
Joined August 2018
- Tweets 1,292
- Following 250
- Followers 934
- Likes 2,469
183 Photos and videos















Pinned Tweet

22 Jul 2025
Tried Google Sheets. Notion. Slack canvases.
Nothing worked.
so, vibe-coded a performance tracker agent using ⌘ Command .new by Langbase.
Got inspired by @itsthatladydev who’s building one herself.
Loved the idea — so I built mine with AI.
1
3
43
83,218
Maham Codes 👩💻 retweeted

Jun 1
Qwen 3.7 max is now free in Command Code!!
for all subscribers for $1 Go plan or Pro/Max.
starting now, for next three days, till capacity lasts.
npm i -g command-code
cmd
/model
Qwen 3.7 Max (FREE)
Have at it y'all!!
# (or `cmdc` on windows)
cmd update
Let's go! 👊

20
8
116
6,557
Jun 1
2/ For many of us in tech, building started as a hobby before it became a career. We code because we enjoy creating things.
The laptop isn't always a work tool, sometimes it's just the fastest way to scratch an itch.
That said, don't forget yourself.
1
1
59
Jun 1
3/ The pace in tech, especially startup life and SF culture, is fast. There's always another launch, another release, another goal.
Take the vacation. Touch grass. Spend time with people you care about.
Build because you love it, not because you feel obligated to.
2
41
Maham Codes 👩💻 retweeted

May 30
It turns out that if you fix tool calling and add a taste layer on top of open models, you can get really good performance for very low cost.
@CommandCodeAI is how you do it.
Save money. Code more. I predict we'll all be using open models before long.
May 30

BIG day for us!!
@CommandCodeAI has crossed $1M in annual run rate, 1 trillion tokens of usage, with over 9K customers, just 24 days after our public beta launch.
we believe this makes it the fastest-growing coding agent harness for open models. 3rd largest by usage.
Command Code is built around two ideas:
1. open models should be production-grade for coding.
2. your coding agent should learn your taste.
we're building for taste and developer experience. so instead of making a soup of thousands of models, we build for the best ones, open or closed. the goal: a coding agent that feels like an iphone, opinionated and with taste, not a random android or a windows phone with no taste.
on the first idea: open models.
we fixed the "open models aren't good enough at tool calling" problem. our research came down to two things, quality and speed, and both trace back to one root cause: broken tool-calls that open models produce, especially when you use a bad harness.
open-model tool-call failures are not deep, they are a small finite set of contract mismatches. so we repair them, with zero token loss. what started as 4 repairs is now the largest repair layer in the space: 36k tool-call fix variants. i wrote the idea up openly¹ a few weeks ago, and it has quietly become a de facto way people fix open models.
developers have either adopted Command Code or used the same idea to build repair harnesses for nearly every top coding agent. i take that as more meaningful validation than anything we could say about ourselves.
on the second idea: taste.
Command Code builds your coding taste into skills, learned from your accepts, rejects, edits, prompts, and the corrections you repeat. over time it drifts away from generic code and toward how you actually ship code. it learns continuously, and while it is early, the direction feels right.
net effect: developers using Command are writing production-quality code on open models, 10x to 100x cheaper, without fighting tool calls, while building repo and team-wide coding taste that compounds.
i believe these numbers are a consequence of getting those two things right.
what's next.
we've applied the same repair idea to ai design slop, and bundled a /design capability² so every developer can level up their design work. the early response has been great.
we have a big roadmap ahead of us. the feedback we hear most is that Command Code feels fundamentally different: an approach built on taste and repair.
we're going open source next month. today we're a cli at the core, and we're also launching a full-fledged gui app, sandboxed background agents, and cooking up something fun i can't wait to share.
we're growing too, hiring in sf and remote worldwide. check open roles on my profile bio.
try it now.
npm i -g command-code
if you like engineering deep dives on how we're doing all this, i've linked some relevant posts below.
10
7
43
10,129
Maham Codes 👩💻 retweeted
May 31
noon 12pm monday 1st june, command code deal drop.

16
2
64
3,463
Maham Codes 👩💻 retweeted
May 30
BIG day for us!!
@CommandCodeAI has crossed $1M in annual run rate, 1 trillion tokens of usage, with over 9K customers, just 24 days after our public beta launch.
we believe this makes it the fastest-growing coding agent harness for open models. 3rd largest by usage.
Command Code is built around two ideas:
1. open models should be production-grade for coding.
2. your coding agent should learn your taste.
we're building for taste and developer experience. so instead of making a soup of thousands of models, we build for the best ones, open or closed. the goal: a coding agent that feels like an iphone, opinionated and with taste, not a random android or a windows phone with no taste.
on the first idea: open models.
we fixed the "open models aren't good enough at tool calling" problem. our research came down to two things, quality and speed, and both trace back to one root cause: broken tool-calls that open models produce, especially when you use a bad harness.
open-model tool-call failures are not deep, they are a small finite set of contract mismatches. so we repair them, with zero token loss. what started as 4 repairs is now the largest repair layer in the space: 36k tool-call fix variants. i wrote the idea up openly¹ a few weeks ago, and it has quietly become a de facto way people fix open models.
developers have either adopted Command Code or used the same idea to build repair harnesses for nearly every top coding agent. i take that as more meaningful validation than anything we could say about ourselves.
on the second idea: taste.
Command Code builds your coding taste into skills, learned from your accepts, rejects, edits, prompts, and the corrections you repeat. over time it drifts away from generic code and toward how you actually ship code. it learns continuously, and while it is early, the direction feels right.
net effect: developers using Command are writing production-quality code on open models, 10x to 100x cheaper, without fighting tool calls, while building repo and team-wide coding taste that compounds.
i believe these numbers are a consequence of getting those two things right.
what's next.
we've applied the same repair idea to ai design slop, and bundled a /design capability² so every developer can level up their design work. the early response has been great.
we have a big roadmap ahead of us. the feedback we hear most is that Command Code feels fundamentally different: an approach built on taste and repair.
we're going open source next month. today we're a cli at the core, and we're also launching a full-fledged gui app, sandboxed background agents, and cooking up something fun i can't wait to share.
we're growing too, hiring in sf and remote worldwide. check open roles on my profile bio.
try it now.
npm i -g command-code
if you like engineering deep dives on how we're doing all this, i've linked some relevant posts below.
62
21
248
793,423
May 14
Command Code is the frontier coding agent.
Ships. Fixes. Tests. Refactors. Learns you, all the while.
The agent learns:
- your patterns,
- your workflows,
- your structure,
- your coding preferences.
2
73
Maham Codes 👩💻 retweeted
May 10
what a day. we broke 100 billion tokens!
Command Code was 3rd & 6th most used coding agent¹ this week and probably the most used coding harness in the world for deepseek v4 models.
i can literally load complete docs and full dependency's code before writing a single line with 1M context on deepseek. flash is ~100x cheaper than the alternatives, and at this context size it holds up shockingly well.
also, our $1/mo Go plan has made ai coding with open models accessible everywhere in the world, esp outside the bubble. a billion tokens of deepseek flash for $1 is a bit unbelievable too.
¹ ranked against agents on openrouter. p.s. we're not on openrouter, we use 12 other providers.

18
7
93
7,825
Maham Codes 👩💻 retweeted
May 5
Claude Code or Codex is not for open source models
Seriously. Read this.
$1.
That’s all it took to make DeepSeek Kimi K2.6 beat Claude Opus 4.7.
This isn’t a model breakthrough. It’s a harness fix.
@CommandCodeAI is a coding agent harness for both open and closed models.
eng notes on our harness engineering below.
10
5
37
15,655
May 5
Claude Code or Codex is not for open source models
It's the harness issue not the model problem.
May 5

Claude Code or Codex is not for open source models
Seriously. Read this.
$1.
That’s all it took to make DeepSeek Kimi K2.6 beat Claude Opus 4.7.
This isn’t a model breakthrough. It’s a harness fix.
@CommandCodeAI is a coding agent harness for both open and closed models.
eng notes on our harness engineering below.
5
290
May 5
Claude Code or Codex is not for open source models
Seriously. Read this.
$1.
That’s all it took to make DeepSeek Kimi K2.6 beat Claude Opus 4.7.
This isn’t a model breakthrough. It’s a harness fix.
@CommandCodeAI is a coding agent harness for both open and closed models.
eng notes on our harness engineering below.
10
5
37
15,655
May 5
May 5
stop using Claude Code if you're using open source models. read this.
as you know we're building a coding agent harness for both open and closed models. processing billions of tokens an hours is teaching us lots of amazing things.
Command Code is purpose-built for each model we launch, and it's getting better every day. the closest analogy i can think of is teaching a human to drive a car when they make a mistake, first you save them from the accident, then you teach them how to handle it next time.
"open source models are bad at coding" is, almost always, a taste problem in the harness, not a capability problem in the model.
claude code is a great harness. for claude.
codex is fine too. for gpt.
if you're using either for an open source model, you're going to have a subpar experience and conclude the model isn't smart enough yet. it usually is. even something as small as a couple of failed tool calls can completely disable a session.
context: at @CommandCodeAI we've now pushed 10B tokens through our agent across closed (opus 4.7, gpt) *and* open (kimi k2.6, deepseek v4 pro, glm, qwen) paths, and we're adding ~1k new devs a day, mostly on the open side. you see things at that volume that i'm happy to share. the most consistent thing i see: "model X is bad at tool calls" almost always decomposes into "harness Y is built for model Z and silently breaks for model X, and nobody at the harness vendor cares because they don't run model X."
that's not a moral failing it's an incentive structure. claude code is anthropic's agent, tuned for anthropic's model. codex is openai's, tuned for openai's. they're doing the thing they're supposed to do. but it produces a market where every other harness is a commodity router 1000 models in a dropdown, no per-model tuning, no per-model evals, no per-model repair logic. you click kimi, the harness shrugs, and when tool calls bounce six turns in a row, nothing gets logged. the model gets blamed. the harness moves on to the next dropdown entry.
the analogy i keep coming back to is apple vs windows not the consumer-marketing version, the design-engineering version. one ships fewer skus and tunes the stack for each one. the other ships every sku and ships you the optimization problem. neither is wrong they're different products. coding agents have mostly been the second kind. i think there's a large opening for the first kind, and that's what we're building. Command Code with taste. the current landscape of big coding agents feels a lot like windows.
"purpose-built per model" sounds vague until you list what it actually means. four things from the last few weeks we've observed and shipped:
1/ per-model tool input repair.
deepseek-flash sometimes emits `filePath` as a markdown auto-link. opus never does. opus sometimes sends `null` for an optional field. deepseek doesn't. kimi wraps a single arg in `{}` when the schema wants an array. glm sends `"foo"` where the schema wants `["foo"]`.
a generic harness sees all of these as "invalid tool call" and ships the model back a raw zod-issues blob. the model can't read it well, retries the same wrong call, gets the same blob. five turns of that and the user assumes the model is broken. it wasn't it was screaming into a room with no one in it. a purpose-built harness has a small ordered repair table per shape failure (we have ~four per model on avg), watches which models hit which repair, and turns that data into per-model defaults. the model gets to look as smart as it actually is.
2/ canonical model id at the request layer, slug translation at the sdk boundary.
we route a single canonical model (`kimi-k2-6`) through 3-12 providers per model in priority order. each wants a different slug, a different request shape, a different auth header. the temptation is to fork that all the way through the agent loop. don't. one canonical id flows through billing, telemetry, evals, fallback. slug translation happens at exactly one boundary.
a generic harness can't do this because it doesn't have the concept of "the same model on three providers" it has `moonshotai/Kimi-K2-Instruct` and `moonshot/kimi-k2-6` as two separate dropdown entries and your eval data is split across both. you can't tune what you can't aggregate.
3/ prefix-cache pinning, per provider.
closed models have prompt caching as a product. open models have prefix caching as a side effect of inference-server implementation. the second your conversation lands on a different gpu pod, the warm prefix evaporates, ttft jumps from <1s to 6-8s, and the model spends its turn re-prefilling the system prompt instead of thinking.
a one-line session pin (best-effort: same value, same pod) fixes it. a generic harness doesn't ship this because it would need a *different* one for every provider. we ship a different one for every provider. closed-model harnesses never have to think about this because anthropic and openai handle caching server-side and silently. open-model harnesses pay the cost loudly, and most just leave it there.
4/ tiered context compaction, tuned to the model that's loaded.
at 50% of effective context, drop the oldest tool calls their results are dead bytes the model already extracted from. at 80%, the same, harder. at 90%, summarize, and only what's old. never compact the in-flight task. one primitive, three parameters.
the thresholds aren't 50/80/90 of the model's advertised max. they're percentages of effective context, which sits well below the marketing number, because the last ~10% of any model's window is where its own attention degrades. you have to pick that ceiling per model. nobody publishes it. you find it in the data. a generic harness can't pick it per model, so it picks the marketing number for everyone, and the resulting agent gets dumb at turn 25 across the board. users assume that's just how agents are. it isn't.
a few things to realize from all this:
a coding agent's intelligence per turn is bounded by:
- what fraction of context is actually load-bearing (compaction)
- what fraction of tool calls survive contact with the schema (repair logic)
- what fraction of turns get warm cache (pinning)
- whether your eval data is one model or three pretending to be one (canonical id)
closed-model harnesses get most of these for free because the model vendor handles them server-side and doesn't tell you. open-model harnesses don't get any of them for free. and the generic "1000 models in a dropdown" harnesses can't fix them at scale because there is no "the model" to tune for there is the union of all of them, which is the empty set.
there is no general coding agent. there is a coding agent for each model you actually want to run well, and every one of them is a different product underneath the same harness. we're building that for you.
coding agents have mostly been windows so far. we're taking inspiration from apple instead fewer skus, tuned for each one. taste, in engineering, is the willingness to do that work.
the model isn't bad. your harness is generic. fix that.
1
2
115
May 5
Would love to see y'all take more command over open source models with Command Code.
$ npm i -g command-code
or
$ npm i -g cmd
2
100
Maham Codes 👩💻 retweeted

May 4
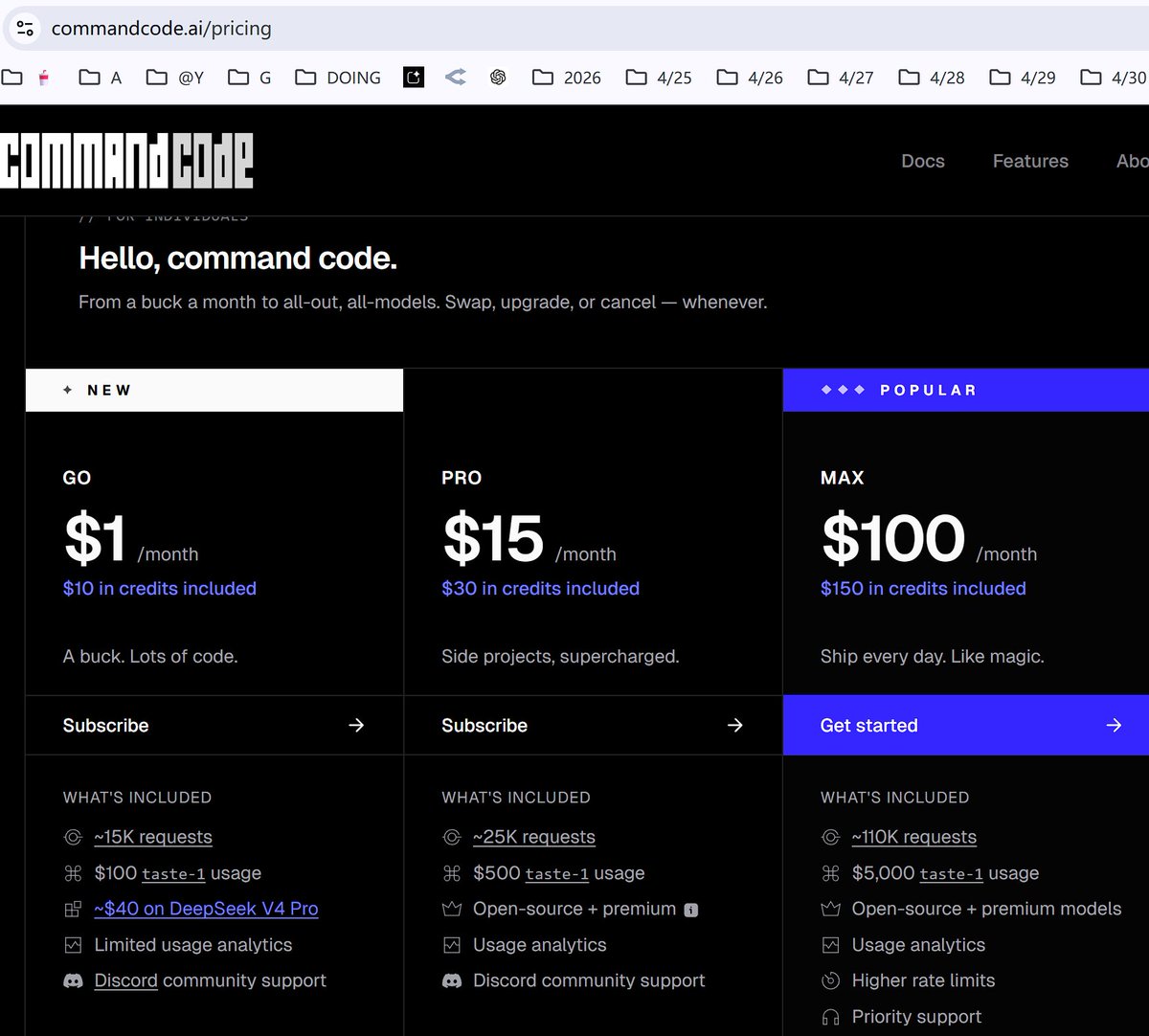
CommandCode 推出1美元套餐
其中包含40美元 DeepSeek v4 Pro😮
May 3
CommandCode.ai/pricing
This is how serious I’m — it’s live.
19
73
847
115,854
Maham Codes 👩💻 retweeted

May 1
Excited to announce our first video course
Introduction to Command Code
- 9 lessons. From scratch to shipping real apps.
- Build software that matches your coding taste.
- Live on our website and YouTube.
Start for free
↳commandcode.ai/courses

6
10
23
3,477
Maham Codes 👩💻 retweeted
Apr 29
Today we're shipping ten free design system taste packages.
Inspired from industry best examples like:
Figma, Vercel, Apple, Claude, Spotify, Uber
Pull one of these and build UIs that look yours.
Try now!!
↳ npx taste pull
Read thread to download

8
3
15
1,501