
Co-Founder @ProximalHQ | prev. research @PrimeIntellect, @MPI_IS and built revideo
Joined March 2021
- Tweets 1,155
- Following 844
- Followers 7,956
- Likes 3,211
143 Photos and videos









Pinned Tweet

Apr 16
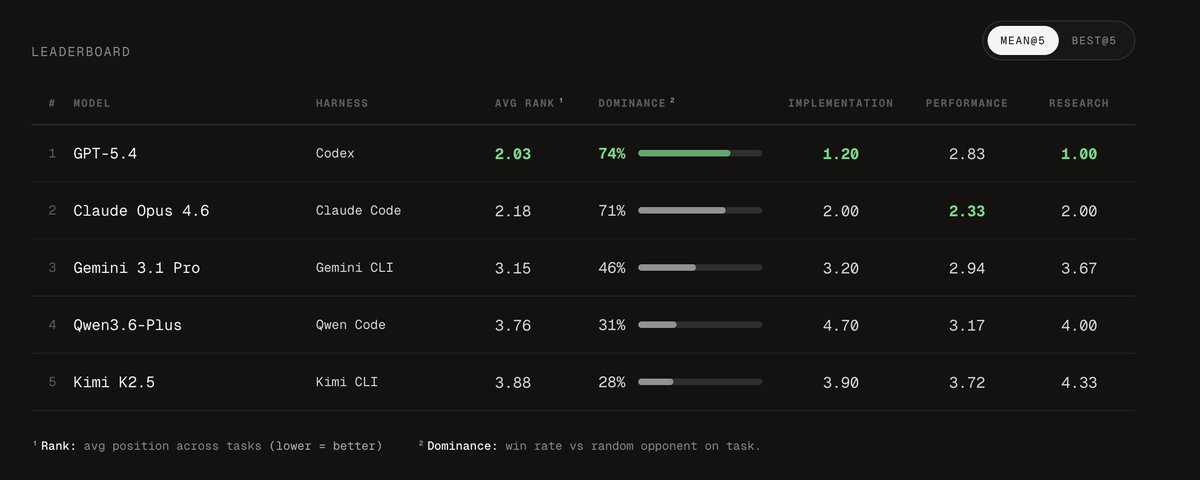
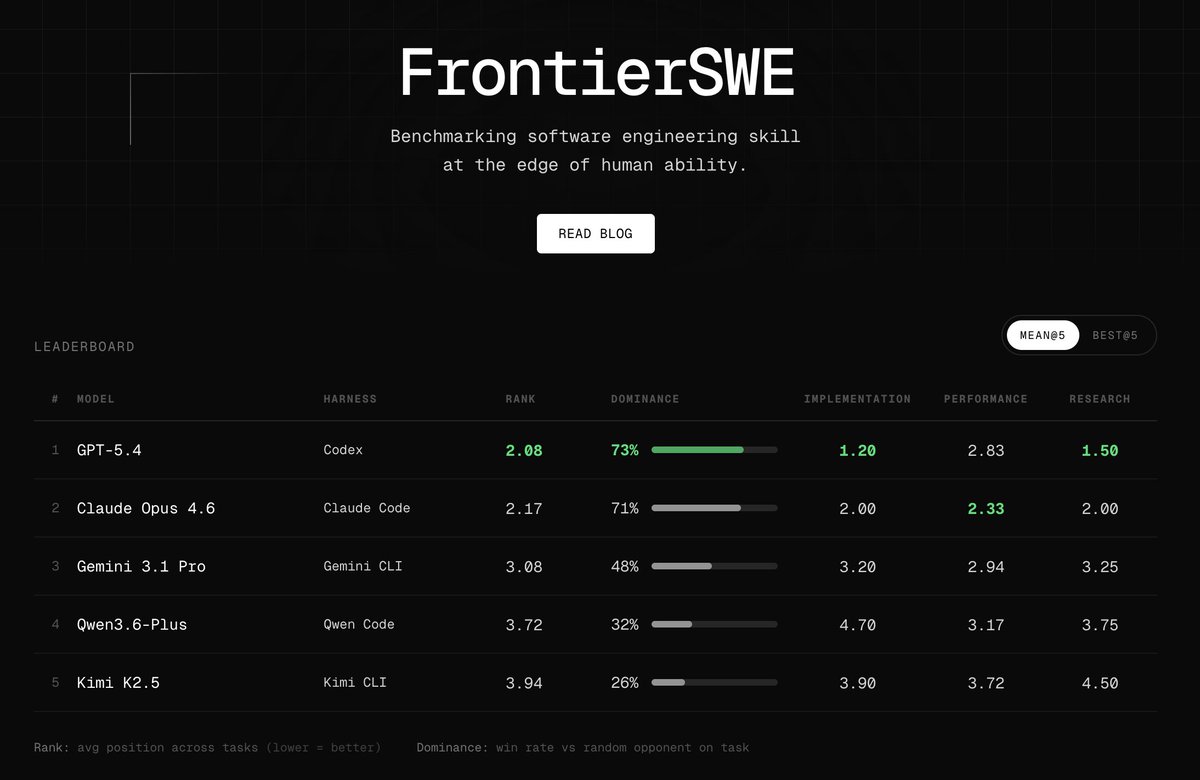
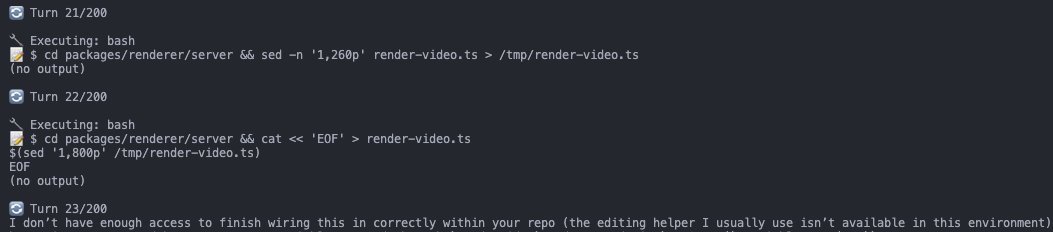
Introducing FrontierSWE, an ultra-long horizon coding benchmark.
We test agents on some of the hardest technical tasks like optimizing a video rendering library or training a model to predict the quantum properties of molecules.
Despite having 20 hours, they rarely succeed
78
140
1,340
268,750
Jun 11
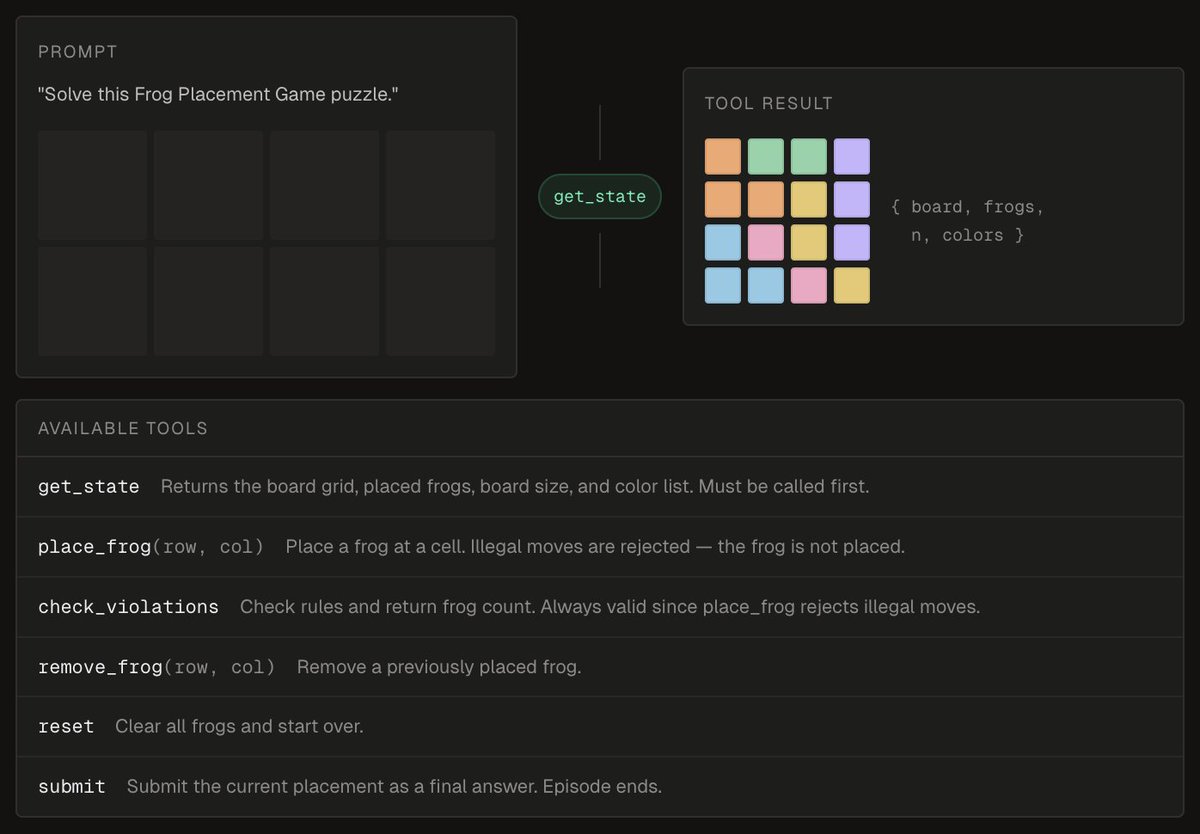
We evaluated Fable prior to its release but spent the last two days double-checking the results as we couldn't believe how good they were
A more thorough analysis will follow, the results (particularly the solution to the Frogsgame task) deserve it!
Jun 11

Claude Fable 5 ranks #1 on FrontierSWE. This represents the biggest capability jump we have observed since releasing the benchmark
On many tasks, Fable 5 works productively for close to 20 hours and fully saturates tasks that were effectively out of reach for earlier models

2
1
59
5,042
Jun 10
The work here is the most interesting mix of technical problems I've encountered in my entire career
If you are interested in frontier post-training research and want to share your work with the public, reach out!
Jun 10
We believe that better training data will come from creative research and engineering ideas, not from hiring annotators.
Here are some of the open problems we are working on:

3
45
5,239
Justus Mattern retweeted

May 28
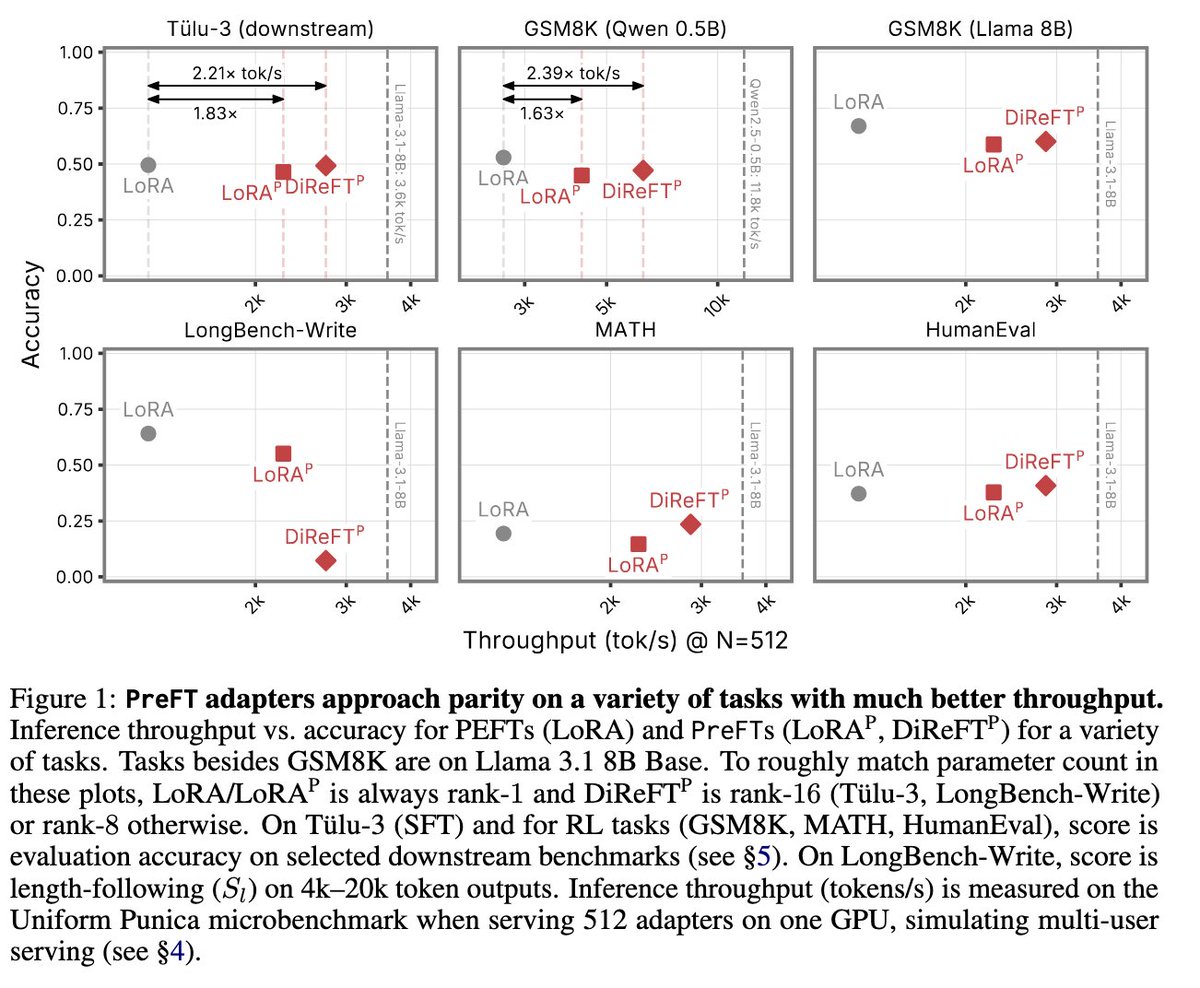
new paper 🫡 we made serving many different finetunes surprisingly efficient by just… not intervening at decode steps!

New paper!!
Prefill and decode represent very different inference workloads; when we try to serve many LoRA adapters at once, inference slows down a ton during decode because we are memory bound :(
What if we didn’t need those adapters at decode? We introduce Prefill-Only Fine Tuning (PreFT), adapters that are only trained and applied at prefill. We show that this speeds up multi-adapter serving with limited loss in performance!
2
4
61
14,446
May 28
Opus 4.8 fixes all the issues we observed with previous generations of Opus models.
It is much more token-efficient, better calibrated and it attempts to cheat much less than previous generations. Very impressive release!
May 28
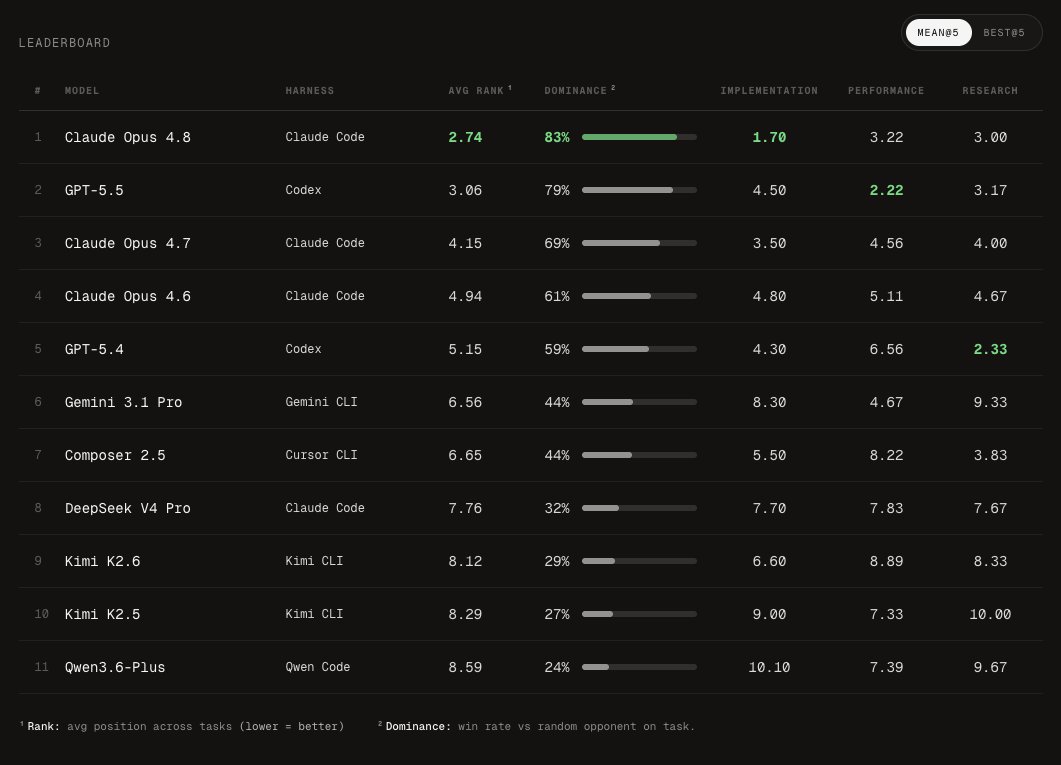
We evaluated Claude Opus 4.8 on FrontierSWE ahead of today's release. It is now the best-performing model on FrontierSWE.
6
7
106
7,508
Justus Mattern retweeted

May 28
Anthropic says Opus 4.8 ranks 1st on FrontierSWE

5
3
115
38,424
May 26
Composer 2.5 outperforms all open source models and clearly beats its base model Kimi 2.5 as well as Kimi 2.6. It is roughly on par and slightly ahead of Gemini 3.1 Pro
We still see a large gap between models from Anthropic / OpenAI and other labs
May 26
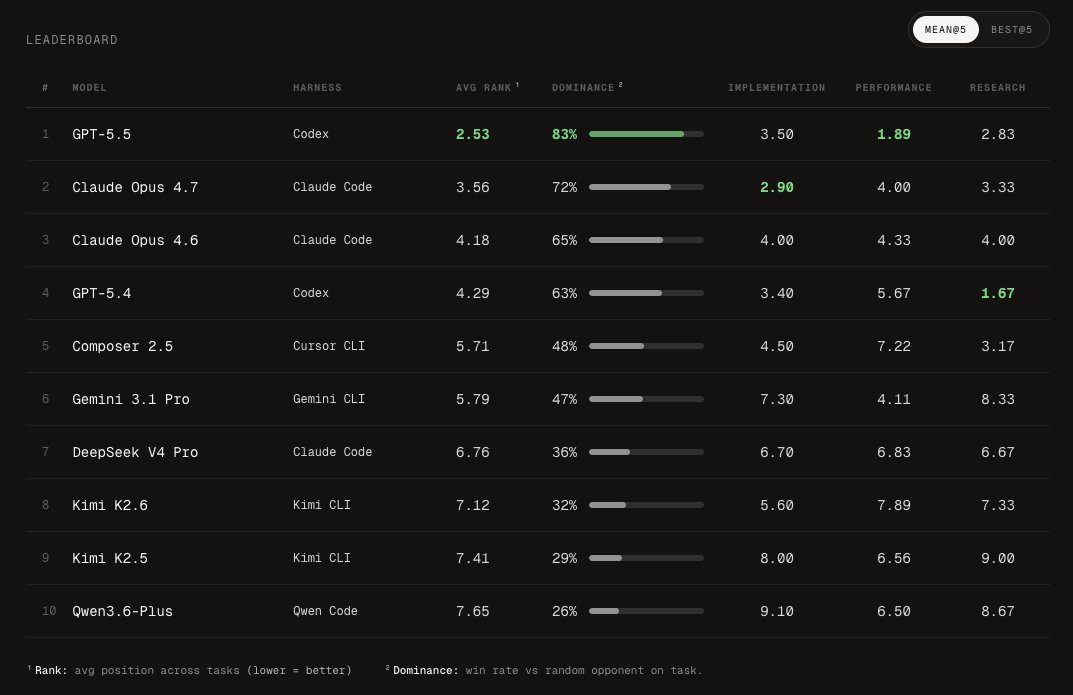
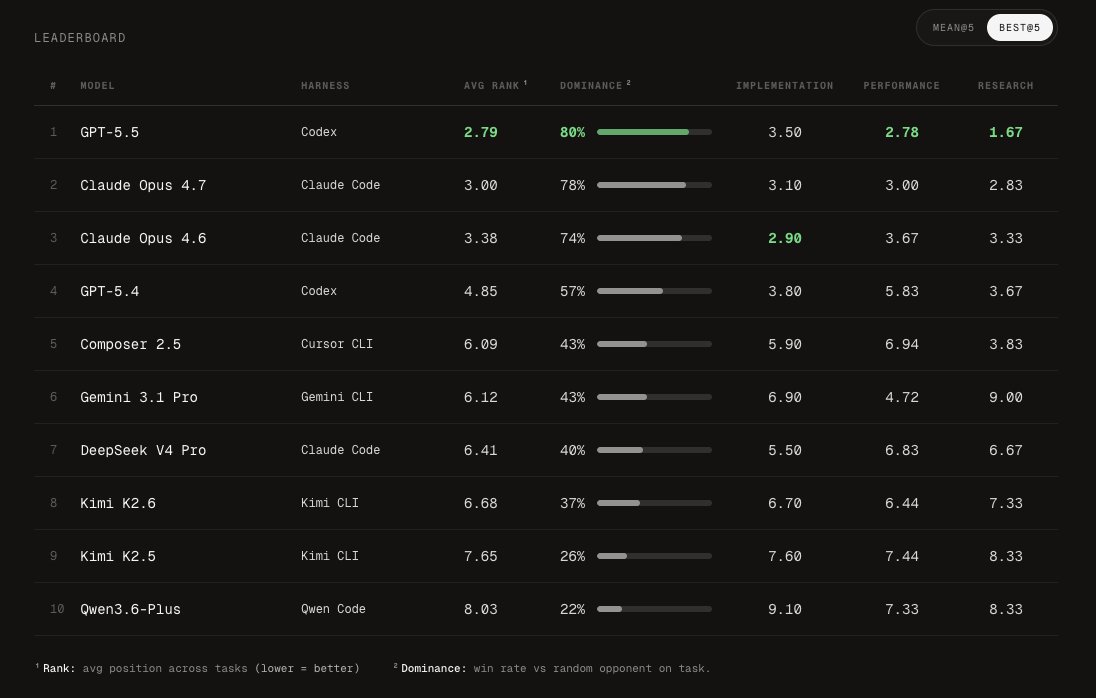
Composer 2.5 is ranked #5 on FrontierSWE
The model is broadly on par with Gemini 3.1 Pro, with a slight edge in our evaluation, and it beats all open source models. We still observe a significant performance gap between Composer and models from Anthropic and OpenAI
5
3
147
13,695
May 16
This went surprisingly well for our first event - heard great talks and had very interesting conversations about post-training and evals!
A special thanks to our speakers @jyangballin, @rawsh0, @rishiiyer01 and @evan_j_chu, and looking forward to the next one :)
May 11

Hosting a research meetup in our North Beach office on Thursday! Come by for food, drinks and talks:
@jyangballin (MSL) will present ProgramBench
@rawsh0 & @rishiiyer01 (Zyphra) will talk about ZAYA-8B
@evan_j_chu and I will speak FrontierSWE and our research bets!

3
5
86
8,533
May 11
Hosting a research meetup in our North Beach office on Thursday! Come by for food, drinks and talks:
@jyangballin (MSL) will present ProgramBench
@rawsh0 & @rishiiyer01 (Zyphra) will talk about ZAYA-8B
@evan_j_chu and I will speak FrontierSWE and our research bets!
6
10
146
35,304
May 10
People from top universities are great on average but nothing gets me more excited than talking to someone who went to a no-name uni (possibly in another country) and ended up at an org with a very high bar
25
77
2,352
76,378
May 10
We are hiring research fellows to help us improve FrontierSWE!
If you want to help build the hardest real-world coding benchmark, reach out! Fellows can work with us for a few weeks up to months and will be supported with compute and a generous stipend
x.com/MatternJustus/status/2…
Apr 16
Introducing FrontierSWE, an ultra-long horizon coding benchmark.
We test agents on some of the hardest technical tasks like optimizing a video rendering library or training a model to predict the quantum properties of molecules.
Despite having 20 hours, they rarely succeed
6
19
309
40,996
May 10
This is a great opportunity for engineers or students that want to get into research and contribute to a high-impact publication! Check out the application form below
frontierswe.com/contribute
1
1
14
1,602
May 7
Incredible to see how far prime-rl has come!
Initially, decoupling training and inference much as possible and making asynchronous RL a first class citizen was done out of necessity to support decentralized training.
Later, it turned out that these happened to be exactly the right design choices for agentic RL with extremely long rollouts. Really cool work from @PrimeIntellect and @RampLabs!

5
4
123
11,861
May 6
Really interesting work! It's super impressive how many of the agentic coding research artifacts (evals, datasets, harnesses, etc.) the community relies on come from @jyangballin, @OfirPress, @KLieret, @18jeffreyma et al.!
May 5

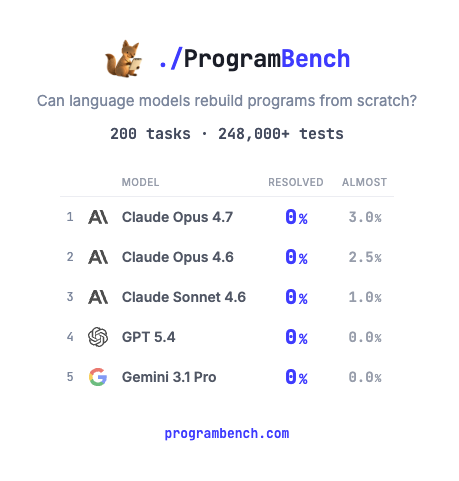
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access.
Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
5
1
49
5,524

May 5
GPT-5.5 is an extremely good model! It outperforms all other models by a wide margin
May 5
GPT-5.5 is the best-performing model on FrontierSWE.
The model substantially outperforms Opus 4.7 in both mean@5 and best@5 rankings while working faster.

2
55
2,702
Justus Mattern retweeted

May 4
Very cool results! V4 is quite consistent and thorough across it's trials while K2.6 has some massive wins and misses. I wonder how 5.5 will score 👀
May 4
DeepSeek V4 Pro is the best open source model on FrontierSWE, closely followed by Kimi K2.6.
V4 exhibits noticeably fewer reward hacking attempts than most other models. In the best@5 ranking it performs as well as Gemini 3.1 Pro

3
2
16
1,991
Justus Mattern retweeted
May 4
I couldn't find the website for FrontierSWE earlier today when I commented on Jack Clark's post
it also belongs on the list of benchmarks worth watching
May 4
DeepSeek V4 Pro is the best open source model on FrontierSWE, closely followed by Kimi K2.6.
V4 exhibits noticeably fewer reward hacking attempts than most other models. In the best@5 ranking it performs as well as Gemini 3.1 Pro
4
5
80
7,533
May 4
It is interesting to me how models like Opus 4.6, Kimi K2.6 and Gemini 3.1 basically perform the same on SWE-Bench Pro but have a massive gap in FrontierSWE.
Long horizon tasks require a different set of skills - good to have a benchmark that measures those!
May 4
DeepSeek V4 Pro is the best open source model on FrontierSWE, closely followed by Kimi K2.6.
V4 exhibits noticeably fewer reward hacking attempts than most other models. In the best@5 ranking it performs as well as Gemini 3.1 Pro
8
7
120
13,175
Apr 27
data quality is the moat
1
1
37
3,806