
341 Photos and videos
















Pinned Tweet

11 Mar 2025
🔹 Bullish? Bearish? Nah. We’re going MOOSISH. 🫎🚀
Strong, steady, and unstoppable—no weak hands, no panic, just conviction.
Are you #Moosish enough? 💎
#CryptoMoose

1
4
700
Cryptomoose retweeted

Jun 3
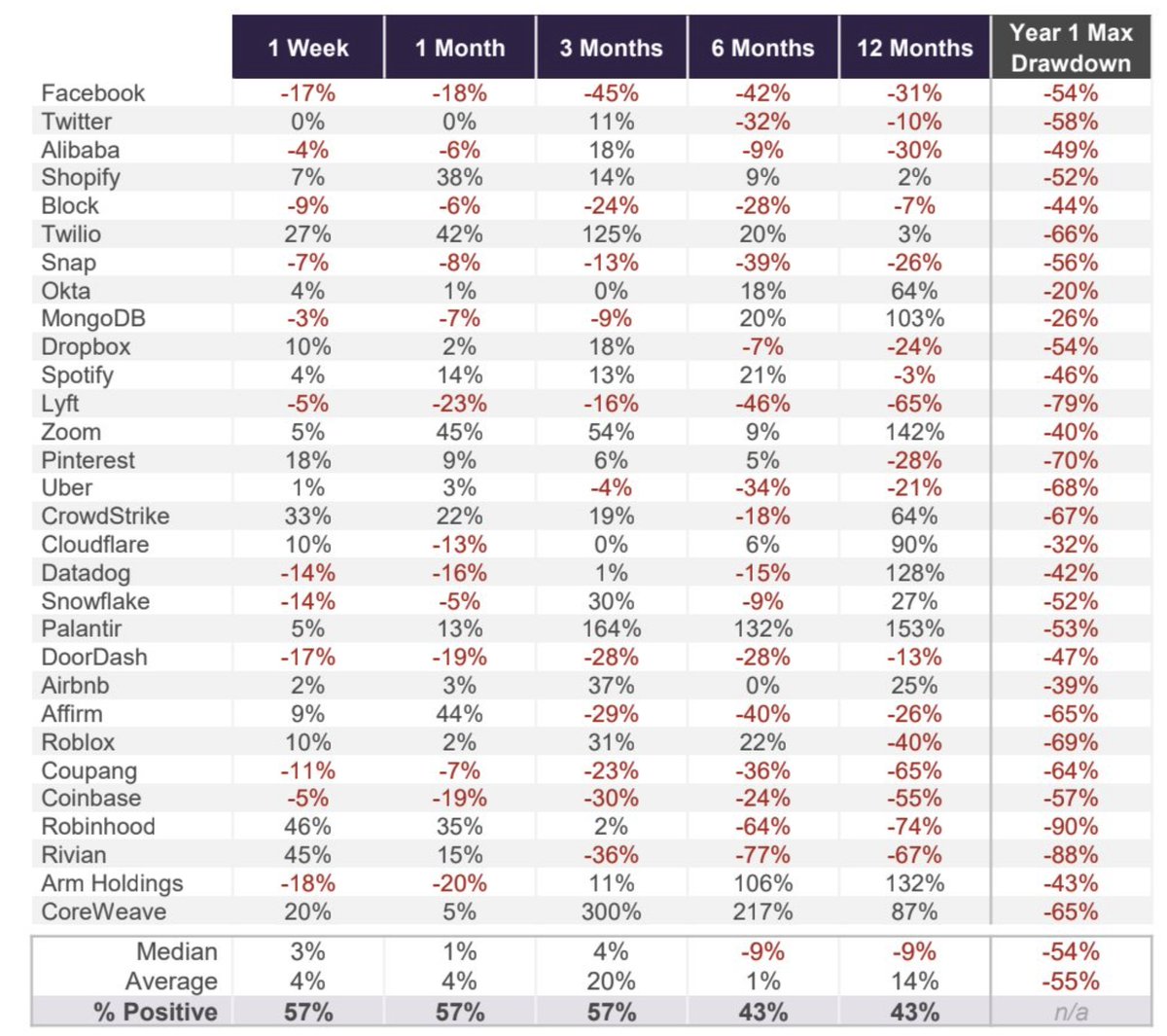
Moral of the story - do NOT chase hot IPOs
Year-1 average drawdown = 55%
Year-1 median drawdown = 54%
Table: Truist
198
545
3,605
684,381
Cryptomoose retweeted

May 16
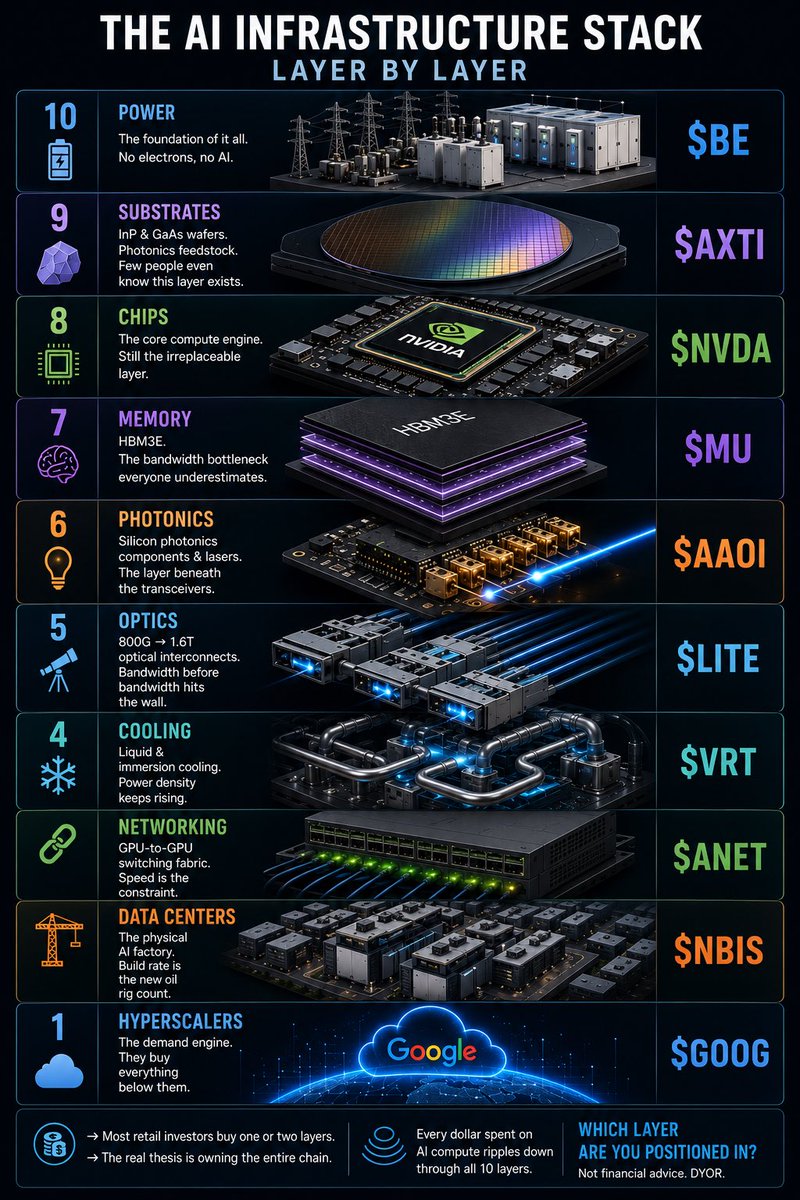
One AI Supercycle -
10 Layers. 10 Tickers.
Layer 1 — Power | $BE
A single AI data center can consume 100–500MW. The US grid wasn’t built for this. Bloom Energy sits at the intersection of distributed power generation and the insatiable energy appetite of hyperscalers. Power is the foundational constraint — before chips, before cooling, before anything else.
Layer 2 — Substrates | $AXTI
InP (Indium Phosphide) and GaAs (Gallium Arsenide) wafers are the raw material for photonic components — lasers, modulators, detectors. AXT Inc supplies these specialty substrates to the photonics supply chain. Demand is structurally rising as Co-Packaged Optics (CPO) and 1.6T transceivers scale. Tight supply, long qualification cycles, few alternatives.
Layer 3 — Chips | $NVDA
H100. H200. Blackwell. Each generation widens the moat rather than narrowing it. CUDA lock-in is one of the deepest competitive advantages in tech history. $NVDA isn’t just a chipmaker — it’s the operating system of the AI era.
Layer 4 — Memory | $MU
HBM3E (High Bandwidth Memory) is the bandwidth interface between the GPU and data. Without it, the most powerful chips in the world are throttled. Micron is one of only three companies globally that can produce HBM at scale — alongside SK Hynix and Samsung. Supply is tight. ASPs are rising. The AI upgrade cycle is a multi-year HBM demand wave.
Layer 5 — Photonics | $AAOI
As data centers scale from 400G to 800G to 1.6T optical speeds, the components inside transceivers — lasers, modulators, detectors — face an exponential demand surge. Applied Optoelectronics is a pure-play photonics manufacturer benefiting directly from this cycle. Margin expansion volume ramp = a powerful setup.
Layer 6 — Optics | $LITE
If photonics makes the components, optics assembles them into the interconnect.
Lumentum is a leader in optical networking — coherent transceivers, 3D sensing, EML lasers. The 800G → 1.6T transition is a hardware replacement cycle that touches every hyperscaler and co-lo data center globally. This isn’t incremental demand. It’s a full network overhaul.
Layer 7 — Cooling | $VRT
Vertiv designs and manufactures liquid cooling, immersion systems, and thermal management infrastructure for high-density AI racks. As GPU power density climbs past 1kW per chip, traditional air cooling fails. Vertiv is already embedded with the largest hyperscalers. Backlog is growing. Lead times are extending.
Layer 8 — Networking | $ANET
Arista Networks builds the high-speed Ethernet switching fabric that connects thousands of GPUs inside AI training clusters. Their software-defined architecture and 400G/800G switching platforms are designed for exactly the traffic patterns AI workloads generate. AI networking is a separate, incremental growth vector on top of their already dominant enterprise business.
Layer 9 — Data Centers | $NBIS
Nebius Group is building AI-native data centers — purpose-built for GPU density, liquid cooling, and low-latency networking. Unlike legacy co-los retrofitting old facilities, Nebius is starting from scratch for the AI era. Backed by Yandex’s original infrastructure DNA, they’re scaling fast in a market where capacity is chronically constrained.
Layer 10 — Hyperscalers | $GOOG
Google has committed $75B in capex for 2025 alone. Their TPU buildout, data center expansion, and AI product integration (Gemini, Search, Cloud) make them both a consumer and a builder across the stack. Every dollar they spend flows down through layers 1–9.
The AI supercycle isn’t a software story — it’s a physical infrastructure buildout that rivals the railroad era. Every layer of this stack is capacity-constrained, capital-intensive, and structurally undersupplied relative to where demand is heading. Most investors own one or two names at the top of the stack. The opportunity is in understanding all 10 layers — and sizing accordingly.
Not financial advice .
14
278
1,016
58,970
Cryptomoose retweeted

CEO $NVDA says to buy sustainable energy stocks.
$ENLT is the strongest with price target $400 Its spiked $15 to $90 for 600% already.
Right now, these 16 stocks have the exact set-up:
1. $PLUG — Price: ~$3.76 | Target: $30
Green hydrogen fuel cells deliver clean, on-site backup power for AI data centers bypassing overloaded grids entirely.
2. $FLNC — Price: ~$20 | Target: $65
Grid-scale battery storage keeps renewable power stable and uninterrupted for 24/7 AI data center operations.
3. $ARRY — Price: ~$10 | Target: $40
Solar tracking systems maximize output at utility farms directly powering AI data center campuses nationwide.
4. $SHLS — Price: ~$10 | Target: $32
Electrical balance-of-system components connect large solar farms to the grid that powers AI infrastructure.
5. $RUN — Price: ~$14.00 | Target: $50
Distributed home solar and storage cuts grid strain during peak AI-driven electricity demand surges.
6. $CSIQ — Price: ~$17.87 | Target: $80
Utility-scale solar modules and grid-scale battery storage systems feed clean power into AI-hungry electrical grids.
7. $BEP — Price: ~$35 | Target: $200
Global hydro, wind, solar & nuclear operator $BE
partnered with Bloom Energy in a $5B deal to co-build AI power factories.
8. $CWEN — Price: ~$38 | Target: $120
10 GW of contracted wind, solar & storage sells clean baseload power directly to hyperscaler data centers.
9. $JKS — Price: ~$25.00 | Target: $50
One of the world's largest solar manufacturers supplying panels to utility farms feeding the AI power grid.
10. $DQ — Price: ~$20.00 | Target: $35
Polysilicon feedstock producer enabling solar panel manufacturing that powers AI data center campus buildouts.
11. $HASI — Price: ~$42 | Target: $80
Finances solar, wind & storage projects supplying contracted clean power directly to AI data center operators.
12. $EOSE — Price: ~$8 | Target: $24
Long-duration zinc batteries solve renewable intermittency enabling always-on clean power for non-stop AI workloads.
My top 3 favorite ones to buy and hold would be $PLUG, $ENLT and $BEP since they have a deal with $BE.
BONUS, I really like $ENPH (look how beaten down it is) at $53. It could run towards $300 again.
♻️RESHARE this post and make 1 comment for my list of sustainable energy companies under $10. There's only 5 good ones like $PLUG to choose from.

127
705
3,504
386,032
Cryptomoose retweeted

Feb 24
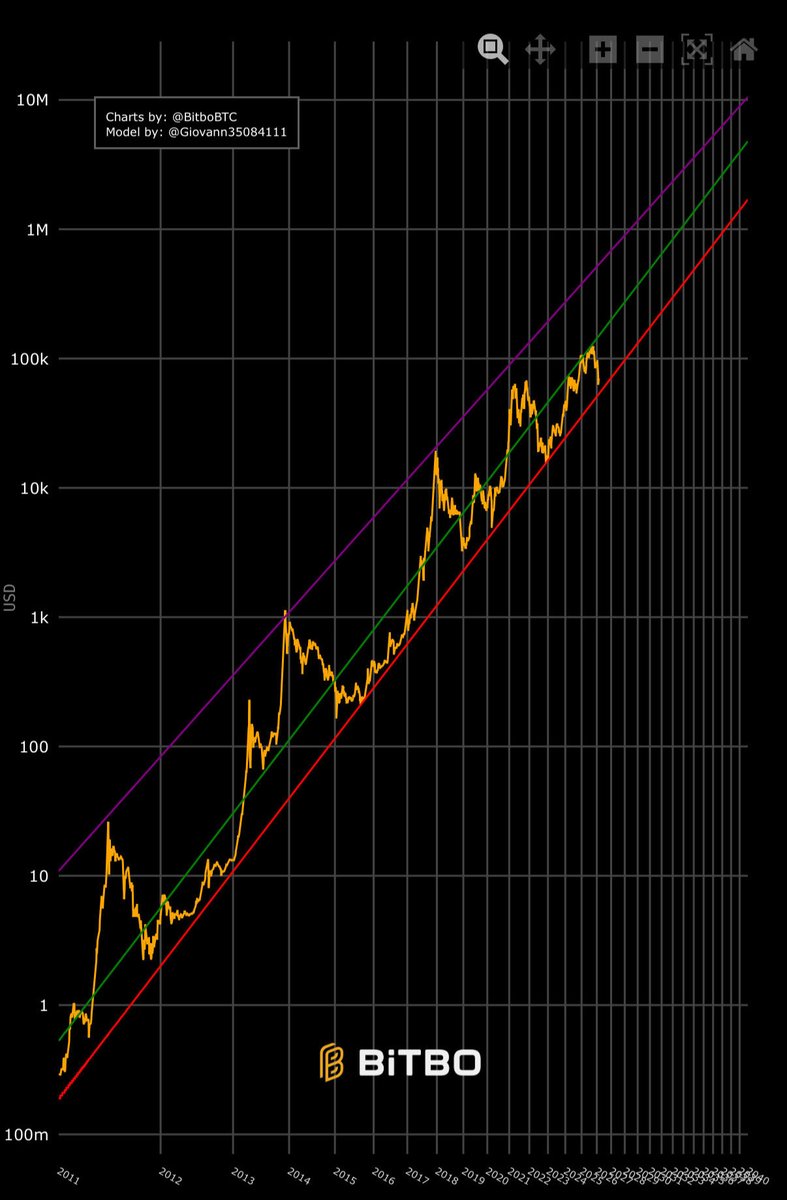
Bitcoin is going to ZERO for the last 17 years.
158
259
1,725
58,777
13 Nov 2025
$BTC might dip, but CryptoMoose doesn’t flinch. The market shakes — the moose stands tall. 🦌⚡ #CryptoMoose #BTC
32
Cryptomoose retweeted

4 Sep 2025
V2 awakens on September 10th 2025.
76
139
426
62,312
Cryptomoose retweeted

18 Jul 2025
The new Node Sphere AI website is live.
This version wasn’t assembled. It was written.
It reflects how we build product:
purposeful, efficient, and on our own terms.
→ nodesphereai.com
30
26
62
2,571
Cryptomoose retweeted

11 Jul 2025
$IBIT blew through the $80b mark last night, fastest ETF to get there in 374 days, about 5x faster than the previous record, held by $VOO, which did it in 1,814 days. Also at $83b it's now 21st biggest ETF overall.. via @JackiWang17
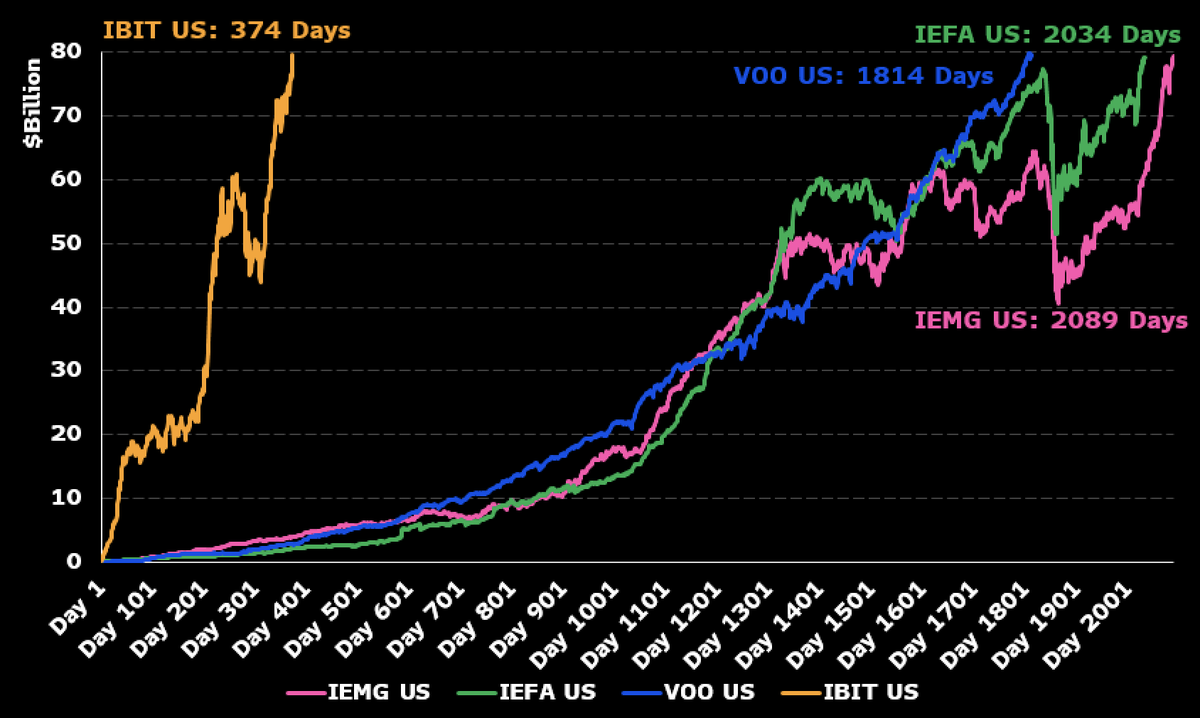
81
418
2,463
375,513
Cryptomoose retweeted

9 Jul 2025
Stablecoins are dollars that do more.
☑️ Programmable.
☑️ Globally accessible.
☑️ Available 24/7.
($/acc)
56
69
498
24,479

Cryptomoose retweeted
9 Jul 2025
Roadmap for Internet Capital Markets

46
136
487
86,374
Cryptomoose retweeted
5 Jun 2025
Collaterize Launchpad is live ! 🌍
RWAs are now liquid and globally accessible on DeFi rails, powered by @Solana
Internet Capital Markets are now live at launchpad.collaterize.com
125
208
657
172,075

Looks like big money is positioning for potential upside in $COLLAT, even as technicals lean bearish with negative MACD and shrinking volume. Socials are buzzing—some see RWA Meme potential, but confusion over tokenomics keeps sentiment split. Want more on why whales might bet against the current?
Dive into the full breakdown for deeper wallet flow and indicator signals:
alva.xyz/share/entity?id=125…
2
7
227
Cryptomoose retweeted

3 Jun 2025
Someone's rotating out, unloading $172.9K of #Fartcoin and their last $43.6K of #Titcoin into $COLLAT.
That's $216.5K bet on @CollaterizeHQ
What do they know that we don't?
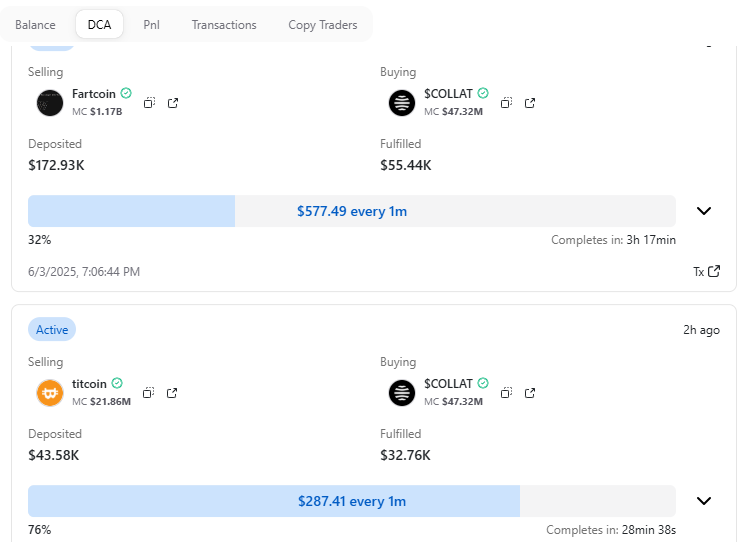
22
42
181
19,366
Cryptomoose retweeted
31 May 2025
RWA Launchpad is ready to go live. 🌍
132
211
754
156,131
Cryptomoose retweeted

26 May 2025
The most important WhiteRock update of 2025.
Tune into our X livestream tomorrow.
⏰ May 27 - 2PM EST
- Major updates dropping
- Future strategy breakdown
This is a critical livestream for everyone, every community member needs to tune in.
x.com/i/broadcasts/1dRKZYbgb…
65
59
185
26,630
Cryptomoose retweeted

19 May 2025
🚨 Solana-based project $COLLAT (@CollaterizeHQ) breaks into the top 10 RWA protocols by market cap
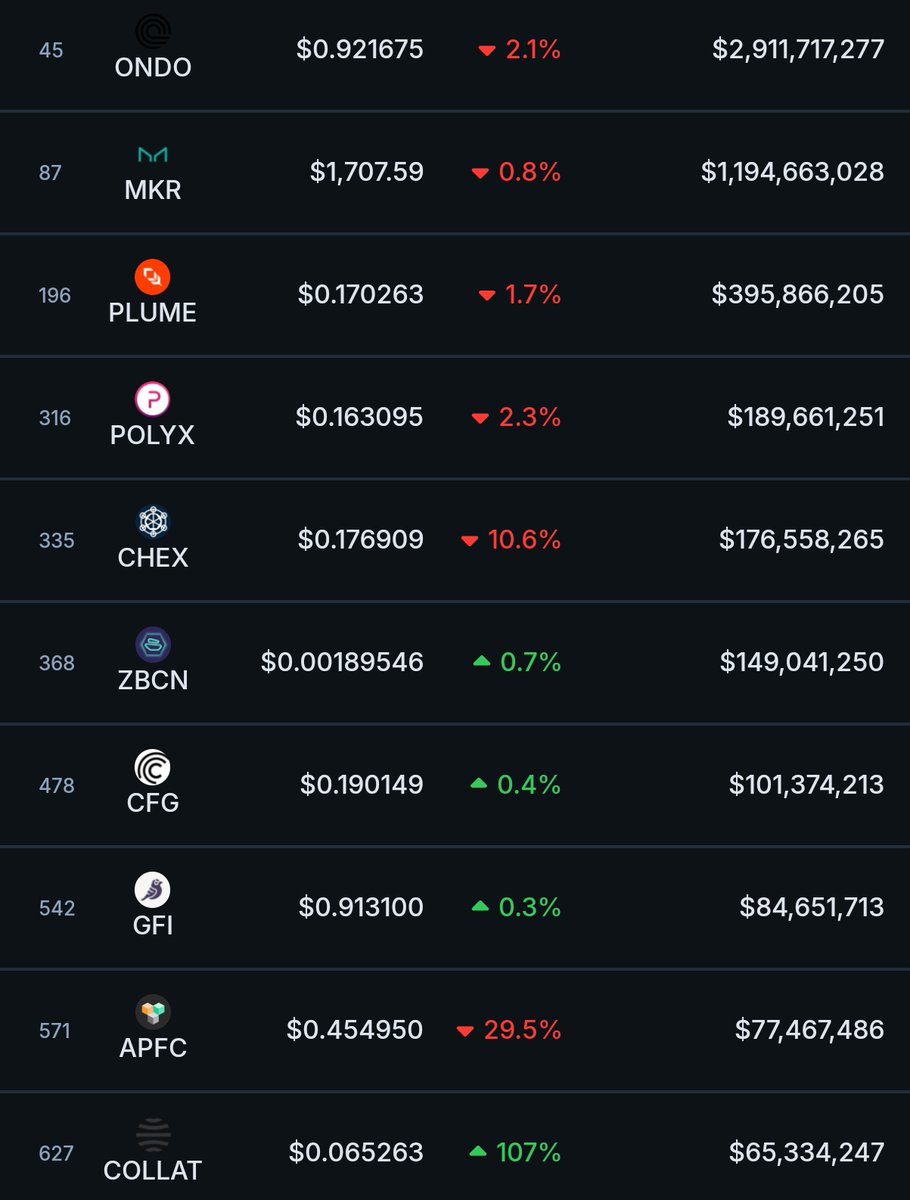

18
65
273
26,375
Cryptomoose retweeted
18 May 2025
🚨 Solana-based project $COLLAT (@CollaterizeHQ) ranks #1 in gains among all RWA protocols over the past 24 hours.
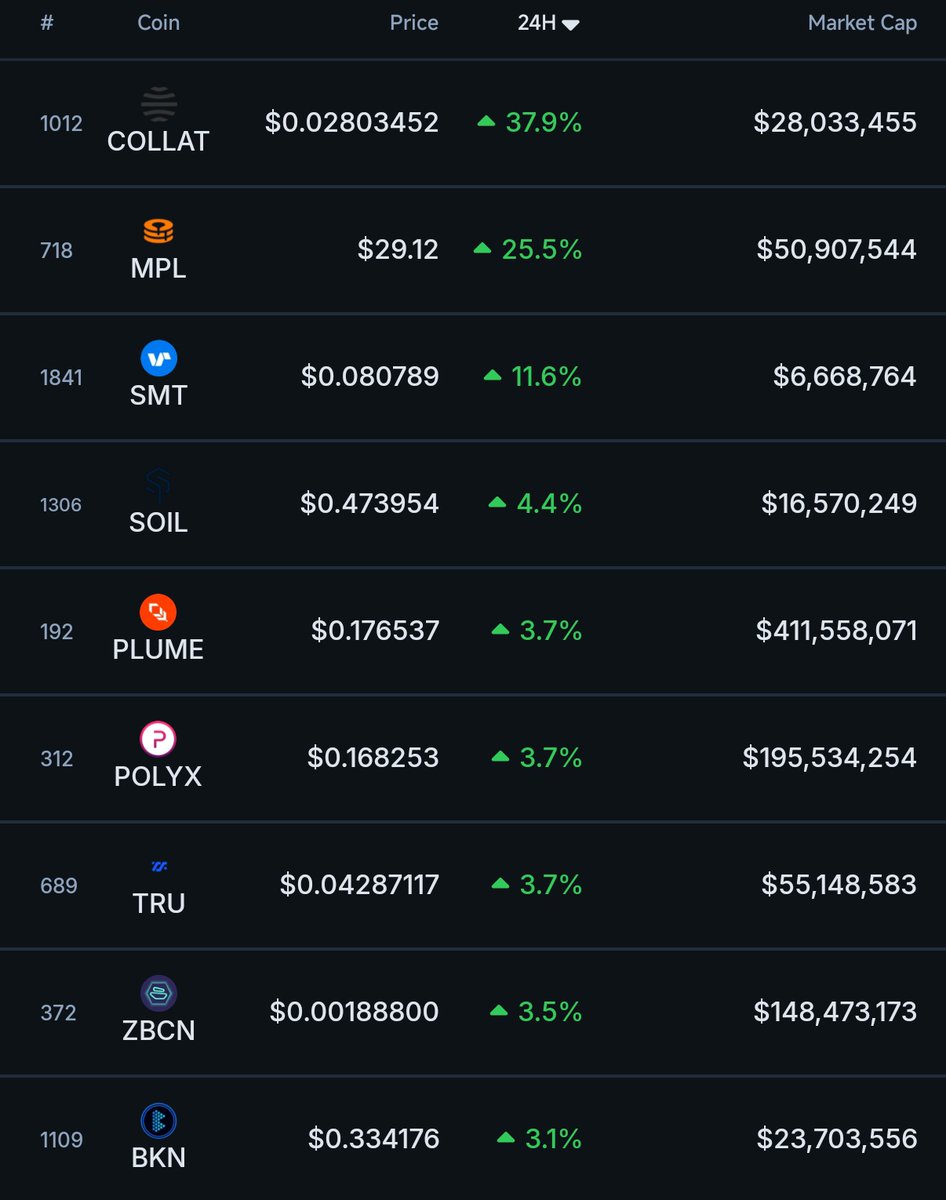

31
90
354
18,626
Cryptomoose retweeted

15 May 2025
Sui’s playing in hard mode 🌐
We’re now the chain with the Best Asia Strategy, according to @TheTieIO’s Innovator Awards.

Congratulations to @SuiNetwork - Winner of Best Asia Strategy
Awarded to the project that successfully penetrated and expanded within Asian markets through strategic initiatives and partnerships.
#InnovatorAwards

150
63
581
50,758
Cryptomoose retweeted

15 May 2025
The encryptSIM team has been thriving at Blockchain Hub in Da Nang, collaborating with the awesome @SuperteamVN crew! 🚀
We’re grateful for the productive environment and shared vision.
Whats happening next:
89
21
237
29,597