
Photos and videos

Magick is finally in a state where we can build things like BabyAGI within an hour. You can watch the graph executing in real time, watch the thought process as it executes, and understand the flow. This is unbelievably cool.
10 Jan 2024

BabyAGI in Magick. I'll work on a better video soon walking through the graph. But so stoked that Magick is finally in a state where I can do this. And this is only the beginning.
22
8
45
9,647
We have been quiet for a while. We have been heads down building something new. We are building an Agent framework, with our Magick IDE fully open sourced at the core of it. We invite you to join in and let us know what would be most useful!
github.com/Oneirocom/Magick/…
12
2
16
4,441
Amazing work coming down the pipeline. This makes it all worth it.
21 Jun 2024

What I’m building with @MagickML for @Safe_Sats will soon blow your mind.
I doubt anyone is ready yet.
5
4
12
4,701
We have been excited about this for a long time, and we finally have them back in V2. Sub-spells. Vastly improved and better than ever. In this case, we brought in the amazing design pattern created by @unity with the subgraphs in visual scripting.
4 Jun 2024
We have sub-spells. Nested graphs are coming to Magick.
The next step will be sub-spells as tools. The socket inputs and outputs on the sub-spell are given descriptions, and we can transform them into tool schemas. Then we parse and call the sub-spell, returning the result.
This is going to open up all kinds of possibilities.
2
8
3,135
MagickML retweeted

4 Jun 2024
We have sub-spells. Nested graphs are coming to Magick.
The next step will be sub-spells as tools. The socket inputs and outputs on the sub-spell are given descriptions, and we can transform them into tool schemas. Then we parse and call the sub-spell, returning the result.
This is going to open up all kinds of possibilities.
2
8
4,652
We just pushed out a major update to Magick. We integrated @keywordsai as our LLM proxy, providing our users with over a hundred models to use. We have improved stability for large graphs, with UI performance working at well over 300 nodes. We will be announcing more very soon.
1
3
11
1,303

OpenAI is expected to demo a real-time voice assistant tomorrow. What does it take to deliver an immersive, or even magical experience?
Almost all voice AI go through 3 stages:
1. Speech recognition or "ASR": audio -> text1, think Whisper;
2. LLM that plans what to say next: text1 -> text2;
3. Speech synthesis or "TTS": text2 -> audio, think ElevenLabs or VALL-E.
Last year, I made the figure below to show how to make Siri/Alexa 10x better. However, naively going through 3 stages results in huge latency. User experience falls off the cliff if we have to wait 5 seconds for *each* reply. It breaks the immersion and feels lifeless even if the synthesized audio itself sounds real.
Natural dialogues fundamentally don't work like this. We humans
> think about what to say next at the same time as we listen & speak;
> inject "yes, hmm, huh" at appropriate moments;
> predict when the other person finishes and immediately take over;
> decide to talk over the other person organically, without being offensive;
> handle interruptions gracefully. Currently, AI assistants either cannot be interrupted (super frustrating) or simply stop when they detect an audio event and lose train of thought;
> engage in group chat. We are so good at multi-agent conversations.
It's not as simple as making each of the 3 neural nets faster, sequentially. Solving real-time dialogue requires us to rethink the whole stack, overlap each component as much as possible, and learn how to make interventions in real time.
Or perhaps even better - just have 1 NN mapping audio to audio. End-to-end always wins.
I'll sketch out how to design such a model and its training pipeline. Meanwhile, let's wait and see how far OpenAI pushes it!

128
517
3,209
727,916
MagickML retweeted

9 May 2024
Check out our brand-new course on Building Agentic RAG with LlamaIndex with @DeepLearningAI @AndrewYNg 🔥
Learn how to build an autonomous research assistant that can answer complex questions over multiple documents - handle a much broader range of inputs than a standard RAG pipeline! 📖🕵️
The course helps you learn how to build an agent ingredient by ingredient from a standard RAG pipeline. Once you're done with the course check out the following @llama_index resources to take your agents to the next level 👇
Building a custom agent: docs.llamaindex.ai/en/stable…
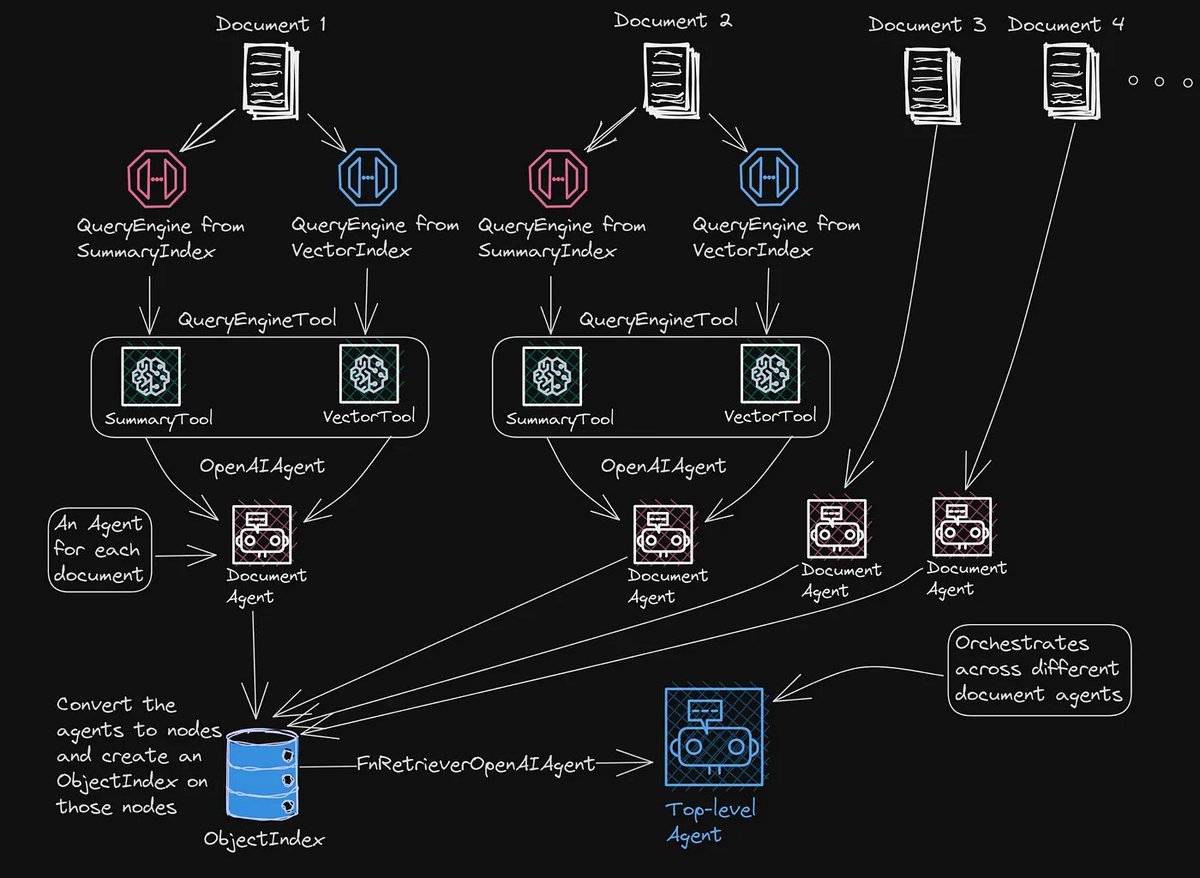
Multi-document agents (diagram by @clusteredbytes): docs.llamaindex.ai/en/stable…
Course: deeplearning.ai/short-course…
8 May 2024

I’m excited to kick off the first of our short courses focused on agents, starting with Building Agentic RAG with LlamaIndex, taught by @jerryjliu0, CEO of @llama_index.
This covers an important shift in RAG (retrieval augmented generation), in which rather than having the developer write explicit routines to retrieve information to feed into the LLM context, we instead build a RAG agent that that has access to tools for retrieving information. This lets the agent decide what information to fetch, and enables it to answer more complex questions using multi-step reasoning.
In detail, you'll learn about:
- Routing: Where your agent will use decision-making to route requests to multiple tools.
- Tool Use: Where you'll create an interface for agents to select what tool (function call) to use as well as generate the right arguments.
- Multi-step reasoning with tool use: Where you'll use an LLM to carry out multiple steps of reasoning, while retaining memory throughout the process.
You’ll also learn how to step through what your agent is doing to debug and improve it iteratively.
It’s an exciting time to build agents. Sign up and get started here! deeplearning.ai/short-course…
5
79
418
48,313
MagickML retweeted
8 May 2024
Another small UX improvement. Hiding unused sockets. It isn't a full node collapse, which I want to do next, but that will have to wait. In demo crunch time.
1
3
640
MagickML retweeted
8 May 2024
I love adding these little UX improvements that make my experience building way better. Renaming a nodes title goes a long way to legibility. Even more so possibly than comments.
1
4
452
MagickML retweeted
3 May 2024
I have just decided that I love multi-gates. I find this incredibly satisfying. Using this in the demo I am working on, and will have to document this.
1
5
423

We have docs! :D
docs.magickml.com
1
1
4
439
New things coming down the pipeline.
1 May 2024
Another dev log since it has been a while. I did some work under the hood on the runtime engine underneath Magick. These changes have allowed me to run a dedicated engine instance per spell and finally implement the "on tick" event. The Magick Engine runs similarly to a game engine at 30FPS. You can tie into this runtime using the on-tick event which is called once per frame.
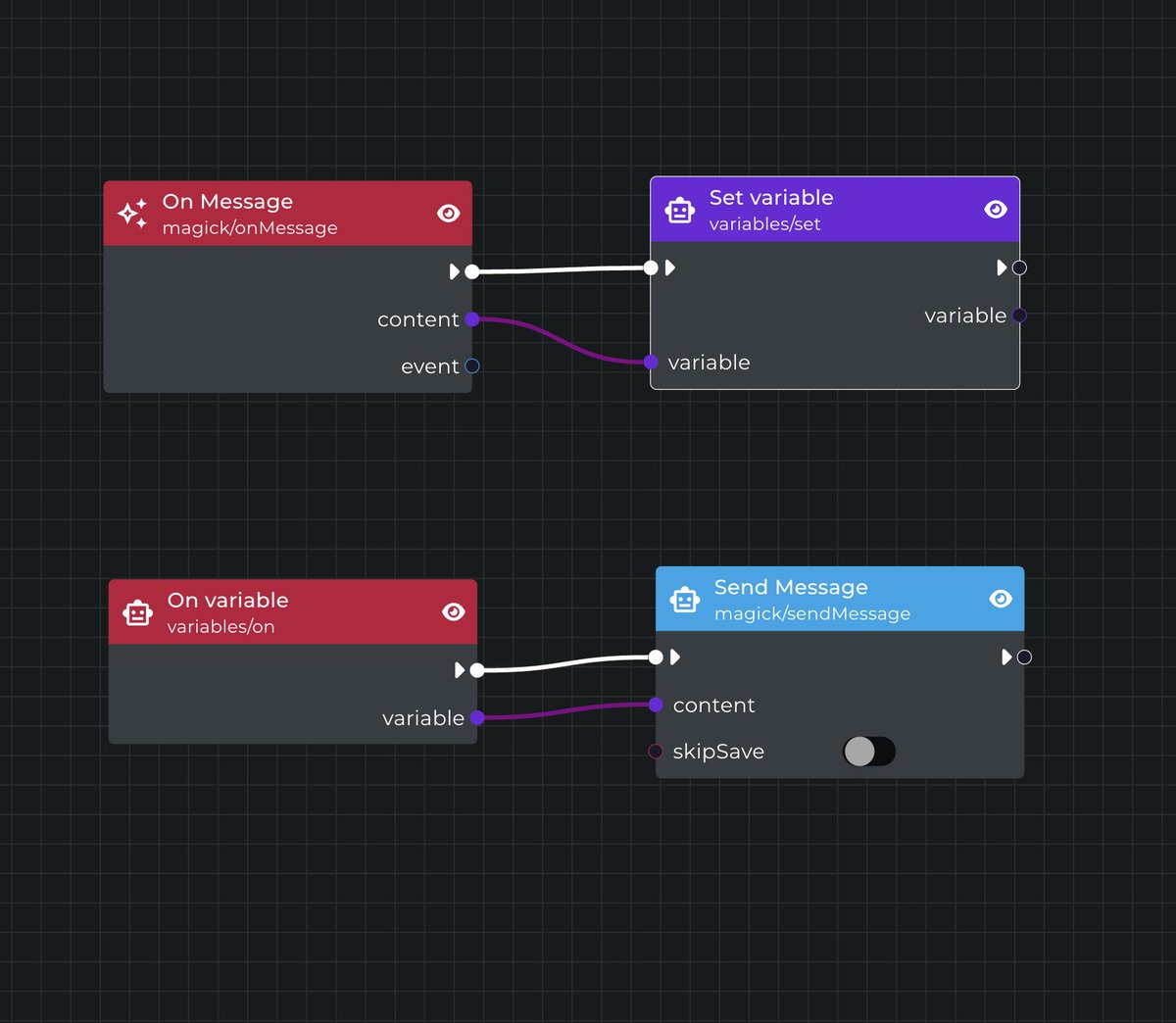
This lets us do some pretty wild stuff. This first test was simply seeing if I could shuttle a message from the onMessage event over to the core loop using a basic string variable. However, we could likely use an array variable for this and create a simple queue system.
Under the hood, these changes to the engine essentially mean that different event channels can have dedicated engines running on them continuously. I previously underestimated the power and performance of a single engine as an even processor and so missed out on these possibilities.
Now that the functionality is there, I will be starting to implement more complex systems with an ongoing cognitive loop designed to process and think.
I have some ideas next to experiment with as well to make some improvements to my original BabyAGI implementation in Magick to create different looping processors for tasks and queues.
2
383
MagickML retweeted

4 Apr 2024
Been talking lots about knowledge graphs and LLMs, specifically for autonomous agents, recently.
Organized some thought here if you want to dig in 👇
KG 🤝 LLM
🧵 (a thread)
28
97
751
196,997
The most epic AI panel in a while! We at NVIDIA have gathered ALL 8 authors of "Attention is All You Need" for a panel at GTC, hosted by none other than the GOAT himself, Jensen Huang.
In 2017, 8 researchers had a flash of genius and invented Transformer, the seminal work that transformed AI once and for all.
How did they come up with the idea?
What challenges did they face?
What surprised them in the following years?
What have they been up to these days?
How do they envision a post-transformer future?
Thanks @maggie_albrecht for making this happen! I'm so glad to play a part in reaching out to some of the coauthors.
Join us for a behind-the-scenes look at modern AI's greatest moment. Mar. 20, 11 am PDT, at San Jose McEnery Convention Center, NVIDIA GTC: nvidia.com/gtc/session-catal…

55
249
1,614
189,710
MagickML retweeted

3 Feb 2024
Brad Templeton asks if it is a copyright violation to recite a poem or song because you have a copy of it in your brain
21
14
97
7,461