
Joined October 2020
- Tweets 5,462
- Following 362
- Followers 2,159
- Likes 2,196
1,640 Photos and videos










Devansh: chocolate milk cult leader retweeted

Jun 12
Your Retirement Account Is About to Buy SpaceX. Nobody Asked You
How index providers rewrote their rulebooks in 90 days to force $14 trillion in passive savings into the largest low-float IPO ever
by @Machine01776819 medium.com/p/your-retirement…
1
1
3
367

How Elon Musk Found is about to Steal from Your 401(k) open.substack.com/pub/artifi…
@elonmusk
1
2
40
Devansh: chocolate milk cult leader retweeted

Jun 9
I don't really want to have to go to bat against Anthropic, but they've just been unnecessarily antagonistic to all of China, then not so subtly to open weight models, and now more broadly open AI research. What's next on the list?
111
138
2,453
147,577
How to Deploy AI Projects That Create Business Value open.substack.com/pub/artifi…
1
38
Stateful Swarms: How Persistent Memory Beats Traditional Agent Architectures open.substack.com/pub/artifi…
57
If you want to understand if your job is safe from AI, you need to grasp James Wang's concept of bounded variation.
Bounded variation describes tasks that involve rearranging known patterns and structures within familiar contexts—precisely where AI excels. AI automates jobs or tasks with clearly defined rules, stable patterns, and limited novelty.
However, tasks demanding genuine creativity, nuanced judgment, and the ability to handle situations that don't neatly fit prior examples—tasks outside the bounds of routine variation—remain resistant to AI automation. Roles that depend on spotting subtle errors, navigating uncertain scenarios, or requiring deep domain-specific insights stay valuable.
This framework clarifies the real divide in an AI-driven world: Not users vs. non-users. Not tech vs. non-tech.
It's pattern-followers vs. pattern-makers.
To thrive in this age, find where your expertise truly escapes easy compression and focus intensely there.
I unpacked exactly how to identify your AI-resistant edge here:
artificialintelligencemadesi…
1
66
How to Thrive in the Age of AI open.substack.com/pub/artifi…
How to Thrive in the Age of AI
Why You Should Read: James Wang.
artificialintelligencemadesimple.com 1
52
How to perform Data Collection & Labeling in 2026, by @Machine01776819 open.substack.com/pub/coding…
1
97
Devansh: chocolate milk cult leader retweeted
May 22
The title of "open-source champion" for any country is earned by working with the community rather than mandated by raising money
5
12
208
24,909
Devansh: chocolate milk cult leader retweeted
1
1
99
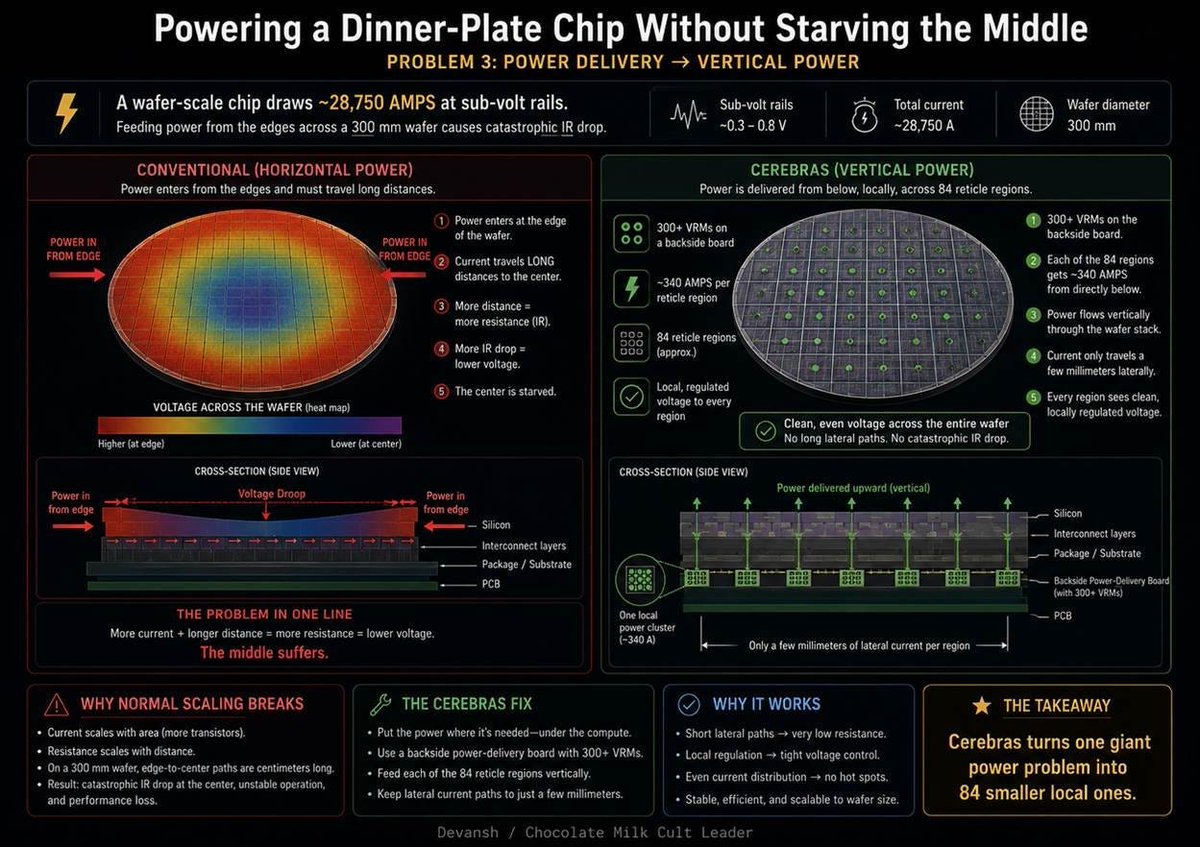
Meet @cerebras , the 66 Billion Dollar IPO out to challenge NVIDIA. artificialintelligencemadesi…
An H100 executes 989 trillion floating-point operations per second. During LLM decode, the chip uses less than 1% of that capacity. The math units sit idle because the weights can't arrive from memory fast enough.
This in a nutshell, is why Cerebras exists.
To produce a single output token, the chip must read essentially every weight in the model from memory, multiply those weights once, and move on. The arithmetic intensity collapses to roughly 1 FLOP per byte. The H100's architecture balances compute and memory bandwidth at 295 FLOPs per byte. Anything below that ratio is bandwidth-bound, and decode is 295x below it. You could weld another GPU to the first one and decode wouldn't get faster.
The obvious fix is to put the memory next to the compute. Engineers have tried this for forty years. Gene Amdahl raised $230 million in 1980 and a prototype shorted and glowed red during a demo. ETA Systems built a liquid-nitrogen-cooled wafer-scale supercomputer — the silicon worked, customers couldn't maintain the nitrogen plumbing. Tesla proved modern wafer-scale packaging works with Dojo, then Musk shut it down because the narrow workload couldn't justify maintaining a custom software stack against CUDA.
Cerebras looked at all of this and decided to try anyway. They kept an entire 300mm silicon wafer intact — no dicing — stitched 84 reticle exposures into one continuous chip, embedded 44GB of SRAM next to 900,000 compute cores, solved the power delivery problem by pushing current vertically through the back of the wafer, and invented a floating connector that absorbs 150-190 microns of thermal expansion mismatch per cycle without cracking.
The result: 0.168 bytes per FLOP versus the H100's 0.0034. A 50x advantage in feeding data to math units during decode. Llama 3 70B at 2,100 tokens per second versus 30-50 on a single H100.
I spent about two months researching this — the semiconductor physics, the five constraints that killed every prior attempt, the first-principles bandwidth math, the OpenAI contract economics (they imply negative 81% gross margin per system on the baseline tenant), and the software ecosystem that currently supports exactly four models.
Full investigation here: artificialintelligencemadesi…
Whether Cerebras survives depends on whether the market window stays open long enough for wafer-scale silicon to outrun the incumbents it forced into action. But the physics is not a debate. The incumbents already conceded the point — NVIDIA bought Groq for $20 billion, Google bifurcated its TPU line, AWS is pairing Cerebras wafers with Trainium for disaggregated inference. Someone is going to capture the value of fixing decode. The question is who.
Drop your thoughts below.
1
196
Fine-tuning is expensive, heavy, and often breaks more than it fixes. Activation Steering promised a surgical alternative, but in production, it usually leaks probability into generic hallucinations.
The reason? A geometric "type error."
We treat AI models like flat maps, but Softmax warps that terrain. My latest deep dive breaks down the Information Geometry of Softmax and how "Dual Steering" fixes the probability leak:
-)The Euclidean Illusion: Why adding vectors in the residual stream causes "probability leakage" into random prepositions.
-)The Two-Map System: Understanding the Primal (freedom) and Dual (cage) coordinate systems.
-)AND vs. OR Logic: Why standard steering crushes unique traits while Dual Steering preserves the union of concepts.
-)The Fix: Why you can't "add a thermometer to a room"—and how to properly apply probes in dual space.
Unlocking the math of knowledge representation is the path to efficient, precise control.
Read the full breakdown: artificialintelligencemadesi…
2
129
A good friend of mine is hosting this event. Y'all might find it interesting to go to (I'll be there as well, lmk if you want to come say hi).
On May 16, 2026, Silsila Sounds invites you to DRAUPADI, a staged reading of an original play that redefines myth through queer and trans perspectives. Blending Bharatanatyam, experimental theater, and original music, this production reimagines Draupadi—not as a victim, but as a mirror to society’s contradictions. Set against the backdrop of the 1906 Ahmedabad textile strikes, the play centers a Hijra and Siddi worker navigating revolution, identity, and divine acceptance.
Showtimes: 3:00 PM (Matinee): A focused performance of the staged reading, preceded by a Bharatanatyam piece,
7:00 PM (Full Experience): Dance performance staged reading a post-show panel on intersectional art creation, labor history, and collective storytelling.
Accessibility: 3-flight walk-up venue. Masks encouraged.
Triggers: Mild violence, transphobia.
Tickets: 3 PM Show | 7 PM Show Panel
Website: silsilasounds.org | IG: @silsilasounds
1
1
122
Devansh: chocolate milk cult leader retweeted

Apr 29
Proactive agent that thinks and acts like you.
Multiplayer AI Brain for teams.
Proper GUI for commanding 50 agents.
Sauna.ai is all three. Sauna goes live today. First 2000 people, use access code LAUNCH for $80 of weekly(!) credits.
Let’s explain. Multiplayer only works once the personal brain is powerful. So let's start here.
Personal AI Brain
3,800 tools connected. State of the Art memory. Skills and schedules you teach once that get repeated forever on cheaper models. An AI first CRM.
Lives on the cloud so you can initiate tasks from anywhere: iMessage, Slack, Email. Also no need for a Mac mini 😉
GUI
AI agents have been stuck in their MS-DOS era. A chat box, a scroll buffer, no way to command 50 of them. We built the first GUI: Live sessions on one side, work waiting for your sign-off on the other, plus the things Sauna kicked off while you were asleep waiting for review. Game mode helps clear the queue with actual joy.
Okay so far so good, but how to give benefit of what you built to more people or whole team?
Multiplayer
Once your Sauna actually knows you and you gave her access to your tools, you can use multiplayer.
Two modes:
- Brain access. My co-founder Robert plugged my brain as a tool into his Sauna last month. He can ask it about pricing while I'm in other meetings, gets a sourced answer back, never has to interrupt me. That’s read only. Yolo mode gives him access to all my tools too :O
- Communal Saunas extend that to whole companies with proper permissioning. Folder owners decide what's true for the whole company and build skills. Most get their personal brain read access to communal files and memories. Works also for group planning my best friend's bachelor party.
The Way
I’ve been obsessed about AI Brain since 2016. Our human brains suck at some things like memory and are brilliant at others like creativity. We are also particularly bad at thinking we are all on the same page and then realising weeks later that we weren’t. Most leaders spend their days being the human diff tool, catching contradictions in hallway conversations and Slack threads. Repeating themselves 50 times. Now every company is spinning up hundreds or thousands of agents that drift faster than humans do, feeding each other their drift as context. Compounding rot.
After 10 years and one failed company in this space we are launching the solution.
The Launch
We thought about a celebrity launch. Margot Robbie in a bathtub explaining agents. But then we realised the same money gives the first 2,000 people free daily credits, every day, until we burn through that $1,000,000.
Sauna runs Claude, GPT-5, Gemini, GLM-5.1, DeepSeek, Kimi so you can budget yourself. The labs are racing to lock you so they can milk you in a year. We picked your side.
Onboarding
It’s live at app.sauna.ai We’ve preheated saunas based on a niche. Use the access codes in the comments to get a better experience.
101
56
609
780,254