
Joined November 2022
- Tweets 136
- Following 994
- Followers 574
- Likes 539
72 Photos and videos















Pinned Tweet

30 Sep 2025
Fast insights from your single-cell datasets, without the coding bottleneck.
With Platforma, you can explore single-cell multiomics without writing a single line of code:
🔹 Navigate UMAPs from single-cell transcriptomics with ease
🔹 Switch between Leiden clustering and cluster-specific filtering
🔹 Combine transcriptomics with VDJ metrics like CDR3 length or sequence labels
🔹 Visualize clonotype clusters and sequence similarities at scale
🔹 Overlay gene expression data within any cluster for deeper biological insights
🎥 Watch the demo below to see how Platforma transforms single-cell analysis.
3
316
Are antibody heavy and light chains really randomly paired, or are there rules?
This week in our latest High Affinity Talks, we sat down with @JosefNg1, Group Leader at UCL, who's dedicated years to answer that question. The short version: there are rules, you can learn them from single-cell data, and you can turn them into a score.
That score is ImmunoMatch. And for drug discovery scientists, it could be a new way to rank candidates before functional validation. Not just to filter liabilities, but score compatibility.
In this clip, we discuss exactly that.
1
1
127
Our next High Affinity talks is coming up tomorrow! 🎙️
We're welcoming Joseph Ng, Lecturer & Group Leader at UCL's Department of Structural & Molecular Biology, who will be sharing how computational immunology and AI are reshaping our understanding of B cell biology.
A core challenge he'll tackle: how do heavy and light antibody chains "choose" each other? His team built ImmunoMatch, a machine learning framework trained on paired human B cell sequences to predict chain compatibility and trace its role in B cell development and maturation.
Register here: luma.com/g1xmha0g?utm_source…
79
Feb 12
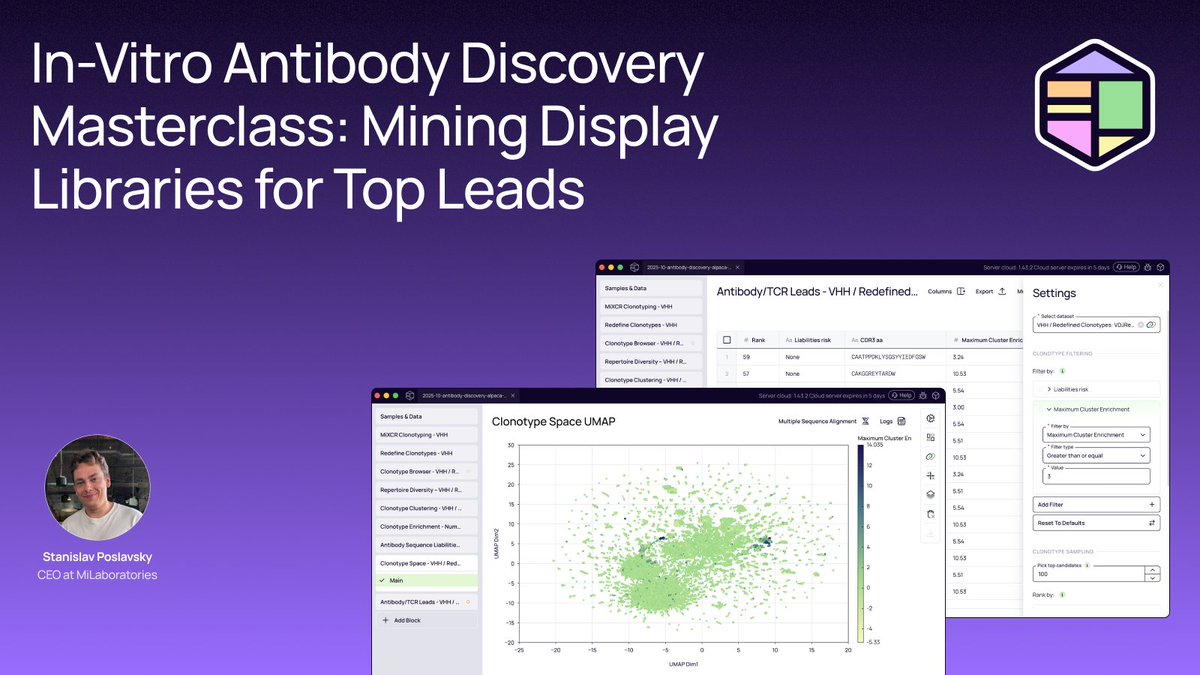
Antibody discovery is moving fast.
But too many teams are still slowed down by fragmented tools, custom scripts, and bioinformatics bottlenecks. If your analysis cycles take weeks, you're already behind.
That’s why we're hosting a virtual masterclass on how leading pharma and biotech teams are accelerating lead selection.
We’ll walk through practical, end-to-end workflows to help you:
• Use clustering and motif-level analysis to uncover emergent clones
• Track enrichment, liabilities, and clone dynamics across rounds
• Prioritize candidates based on developability to de-risk programs early
• Move from hundreds (or thousands) of sequences to best-in-class leads — without coding
Sign up here: bit.ly/4ajVyVS
1
66
Choosing an Antibody Discovery Platform: A 2026 Landscape Review
In our latest deep dive, we compare the current leaders in the space to see how they stack up based on five key criteria:
- End-to-end workflow coverage
- Scientist-first usability
- Functionality and visualizations
- Computational throughput
- Data control and deployment flexibility
bit.ly/3LSJFhP
1
60
Jan 29
The most valuable AI tool in antibody discovery right now isn't "generative." It's a filter.
Many are claiming gen AI designs perfect drugs from scratch. Walk into a real antibody discovery lab, and the goal is much more grounded: Survival.
We don't need AI to generate 10,000 more "novel" sequences that we can't manufacture. We need AI to look at the 10,000 candidates we already have and predict which ones will turn into brick dust in a bioreactor.
The biggest ROI in antibody engineering right now isn't creativity. It’s *Negative Selection*.
It’s the ability to kill bad clones in silica—checking for aggregation, viscosity, and solubility—before you waste a single pipette tip.
A model that saves 3 weeks of failed wet-lab experiments is worth 10x more than a model that hallucinates a "perfect" binder that crashes out of solution.
1
86
Jan 21
The analysis gap is the biggest bottleneck in antibody discovery.
Too often, teams must choose between fragmented scripts or opaque black-box tools.
Our application note details how we enable:
- Deep repertoire sequencing to reveal submerged diversity invisible to shallow screens
- Functional clustering to reason about lineages rather than individual reads
- Developability assessment and diversity-first selection to reduce redundancy and risk
blog.platforma.bio/p/streaml…
1
66
Jan 15
The "Generative Tax" in Antibody Discovery
We are currently generating "Schrödinger’s Antibodies."
Until physically tested, every AI-generated sequence exists in a quantum state: potential breakthrough or confident hallucination.
To resolve this state, we rely on "lab-in-the-loop." But there is a cost to that resolution.
This is the "Generative Tax."
Right now, many teams are using their high-throughput capacity just to filter out developability issues.
Even if AI allows us to screen smaller libraries, if a significant portion fails basic aggregation or solubility checks, you are paying tax on your lab capacity.
AI is undeniably shifting how we design libraries to lower this tax. And there is a growing divide on how:
- The "Data Scale" Camp: "Screen more. Feed the model until it learns the physics implicitly."
- The "Physics-First" Camp: "Simulate reality (MD/FEP) before the lab." Companies like Schrödinger and SandboxAQ are betting on validating the physics in silico to clean the list before synthesis.
There is also a third reality on the ground: The "Tax" is being paid by the scientists validating massive libraries with legacy analysis tools.
Regardless of whether you trust the Data or the Physics, the goal is the same: Stop hoping the cat is alive, and start predicting why it survives.
When you screen AI-generated libraries vs. natural immune libraries, are you seeing a higher "Generative Tax" (lower developability)? Or has the gap closed?
41
Jan 14
Excited to host our first webinar of the year: From Sample to Insight: Streamlining TCR Repertoire Analysis
We're partnering with @miltenyibiotec for an exclusive webinar featuring their newly launched, next-generation bulk RNA library preparation solution for TCR α/β profiling with advanced analysis and visualization in Platforma.
Register here: luma.com/zw6325mq?utm_source…
62
Ten years ago, immune repertoire sequencing felt like something only a handful of highly specialized labs were doing.
Fast forward to today, and the picture looks very different.
1
28
Using insights from 3.5M processed TCR/BCR sequencing samples over the past two years on MiXCR, we looked at what’s really happening across the field of immune repertoire analysis: the shift from isolated discovery to high-throughput, population-scale biology:
➖ Bulk amplicon sequencing remains the primary operational standard and "workhorse" of the industry due to its cost-efficiency and scalability
However, single-cell analysis is growing faster (over 50% annually), with 10X Genomics holding 75% share
➖ Academia favors "home-brewed," in-house protocols, while industry has aggressively pivoted toward standardized commercial protocols to ensure reproducibility and regulatory compliance
➖ The field is splitting into two clear paths: Academia drives discovery through deep, custom-designed protocols, while Industry drives translation and real-world application through standardization
1
48
As we move into the next era of immune profiling, the focus will shift from simple data accumulation to integration: combining bulk structure with single-cell resolution to decode the immune system with unprecedented clarity.
Read the full article here: blog.platforma.bio/p/the-sta…
1
29
The most valuable AI tool in antibody discovery right now isn't "generative." It's a filter.
Many are claiming gen AI designs perfect drugs from scratch. Walk into a real antibody discovery lab, and the goal is much more grounded: Survival.
We don't need AI to generate 10,000 more "novel" sequences that we can't manufacture. We need AI to look at the 10,000 candidates we already have and predict which ones will turn into brick dust in a bioreactor.
The biggest ROI in antibody engineering right now isn't creativity. It’s *Negative Selection*.
It’s the ability to kill bad clones in silica—checking for aggregation, viscosity, and solubility—before you waste a single pipette tip.
A model that saves 3 weeks of failed wet-lab experiments is worth 10x more than a model that hallucinates a "perfect" binder that crashes out of solution
33
18 Dec 2025
What a year for our global research community!
Here’s a look at what we achieved together in 2025:
➖ 1.5 petabytes of data were processed with our technology — a 50% year-over-year increase and a whole lot of discovery
➖ We welcomed 2,400 new users to our community
➖ We reached 375 new institutions, including all 50 of the top research institutions
➖ We expanded our reach to new countries from Bangladesh to Peru.
➖ 741 publications citied our technology - a testament to the impact our platform is having across the scientific ecosystem
➖ Behind the scenes, we’ve also expanded our teams, launched our blog, shipped 30 new biological blocks!
We’re proud to support innovation wherever science happens. Here’s to an even bigger 2026!
1
2
51
11 Dec 2025
What if we’ve been studying TILs wrong?
The tools we use to study tumor-infiltrating lymphocytes may have been altering them all along, introducing a bias that often masks their true therapeutic potential. By limiting in-vitro manipulation, a new paper reveals a better picture of how TILs behave in breast cancer.
Key Findings
➖ Using a low-intervention “minimally cultured” TIL protocol, the study demonstrated that areas of high TIL infiltration did not consistently favor a single T cell subset, with both CD4 and CD8 T cells frequently co-existing in these regions
➖ Low TIL infiltration often contained a higher proportion of CD4 T cells, which was inversely correlated with cytotoxic molecules, suggesting reduced anti-tumor potential.
➖TCR repertoire analysis revealed that CD4 T cells had a significantly less diverse repertoire and specific molecular features compared to CD8 T cells
MiXCR was the leading tool used to precisely quantifying the diversity and molecular features of the minimally expanded TIL populations to identify those with the highest therapeutic potential.
41
10 Dec 2025
Antibody discovery becomes far more powerful when functional assay data and NGS are brought together.
Last week, we demoed Platforma’s antibody space, where we overlay immune assay targets with clonotypes. As soon as we highlight clones from the functional assay, enriched populations immediately stand out, validated by functional screening.
By unifying functional readouts with sequence-level data, teams get a more confident starting point. Instead of running enrichment and functionality separately, you can pinpoint high-value hits and confirm performance directly within clonotype diversity.
With a single visualization, you see functional confirmation aligned with NGS for faster insights and better downstream decisions.
1
45
9 Dec 2025
Last week during our antibody discovery webinar, we gave a live demo of Platforma’s Antibody Lead Selection block.
Unlike the common “Top N” approach, which can bias selection toward a single dominant family, we use a Diversity-First algorithm to mitigate risk: it clusters sequences into families, picks the top representative from each, and fills your target number of leads while ensuring broad biological diversity.
Coupled with other filters for sequence liability and enrichment scores, this decision funnel guarantees a panel of leads that are both enriched and biologically diverse.
Couldn't make it to our webinar? Watch the recording on-demand: youtube.com/watch?v=hhsLB5Rh…
1
35
2 Dec 2025
Last chance to register for our antibody discovery webinar tomorrow!
We’ll cover how to:
• Uncover emergent clones & immune responses
• Track enrichment, liabilities, and clone dynamics
• Predict structure & affinity directly from sequence
• Go from thousands of sequences → top leads without coding
Sign up here: bit.ly/4oVepwJ
🗓️ December 3rd @ 11 AM EST / 5 PM CET
46
27 Nov 2025
Wrapping up our last Platforma Pioneers workshop of the year at Boston Children’s Hospital!
Joining forces with over 40 members of the Harvard network, our team helped spark collaboration and share knowledge.
During the workshop, they demonstrated how Platforma empowers biologists to run their own downstream analyses using powerful, user-friendly tools.
Thank you to @BostonChildrens for hosting us!
1
41
25 Nov 2025
Want to learn more about how top teams combine sequence, functional, and structural analysis to prioritize true therapeutic candidates?
Join our webinar next week.
bit.ly/4oVepwJ
🗓️ December 3rd @ 11 AM EST / 5 PM CET
25 Nov 2025

What everyone in antibody discovery should know:
1. How to combine NGS with functional assay data to reveal truly high-potential clones, not just the most enriched ones
2. Not all lead candidates are therapeutic candidates — can you spot the true winners?
3. Prioritize developability from the start. Spot sequence liabilities early to protect and derisk your pipeline.
85
25 Nov 2025
What everyone in antibody discovery should know:
1. How to combine NGS with functional assay data to reveal truly high-potential clones, not just the most enriched ones
2. Not all lead candidates are therapeutic candidates — can you spot the true winners?
3. Prioritize developability from the start. Spot sequence liabilities early to protect and derisk your pipeline.
139