
Joined November 2022
- Tweets 1,693
- Following 755
- Followers 5,605
- Likes 67,495
144 Photos and videos














Pinned Tweet

May 30
🥊5 months into development
Motion fluidity still not quit there yet, but at least head movement, hands movement and footwork are all procedurally generated by the system in real time according to player input, and they are all works together now, as you can see in the video below when control our guy with keyboard & mouse
Next, will add physics component, so this guy can finally hit something
#gamedev #indiegame #boxing
29
30
500
25,301
Mar 25
🎯Player will have Precise & Separate control over character's Head & Hands motion.
Head and hands position can be controlled separately, while any pose at any given moment would still looks natural, can't achieve this with pre-made animations or blend a set of pre-made poses by curve.
#gamedev #indiegame #boxing
13
464
Mar 24
🥊2.5 months into development, finally achieved precise head & hands position trajectory control from a mouse alone
🎮This boxing simulator is designed as the polar opposite of how traditional boxing/fighting game is usually about, i.e., instead of mapping the pre-made animation directly to input buttons, in case using a mouse, you simply hold left/right mouse button and move it to move the hand, and release the button to throw the punch at certain direction, speed & distance (literally throw a punch), head's movement will simply follow the exact mouse movement with a different sensitivity, so you only need think about What you want to move to Where, and my system will figure out How by procedurally generates fluent animation according to your intention! Complete control while no 2 punches will every be the same!
(Check the inputs in the video below)
🚧Now that baseline head & hand movements system that enables precise head & hands position trajectory control is done, next will be physics & secondary motions to make the characters motion looks more lively and can interact with other physical objects
#gamedev #indiegame
2
11
546
Mar 21
2
15
990
Mar 9
To me, life is all about creating something truly novel, something no human has ever created before!
🥊Video below describes a novel control method design for a new boxing simulator, it's the exact opposite of what has been done in any typical fighting game.
PS: 2 months into making this boxing simulator now, so far it was more challenging than I originally imagined, but still managed to stay on track somehow, I really should post a bit more often about the development process though
10
418
Feb 4
Jab, Cross, Uppercut will also follow the exact player inputs on top of exact head position control, still some work here before working on check/rare Hooks
🥊Punching animations is entirely generated from player inputs on top of entirely generated head movement animations, ZERO pre-made animations is the presistent theme here
#gamedev #Boxing
1
10
553
Jan 28
Head Movement System Testing
🥊Head position is controlled by the Mouse input exactly, and whole body animations are entirely generated on the fly by the system
#gamedev
6
12
621
21 Dec 2025
👒My One Piece fan game:
"One Piece: The Sky Runner" is completed!
Let's just say "Nothing Happened" if you know what I meant😎
▶️See video below for 3 minutes full gameplay
🎮You can also play it here yourself: mrforexample.itch.io/one-pie…
@strawhats @onepiece_games @onepiecedaiIys
1
1
5
487
13 Dec 2025
👒PS: This is a One-Piece fan project that is in development, what you saw here is first 40s of the gameplays (of total about 3 minutes)
💡About a month ago, when I was watching One Piece, I had this idea of designing a game mechanism that allow player to control Sanji to running freely in the sky, since I have some free time now, I figure why not just build it myself.
🚧The main game play is finished; I'm working on a parody 3d animation ending scene and it's almost done, probably going to take another week or two, I'll do my best utilize my free time, man, almost 2026 now, game dev (I call it the Ultimate Art) is still sooooo~ time consuming and hard to get it right.
#ONEPIECE #fanart #gamedev @onepiece_games @onepiecedaiIys
1
4
471
19 Nov 2025
#ONEPIECE #fanart #gamedev
🌩️Skywalk!!!
👒PS: This is a One Piece fan project that is in development, what you saw here is just a control mechanism testing video
💡About 2 weeks ago, when I was watching One Piece, I had this idea of designing a game mechanism that allow player to control Sanji to running freely in the sky, since I have some free time now, I figure why not just build it myself.
🚧I'll upload this mini console game for all to play after 2-3 more weeks once it's done, main game mechanism & assets processing is mostly finished; I'll build the actual gameplay & a few 3d animation scenes next.
@onepiecedaiIys @strawhats @DailyOPMemes @onepiece_games
3
382
7 Nov 2025
Get a feel of the true size of a 1000 X 1000 X 10 matrix, i.e. 10 million Sprites rendered with PointsNodeMaterial
Seems this starting to hit the limit of what native three.js plus WebGPU can handle, but is good enough for what I'm trying to build🚀
1
3
375
6 Nov 2025
Experimenting some WebGPU shaders in three.js, seems interactively visualizing matrix with billions of parameters is possible in browser on a laptop with RTX 4090 mobile GPU
1
336
5 Nov 2025
🎟️We all know The Lottery Ticket Hypothesis raveled the fact that there exist sub/sparse networks within the given dense networks that if trained can be as good if not better than its dense counterparts.
But the fact that field like Reservoir Compute exist and works unreasonably well makes me wonder how much of the performance in those sub/sparse networks is from the updated weights and how much of it is directly from the structure?
Papers like: "What’s Hidden in a Randomly Weighted Neural Network?" & "Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask" demonstrated that connection masks alone can contribute significantly to performance, with signs and zeros in weights playing complementary roles.
This leads to a significant finding that we need only fine-tune a tiny fraction of all parameters to achieve performance as good as full fine-tuning, this finding not only helps model saves compute, but also shows us we can do so while mitigate the catastrophic forgetting issue, two birds one stone indeed, as we can see in papers like:
"Sparse is Enough in Fine-tuning Pre-trained Large Language Models"
"LoRI: Reducing Cross-Task Interference in Multi-Task Low-Rank Adaptation"
"Continual Learning via Sparse Memory Finetuning"
On the surface, seems training/fine-tuning sparse model is the best we can do to achieve compute efficiency & some level of success in Continual Learning, what else can we do to further improve it?
Well, what about we just use the large & completely random networks directly and only update a tiny part of the weights where it's most useful?
Most researcher would think there is no way in hell this can work, but it just might! Since the paper "The Unreasonable Effectiveness of Random Pruning: Return of the Most Naive Baseline for Sparse Training" has shown when a model is large enough, all tickets/subnets become winning tickets!
I'll try to find relevant papers for it first, if anyone knows anything like then please share it to me, if not then I guess I'll find time to conduct this research myself, for Truth🚀
304
1 Nov 2025
🚀I just completed a Diffusion Autoencoder research project after more than a month!
🎯The purpose of this project is to prove this architecture can work well among s-o-t-a VAE models and offers a strong & stable codebase for other VAE researchers to build upon.
🛠️It integrates a deep compression encoder for high-ratio spatial reduction, a single-step diffusion decoder for fast reconstruction, and equilibrium matching for stable generative training, DC-SSDAE achieves compact latent representations while preserving perceptual quality
🎁Entire Codebase:
github.com/MrForExample/DC_S…
📜Technical Report:
mr-for-example.medium.com/dc…
🏋️♀️Experiments Weights & Logs:
huggingface.co/MrForExample/…
Researching Autoencoder/Representation learning is very difficult and largely underappreciated, hopefully this can at least make some Autoencoder researchers' life easier🍻🤜🤛
@du_yilun @songhan_mit @hancai_hm @EmergentMind @sainingxie @felix_m_krause @Den_Kochetov @camenduru @neutanent @toyxyz3 @DylanTFWang
1
9
512
Mr. For Example retweeted

23 Oct 2025
⚡️Your video → a 3D scene. Just in seconds.⚡️
Only *one* model. No more steps❌. Just results🔝.
#WorldMirror reconstructs everything (3DGS, depth, cameras) from any inputs (image, video, 3D prior) *all-at-once*!
code: github.com/Tencent-Hunyuan/H…
arxiv: arxiv.org/abs/2510.10726
10
113
736
66,899
18 Oct 2025
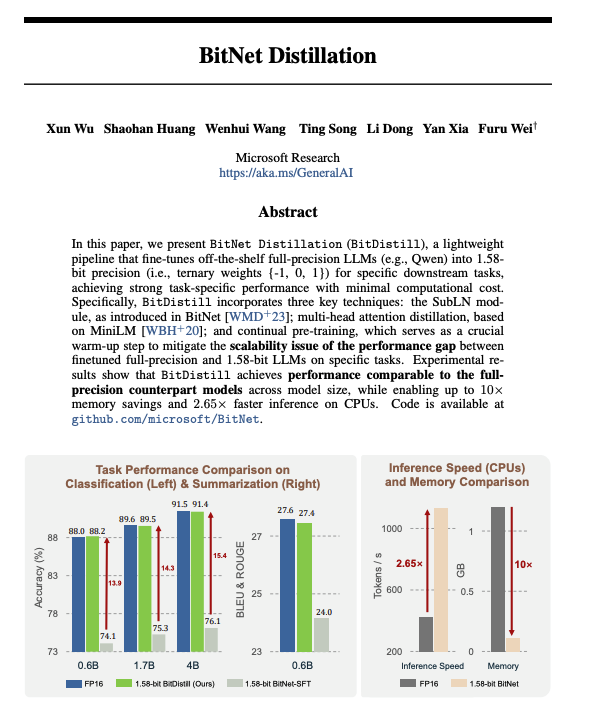
Amazing work, the fact that we can already find ways to build 1-bit network is mind blowing, seems we are getting closer and closer to the essence of the neural network💠
There is no need to hide our excitement as we Entering The Era of 1-bit AI🚀
mr-for-example.medium.com/en…

2
4
850
Mr. For Example retweeted
16 Oct 2025
⚡️Generating 3DGS scenes in 5 seconds on a single GPU⚡️
#FlashWorld enables ⚡️*fast*⚡️ (10~100x faster than previous methods) and 🔥*high-quality*🔥 3D world generation, from a single image or text prompt.
Code: github.com/imlixinyang/Flash…
Page: imlixinyang.github.io/FlashW…
18
117
752
119,981
11 Oct 2025
⚡️Seems ML research in generative AI is converging towards energy-based methods, energy-based LLM a few months ago and now diffusion model
I was working on energy-based real-time physics simulation for a game company 4 years ago, who knows it would be helpful now😆lucky
📜I just wrote a key points article of this paper in case anyone don't have 2 hours to read it:
mrforexample.github.io/Path-…

Excited to share Equilibrium Matching (EqM)!
EqM simplifies and outperforms flow matching, enabling strong generative performance of FID 1.96 on ImageNet 256x256.
EqM learns a single static EBM landscape for generation, enabling a simple gradient-based generation procedure.
5
1,392