
AI = story impact, not just scores. Let’s walk out of this foggy forest together. mail:AI4people@yeah.net
Joined May 2025
- Tweets 766
- Following 403
- Followers 5,044
- Likes 381
183 Photos and videos
















花名:无招
英文名:zhaoless
艺名:赵露思
2
169
传说中的AI大跃进!

133
时代少年团大概也没想到,自己有一天会以这种方式进入中国 AI 行业史。
事情最开始很像一个饭圈小插曲。
有人测试自家爱豆马嘉祺,发现模型明明知道他是谁,能说出团体身份、经历和相关背景,可一到要输出马嘉祺这三个字,就开始绕路、回避、卡壳。
这件事发到社媒后,很快从粉丝吐槽变成技术圈围观。
大家一边觉得好笑,一边又忍不住好奇:一个大模型既然知道马嘉祺是谁,为什么偏偏说不出他的名字?
后来 MiniMax 的小哥回应了这个问题,并且把内部排查过程整理成了一篇技术 Blog。
我看完之后最大的感受是,最严苛的 AI QA,有时候真的藏在饭圈里。
很多人看到这个案例,第一反应会是:模型都知道他是时代少年团成员了,怎么会说不出名字?
但这恰好是大模型最容易被误解的地方。
对模型来说,知道一个人是谁,和把这个人的名字准确生成出来,并不是同一件事。
大模型内部大致有两条链路。
输入侧的 embedding,负责把文字变成模型能处理的向量。
输出侧的 lm_head,负责把模型内部的向量再变回具体文字。
也就是说,模型可能还保留着马嘉祺这个人的语义位置,知道他和时代少年团、队长、综艺这些信息有关。
但到了最后一步生成文字时,它未必还能稳定把马嘉祺这几个字拿出来。
这有点像我们平时遇到的人名卡壳。
你知道这个人长什么样,知道他做过什么,甚至知道他和谁有关,可就是一瞬间想不起来他的名字。
当然,大模型的卡壳不是人类记忆问题,背后是更底层的 token 机制。
这里最关键的角色,叫 tokenizer。
它会先把文字切成一个个 token,模型最终也只能在自己的词表里选择 token 输出。
马嘉祺这个名字里,马被切成一个 token,嘉祺被切成另一个 token。
问题就出在嘉祺这个 token 上。
MiniMax小哥排查后发现,嘉祺这个 token 在预训练阶段其实学得不错。
它的 embedding 正常,语义近邻也很合理,附近有亚轩、千玺、耀文、肖战这类明星或人名 token。
换句话说,模型早期确实知道嘉祺这个词应该待在什么语义区域里。
真正的问题出现在后训练阶段。
后训练数据里,嘉祺这个 token 出现不足 5 条。
它在预训练时被学过,进入后训练后却几乎没再被当作生成目标训练。
时间一长,输入侧的 embedding 还比较稳定,输出侧的 lm_head 却开始漂移。
这就解释了那个现象:模型还认识这个词,但不太会生成这个词了。
另外MiniMax 在排查马嘉祺问题时,还顺手串起了另一个看起来完全不相关的 bug:日语对话里偶尔混入俄语。
一个是中文明星名字说不出,一个是日语输出冒出俄语,乍一看八竿子打不着。
但从底层看,它们指向的是同一个问题:后训练数据对部分 token 覆盖不足,导致这些 token 的 lm_head 表征发生漂移,最后在生成时被错误召回。
Blog 里有一个数字很刺眼。
在 baseline 模型里,29.7% 的日语 token,SFT 前后的 lm_head cosine similarity 跌破了 0.95。
相比之下,韩语是 3.3%,俄语是 3.7%,中文是 3.9%,英文和 Latin 是 3.5%。
这个差距说明,后训练数据的质量评估,不能只看任务有没有覆盖、领域有没有覆盖、指令能力有没有提升,还要看一个更底层的问题:词表里的每个 token,有没有在后训练里被好好照顾到。
如果某些 token 在预训练阶段进了词表,后训练阶段又几乎消失,它们就可能成为模型里的冷门住户。
平时没人找它们,真到需要它们出场的时候,它们已经站错位置了。
这个问题放到更大范围看,还挺像一次互联网语料考古。
MiniMax 小哥排查变化最大的 token 时,发现里面不只有马嘉祺,还有大量预训练语料里残留的旧互联网痕迹,比如传奇私服、外墙涂装等。
这些词之所以能进入词表,很多时候只是因为早期爬虫语料里出现得太频繁。
这也很有讽刺感。
我们以为大模型学习的是人类文明知识,结果它的词表深处,还住着一批古早 SEO 垃圾。
它们平时不会出现在正常对话里,却依然是模型历史的一部分。
修复思路也很朴素。
MiniMax 做了一个实验:把全量 20 万左右的词表随机拆分,用请重复以上内容这样的任务,构造约 500 条对话数据,让每个 token 至少作为 target 出现 20 次。
听上去像让模型做抄写作业。
但效果很明显。
日语到俄文的混淆率,从 baseline 的 47% 降到 1%。
马嘉祺 case 也能正常输出了。
这说明有些大模型问题,其实只要找到真正的断点,用足够克制的工程方式补上,效果就会很直接。
这里也能顺手理解最近行业里关于 tokenizer 的讨论。
有些路线会选择加法,保住更完整的词表,通过数据覆盖和训练策略来维护它。
有些路线会选择减法,把覆盖不到、维护成本高的 token 从词表里裁掉。
前者更重,后者更省,但代价不同。
词表越完整,模型对长尾名词、专有名词的兼容性可能更好。
词表越精简,训练和推理可能更高效,但用户有时候也需要花更多 token 去表达同样的内容。
我觉得这篇 Blog 真正有价值的地方,也在这里。
它没有把问题轻轻带过。
它把一个很好笑的 bug,拆成 tokenizer、embedding、lm_head、后训练数据分布、词表覆盖度几个层次,再用实验把修复路径跑了一遍。
它暴露的是一个更长期的问题:当模型从预训练走向后训练,哪些能力被增强了,哪些冷门 token 被遗忘了,哪些语种因为覆盖不足开始漂移,这些都需要被看见。
这也是这次回应比较加分的地方。
大多数公司遇到这种 bug,可能会选择降低声量。
因为从传播学角度看,大模型不认识马嘉祺这个说法太容易变成玩梗素材。
但 MiniMax 这次把它讲清楚了。
马嘉祺也意外成为一个入口,让更多人看见,大模型不是神奇魔法,也不是万能百科。
它有自己的结构、路径和盲区。
很多看起来玄学的问题,拆到底,往往都是工程问题。
AI 行业有时候总喜欢聊宏大的东西,AGI、智能涌现、下一代入口。
但我越来越觉得,很多真正推动行业变好的问题,往往就藏在这种很小、很具体、甚至有点好笑的 case 里。



1
908
有一种创作的挫败感,几乎每个人都经历过,你脑子里明明有一个完整的画面,眼前却只剩空白。
你开始打字,AI 给你渲染出一段视频,你看了十秒,意识到不对,就差那么一点,却不知道下一步该怎么办。
退出,重来,等待,得到另一个差那么一点。
因为整个交互的逻辑错了。
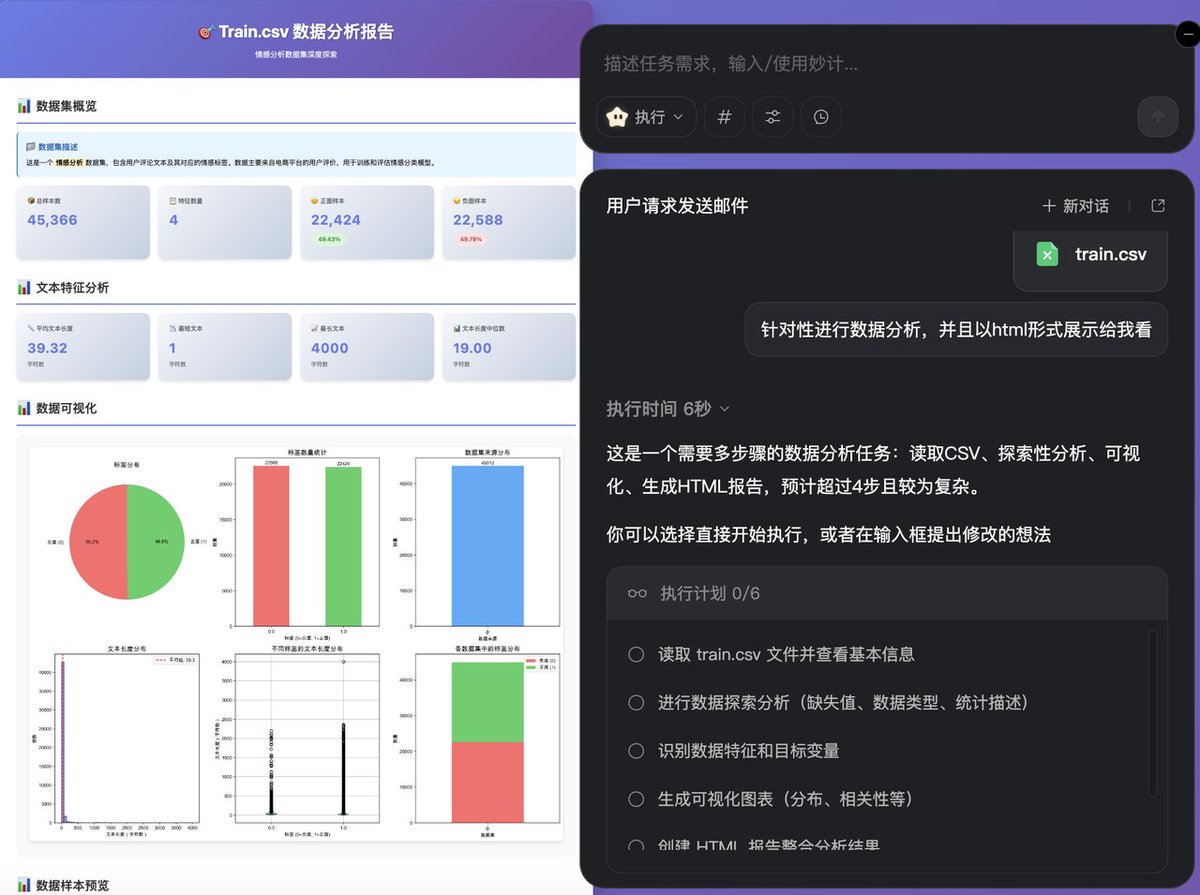
4月16日,阿里ATH事业群发布了世界模型产品HappyOyster(快乐生蚝)。
这是同一个孵化出HappyHorse的团队,带来的一次更具野心的尝试,他们想解决的,是一个根本性的问题:当AI构建的世界出现在你面前,为什么你只能是个旁观者?
过去两年,文生视频的技术进步有目共睹,生成质量飞速提升,但交互范式几乎没有变过:输入提示词,等待渲染,收到成片。
这是一条单向的传送带,用户站在终点等货。
HappyOyster要打破的,正是这个链条。
它提供四个核心能力。
漫游模式(Wander)让用户从一张图或一句话出发,生成具备物理一致性的完整空间,场景持续存在,光照随视角变化,还可以自由拖拽镜头、延伸探索,目前支持1分钟连续实时位移和多样风格切换。
导演模式(Direct)则允许用户在视频任意节点通过文字、语音或图像介入世界演化,改写剧情、调度角色、切换镜头,目前支持连续生成3分钟以上的480p或720p实时画面。
创造让用户持续补充设定、角色、场景和规则。
分享则让数字世界可以被保存、被他人继续体验和二次创作。
漫游和导演两种模式之间存在微妙的区别:漫游更接近身临其境,导演更接近掌控叙事。
而创造与分享,则让这种交互进一步从一次性的体验延伸为持续搭建、持续流转的内容过程。
它们代表着几种不同的创作欲望,也指向了AI内容交互的几个尚未被充分挖掘的维度。
HappyOyster所属的技术流派,世界模拟器,在AI领域仍是相对小众的前沿赛道,与谷歌的Genie3同属一个方向。
要理解它和文生视频的区别,不妨做一个类比:文生视频模型更像是一位摄影师,接到委托,拍好交付。
而世界模型更像是一位物理引擎,持续运行着一个包含空间、重力、因果规律的虚拟宇宙,摄影机只是进入这个宇宙的其中一种方式。
技术层面的差异是本质性的。
传统文生视频模型的建模目标是生成一段合理的画面序列,而世界模型的建模目标是预测一个世界的演化方式。
前者完成后即告一段落,后者在整个过程中持续推演。
这意味着模型需要真正理解空间位置关系、物体的物理属性、角色动作的因果逻辑,而不只是让画面看起来顺滑。
相较于谷歌Genie3,HappyOyster在技术路径上做出了几个有趣的选择。
它采用了时间跨度更长的世界演化建模方式,让模型在更宏观的时序框架下保持场景的高保真度。
同时,它在建模之初就引入了多样的控制信号,文本、动作指令、图像参考,使得生成质量、长时序与实时可控性能够在同一个框架内协同优化,而不是相互取舍。
产品层面的差异则体现在独家的实时导演功能,以及漫游模式更强的风格泛化能力和动态表现力。
再往前一步看,创造与分享能力的补充,也让HappyOyster呈现出一个更完整的产品闭环:从进入世界、干预世界,到搭建世界、传播世界。
世界模型现阶段的技术成熟度仍在早期,但它已经开始改变某些行业的工作流。
在游戏原型设计领域,开发者不再需要搭建完整的关卡就能验证玩法感受,他们可以用HappyOyster快速生成一个可玩的空间原型,在其中测试叙事节奏、光照氛围和空间体验。
在影视创作中,分镜验证的成本被极大压缩。
导演可以在正式开机之前,用自然语言描述想象中的场景,实时获得可修改的视觉参考,并在任意节点调整镜头语言和角色调度,让创意验证从等待渲染变成实时对话。
我个人认为更长远的方向,是与穿戴设备等智能硬件结合,根据用户的位置、动作和语言,实时生成响应性的沉浸内容,让数字世界和现实空间真正产生共振。
而当这些内容能够被保存、分享,再被其他人继续接力创造时,HappyOyster想做的就变成了一个可以不断生长的数字世界入口。
必须承认,世界模型距离大规模商业落地还有相当的距离。
漫游与导演两大模式目前尚未完全打通,真正意义上的边探索边创造还停留在路线图阶段。
画面质量、物理一致性、生成稳定性,都还有肉眼可见的提升空间。
但这恰恰是这个方向最有意思的地方:它的技术可能性还远未被触及天花板,而它描绘的那个愿景,每个人都拥有一个可以随时进入、随时修改、实时反馈的数字世界,足够清晰,足够令人心动。

1
719
上周我去参加一场只有20个早期创始人的闭门会,散场的时候我等滴滴,站在路边吹了十分钟风。
那十分钟里,我脑子里反复冒出来一个判断:创始人的角色,可能真的在变。
以前大家默认,创始人首先是人员管理者。
要招人,要盯执行,要管流程,还要不断处理团队磨合、效率波动和人员流失。
公司想做大,第一反应往往也是继续招人,把组织铺开,把岗位补齐。
但我现在越来越强烈地感觉到,创始人的角色,正在从人员管理者,变成Agent管理者。
你不用天天蹲在工位盯执行,不用一轮一轮招人。
你更需要做的,是把需求提清楚,把流程拆明白,把关键节点定义好,然后指挥不同分工的Agent,把销售获客、内容生产、用户客服这些全链路的活跑起来。
我在闭门会上见了个做ToB业务的创始人,整个公司明面挂着的人类员工只有三个,剩下二十多个岗位全是Agent。
每个Agent都有固定分工和沟通风格,对接客户的销售Agent说话永远干脆,处理售后的客服Agent永远耐心。
客户跟他们合作了大半年,根本没察觉对面不是真人。
现在这种Agent团队,已经越来越像一种新的组织形态,7*24小时待命,随时开工。
并且这不只是公司变轻了,这是公司的成本结构和交付方式都在变。
我身边就有个做垂直行业知识库的朋友,就他一个人,养了十几个Agent做内容更新、用户答疑、续费提醒,现在有120个付费客户,每个月每人付399,一个月流水接近五万,扣掉服务器和API调用成本,纯利还有四万多。
放在以前,这点收入未必养得起一个十人团队。
光是内容、运营、客服这些人力成本,就已经把利润吃掉不少。
很多原本需要多人协作完成的标准化工作,现在都能被拆成流程,再交给不同Agent并行执行。
谁更新内容,谁回答问题,谁做续费提醒,谁整理客户反馈,都可以被设计进一套持续运转的系统里。
这样一来,公司的瓶颈也变了。
过去的核心问题,是怎么招更多人、怎么把人管好。
现在越来越多小公司的核心问题,正在变成你能不能把任务拆清楚,能不能把流程搭起来,能不能把Agent协作跑顺。
这也是我最近反复在想的一件事。
过去大家信奉人海战术,觉得多招人、多铺团队、多设岗位,组织就更稳,交付就更快。
这个逻辑在过去当然成立,因为很多事情确实只能靠人堆出来。
但现在,这个逻辑开始松动了。
因为人一多,沟通成本、协作成本、管理成本都会迅速上升。
很多团队表面上很热闹,实际上大量时间都消耗在对齐、返工、等待和内耗上。
岗位越多,链条越长,响应速度反而越慢。
很多公司最后输的,不是能力不够,是组织太重,动作太慢。
Agent带来的变化就在这里。
它不一定会立刻替掉所有人,但会优先吞掉那些重复的、标准化的、可拆解的工作环节。
一旦这些环节被系统接管,传统靠堆人维持效率的方式,就会越来越不划算。
你招十个人才能跑起来的业务,别人三个人加几十个Agent就能做。
你还在为招聘、培训、考核和流失头疼,别人已经把主要精力放在定义需求、优化流程和提升结果上了。
所以我越来越觉得,未来几年,拼的不会是谁团队更大,拼的是谁更早把公司改造成一个人类指挥、一群Agent执行的新系统。
先跑通的人,会把小赛道的利润先吃掉。
人海战术不会一下子消失,但它最风光的阶段,可能真的快过去了。
1
1
307
招聘Agent开发工程师(实习)
薪资待遇
200-400元/天
岗位职责
- 参与公司Agent产品的设计与开发工作,协助完成前后端全栈开发任务,包括管理后台、用户交互界面、工作流编排系统、任务调度系统及相关服务接口的开发与优化。
- 基于大语言模型(LLM),协助构建高可用的Agent生产能力,参与Prompt优化、上下文管理、记忆机制、工具调用、长文本生成及多轮迭代策略的设计与落地。
- 协助完成RAG检索增强系统的设计与优化,打通知识库、案例库等内容资产,提升Agent对业务需求的理解与响应能力。
- 参与Agent的多Agent协作、工作流协同能力建设,协助解决任务拆解、流程编排、记忆管理等关键问题。
- 与业务团队深度协作,深入理解真实业务场景的需求与痛点,协助优化Agent的可用性、交付质量及生产效率。
- 跟踪自然语言处理、大模型应用、Agent框架的前沿技术,协助推动新技术在业务中的验证与落地。
- 协助完成相关系统的部署、监控、性能优化与稳定性维护,保障Agent平台的持续可用与高效迭代。
必备要求
- 本科及以上学历,计算机、软件工程、人工智能、自然语言处理等相关专业,在校学生(可保证稳定实习时长优先)。
- 具备扎实的工程基础,熟练掌握Java或GO编程语言,具备良好的编码规范与逻辑思维。
- 了解Web开发基础,熟悉前后端分离架构,能够协助完成管理后台、内容工作台等简单功能的开发与调试。
- 对LLM应用开发有一定了解,熟悉Prompt Engineering、上下文工程、工具调用等基础概念,有相关实践经验者优先。
- 了解RAG相关技术原理,能够协助完成知识切片、向量检索等基础工作。
- 具备较强的学习能力、问题分析能力与执行力,能够快速适应业务节奏,主动推进任务落地。
- 具备良好的沟通协作能力,能够配合团队完成协作任务,乐于分享与交流技术。
加分项
- 有完整的Web产品开发实习经验,能够独立完成简单功能模块的开发。
- 熟悉LangChain、LangGraph、LlamaIndex、AutoGen、CrewAI等Agent主流框架,有实际项目落地经验。
- 具备RAG检索增强系统相关开发经验,能够独立完成召回优化、重排序、知识库更新等功能设计与实现。
- 了解HTTP、WebSocket、消息队列、缓存、数据库等基础设施,具备基础的服务端开发与系统集成能力。
- 关注Agent领域技术动态,有相关技术博客、开源项目或竞赛经历者优先。
工作地点 上海/深圳
简历投递邮箱:hr@velneth.com
1
547
中国有大量的方言内容没有被好好存档。
地方戏曲、地区性的口述历史、农村的广播录音,还有那些只在特定城市流传的民谣、市井里的叫卖声、老人讲了一辈子却从未被记录下来的故事。
这些东西有语言学价值,也有文化价值。
但因为方言转写的成本极高,它们大多没有文字,没有索引,没有办法被检索和传播。
慢慢地,随着会说那门方言的人越来越少,这些内容就这样消失了。
不过,严格来说,真正更容易消失的,往往也不是大家最熟悉、最常见的那些方言。
像粤语、四川话、东北话这样仍然拥有大量使用者、内容生产也很活跃的方言,当然不会轻易消失。
更脆弱的,反而是那些传播范围更窄、记录更少、代际传承更弱的长尾方言和地方口音。
也正因为这样,方言识别能力真正有价值的地方,从来不只是能不能听懂常见方言,更在于能不能覆盖那些不那么常见、却更需要被保存下来的语言样本。
从公开信息看,Qwen3.5-Omni 已将语音识别能力扩展到 39 种方言。
除了普通话、粤语这些大家熟悉的类型,也已经支持像广东普通话、南京话这样的更细分表达,以及吴语、闽南语等具有鲜明地域特征的方言体系。
对很多原本更难被记录、也更容易在代际更替中变弱的语言内容来说,这种能力本身就有现实意义。
消失不是一个突然的事件。
它是一个漫长的、安静的过程。
某个地方的录音磁带氧化了,某位老人去世了,某种腔调再也没有年轻人开口说了。
没有人宣布它结束,它只是不再出现。
我有时候会想,语言是文化最后的容器。
当一门方言消失,装在里面的那些东西,也跟着一起走了。
这件事让我开始认真想一个问题:大模型对语言的理解,究竟算不算真正的理解?
标准的评测指标,比如 MMLU、GPQA,还有各种 Benchmark,已经越来越难以让人产生直觉上的认同。
数字在涨,但你不清楚那意味着什么,也不清楚模型会在什么时候悄悄失效。
真正能让我产生判断的,是那种文化嵌入的、需要真正理解才能完成的具体任务。
我最近看到阿里云 Qwen 团队发布了 Qwen3.5-Omni,其中有个 demo 让我比较感兴趣。
他们输入了一段多方言说唱混剪,让模型识别每一位歌手来自哪里、用了什么方言、情绪状态怎样,并转写出完整歌词。
我觉得这个任务比背英语选择题难多了。
因为说唱本身已经是语音识别的噩梦。
语速快、背景音强、韵脚压迫着发音变形,说唱歌手为了押韵,会刻意拉长或切断某些音节。
方言说唱更难。
粤语九声六调,一个字的声调错了,意思就完全不同。
重庆话的入声字短促爆破,标准普通话的 ASR 系统常常直接跳过。
东北话的儿化音密度和北京话不同,有自己的节律逻辑。
维吾尔语混入汉字时,两套音系的边界本身就是一道难题。
而这个 demo 里有 12 位来自不同地区的歌手,粤语、普通话北京口音、杭州话吴语、河南话、天津话、武汉话、维吾尔语、山西话、云南话、河北话、四川话、东北话,轮番出场。
每个人说唱的时间只有十几到三十几秒,没有任何提示告诉模型现在换人了。
模型要做的事是,听出换人,判断来自哪里,分析声音质感和情绪状态,转写歌词,还要给出歌词里的文化语境解释。
我把输出仔细看了一遍,最让我留意的是模型在描述每个歌手时的粒度。
对粤语歌手,它写道,声线属于中音区,听起来自信且充满活力,有一种街头巷尾的亲切感。
对北京普通话女歌手,它写的是,声音中透着一股京味儿的飒爽和利落。
对天津歌手,它的描述是,声音极具辨识度,带有天津话特有的哏儿和幽默感,语调夸张,节奏明快,像是在说相声一样。
这些描述没有说错。
天津话里确实有相声的基因,那种语调的弹性和包袱感是真实存在的东西,不是凭空生成的形容词。
歌词转写的部分也让我有些意外。
粤语部分出现了“哼住歌”“麻将馆等自摸”,四川话部分有“别去装憨厚”,东北话里大碴子味的节奏也基本完整保留。
方言说唱的歌词本来就不容易在文字上对齐,模型在这里没有回避,而是给出了明确的转写结果。
为什么我觉得这个 case 有意思呢。
因为这个任务需要的不只是听清楚,还需要某种关于中国各地城市文化和语言历史的背景知识,才能把声音和来源对上。
天津话和东北话听起来都爽朗,但节奏感截然不同。
河南话和山西话同属北方官话,但声调走向和词汇选择完全是两回事。
武汉话里的码头气,杭州话里的吴侬软语,这些都不是从频谱分析里能直接读出来的东西,它们是文化积淀在语音里的印记。
模型把这些大部分接住了。
这意味着它在某种程度上把语音、语义、文化背景整合到了一起。
语言是文化最后的容器。
一个模型效果究竟怎么样,我不会去看 Benchmark,我会观察它在这种任务上的表现。
具体的、文化嵌入的、需要真正理解才能完成的。
因为只有到了这种时候,你才比较容易判断,它到底是在机械匹配,还是已经开始摸到理解这件事的边。
而 Qwen3.5-Omni,确实交出了一份还不错的答卷。
456
最近AI行业有个现象挺有意思:大厂们好像突然一起踩了油门。
谷歌把Gemini从“大模型”重新定位成“全栈AI系统”,Android、Chrome全线往Agent化改;英伟达不满足于卖显卡,开始做Agent开发平台;OpenAI在收缩应用线,集中资源押注基础能力。
方向出奇一致,都在从“做一个聪明的模型”转向“做一套能干活的系统”。
国内这边,最近动静最大的是阿里。
Qwen3.6-Plus发布两天,直接冲上了OpenRouter日榜第一,更夸张的是,单日调用量达到1.4万亿Token,把OpenRouter单日单模型的全球纪录给破了。
OpenRouter是真实的使用场景,开发者在这里用真实的项目来投票,性能、速度、成本,一个都不能糊弄。
。而且三天发了三款模型:全模态的Qwen3.5-Omni、图像生成的Wan2.7-Image、编程和Agent方向的Qwen3.6-Plus。
这个速度本身不是新闻。
真正罕见的,是一家体量这么大的公司,能在半个月内完成从组织重构到产品集中兑现的完整动作。
这让我想起一个不那么常被讨论的话题,为什么大公司的AI进展总是忽快忽慢?
往往是因为组织结构没有跟上。
资源在不同事业部之间摩擦,决策链条拉长,能力没办法形成合力。
阿里之前也经历过这个阶段,通义实验室能力毋庸置疑,但从实验室到产业化的路走得并不顺畅。
ATH的成立,某种程度上是在修复这个问题。
今年还有一个趋势越来越清晰:AI的竞争正在从“谁更聪明”转向“谁更能干活”。
龙虾这种个人桌面agent的走红,是因为它真的能替人完成一系列连续的操作,打开应用、搜索信息、执行任务,像一个有手有脚的数字员工。
这种能力,需要的是多模态理解、工具调用、任务规划的综合协同。
而Agent的兴起,也让AI的Token消耗进入指数级增长。
一个Agent完成一次复杂任务,调用的Token数量可能是普通对话的几百倍。
这意味着,谁能高效地创造Token(模型端)、输送Token(云和算力端)、应用Token(产品和场景端),谁就占据了这一轮AI产业化的核心位置。
黄仁勋说Agentic AI是继大模型之后的下一个万亿美元机会。
这个判断大概率没错,但问题是,要把Agent能力真正落进企业工作流,光有一个好模型是不够的。
你还需要理解企业场景,需要安全可控的私有化部署能力,需要跟现有软件生态打通。
钉钉背后的2000多万企业组织,是悟空真正有意思的地方,它的分发渠道和场景密度,是大多数AI创业公司没有办法复制的。
但这里有一个更值得深思的问题:可持续的技术创新体系,到底依赖什么?
很多公司会在某一轮押对,用一款产品出圈,然后逐渐掉队。
而真正能在多个技术代际保持前沿的,往往是那些把创新做成体系化能力的。
这件事说起来容易,做起来极难,它需要组织耐心、资本持续性和判断力同时在线。
黄仁勋说Agentic AI是下一个万亿美元机会。
但机会这个词本身是中性的,它向所有人敞开,又对大多数人关闭。
真正的问题或许是,当AI开始真正干活的那一天,你的工作流里,还剩下多少事情是只有人能做的?
1
383
我们一般把聊不下去还硬聊的情况称之为爱情


276
AI生图用了两年,我终于等到一个肯认真填坑的模型
过去几年,用AI生图的人都有一段相似的心路历程。
刚接触的时候觉得什么都能做,满脑子是这东西要改变设计行业了。
用了三个月开始发现不对劲,用了半年开始认命,用了一年之后,已经学会了在心里给它划一道边界:这类需求别指望它,绕开走。
那道边界后面,堆着四个没人打算修的问题。
AI生图过去最大的困境,是关键细节一直不可控。
人物差异、文字精度、局部修改,这些看起来像小问题,实际上决定了一张图能不能真正进入专业工作流。
1. 所有人长同一张脸。
你在提示词里写鹅蛋脸、丹凤眼、高颧骨,它给你生一张脸。
你换成方脸、圆眼、低眉骨,它给你生出相似的脸换了个表情。
不同提示词,不同性格设定,出来的人物放在一起,像是同一个人的换装游戏。
角色控制做不到,意味着AI生图很难进入短剧、游戏设定、多角色广告这些需要角色体系的生产流程。
2. 颜色是开盲盒。
你脑子里有一个配色方案,提示词里写的很具体,但生图工具不认这个。
每次生成都是随机抽卡。
颜色控制决定的是AI生图能不能进入品牌和商业场景。
在专业设计里,颜色是规范变量。
只要颜色还在开盲盒,AI生成图就很难真正进入交付链条。
3. 薛定谔的文字。
短文本还好。
但只要图上的字数一多,就会开始模糊、变形、漏字、出现乱码。
文字渲染一直是AI生图最容易暴露玩具属性的地方。
因为论文配图、信息图表、密排版的商业海报,这些日常真实存在的需求一直没有被满足。
4. 改一处,动全部。
这是最让人崩溃的。
你有一张九成满意的图,嘴角弧度不对,或者背景有个元素位置偏了。
改完之后,那个局部确实变了,但整张图整体可能也都变了。
局部编辑之所以重要,是因为真实创作流程里,大部分修改都是局部的。
只要局部改动还会牵连全图,AI生图就永远无法进入真实生产端。
不过,今天,Wan2.7-image发布。
它把这四个门槛挨个认真过了一遍。
1.千人千面
Wan2.7-image做了可深度自定义的面部控制系统,提示词可以细化到脸型类别(鹅蛋脸/方脸/长方脸)、眼形(杏仁眼/丹凤眼/深邃眼窝)、肤色、发型和五官比例的逐项指定。
不需要全部写清楚。
提示词可以就是“四个刚入学的大一新生在寝室合影”,它会生成有差异的四张脸。
2.规范色彩
颜色控制的解法更直接:一键提取或输入参考图中的颜色和占比,模型就能按这个配比生成色彩构成。
颜色不再是开盲盒,它可以作为规范变量输入。
3.超超超长文本渲染
它用长上下文文本编码器(Long Context Text Encoder)处理文字输入,支持最高3K token,覆盖12种语言,复杂公式和表格在处理范围内,渲染精度达到印刷级。
这意味着AI生图开始能承载信息,而不只是承载氛围。
论文配图、信息图表、密排版的商业海报,这些之前只能绕开的场景,开始有了进入的可能。
4.局部修改
原生支持交互式编辑,框选区域内可以进行添加、移动、替换、对齐操作,框外图片理论上不受影响。
这意味着AI生图不再只是玩具。
它开始尝试进入更细的制作环节。
AI生图这几年最尴尬的地方,是太多关键环节一直停留在偶尔能用。
Wan2.7-image这次真正值得看的,是它开始把这些长期影响专业使用的细节,当成正经问题来解决。
这件事的意义可能比某一次跑分领先更大。
因为AI生图真正的分水岭,一直都是那些最容易让人返工的细节,能不能终于开始变得可控。


1
744
我个人平时其实不太依赖AI产品来搜集信息。
原因很简单,大模型的幻觉问题一直都在。
另外,很多时候,它给出的内容看起来完整、流畅,甚至还附着引用和出处,但只要真的顺着查下去,就会发现有些引用本身质量不高。
这会影响我获取信息的效率。
这也是为什么,哪怕AI已经成了很多人的默认工具,我在搜集信息的时候,依然会多留一个心眼。
其实AI出现之后,连不少大媒体都曾被AI内容误导过。
也正因为这样,我最近看到千问在产品里测试引证feature时,还是比较惊喜的,因为终于有一个主流AI产品,开始正面碰这个行业一直绕着走的问题了。
今天发现,打开千问提一个涉及新闻时事的问题。
等AI洋洋洒洒答完,你会在回答末尾发现一个不起眼的按钮,叫引证。
点下去,界面里的文字开始变色。
绿色的部分,是有可靠信源交叉验证过的内容。
红色的部分,系统会打上一行小字提示:需进一步核查。
这个设计看起来不算复杂,却十分重要:这是第一个主流AI产品,开始主动寻找“回答内容来源有问题”的解法。
在此之前,绝大多数主流AI产品的默认逻辑是:给出答案,语气笃定,哪怕内容存疑。
用户如果不主动追问来源,很难知道眼前这段流畅的文字,究竟是有据可查的事实,还是模型觉得大概是这样的自信推断。
为什么行业迟迟没有正面应对AI幻觉问题呢?
自从大语言模型进入公众视野,这个问题就从未消失。
模型会虚构引用、捏造案例、把错误的年份和人名混搭在一起,还会用毋庸置疑的语气包装这一切。
学界和工业界对此的态度,长期处于一种奇怪的错位,技术论文里年年讨论,产品设计上几乎不正面承认。
原因不难理解。
主要还是因为用户体验的包袱。
AI产品最核心的价值主张就是快速、流畅、有用。
如果每一条回答后面都挂着警示标,用户的第一感受可能不是这个产品诚实,而会是这个产品不可信。
产品经理不愿意自己挖坑。
还有就是技术上的模糊地带。
大语言模型的运作机制,决定了它在生成文本时并不区分“我知道”和“我猜”。
从模型的视角看,两者在输出层面没有本质差异,都是对下一个词的概率预测。
要给输出内容打上可信度标签,需要在模型生成之后再增加一层独立的核查机制,这在工程上是额外成本,在逻辑上也容易自相矛盾。
另外,还有竞争压力。
现在正是几家头部AI产品你追我赶的阶段,没有人愿意率先给自己贴上答案可能有误的标签,眼睁睁看着用户去用更自信的竞品。
正因为如此,千问这次测试引证功能,才显得有几分反常,反常得让人意外。
要理解这个功能的价值,必须先搞清楚它在技术上做了什么,以及更重要的,它没有做什么。
我根据已有的产品表现来推断,引证的工作流大致如下:模型先生成初始回答;系统再对回答中的关键信息节点进行提取和拆解;接着针对每个信息节点,调用实时检索能力,比对网络上的权威信源,包括主流媒体报道、官方声明等;最后根据比对结果,对原始回答中的对应内容进行标注,可验证则标绿,存疑则标红。
这个逻辑的核心,本质上是检索增强验证(Retrieval-Augmented Verification),可以视作RAG技术路线的一种延伸应用。
区别在于,传统RAG是在生成回答之前检索信息以提升质量,而引证是在生成之后反向检索以核查质量。
在引证之前,行业针对AI可信度问题,主要有几种已有的解法。
一种是引用来源链接。
这是最常见的做法,在回答末尾附上参考链接,把验证责任转交给用户。
问题在于,链接的存在不等于内容的准确。
链接有时指向的页面内容与AI的表述存在出入,或者链接内容本身不可信。
另外,这种方式依赖用户主动点开并阅读来源,而现实中大多数用户不会这么做。
一种是输出置信度分数。
部分模型探索过给回答的不同部分打上置信度分数。
但这种方式对普通用户不友好,且置信度的计算来自模型内部,仍然是模型对自己有多自信,而不是独立的外部验证。
还有一种是添加通用免责声明。
在回答末尾加上以上内容仅供参考之类的措辞。
这种方式几乎是无效的。
引证的本质区别在于,它通过颜色的视觉差异,把核查结果直接嵌入用户的阅读体验之中。
用户不需要主动去验证,系统替你做了第一步初筛,并且明确告诉你哪里可信、哪里存疑。
我认为这种设计,比任何通用免责声明都更有信息密度,也更诚实。
有人会说,这不就是加了个核查标注,有那么重要吗?
我倒觉得这个feature值得认真对待,因为它改变的是一种底层预设。
过去几年,AI内容的默认状态是可信,直到被证伪。
用户拿到一段AI回答,如果没有明显的漏洞,往往会直接接受。
这种默认信任,在AI回答私人问题,帮我写封邮件、解释一个概念时影响有限。
但在涉及新闻事实、政策信息、医疗健康等领域,它的代价可能相当高昂。
引证功能试图做的事,是把这个默认值翻转过来。
这个翻转,如果成为行业惯例,对AI内容生态的影响是深远的。
用户会开始习惯区分被验证的AI内容和未被验证的AI内容,正如他们区分经过编辑审核的报道和社交媒体上的传言。
这种识读能力的建立,确实需要产品端率先给出示范。

1
1
1
467
太有生活了
Mar 26

Manus CEO 肖弘收到通知后, 急匆匆的从新加坡赶到西城区月坛南街38号发改委,
快走进会议室大门时,行动小组在走廊里把他扭住,小肖惊慌失措,一边大声说: “我是来开会的,你们要干什么?” 一边拳打脚踢,拼命进行反抗。
321
过年的时候回老家,跟刚毕业的堂妹吃饭。
她是比较典型的江浙沪独生女,从出生起,就被整个家族捧在手心里。
她一路走得也很标准,读的是不错的学校,成绩一直不差,家里人对她的期待也很明确,就是找一条体面、稳定、风险低的路。
她从小几乎没怎么吃过生活的苦,家里把能铺好的路都尽量铺好了,所以她天然相信,只要自己继续努力,沿着标准答案一直往前走,人生就不会出太大偏差。
但她一心追求考公,说只要考上了,这辈子就稳了。
我看着她翻得卷边的公考习题册,话到嘴边又咽了好几次。
很多人还在顺着以前的路径卷,考公,考编,考各种证,刷各种标准化试题,以为分越高越稳。
像我堂妹这样的孩子,其实特别有代表性。
她们学历不错,成长路径清晰,也很擅长在规则明确的体系里往上走。
学校、家庭、社会给她们的反馈都很一致,只要你够自律、够努力、够会考试,就能换来一个安稳的人生。
这种想法放在过去确实成立过。
因为过去整个社会的分工很清楚,很多岗位需要的就是服从流程、记住规则、按标准执行。
谁更擅长在既定规则里拿高分,谁就更容易拿到一张看上去安全的入场券。
但现在学校教的所有标准化考纲内容,本质上都是训练你解决有标准答案的问题的能力。
你会发现,这套能力过去是稀缺的,现在却在被快速稀释。
因为这些是AI最擅长的事,你刷十年题攒的知识点,AI一秒钟就能调出来,还不会出错。
另外,整个社会对标准化能力的定价在往下掉。
以前大家觉得背得住、记得全、反应快,就是竞争力。
接下来这些能力会越来越像基础配置,甚至像水电煤一样默认存在。
谁还只是停留在这一层,谁就会越来越被动。
反而三四线甚至农村出身的人,在这个时代有天然的优势。
因为他们从小接触的全是没有标准答案的问题,解决问题的思路特别活。
很多农村孩子小时候的成长环境,和我堂妹这种被精心托举着长大的孩子,几乎是两个世界。
前者从小就知道,很多事没人会提前替你安排好。
家里缺点什么,要想办法补,遇到麻烦了,要自己找人问。
很多城市里长大的孩子,从小被培训班训练得只会找标准答案,遇到没有固定解法的问题,直接就懵了。
比如家里要办点事,找谁帮忙,怎么开口,东西不够了怎么临时凑,出了岔子怎么补救,这些事在很多小地方的孩子成长过程中几乎是日常。
表面看不体面,甚至不系统,但它训练出来的是另一种能力,就是在资源有限、信息不完整、规则不清晰的情况下,照样把事情往前推。
这也是我那天看着堂妹时,心里特别复杂的一点。
她很优秀,甚至可以说,她就是过去那套评价体系里的优等生。
学历好,履历干净,做题能力强,也懂得怎么在一个明确的框架里不断拿更高分。
可问题恰恰在这儿,旧时代最奖励的能力,到了AI时代,正在慢慢失去过去那种稀缺性。
相反,那些从小就在复杂环境里长大的人,反倒更早练出了一种贴近现实的能力。
这些非标准化的解决问题能力,还有从小练出来的跟人打交道的能力,恰恰是AI没有的,这些都是人独有的优势。
AI可以给你答案,可以帮你整理资料,可以生成一个看起来像样的方案,但它没有真实处境,没有人情分寸,也没有现场判断。
很多事情最后能不能成,靠的从来不只是答案对不对,还要看你能不能把人说动,把关系接住,把一件模糊的事慢慢做成。
我越来越强烈地感觉到,未来人与人之间真正拉开差距的,是你能不能在没有标准答案的情况下,把复杂问题拆开,把现有资源调动起来,再把结果做出来。
一个人如果从小到大都活在被安排好的轨道里,很容易把高分当成能力,把证书当成保障,把体制内外的某个位置当成人生的终点。
可现实不会永远按照试卷的方式出题。
真正进入社会以后,你迟早要面对那些没有参考答案、没有统一评分标准、甚至连题目都模糊不清的局面。
这也是为什么,我现在看很多年轻人一路埋头卷标准答案,心里会有点替他们着急。
因为他们以为自己在追求稳定,实际上追求的可能只是一个旧时代留下来的安全感幻觉。
普通人想要快速转成AI-native的思维,有三个可落地的路径。
第一个是先把英语学好,不用达到同声传译的水平,能看懂基本的英文文档,能跟全球的人正常交流就行。
现在很多新的AI工具、新的机会都是先在全球平台出现的,你能看懂英文,就能比别人早半年摸到机会。
第二个是别再死磕标准化的考试和证书,多去解决身边真实的问题。
比如老家的农产品卖不出去,你能不能试着用AI做宣传素材,找线上销路。
比如小区里的老人不会用智能手机,你能不能组织个小课堂教他们。
再小的问题都没关系,关键是你要真的下场。
你会发现,现实里没有哪个问题会像试卷一样,把条件、边界和答案都整整齐齐写给你。
现实里的大多数问题,都是一边做一边修,一边碰壁一边找路。
这些没有标准答案的事,你做多了,解决问题的能力自然就上来了。
第三个是学会用AI,不管你是做什么岗位的,都要试着让AI帮你干重复的活。
做文案的让AI帮你找素材列大纲,做设计的让AI帮你出初稿,做行政的让AI帮你整理报表。
你只需要负责提需求、判断结果好坏,效率能翻好几倍,也不用怕被AI替代。
很多人一提到AI就紧张,觉得它是来抢饭碗的。
可换个角度看,它更像一个被你调用的能力放大器。
你越早学会怎么提问、怎么拆任务、怎么判断结果,AI就越像你的助手。
你越抗拒,越不碰,它才越容易变成你的压力来源。
其实真的不用焦虑,AI废掉的从来不是人的机会,而是那些把人当机器用的岗位。
你以前追求的稳定,本质上是把你困在重复的劳动里,耗掉你所有的创造力和可能性。
很多人从小被教育要找一条最稳的路,最好这条路风险低、波动小、规则明确。
可问题是,今天这个时代变化太快了,外部世界已经不再奖励单纯的服从和重复。
你越早接受这一点,越容易从旧路径里走出来。
现在正好是个机会,去做那些你真正感兴趣的、能实实在在帮到别人的事,去跟同频的人建立信任关系,这些才是真正属于你的,谁也抢不走的稳定。
722
这两天我刷社媒发现,现在很多人认为,国内做AI还得看创业公司。其实真不是,虽然很多AI公司市值动不动破千亿,但大模型市场每天都在洗牌,最后头部玩家通吃可能是常态。
尤其是最近我看完几个业内权威榜单和阿里昨天的财报电话会纪要,越想越觉得现在市场对阿里,错估得不是一星半点。我做ai这一行快5年了,还是比较了解阿里的ai方面的实力,所以我还是想展开聊聊阿里。
1️⃣阿里的模型能力完全没有短板。LMSYS基于各公司最强模型对全球大模型公司进行排名,Anthropic、谷歌、xAI、OpenAI、阿里位居全球前五,位居中国大模型公司首位。
刚刚更新的LMArena榜单也很权威,国际机构LMSYS做的盲测,所有评分都来自全球开发者不知道模型品牌的两两PK投票,没有任何滤镜,公正性是业内公认的。
千问Qwen3.5-Max-Preview,仅仅是预览版首次亮相就拿了1464分,超过了GPT5.4、Claude sonnet4.5等海外顶流模型,也超过了所有国产模型,直接拿下中国第一。
[图片]
在考验模型绝对胜率(无风格控制)的全球总榜中,Qwen3.5-Max-Preview排名全球第六。细分能力里,数学能力排全球第五,专家级文本能力排全球第十,两个单项都是国内第一。
阿里除了旗舰款模型,今年除夕发布的千问3.5已经开源了8款不同尺寸的模型,从0.8B到397B全覆盖,不管你是做端侧的轻量应用,还是要企业级的超大算力部署,都能找到适配的版本。
现在还只是预览版,后续正式发布的旗舰版能力还会继续升级。
2️⃣战略优先级,阿里已经把AI拉到了集团最核心的位置,甚至专门成立了ATH事业群。
而昨天吴泳铭的电话会表态非常明确,当前ATH事业群的更高优先级是打造智能能力最强的模型。短短一天之后,阿里旗舰模型Qwen3.5-Max的预览版就惊艳登场,必然不是巧合,阿里AI战略正在有条不紊的推进中。
只有业内最强的模型才能支撑起阿里的AI叙事,才能驱动各行各业的应用场景拓展,并吸引各行各业的应用来使用阿里的Maas业务。
他们甚至给出了明确的量化目标,未来五年包含MaaS在内的云和AI商业化收入要突破1000亿美元,相当于再造一个阿里,可见其决心。
3️⃣增长空间完全打开。现在Agent时代已经开启,旗舰模型能力正在快速融入各个主流工作场景,各行业的token消耗量都在暴涨。
阿里作为全栈的AI基础能力提供者,能触达的市场规模会呈指数级增长。
昨天吴泳铭还提到,他们的百炼MaaS平台过去三个月的公共模型服务token消耗规模直接提升了6倍,吴泳铭也直接判断,商业化MaaS收入会成为阿里云最大的收入产品,市场天花板完全打开了。
现在市场上大家都在追那些估值炒得很高的AI创业公司,反而把阿里这种全栈能力都很强的玩家给漏了,现在的估值明显是被低估的。
AI行业不是短跑,是马拉松,拼到最后比的是长期的技术积累、稳定的供给能力、落地的商业场景,还有all in的战略决心。这些东西阿里现在都有,只是很多人还没反应过来而已。
1
1
433
我给普通人的建议是,家里有几口人买几件,作为“家服”,再定一个家规家训,比如用claude不用gpt的移出家庭群。

2026年,我对普通人的第二个投资建议, 我推荐大家 19 元拼多多买一件,平时在家里倒腾 AI 的时候时候穿,有额外隐藏 buff 加成的。就说这么多了,自己判断跟不跟吧。

361
前几天我见一个在深圳做外贸SOHO的朋友,工作日下午三点,他办公室里安安静静。
我本来以为现在外贸不好做,他多少会有点焦虑,结果他直接把后台翻给我看,最近几个月,询盘在涨,成交在涨,内容更新频率比以前更高,复盘表做得比请团队时还细。
这段时间我接触到好多这样的个体创业者,发现大家的模式真的变了。
以前总觉得要先凑齐三五个人,项目才算能启动。
现在很多人一个人加一套AI工具,就已经敢直接开干。
其实这也不是国内独有的现象,Economist和Wired去年都陆续发过专题,一人公司已经慢慢变成全球范围内越来越主流的商业叙事。
小成本创业这件事,确实已经正式进入AI红利期了。
前几年大家用AI工具时,最大的痛点都很像。
看起来功能很多,真要干活,还是得自己在不同软件之间来回跳转。
AI最多给你一个答案,真正落地执行还是得自己动手。
现在整个行业的方向已经明显变了。
Agent产品从去年开始,就在把重心从单次问答转向真实任务执行。
悟空刚好踩中了这个拐点。
它作为全球首个AI原生企业级Agent平台,把钉钉过去11年服务8亿用户、超2000万企业组织积累下来的能力,做了一次底层CLI化改造,让AI可以直接操作企业工作流,不需要再模拟人类点击图形界面。
说得更直白一点,就是直接给你配了一群能上手干活的执行人员。
而且和很多更偏个人效率工具的Agent不同,悟空本身就是为企业组织设计的,账号权限、数据访问、软件系统调用这些企业最敏感的问题,也被放进了底层能力里处理。
对B端来说,这种企业级安全能力是工具能不能真正进入日常业务流程的前提。
为了让这种企业级能力真正开箱即用,悟空同步发布了OPT(One Person Team)十大行业解决方案。
这是全球首个将AI Skill从技术概念落地为行业级产品的方案,并且以场景化 Skill 套件 预编排工作流交付,目前这套方案已经在三个很典型的单兵职业里跑通了。
第一类是跨境电商从业者。
以前最消耗人的,是每天盯热榜、找货源、做多语言物料、跟投放节奏、复盘数据。
每个环节单拆出来都不算难,真正烦的是事情又碎又多,来回切换特别耗神。
现在核心运营环节已经可以从原来的一周,压缩到一个下午。
第二类是独立律师。
这个群体的时间消耗其实非常重,白天跑客户,晚上做检索、写文书、改合同,很容易被高频重复劳动拖住。
现在文书生成、合同处理、法律检索这些高频工作,都能交给AI先跑一遍,自己只需要把控关键判断和风险点,就能腾出更多时间去接新案子。
第三类是自由设计师。
很多设计师真正累的地方,是创作之外那一大堆杂活。
谈单、沟通、排期、交付、改稿、收款、售后,每一样都要自己顶着。
AI把运营、客服、财务这类杂事接过去之后,设计师终于可以把更多精力放回核心创作。
这一点特别重要,因为创作者最值钱的,从来都是判断和审美,不该被一堆重复事务掏空。
这几个场景的用户数据显示,人均产出最高的已经翻了三倍。
这个数字背后真正有意思的地方,是很多原来必须靠团队完成的事,现在开始被一个人撬动了。
而且用起来没有大家想得那么复杂。
你不用专门花很多时间去学复杂的prompt技巧,也不用自己从零开始拼工作流。
直接选对应自己行业的开箱即用套件就行。
你真正需要做的事情,其实只剩三件。
做核心决策,验收最终结果,处理少见的例外情况。
剩下那些重复的、标准化的执行工作,都可以交给AI。
如果你在自己的行业里已经沉淀出了一套独家的经验方法,未来甚至不只是自己用。
你可以把这些经验封装成标准化的Skill技能包,要么在自己的小圈子里共享,要么上架到悟空的Skill市场,供别人付费调用。
其实就是把原来只能靠你亲自出场才能交付的经验,变成一个能被复制、被调用、被交易的数字能力。
这件事的想象空间其实很大,因为它让很多个人经验第一次有机会脱离时间出售。
再往后看一步,如果淘宝、天猫、1688、支付宝、阿里云这些阿里系B端能力陆续接进来,悟空还可能慢慢变成阿里ToB能力在企业工作场景里的统一入口。
到那时候,很多原本分散在不同系统里的能力,就有机会通过一个入口被直接调动起来。
所以我最近越来越强烈地感觉到,创业这件事的底层逻辑已经在变了。
以前我们讨论创业,脑子里第一反应永远是要招多少人、租多大场地、准备多少启动资金。
现在这些门槛,真的在被快速拉低。
你只要有核心的专业能力,再加一套OPT的AI团队,就已经可以直接启动项目。
更重要的是,商业的放大方式也变了。
过去扩大产能,通常意味着继续招人、继续管理、继续堆成本。
现在你把自己的经验沉淀成可复用的Skill包之后,卖一万份和卖一份,边际成本几乎没有差别。
这就等于多了一条非常长的变现路径。
现在商业竞争的基本单位,已经越来越不是看你公司有多少员工,而是看你能调动多少自动化能力。
谁能更快把经验流程化、把流程工具化、把工具变成稳定产能,谁就更容易在这个阶段跑出来。
对于所有想做小成本创业的普通人来说,这真的是一个前所未有的机会。
你不用再被团队、资金、场地这些外部条件死死绑住手脚。
只要你手里真有一技之长,再配上一套能执行的AI系统,你的能力就有机会被放大很多倍。
接下来真正拉开差距的,是谁更早把自己变成一个可以被持续放大的超级个体。
1
1
3
1,043
今天早上我摸鱼刷社媒,刷到一条消息,说阿里新上了AI激励计划,直接给每个人发专属Token额度。
很多人会以为,这就是大厂蹭AI热度搞的福利噱头。
真不是。
你仔细看阿里这次启动的这个内部AI激励计划,给员工发专属Token额度,悟空、Qoder这些内部付费AI工具全部免费用。
员工买百炼Coding Plan会员或者外部的AI开发工具,还能直接申请报销。
相当于只要你想在工作里用AI,所有成本公司基本都帮你兜了,你只管用来提效就行。
前阵子腾讯的朋友跟我讲过类似的事,说今年公司给每个人配了价值22万元/人的Token额度,让他们使劲用。
Cursor、Claude、GLM这些现在开发者圈子里抢着用的热门工具和模型,全都包含在内。
这俩国内最顶级的互联网公司,花这么多钱给员工配AI工具,肯定是算过账的。
这其实是顺着开发者原本的使用习惯来的。
Stack Overflow 2025年开发者调查的数据显示,84%的受访者已经在使用或者计划使用AI开发工具,职业开发者里有50.6%已经把AI工具纳入日常工作流。
很多程序员写代码之前先找AI理逻辑,修bug先扔给AI排查,已经是常态了。
之前很多员工为了用顺手的AI工具,都是自己掏腰包充会员,现在公司直接把成本包了,相当于把大家本来就有的需求,直接变成了公司层面的标配支持,所以这件事真正落地的阻力并不大。
另外,AI编程是现在少有的能直接跑通ROI的生成式AI场景。
现在生成式AI很多场景的回报都还比较模糊,只有软件开发相关的AI工具,是已经被验证过确实能提效的。
GitHub Copilot 2024年的收入超过5亿美元,用户量破1500万,就是很好的证明。
你想,一个工程师一年的人力成本大几十万,公司花几万块给他配齐所有AI工具,只要他的产出能提升10%,这笔钱就赚回来了,更别说很多熟练用AI的开发者,产能能提升30%甚至更多。
这笔账谁都会算。
大厂做这件事的逻辑也很清晰,本质上就是在鼓励员工,也在倒逼员工,把AI深度融入到日常工作的每一个环节,不要考虑工具成本,只考虑怎么用工具把活干得更快更好。
现在很多大厂的面试,已经会问你平时用什么AI开发工具,熟练程度怎么样,会不会用AI提效。
这已经不是加分项,是必备项了。
我之前还看到有人讨论,发AI工具的Token会不会成为未来大厂的标配福利。
现在看这个趋势已经很明显了,头部都已经跑通了模式,后面的公司跟上只是时间问题。
本质上大厂现在拼的已经不是员工数量,是单个员工的产能。
同样的岗位,会用AI的人一个人能干以前两个人甚至三个人的活,那公司当然愿意在工具上砸钱,把每个员工都武装成超级员工。
对我们普通职场人来说,这个信号更值得注意。
现在还觉得AI是噱头,不愿意花时间去熟悉AI工具的人,再过一两年就会发现,身边的人产出是你的好几倍,你连竞争的资格都没有。
毕竟人家背后有一整套AI工具当助攻,你还在靠手动熬时间,怎么比?
超级大厂都在砸钱帮员工变成超级个体,我们自己更得跟上。
1,120