
building @interact_studio || growth eng @AquinF03
Joined September 2023
- Tweets 2,826
- Following 2,236
- Followers 507
- Likes 10,069
361 Photos and videos
















Pinned Tweet

Mar 26
ai avatars are boring
We built characters that argue, react, and sometimes go completely off-script
Powered by @odysseyml
live at interactstudio.space
14
10
46
7,974
Jun 17
Rain ☔ Sunshine ☀️ Sunset 🌅
you control what happens next.
built with LingBot on @reactorworld · this is what interactive media looks like
3
13
445
Jun 16
We’re sitting down with @willemhelmet, Member of Technical Staff at @reactorworld , for a fireside chat on World Models
live Q&A at the end.
thursday june 18 · 9 AM EST · 6:30 PM IST
register here : luma.com/156243u8
1
1
25
2,156
Jun 16
reality, now with style presets
using @nvidia's SANA-Streaming for this on @reactorworld
2
19
722
Jun 16
we're doing India's first world model hackathon in blr on 20th
check it out
x.com/thelaunchd/status/2065…
Jun 11

media has been static for 150 years
world models change that with interactive media
we're hosting Inception: India's first world model hackathon with @interact_studio powered by @reactorworld
june 20. bangalore. $1500 prize pool
access to models almost nobody has built on before
applications open
2
106
Jun 12
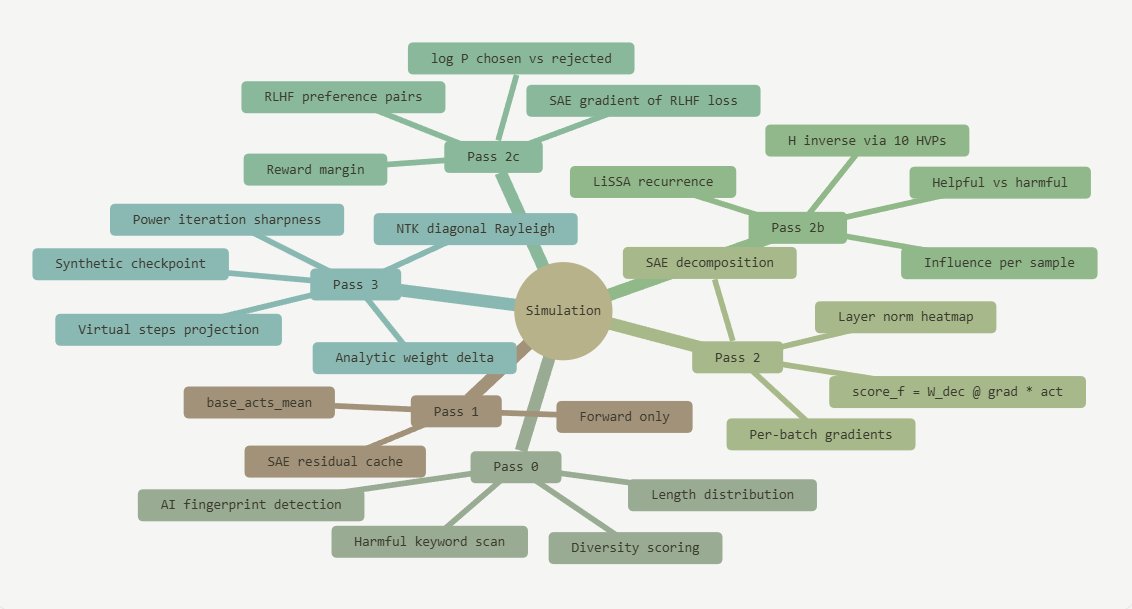
post training isn't always the answer to making your model better.
most teams don't know if their fine-tune is going to work until they've already spent the compute finding out.
at @Aquinf03, we built something that answers that question before you train a single step.

for the first time you can simulate fine-tuning before committing any compute
with @AquinF03, see exactly which features strengthen or suppress, which samples hurt generalization, which layers go dead!
1
1
3
99
Sachin retweeted

Jun 11
media has been static for 150 years
world models change that with interactive media
we're hosting Inception: India's first world model hackathon with @interact_studio powered by @reactorworld
june 20. bangalore. $1500 prize pool
access to models almost nobody has built on before
applications open
21
21
88
6,429
Jun 11
worlds you can step into, not just watch
Inception. june 20, bangalore.
build with world models : luma.com/51ycy57g
Jun 11
media has been static for 150 years
world models change that with interactive media
we're hosting Inception: India's first world model hackathon with @interact_studio powered by @reactorworld
june 20. bangalore. $1500 prize pool
access to models almost nobody has built on before
applications open
4
234

→ Aquin by @Ashf03 helps build private LLMs with local-first control.
Upload data, fine-tune models, and run RAG pipelines without infra complexity.
🔴 Live on Dev Hunt → devhunt.org/tool/aquin
4
2
6
82
Jun 7
exploring sf
new travel hack: don't travel
Jun 7

Google Maps lets you look at places
with world models you can experience them
Built smt where you can click anywhere on map, drop in with Lingbot, and walk around.
Made with @reactor
1
6
420
Jun 7
Google Maps lets you look at places
with world models you can experience them
Built smt where you can click anywhere on map, drop in with Lingbot, and walk around.
Made with @reactor
4
16
1,449
May 31
last week we did livestream on real-time interactive media and world models coz we believe that's where media is headed.
so we’re starting a weekly newsletter to explore the space, share cool things we find
and got a few other things cooking too
drop your mail to get in
1
4
199
May 31
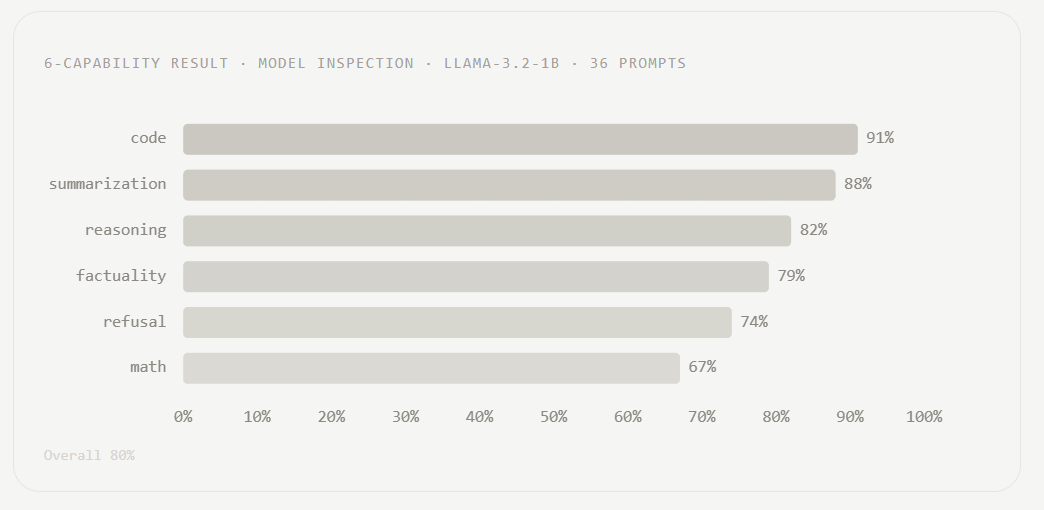
most evals measure outputs, but great evals should be able measure what’s happening inside the model itself
At @AquinF03, we're continuing to make all existing evals and benchmark tools obsolete:
1/3
Custom evals: write your own scorer in Python and you get access to activations and SAE features, so you can do things like:
"check whether a specific feature fired above threshold on a response"
which no external eval harness can do!
2/3
Benchmark Builder now can run weight evals differently in a suite, and export results in multiple formats.
3/3
Auto-suggestions: agent observes and proactively suggests most relevant evals, with just one click to run.
1
5
375
May 29
media won’t be passive anymore
real time interactive media @interact_studio
May 29

For a century, media has been passive.
Films, pictures, streaming, always one-way.
In 2026, it finally talks back.
That's Interact Studio.
8
469

2 months building and researching interpretability tooling at @AquinF03
and I discovered that our users are divided into two groups:
1. People working on Interpretability
2. People leveraging their ML work with Interpretability
First group builds on top of our tooling and experiments. Second group uses tooling for existing pipelines, and to debug/improve their ML work.
At @AquinF03, we care about both. We're shipping a lot, and every release could turn into a experiment or study or a paper.
Come build and research with us: aquin.app/bounty

3
2
9
510
May 27
@nvidia SANA-WM works on a single image and a pre-defined camera trajectory
nvlabs.github.io/Sana/WM/
1
122

May 24
super cool place to be, for anyone building smt cool
May 24

We are bringing 12 founders into one house in Hyderabad for three months. Fully funded will you get selected.
Living costs covered. Operators in the room. Weekly pressure to build, ship, and become worth backing.
@theresidency
10
792