on a foundational knowledge of Python & SQL; don't jump the gun learning these.
🟢 C TIER — Data Platform Awareness
Pick the one your company uses. Understand both conceptually:
❄️ Snowflake (~26%) — pure SQL warehouse. Optimized for analytics. Modern-stack favorite.
🧱 Databricks (~24%) — lakehouse on Spark. Handles structured unstructured. ML/AI heavy teams.
🔵 D TIER — Versatility Multipliers
Lower headline demand, but high value per hour:
📊 Power BI (~15%) / Tableau (~10%) — but the kicker: in AE roles these jump to 28% / 33%.
Modern data teams want pipeline builders who can also visualize. For analysts pivoting to DE, lead with this in interviews.
🟣 E TIER — Path-Dependent
High demand on paper, but concentrated in legacy enterprise stacks. Skip until your job requires it:
☕ Java (~25%) — legacy enterprise data infrastructure
⚖️ Scala (~22%) — Spark's native language. Spark-heavy shops.
🎥 How did I derive this ranking? In my latest video, I walk through the concepts first (the DE lifecycle, what each tool actually solves) and then derive the tiers. (Link in comments 👇)
6
26
157
5,244
May 15
⚠️ Fundamental DE concepts are more important than focusing on tools first.
I break down how I rank these tools based on the core concepts here👉 youtu.be/_-DzZeixu0w
1
8
651
Apr 20
Data Nerds! I just launched a FREE 10-Day Crash Course on Becoming a Data Engineer! 🛠️
This course is for the analyst whose boss heard 'I know SQL' and somehow translated that to 'build our entire data infrastructure.' 😵
Over the course of 10 days, I'll deliver it straight to your inbox, one email at a time:
🧑💻 Day 1: What Data Engineers actually do
🔄 Day 2: The Data Engineering Lifecycle — the framework everything clicks around
🛠️ Day 3: Essential DE tools — backed by real job posting data
🏗️ Day 4: Data warehouses, lakes, and lakehouses
📐 Day 5: Data modeling — the skill that separates analysts from engineers
📥 Day 6: Batch vs. streaming ingestion
🔧 Day 7: ETL, ELT, and transformations
📊 Day 8: Serving data to the business
⚙️ Day 9: Orchestration and production pipelines
🗺️ Day 10: Your DE learning roadmap
🎁 Bonus: How to land your data job
It's the crash course I wish I had back when I was nodding along to words like 'orchestration' and 'ingestion' and praying nobody asked me to define them. 😅
No fluff. No tool-of-the-week hype. Just the concepts that make the rest of it click.
📩 Link in the first comment 👇
6
89
525
20,788
Apr 6
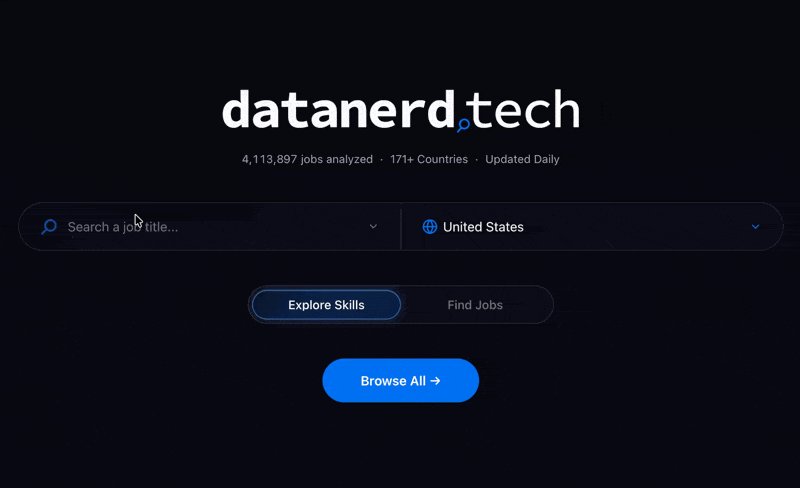
Data Nerds! I just rebuilt datanerd.tech, my free job market intelligence app. 📲
But first, why the heck is this app even needed?
Ask any AI what the top skills for data analysts are, and you'll get a confident answer — pulled from the same biased sources that have always polluted this topic.
Colleges list outdated technologies to justify their aged programs. Course providers list their own courses as "top skills." Influencers (including me) are falling for it, too.
As someone who wasted months learning outdated tools because I thought it was “relevant” (...thanks, Microsoft Access 🤦🏼♂️)
I built an app that cuts through the noise.
🙅🏼♂️ No opinions. No agendas.
📊 Just an analysis of real-time job postings telling you exactly what employers are actually demanding.
Since launching 3 years ago, datanerd.tech has aggregated over 4 million job postings so data nerds like you can focus on the skills that actually matter and stop wasting time on the ones that don't.
And here's what the rebuild actually brought:
🌍 A faster, cleaner pipeline pulling real-time job postings from around the world
🔍 A brand new job search feature where you enter YOUR current skills and find recently posted jobs that match you
No more "what should I learn next?" Just data telling you where you stand and what's in demand right now.
Tomorrow I'm dropping a full walkthrough video on everything the app can do. Stay tuned. 🙌
2
2
12
471
Feb 11
Data Nerds! I just launched a free course on "SQL for Data Engineering!"
This is the course I wish I had when I stopped asking “how do I query this?” and started asking “how do I build this?” 🏗
This YouTube video has over 14 hours of content and walks through building a real data warehouse and production-ready SQL pipeline from scratch.
We go far beyond SELECT statements:
1️⃣ Production SQL — DDL, DML, CTEs, subqueries, window functions, and advanced query patterns
2️⃣ Data Modeling — Designing star schemas and analytics-ready warehouse tables
3️⃣ Data Warehousing — Structuring fact and dimension tables properly
4️⃣ End-to-End Pipelines — Transforming raw data into clean, production-ready outputs
5️⃣ Engineering Workflow — Using Terminal, DuckDB, VS Code, and Git
And because the best way to learn is to build, we complete two real projects:
📊 Project #1 — Exploratory Data Analysis on a live warehouse dataset
🏗 Project #2 — Build a full SQL-based data pipeline
Huge thank you to the team that made this possible:
Kelly Adams - Course Producer
Rikki Singh - Content Developer
Brannon Linder - Video Editor
P.S. If you’re wondering how this compares to my SQL for Data Analytics course:
That course focuses on querying data to answer business questions.
This one focuses on modeling data, designing warehouse schemas, writing production-grade SQL, and building end-to-end pipelines using the Terminal and Git.
🧑💻 Analytics is about extracting insights.
🧑🔧 Engineering is about building the systems that make those insights possible.
Neither course is a prerequisite, but they prepare you for different roles.
16
166
972
35,654
11 Aug 2025
Data Nerds! Help me choose my next YouTube course 👇
32%
🛠 SQL for DE
11%
📊 Tableau for DA
40%
📈 Adv. Power BI w/ DAX
17%
🤖 Python for ML
47 votes • Final results
17
3,197
11 Jun 2025
Data Nerds! I just launched a free course on "Power BI for Data Analytics!"
This course is for anyone who has ever been stuck emailing 'final_v3_final_FINAL.xlsx'. 🥵
It's the guide I wish I had when learning how to build a real, end-to-end analytics solution, packed with all my professional tips and tricks on a live dataset. 🪄🐰
We cover the entire Power BI workflow across four key chapters:
1️⃣ Grand Tour: A deep dive into Power BI Desktop & Service.
2️⃣ Visualizations: Mastering charts, maps, cards, and design.
3️⃣ Power Query: For all your data cleaning & transformation (ETL).
4️⃣ DAX & Modeling: Write powerful formulas on a solid data model.
And since the best way to learn is by building, we'll apply these skills to create two portfolio-ready dashboards!
📊 Project #1: Data Jobs Dashboard (with Drill-Through)
📈 Project #2: The Final Dashboard (Single-Page Focus)
P.S. This course was a beast to build, but I'm so stoked it's finally here!
12
18
141
8,136
3 Feb 2025
Data Nerds! I just launched a FREE 5-Day Crash Course on Becoming a Data Analyst! 🤓
Breaking into data can feel overwhelming—too many skills, too many paths, and the classic “How do I get experience without a job?” dilemma. 😵💫
That’s why I built this step-by-step course to cut through the noise and get you job-ready, fast. Each day, we tackle a key challenge on your path to becoming a Data Analyst:
😨 Day 1 - Overcoming the Biggest Fears About Breaking Into Data
🧑💻 Day 2 - What Data Analysts Actually Do (And Common Myths)
🛠 Day 3 - The First Technical Skills You MUST Learn
🧠 Day 4 - 3 Secrets to Accelerate Your Learning
🗺️ Day 5 - My 3-Step Roadmap to Stand Out With Employers
It's completely free and sent straight to your inbox—because getting started in data shouldn't feel like guesswork.
4
5
36
2,403
14 Oct 2024
Data Nerds! I just launched a free course on "Excel for Data Analytics!"
This is the course I wish I had when starting in the sheets...
Spreadsheets, that is! 🤓
This YouTube video is packed with 11 hours of content with real-world analytic exercises on a live dataset; capturing all my tips and tricks. 💻
In the first half, we’ll focus on the basics, ultimately building a dashboard for our first project:
1️⃣ Spreadsheets Intro
2️⃣ Formulas & Functions
3️⃣ Charts
4️⃣ Tables / Conditional Formatting
📊 Project No.1 - Data Science Job Dashboard
In the second half, we’ll turn up the heat and get into advanced analysis techniques:
5️⃣ PivotTables / PivotCharts
6️⃣ Analysis Add-ins
7️⃣ Power Query
8️⃣ Power Pivot / DAX
📈 Project No.2 - Data Science Job Analysis
P.S. This course took WAAYYYY longer than I was expecting to build, and I couldn't have done it without the help of Kelly Adams!
P.S.S. Taking recommendations now for the next course. 🤙
6
12
77
3,217
Luke Barousse retweeted

2 Jul 2024
is generating an AI image worth a thousand tokens?
2
2
17
2,352
18 Jun 2024
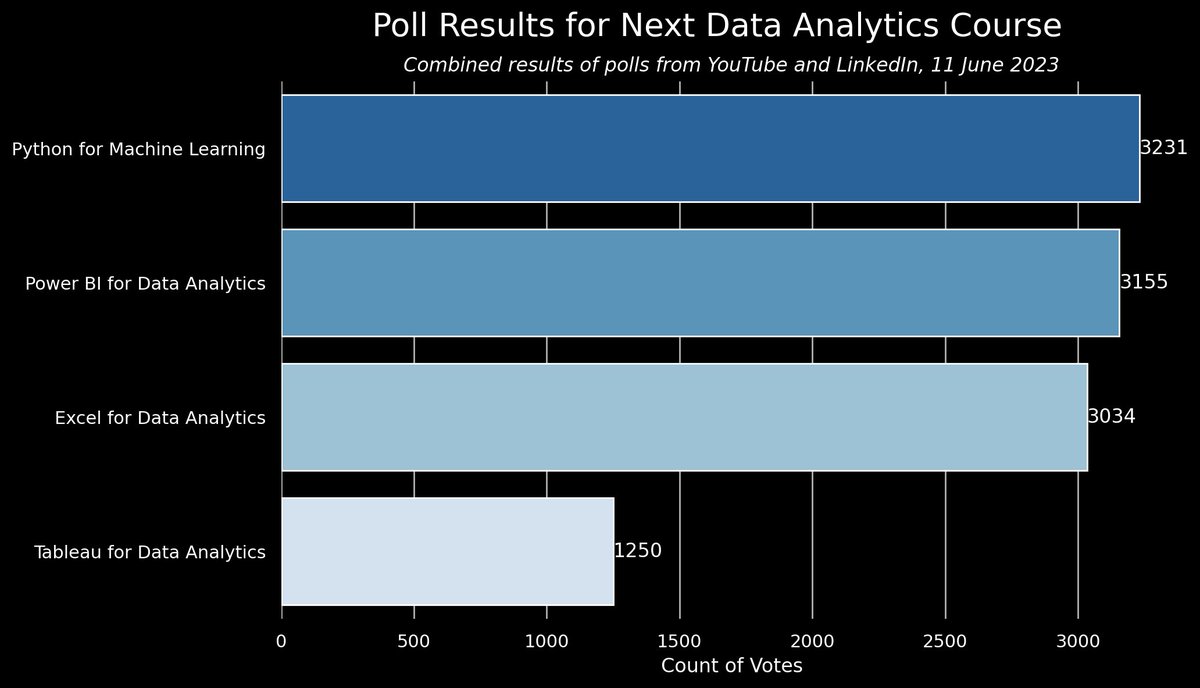
Data Nerds! Poll results are in, and the next course is:
🥉 Excel for Data Analytics (😳 …let me explain)
Python and Power BI both beat out Excel, so why are @KellyjAdamz and I ignoring this?
----------------------------
📈 Reason # 1: Tool Demand
Here are the top skills demanded of Data Analysts according to job postings:
1️⃣ SQL (47%)
2️⃣ Excel (33%)
3️⃣ Python (31%)
4️⃣ Tableau (24%)
5️⃣ Power BI (20%)
Coincidently, my SQL and Python courses have performed proportionally to these percentages
Additionally, the job market is demanding Excel over these other skills, and… “the market always wins”
---------------------------------
🧠 Reason # 2: Learning Journey
When it comes to learning tools to become a Data Analyst, I’d recommend this general order:
SQL and Excel ➡️ Power BI or Tableau ➡️ Python or R
SQL and Excel are staples of any Data Analyst role, along with being relatively easy to learn (compared to programming languages)
So why are visualization tools before programming languages?
You can learn Power BI/Tableau in a weekend (at least I did); Python/R takes weeks, if not months, just to get the basics, so knock out the easier tool first.
---------------------------------------
🧮 Reason # 3: Statistical Significance
So, Luke, you’re ignoring the poll results…
Well… not really
There is only a 200 vote difference (<2%) between the top 3 tools
Based on the amount of votes and the difference in the votes, the results are not statistically significant (p-value: .206)
---------------------------------------
P.S. I used ChatGPT to combine the YT and LinkedIn polls by providing pictures of the poll results (it also calculated the p-value);
Curious about how I’ve done this? Check out my ChatGPT course.
5
1
30
2,161
11 Jun 2024
Data Nerds! I'm looking for input on my next video course 👇
P.S. Thanks for all the love for my recent "Python for Data Analytics" course 🫶
36%
Excel for Data Analysis
29%
PowerBI for Data Analysis
16%
Tableau for Data Analysis
20%
Python for ML/AI
45 votes • Final results
1
3
19
1,499
11 Jun 2024
Data Nerds! I just launched a free course on “Python for Data Analytics!"
This is the tutorial I wish I would have had when first learning how to code
This YouTube video has over 11 hours of video content, and I couldn't have done it without the help of @KellyjAdamz! 🙌
Here are some course highlights:
💻 Python Environment and Full Data Access
📚 Top Libraries Covered: Matplotlib, Pandas and Seaborn
👨🏼💻 All Code Publicly Available in my GitHub Repo
And the best way to LEARN something is to BUILD something; So we’ll also tackle a real-world problem for our final capstone project:
📺 Walkthrough of a Fully Customizable Project
📊 Access to Data Science Job Insights
👾 Shareable Project to Host on GitHub
P.S. Sorry for the delay in content over the past couple of months, as this has been taking up all my bandwidth, and there is no way I could have done it without Kelly’s help!
3
9
44
1,813