
Training the models. Prior: Saronic, Anduril, Oculus VR, Game Closure, MSEE@GATech
Joined July 2014
- Tweets 16,417
- Following 859
- Followers 3,835
- Likes 24,371
1,480 Photos and videos














Implemented teamcodex which is a port of teamclaude to codex. Just saw it successfully seamlessly switch between two Pro plans when the first one ran out of tokens for the week: github.com/catid/teamcodex
1
435
Enjoyed this video featuring @yoavartzi youtube.com/watch?v=hRENteFR…
1
1
3
1,228
Adds a 3 layer GELU MLP to predict the residual latents between each token in each SGD batch. Loss function is L1 between latents and the predicted token distribution (KL)

Next-token prediction is myopic. What if transformers learn to predict their own next latent state?
🌠 We present 𝗡𝗲𝘅𝘁-𝗟𝗮𝘁𝗲𝗻𝘁 𝗣𝗿𝗲𝗱𝗶𝗰𝘁𝗶𝗼𝗻 (𝗡𝗲𝘅𝘁𝗟𝗮𝘁): a self-supervised learning method that teaches transformers to form compact world models for reasoning and planning. It also unlocks up to 3.3x faster inference via self-speculative decoding! 🚀

ALT illustration of next-latent prediction vs. other predictive mechanisms
6
344
catid retweeted

Next-token prediction is myopic. What if transformers learn to predict their own next latent state?
🌠 We present 𝗡𝗲𝘅𝘁-𝗟𝗮𝘁𝗲𝗻𝘁 𝗣𝗿𝗲𝗱𝗶𝗰𝘁𝗶𝗼𝗻 (𝗡𝗲𝘅𝘁𝗟𝗮𝘁): a self-supervised learning method that teaches transformers to form compact world models for reasoning and planning. It also unlocks up to 3.3x faster inference via self-speculative decoding! 🚀
ALT illustration of next-latent prediction vs. other predictive mechanisms
22
124
796
46,955
This came out of nowhere super smart: forbes.com/sites/karlfreund/…
2
163
catid retweeted

Jun 15
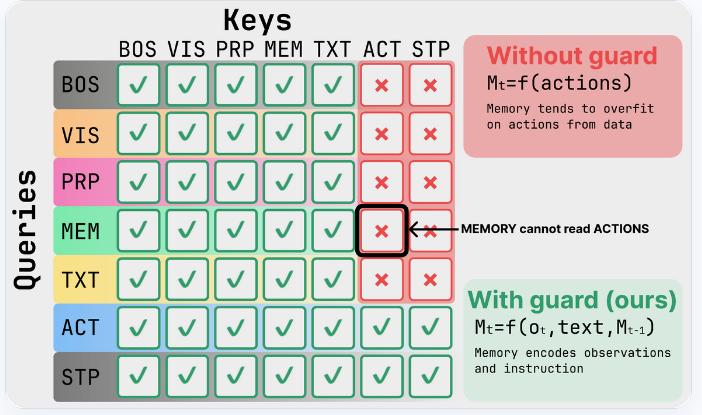
5/ On MIKASA-Robo, success rate jumps 0.42→0.84, and held-out tasks with shared memory structure go 0.07→0.23. On LIBERO it holds at 96.2% - recurrence doesn't hurt when memory isn't needed.
1
1
2
249
Implemented teamcodex which is a port of teamclaude to codex. Just saw it successfully seamlessly switch between two Pro plans when the first one ran out of tokens for the week: github.com/catid/teamcodex
1
435

Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
362
997
8,370
2,522,007
Who could have seen this coming oh no


256
catid retweeted

Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
12,600
25,782
88,121
90,222,978