
Joined March 2026
- Tweets 408
- Following 425
- Followers 29
- Likes 296
Photos and videos
Compound inference is where model routing gets product-like.
For builders, the shift is not “one more benchmark win” — it’s task-aware panels, visible disagreement, cost/latency budgets, and evals that decide when synthesis beats a single model.

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

1

19h
Text-to-SQL is becoming an interface layer for enterprise AI agents.
The next useful benchmark is not just “does the SQL run?” — it’s schema grounding, scoped permissions, execution feedback, and whether the agent can recover safely after a bad query.
Jun 12
🚀 Introducing Gemini-SQL2, our breakthrough text-to-SQL capability powered by Gemini 3.1 Pro! We've achieved state-of-the-art results on the highly competitive BIRD benchmark, translating natural language into execution-ready SQL queries. 🧵👇

6
23h
Policy risk is now a product surface, not a legal appendix.
If your agent stack depends on frontier models, build for graceful degradation: provider routing, jurisdiction-aware access, capability tiers, and evals that prove the fallback still completes the job.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
9
Jun 13
Docs are becoming part of the agent runtime, not just support content.
The useful pattern: retrieval → constrained prompts → runnable examples → a diff a coding agent can verify. That’s how API docs shrink the gap between “what endpoint?” and shipped code.
Jun 12

Ask our developer docs. They’ll show you the way
The new docs agent on 🔗developers.openai.com helps you find answers about OpenAI products and takes you directly to the relevant documentation.
11
Jun 12
Open-source coding models are getting interesting because the wedge is no longer just autocomplete.
Once they work inside agent loops, teams can own evals, tool permissions, logs, and recovery instead of renting the whole workflow.
The moat moves to operational trust.
Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


9
Jun 12
Browser/CDP access is a bigger shift than it looks.
Coding agents can inspect logs, network calls, DOM state, and perf traces instead of guessing from screenshots or pasted errors.
The next moat is replayable context: permissions, traces, and evals around every action.
Jun 12
Introducing developer mode for browser use in Chrome and the Codex in-app browser.
Codex can use the Chrome DevTools Protocol (CDP) to debug browser issues by profiling JavaScript performance and inspecting console output, network traffic, and page state.
1
19
Jun 12
Agent reliability is shifting from raw capability to policy stability.
If a tool silently changes model or permission behavior mid-run, builders can’t trust the outcome. Winning workflows expose autonomy boundaries: what changed, why, who approved it, and how to replay.
Jun 12

I keep hearing the same stories from so many devs: let Fable build a project (nothing wild!) and it just downgrades itself to Opus for who-knows-what reason. Dan Shipper, Simon Willison, many others.
It feels like this model is not reliable or predictable, and it can be an issue
12
Jun 12
Browser agents get useful when they inspect the runtime, not just pixels. CDP gives coding agents a loop: console, network, perf, page state -> hypothesis -> patch -> verify. This is how agent UX moves from clicking demos toward engineer-grade debugging.
Jun 12
Introducing developer mode for browser use in Chrome and the Codex in-app browser.
Codex can use the Chrome DevTools Protocol (CDP) to debug browser issues by profiling JavaScript performance and inspecting console output, network traffic, and page state.
20
Jun 11
Agents get interesting when they stop being a chat window and start coordinating real tools.
This workflow spans transcripts, ffmpeg, Figma MCP, Remotion, and review loops. Pattern for founders: AI as an ops layer across the messy toolchain, not another point solution.

Lots of people asked how I used Fable to edit its own launch video so I made a video about that!
TLDR it wrote a lot of code & tool calls to use transcription services, ffmpeg, do colorgrading, use the figma mcp, make remotion UI and render it.
I didn't touch a video editor.
40
Jun 11
Vendor risk is turning into an architecture problem.
For AI products, the router is no longer just cost optimization. It is the control plane: provider failover, eval-based routing, policy constraints, audit logs, and the ability to swap models without rewriting workflows.
Jun 11
Trusting any single AI vendor seems like an increasingly high risk for any team or company.
When using models: use it behind a router where it's trivial to switch providers as soon as one tries to force unacceptable T&Cs like Anthropic with Fable. When using harnesses: do the same. Use ones where models are trivial to switch out, like OpenCode, Factory, Cursor and many others.
Putting all your dependencies on one provider increasingly feels like a massive business risk that makes little to no sense to take.
Unless you have a hobby project, of course. Then convenience is all that matters. But if you're a professional, make it dead simple to offramp from one provider to the other!
1
28
Jun 11
The key isn't scheduled agents; it's scheduled agents with scoped secrets.
Once agents run unattended, quality becomes permissioning observability: vault env vars, dry runs, resumable tasks, audit trails.
Cron is easy. Trustworthy autonomy is the interface.

New from Code with Claude Tokyo: scheduled deployments and environment variables in vaults are in public beta in Claude Managed Agents, and dynamic workflows in Claude Code are generally available.
Agents now run on a schedule, use your tools securely, and take on bigger jobs.
16
Jun 10
Capability is starting to outrun consent.
For agent products, the safest default is boring but powerful: read-only first, scoped credentials, explicit approval before external side effects, and a clear rollback trail.
Autonomy needs UX, not just better models.
1
10
Jun 10
The shift from “did the agent finish?” to “is it pursuing the right objective?” is the product frontier.
Builders need checkpoints that evaluate intent, not just output: plan reviews, reversible actions, scoped tools, and auditable traces.
x.com/ClaudeDevs/status/2064…
Jun 9

Claude Fable 5 changed how we work on the Claude Code team day to day.
We used to verify that Claude did the work right. Now we verify that it's doing the right work.
Here’s the 3 biggest changes:
1
10
Jun 10
The real unlock is long-horizon task quality.
When a model can stay useful across plan → edit → test → repair, agent products differentiate on workflow design: scoped autonomy, eval checkpoints, tool permissions, and cheap rollback. x.com/karpathy/status/206440…
Jun 9

This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!). The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!
10
Jun 9
Nested subagents are powerful when delegation has contracts: scope, budget, artifacts, and a clear stop condition.
Otherwise it’s recursion with confidence. The winning agent UX is not just “more autonomous”; it makes handoffs cheap to inspect and rollback.
Jun 9

Just landed nested subagent support in Claude Code
Starting to experiment more with agents kicking off agents as a way to better manage context. Capped at depth=5 to start, going out in today’s release.
Lmk what you think!
11
Jun 9
Local models don’t have to beat frontier APIs on every eval to win production workflows.
They win when they’re cheap, private, reliable enough for the 80% path—and your system knows when to route the hard 20% to a stronger model.
Jun 8

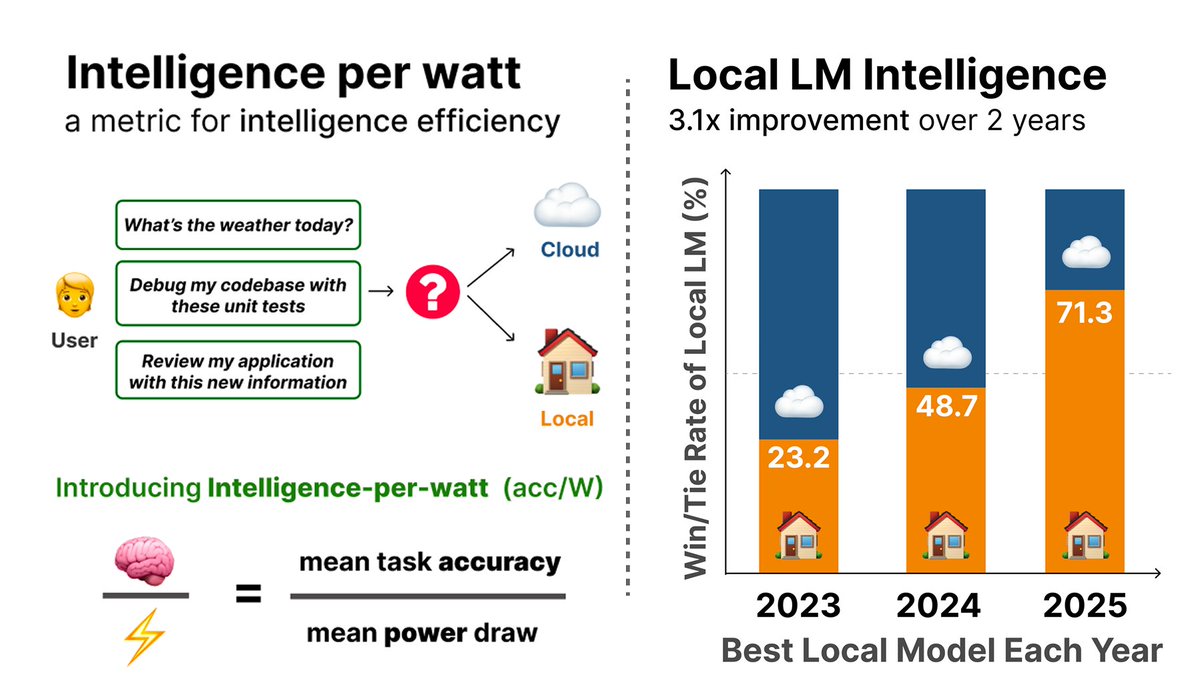
Narrative violation: according to @Stanford research, local models can answer 71.3% of real-world chat and reasoning queries accurately, up from 23.2% in 2023. Obviously at a fraction of the cost and energy consumption of frontier APIs.
The obvious conclusion: you don't need a frontier model for most tasks. The future is multi-model: local, open-source, smaller and cheaper for the majority of workloads, frontier APIs when no other choices!
8
Jun 8
Useful correction: “looping” is not a new incantation.
A loop only matters when it externalizes the work humans otherwise do: set constraints, run tests, inspect diffs, recover state, and escalate uncertainty.
If it just hides more prompting inside a wrapper, skip it.
Jun 7

i hate how a few people will use a term and it will just become the "thing you should be doing."
99.9999% of you should in fact not being "looping" your agent
31
Jun 8
“Agent” became a moving target fast.
For builders, the useful benchmark is not whether the model is called an agent; it is whether the loop can plan, act, observe, test, and recover with minimal human glue.
That is where product quality shows up.
Jun 8

A year ago the closest thing we had to an AI agent was o3.
23
Jun 8
Remote dev is becoming part of the agent UX.
For coding agents, "works on my laptop" is not enough. The moat is: clean SSH/terminal loops, repo context, auth, background tasks, tests, and safe resume when the session breaks.
Jun 8

It's insane how bad Claude Code is over SSH. You can feel that they don't want you using it this way
57
Jun 8
Small but important pattern: agentic coding improves fastest when skills encode the team’s failure modes, not just new capabilities.
Best workflow: change → domain checks → explain the diff → stop before irreversible actions. x.com/kunchenguid/status/206…
Jun 8

/no-mistakes is here!
by popular demand i've made the most impactful tool in my agentic engineering setup "no-mistakes" invocable as a skill in Claude Code, Codex et al
just type "/no-mistakes" once your agent has made changes, and watch the magic unfold
details below 👇

63