
Software branch of @Strategy. We build Strategy Mosaic, the enterprise semantic layer powering trusted, governed data for every BI tool, app, and AI agent.
Joined May 2008
- Tweets 13,465
- Following 3,081
- Followers 303,415
- Likes 6,403
4,006 Photos and videos



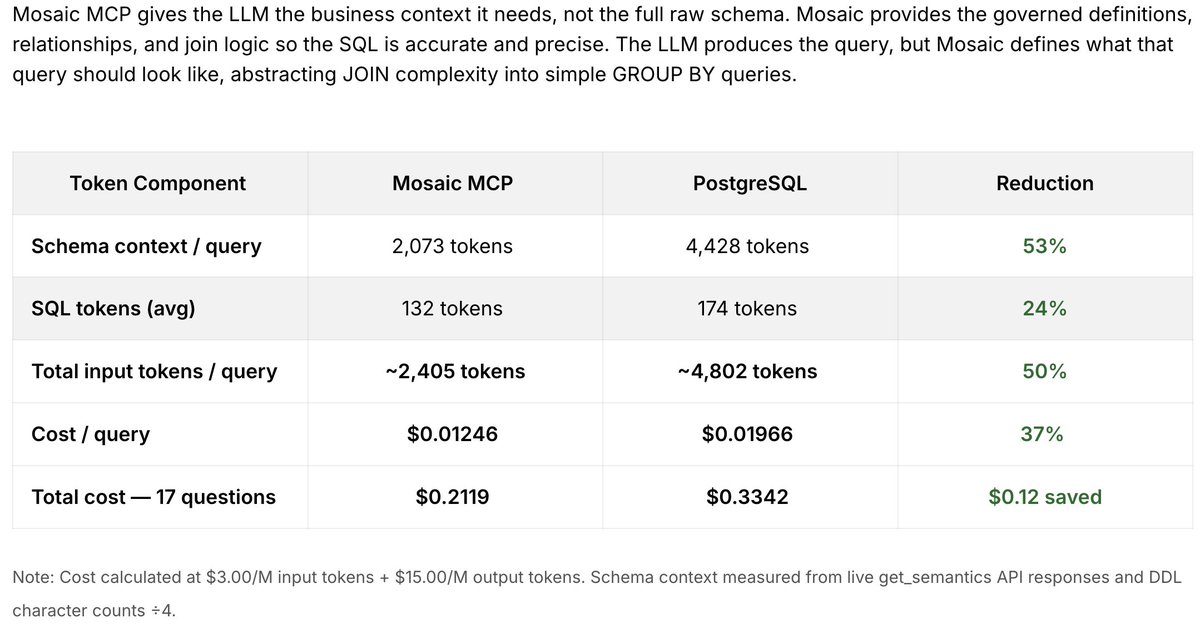













Jun 12
Join us for a live webinar led by Nathan Downs where we'll put Strategy Mosaic and AtScale head-to-head across the areas that matter most for modern data and AI teams.
Register now: ow.ly/IWVz50Z7GPn
#SemanticLayer #DataGovernance #EnterpriseAI #DataArchitecture #Analytics
4
6
33
3,802
Jun 12
🤖 What does a Sales Engineer actually do?
In this clip, Joe Bullis, VP Technical Evangelist at Strategy, shares insights from his career journey from the U.S. Army to the executive team at a global software company, along with lessons learned along the way.
Watch the full interview on YouTube: ow.ly/bjQu50ZaYxU
#SalesEngineering #TechCareers #CareerGrowth #EnterpriseSoftware #LifeAtStrategy
5
33
5,545
Jun 10
The scariest AI failures aren't the obvious hallucinations, they're the answers that look completely reasonable.
Everything runs exactly as intended. The SQL executes, the chart renders, the report is shared, and a business decision is made. No errors or warnings. Then, four days later, someone realizes the numbers were completely wrong.
We ran a benchmark against a complex 28-table insurance data model to see how often this happens.
Direct text-to-SQL returned plausible-looking business logic errors. In one case, it returned a result nearly 8x HIGHER than the correct answer. In another, costs from one policy were silently attributed to a completely different one.
Mosaic, on the other hand, answered every single question correctly.
Once bad data makes it into a report, nobody blames the AI. They blame the person who published it.
TL;DR: Mosaic answered every question correctly. Direct SQL returned numbers that were off by 8x, with no error to flag it.
See the full methodology and results here: ow.ly/Z2tE50Z9RNv
We'd love to hear how other teams are approaching this.
#SemanticLayer #EnterpriseAI #DataGovernance
13
14
142
13,483
Jun 10
🌟 We’re onsite for Day 2 of Strategy World London 2026!
Today’s focus is on a key question: how do you build the foundation that makes AI trustworthy, scalable, and genuinely useful across the enterprise? 📊
It’s a full day of keynotes, customer stories, and expert sessions exploring what it really takes to become AI-ready.
Learn more here: ow.ly/f9vX50Z9eXq
#EnterpriseAI #DataGovernance #Analytics #BusinessIntelligence #SemanticLayer



5
6
44
4,758
Jun 10
Join Erika Moreno, VP of Product Management at Strategy, on June 18 at 12 PM EST for an inside look at the Mosaic roadmap and where the semantic layer category is headed in 2026.
Register now 👉 ow.ly/J72h50Z7s0q
#EnterpriseAI #SemanticLayer #DataGovernance #AIReadiness #Analytics
4
25
4,168
Jun 9
🚀 We are on-site for Strategy World London 2026
Join us for the Strategy Workshop today at BAFTA and explore how leading organizations are building AI-ready foundations with governed data, business context, and the Universal Semantic Layer.
Learn more here: ow.ly/Tcqm50Z9l9A
#EnterpriseAI #DataGovernance #Analytics #BusinessIntelligence #SemanticLayer


6
38
4,599
Jun 8
We created Strategy AI for Business Users: Getting Started. A free, 25-minute course designed to help business users start working with AI in their everyday workflows.
It's the easiest 25 minutes you'll invest all week, enroll now and get a head start as AI becomes everyone's must-have skill: ow.ly/T8ZK50Z7rLC
#AI #BusinessIntelligence #StrategyAI #DataAnalytics
5
6
54
5,689
Jun 5
The questions that actually separate production-grade from pilot-grade are specific: Does governance enforce automatically across every connected tool, or does it need to be configured per tool?
There's a phrase worth keeping in mind: the code runs isn't the same as the data is right.
Most platforms will answer yes to all of it in a meeting. Ask for the production references.
[LINK BROKEN!!] 📖 Read now: strategy.com/software/blog/s…
#SemanticLayer #EnterpriseAI #DataGovernance #DataArchitecture #AIInfrastructure
3
4
41
7,212
Jun 5
📢 Mosaic Summit Amsterdam is happening on June 18!
Join us as we bring together industry leaders, customers and experts to explore how organizations are building a consistent, governed foundation for analytics and AI.
📍 The Hoxton, Amsterdam
📅 18 June 2026 | 13:30 – 19:00
Register now: ow.ly/4fVi50Z7rWV
#EnterpriseAI #DataGovernance #SemanticLayer #Analytics #MosaicSummit
1
5
27
5,504
Jun 4
In this upcoming webinar, Sophie Da Silva, Education Delivery Manager at Strategy, explores what comes next after the fundamentals.
Learn how to refine agent behavior through advanced tuning, integrate unstructured data, and build agents that can handle changing business requirements with greater accuracy and consistency.
Last chance to register: ow.ly/lTxL50Z5gMO
#AIAgents #EnterpriseAI #ArtificialIntelligence #MachineLearning #DataIntegration
2
4
31
5,326
Jun 4
🎤 We'll have Gábor Zsolnai, Diageo's Senior Product Manager leading the customer spotlight at Strategy World London at 11:15 AM!
Learn more about turning AI into real business value and scaling governed AI across global organizations, don't miss Strategy World London from June 9–10.
Register now: ow.ly/yvQ350Z7rNY
#EnterpriseAI #AITransformation #DataStrategy #DigitalTransformation #StrategyWorldLondon
4
27
4,670
Jun 3
In this recent blog, we share key takeaways from the discussion, including why organizations scaling AI successfully are investing in governed semantic layers, centralized business definitions, and traceable AI outputs before expanding adoption.
Read to find out what separates successful AI adopters from those struggling to scale: strategy.com/software/blog/f…
#EnterpriseAI #DataGovernance #SemanticLayer #CIO #DataStrategy
3
9
74
7,891
Jun 2
Strategy World London 2026 is almost here!
We're especially looking forward to PokerStars' session on turning growing data complexity into actionable insight.
Alongside customer stories like this, Strategy World London brings together data, analytics, and AI leaders for two days of expert sessions, hands-on workshops and product innovation.
Register here: ow.ly/GEWL50Z5gGG
#StrategyWorld #EnterpriseAI #BusinessIntelligence #DataAnalytics #SemanticLayer
5
7
48
9,347
Jun 1
Join Strategy and Agiliz at Mosaic Summit Amsterdam 2026 on June 18th for an afternoon of executive insights, customer perspectives and discussions around the future of analytics, governance and AI.
Register here: ow.ly/5lkY50Z4O6J
#StrategyMosaic #AIInnovation #SemanticLayer #DataGovernance #Analytics #EnterpriseAI
7
4
35
10,385
May 29
We built the Strategy Mosaic Semantic Layer Comparison Hub to make the evaluation easier, a framework for comparing Mosaic against AtScale, dbt Labs, Denodo, and Looker across the criteria that actually matter: governance, AI readiness, federation, self-service modeling, and pricing transparency.
Check it out here 👉 ow.ly/wRqz50Z4lOr
#DataStrategy #SemanticLayer #EnterpriseData #BusinessIntelligence #AIReadiness
4
5
48
10,010
May 28
Join Strategy's Education Delivery Manager, Sophie Da Silva, at our next webinar and learn how to fine-tune agent behavior for more precise, reliable outputs. You'll be able to integrate and process unstructured data to expand what your agent can do and build agents that flex and adapt to dynamic business needs.
Register today: ow.ly/2xyO50Z59Kj
#AIAgents #ArtificialIntelligence #DataIntegration #EnterpriseAI #MachineLearning

2
4
30
7,682

May 27
Enterprise AI needs more than orchestration, observability, and audit logs.
It needs a governed semantic layer that delivers consistent, trusted context across dashboards, AI agents, and enterprise workflows.
Read the full blog here to understand what governed context actually means at enterprise scale: ow.ly/1mpj50Z1NUa
#EnterpriseAI #SemanticLayer #AIInfrastructure #DataGovernance #GenAI

3
7
33
6,308
May 26
At the Mosaic Summit, we’re moving beyond the hype. We will show you how Mosaic acts as a "Universal Intelligence Layer," enforcing common business definitions to eliminate inconsistencies and build trust in your AI outcomes.
View the Agenda and Register Now! ow.ly/u03v50Z45Aw
#Sydney #Melbourne #AI #Data #Mosaic #Semantic Layer

2
4
31
6,005