
Joined August 2020
- Tweets 85
- Following 2,749
- Followers 348
- Likes 853
3 Photos and videos


Pinned Tweet

17 Oct 2024
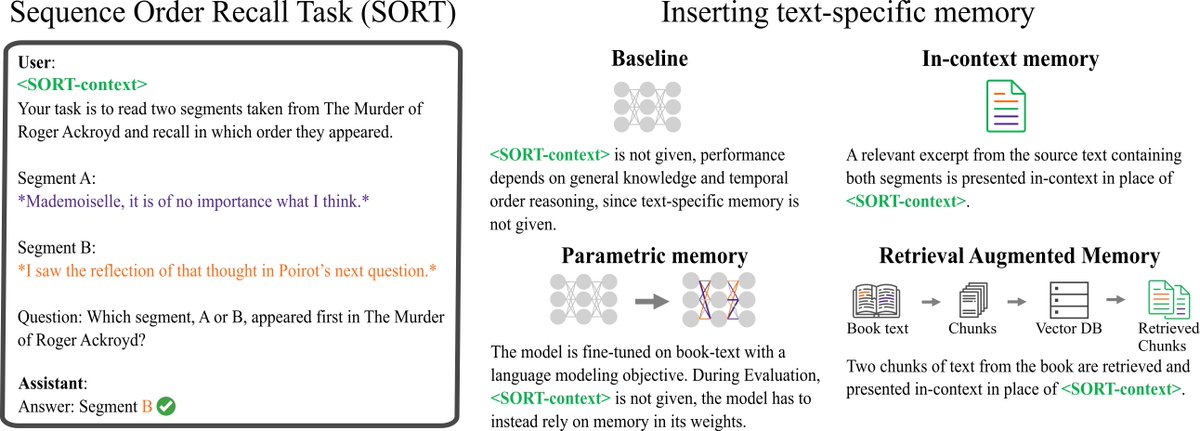
1/n🤖🧠 New paper alert!📢 In "Assessing Episodic Memory in LLMs with Sequence Order Recall Tasks" (arxiv.org/abs/2410.08133) we introduce SORT as the first method to evaluate episodic memory in large language models. Read on to find out what we discovered!🧵
4
16
61
7,266
Mathis Pink retweeted
How can generative AI better support human creativity, without limiting it?
If you have thoughts, we invite submissions to our ICML workshop on Generative AI, Creativity, and Human-AI Co-Creation (@creativeai_ws)
📍 July 2026, Seoul
📄 Submit by: April 24 (AOE)
⏬ (1/2)
3
17
79
9,479
Mathis Pink retweeted

12 Nov 2025
📢 I'm recruiting PhD students at MPI!!
Topics include:
1⃣ LLM factuality, reliable info synthesis and reasoning, personalization applications in real-world inc. education, science
2⃣ Data-centric interpretability
3⃣Creativity in AI, esp scientific applications 🧵1/2

ALT Kaiserslautern city
10
112
479
95,405
Mathis Pink retweeted

8 Jul 2025
Exciting new preprint from the lab: “Adopting a human developmental visual diet yields robust, shape-based AI vision”. A most wonderful case where brain inspiration massively improved AI solutions.
Work with @lu_zejin @martisamuser and Radoslaw Cichy
arxiv.org/abs/2507.03168
5
49
143
17,504
Mathis Pink retweeted

10 Jun 2025
🚨Excited to share our latest work published at Interspeech 2025: “Brain-tuned Speech Models Better Reflect Speech Processing Stages in the Brain”! 🧠🎧
arxiv.org/abs/2506.03832
W/ @mtoneva1
We fine-tuned speech models directly with brain fMRI data, making them more brain-like.🧵
1
4
29
1,821
Mathis Pink retweeted

18 Apr 2025
We will be presenting this 💫 spotlight 💫 paper at #ICLR2025. Come say hi or DM me if you're interested in discussing AI #interpretability in Singapore!
📆 Poster Session 4 (#530)
🕰️ Fri 25 Apr. 3:00-5:30 PM
📝 openreview.net/forum?id=Qogc…
📊 iclr.cc/virtual/2025/poster/…
6
27
208
16,265
Mathis Pink retweeted

26 Jan 2023
Excited to share our new preprint bit.ly/402EYEb with @mtoneva1, @ptoncompmemlab, and @manojneuro), in which we ask if GPT-3 (a large language model) can segment narratives into meaningful events similarly to humans. We use an unconventional approach: ⬇️
2
29
93
20,608
Mathis Pink retweeted

19 Dec 2024
A few interesting challenges in extending context windows.
A model with a big prompt =/= "infinite context" in my mind. 10M tokens of context is not exactly on the path to infinite context.
Instead, it requires a streaming model that has
- an efficient state with fast incremental state updates
- strong compression & abstraction of multimodal history
- effective at reasoning over state to generate future action
(The model needs to be able to run forever.)
I dislike the phrase "infinite context" as a matter of taste, since it suggests an extension of the retrieval based paradigm where you reason over context windows in order to answer a query. That's not quite what's going on.
Instead, memory is about building useful abstraction over histories. It's nice to think of it as a state with a choice of method for storing/updating information -- this is more in line with a model that always runs and streams in information. Transformers / SSMs are just different ways to choose how to model the state and update it. There are more abstractions left to uncover.
There are also new data regimes and training algorithms required to produce these kind of long-term memory models. Interaction is a core part of the way these models operate.
We don't seem to have the right evals that measure useful proxies that are in line with this notion of memory. Ideally, it's not just about being able to remember facts -- the model should get better at retaining skills (compound knowledge), and learning new skills over time (learning to learn faster).
This is a very interesting direction that I'm personally super excited to be working on.
19 Dec 2024

Sam Altman: 10m context window in months, infinite context within several years
2
10
83
10,611
Mathis Pink retweeted

17 Dec 2024
Anyway, glad to see that the whole "let's just pretrain a bigger LLM" paradigm is dead. Model size is stagnating or even decreasing, while researchers are now looking at the right problems -- either test-time training or neurosymbolic approaches like test-time search, program synthesis, and symbolic tool use.
8
33
504
38,136
14 Dec 2024
x.com/MathisPink/status/1846… We think this is because LLMs do not have parametric episodic memory (as opposed to semantic memory)! We recently created SORT, a new benchmark task that tests temporal order memory in LLMs
14 Dec 2024

An LLM knows every work of Shakespeare but can’t say which it read first. In this material sense a model hasn’t read at all.
To read is to think. Only at inference is there space for serendipitous inspiration, which is why LLMs have so little of it to show for all they’ve seen.
4
320
Mathis Pink retweeted

10 Nov 2024
Consider the prompt X="Describe a beautiful house."
We can consider two processes to generate the answer Y:
(A) sample P(Y | X) or,
(B) sample an image Z with a conditional image density model P(Z | X) and then sample P(Y | Z).
1/3
5
3
62
12,974
Mathis Pink retweeted
17 Oct 2024
4/n💡We find that fine-tuning or RAG do not support episodic memory capabilities well (yet). In-context presentation supports some episodic memory capabilities but at high costs and insufficient length-generalization, making it a bad candidate for episodic memory!
1
1
4
4,338
Mathis Pink retweeted
24 Oct 2024
We are so excited to share the first work that demonstrates consistent downstream improvements for language tasks after fine-tuning with brain data!!
Improving semantic understanding in speech language models via brain-tuning
arxiv.org/abs/2410.09230
W/ @dklakow, @mtoneva1

3
8
62
11,422
17 Oct 2024
1/n🤖🧠 New paper alert!📢 In "Assessing Episodic Memory in LLMs with Sequence Order Recall Tasks" (arxiv.org/abs/2410.08133) we introduce SORT as the first method to evaluate episodic memory in large language models. Read on to find out what we discovered!🧵
4
16
61
7,266
17 Oct 2024
11/n SORT is the product of joint work together with @vvobot, @moon91007207, Jianing Mu, @javiturek, Uri Hasson, Ken Norman, @s_michelmann, @alex_ander and @mtoneva1
1
290
17 Oct 2024
12/n Check out our full paper, SORT evaluation code to test your own models, and Book-SORT dataset on 🤗-datasets:
Paper: arxiv.org/abs/2410.08133
Code: github.com/bridge-ai-neuro/S…
Book-SORT: huggingface.co/datasets/mema…
1
270