
Joined July 2020
- Tweets 120
- Following 106
- Followers 3,881
- Likes 80
23 Photos and videos




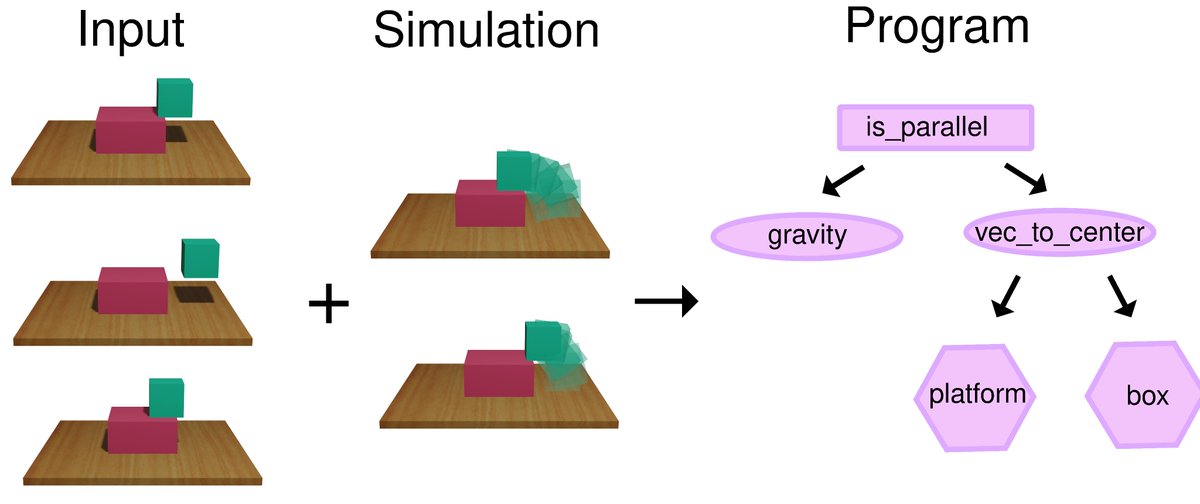




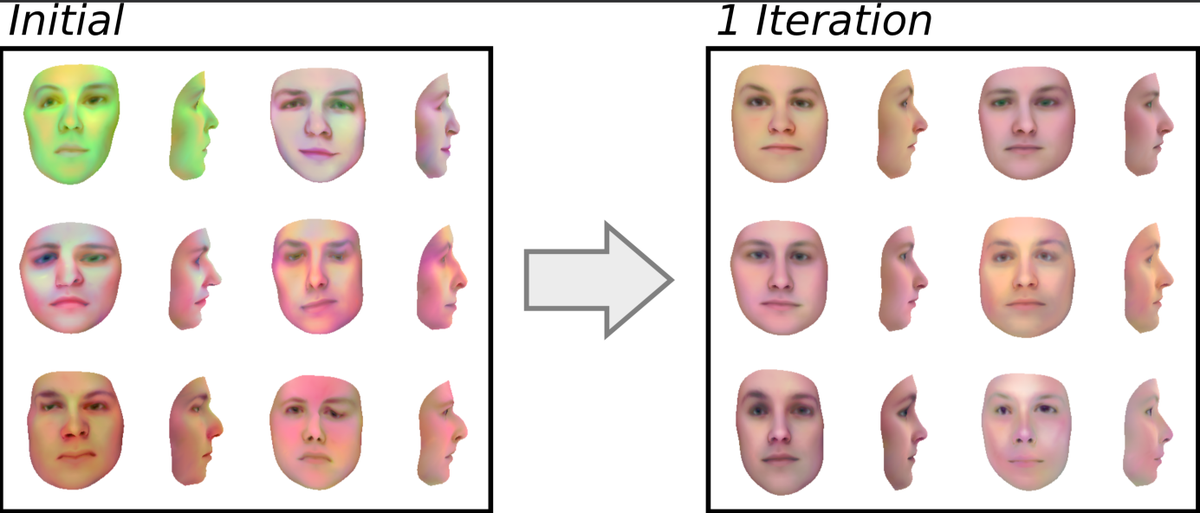

1/ How do we see 3D shape — for grasping, reaching, navigating — when the world is constantly in motion? We started with one piece of this puzzle—how the brain recovers surface geometry from dynamic input. New preprint, a joint effort from Josh Tenenbaum’s and Jim DiCarlo’s labs at MIT. (1/6)
doi.org/10.64898/2026.05.13.…
5
20
76
6,009
CoCoSci MIT retweeted

Feb 23
Today we present a new framework for measuring human-like general intelligence in machines (what some people call AGI).
Conventional AI benchmarks today assess only narrow capabilities in a limited range of human activities.
We propose that a more promising way to evaluate human-like general intelligence in AI systems is through a particularly strong form of general game playing: studying how and how well they play and learn to play all conceivable human games — what we call the ``Multiverse of Human Games''.
Taking a first step towards this vision, we introduce the AI GameStore, a scalable and open-ended platform that uses LLMs with humans-in-the-loop to automatically construct standardized and containerized variants of popular human games on digital gaming platforms.
As a proof of concept, we generated 100 such games based on the top charts of Apple App Store and Steam, and evaluated seven frontier vision-language models (VLMs) on short episodes of play. The best models achieved less than 10% of the human average score on the majority of the games.
Check out our website to play the games, see how agents play, and build agents to solve them!

4
28
114
20,536

5 Nov 2025
Huge congratulations to @LanceYing42 and @xuanalogue on their new EMNLP paper, and invitation to present their work later this week! We’re thrilled to see this exciting work recognized. 👏 #EMNLP2025 #NLP
x.com/xuanalogue/status/1986…
5 Nov 2025

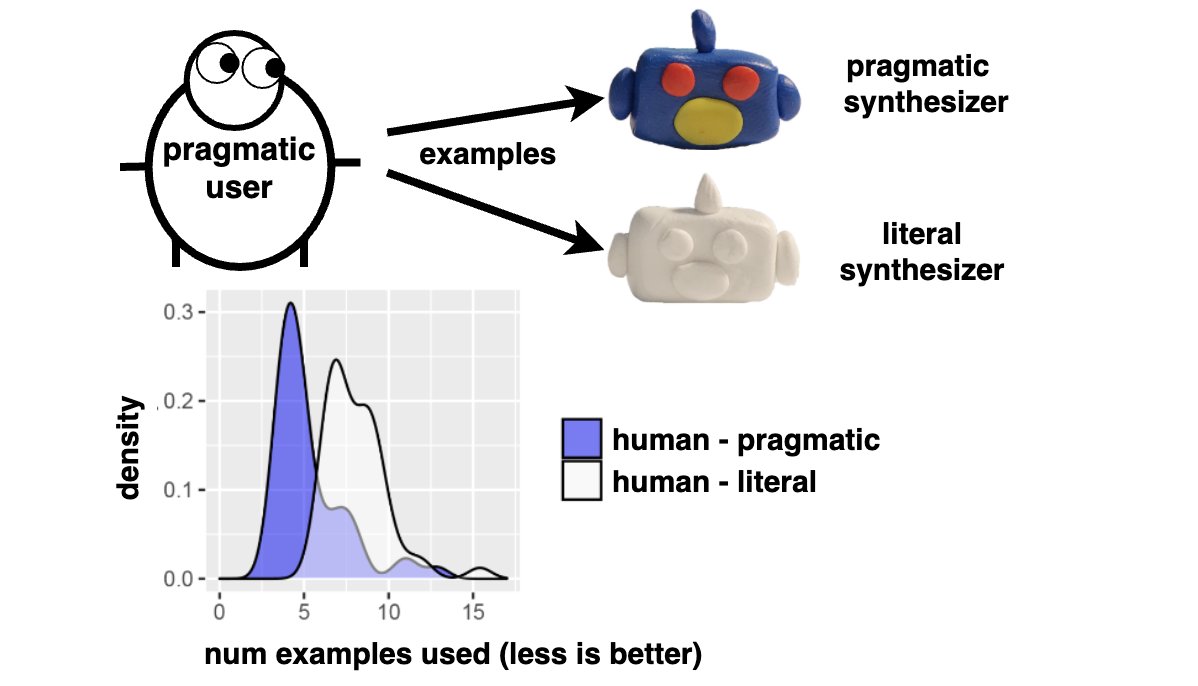
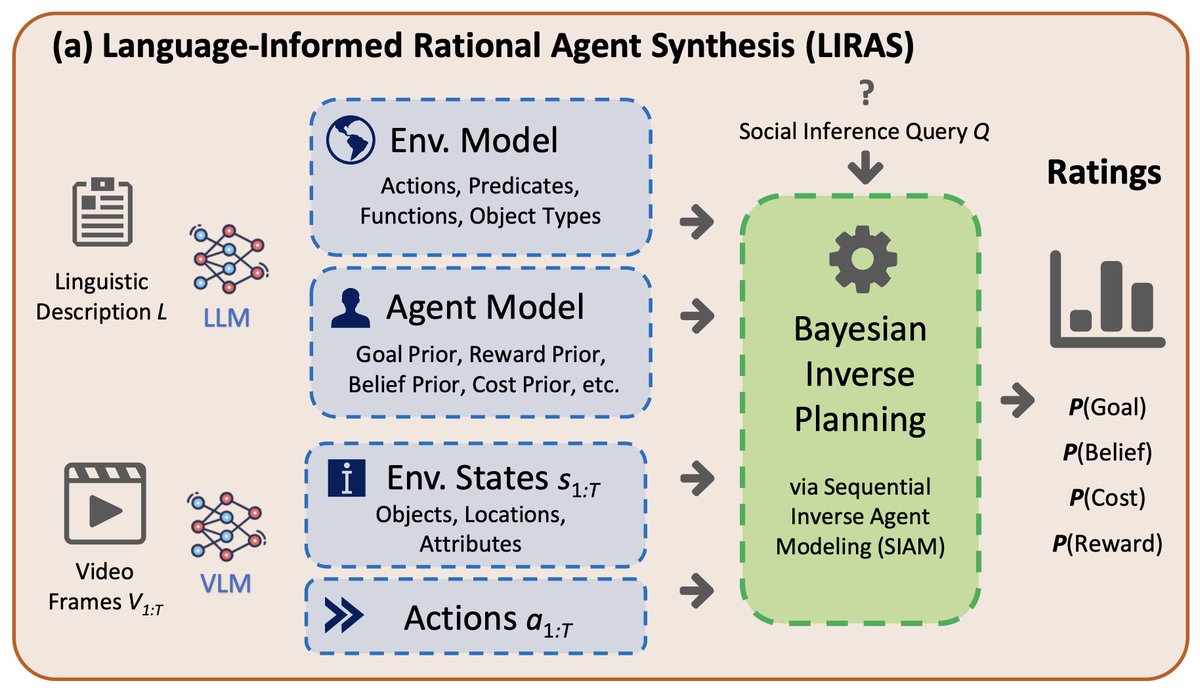
How do people flexibly integrate visual & textual information to draw mental inferences about agents we've never met?
In a new paper led by @LanceYing42, we introduce a cognitive model that achieves this by synthesizing rational agent models on-the-fly--presented at EMNLP 2025!
1
1
11
1,468
CoCoSci MIT retweeted

5 Nov 2025
How do people flexibly integrate visual & textual information to draw mental inferences about agents we've never met?
In a new paper led by @LanceYing42, we introduce a cognitive model that achieves this by synthesizing rational agent models on-the-fly--presented at EMNLP 2025!
4
10
52
6,137
CoCoSci MIT retweeted

22 Jul 2025
How do people reason so flexibly about new problems, bringing to bear globally-relevant knowledge while staying locally-consistent? Can we engineer a system that can synthesize bespoke world models (expressed as probabilistic programs) on-the-fly?

2
23
94
7,713
CoCoSci MIT retweeted

18 Jul 2025
How do people reason while still staying coherent – as if they have an internal ‘world model’ for situations they’ve never encountered? A new paper on open-world cognition (preview at the world models workshop at #ICML2025!)

4
26
147
20,176

Tomorrow, Oct. 8, @fchollet @mikeknoop are bringing ARC Prize live to @MIT in Boston!
Thanks to Prof. Josh Tenenbaum, @mitbrainandcog, @MITCoCoSci, and AI@MIT for making this event possible.
MIT students & staff - register now to get in!
lu.ma/579tcudx
1
9
46
43,277
29 May 2024
Ready to unlock new insights? Join this upcoming workshop and let's learn together!

Hi friends — I'm delighted to announce a new summer workshop on the emerging interface between cognitive science 🧠 and computer graphics 🫖!
We're calling it: COGGRAPH! coggraph.github.io/
June – July 2024, free & open to the public
(all career stages, all disciplines)
🧶

12
2,652
CoCoSci MIT retweeted

17 Apr 2024
I'm deeply honored to receive one of this year's @cogsci_soc Glushko Dissertation Prizes.
While I'm still in a state of disbelief about the award, what I can say in no uncertain terms, is that developing these ideas with @rebecca_saxe has been immensely formative and rewarding.
17 Apr 2024

The Cognitive Science Society is thrilled to announce the winners of the 2024 Glushko Dissertation Prize! 🏆
Let’s meet the brilliant minds behind groundbreaking research in Cognitive Science 🧵👇

ALT Congratulations to the winners of the 2024 Glushko Prize for outstanding dissertation in Cognitive Science.
5
10
82
10,535
21 Dec 2023
We show that Ada *dramatically outperforms* other approaches for using LLMs in planning (including a Voyager-like model!) on two interactive planning benchmarks — Mini Minecraft and ALFRED. We’re excited to try scaling this to harder robotics domains! [4/5]
1
5
33
12,652
21 Dec 2023
Work done jointly with w/ Lio Wong, @maojiayuan, @pratyusha_PS, @siegelz_, @feng_jiahai, Noa Korneev, Josh Tenenbaum, & @jacobandreas
1
1
8
3,202
21 Dec 2023
We use LLMs as *priors* over high-level, symbolic action abstractions that might be useful for collections of related tasks like cooking or game-playing. [2/5]
2
3
25
8,239
21 Dec 2023
Then, we interactively use these abstractions to build concrete plans, in the process learning *which actions are actually useful for solving problems*, and *how to implement them in the environment*. [3/5]
1
3
15
2,968
21 Dec 2023
People don't take a one-size-fits-all approach to planning: we change how we abstract the world to fit our goals.
Our approach, Ada, integrates LLMs formal planning to learn libraries of composable skills adapted to individual planning domains: tdy.lol/BXnzn
🧵 [1/5]

3
44
212
76,736

[publication] "Perception of 3D shape integrates intuitive physics and analysis-by-synthesis"
Research from @MITCoCoSci studying intuitive physics to explain how shape can be inferred from the deformations it causes to other objects, as in cloth draping.
cbmm.mit.edu/publications/pe…

4
20
3,082
CoCoSci MIT retweeted

28 Nov 2023
In a seminal paper by @LakeBrenden @TomerUllman @MITCoCoSci and @gershbrain put forward core domains of intelligence that are easy for people to reason about but difficult for machines. These include intuitive physics, causal reasoning, and intuitive psychology, among others.

1
4
23
2,666
CoCoSci MIT retweeted
22 Nov 2023
There have been tremendous advances at the nexus of AI mathematics. But it’s worth reflecting what our goals are for automated mathematicians. In our brief position piece for the #MathAI workshop @NeurIPSConf, we argue now is a great time to look to CogSci for reflection! 1/

7
93
483
82,257
CoCoSci MIT retweeted

7 Nov 2023
Once upon a time, a mighty sphinx, the Area Chair of Thebes, terrorized all who dared to cross the mountain path into the city. Travelers would be asked the riddle: “How is a photon like a rational agent?” Failure to answer resulted in an immediate desk reject. #NeurIPS2023
1
6
31
5,974
CoCoSci MIT retweeted

31 Oct 2023
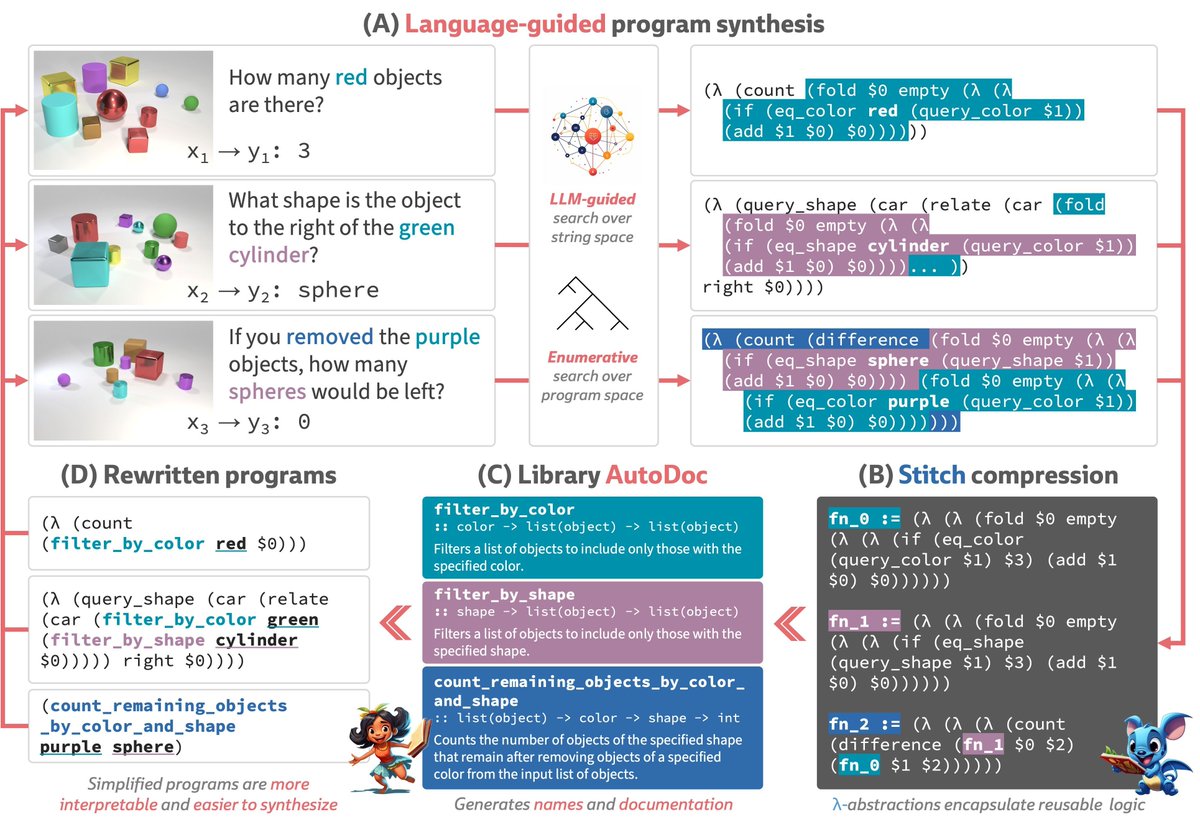
What if we equipped LLMs with cutting-edge code refactoring tools? 🤖🛠
Presenting LILO: Library Induction with Language Observations
📝 arxiv.org/abs/2310.19791
💻 github.com/gabegrand/lilo
Lio Wong, @mattlbowers, @theo_olausson, Muxin Liu, Josh Tenenbaum & @jacobandreas️
🧵⬇️
1
47
194
46,969