
CS PhD@UIUC.mainam2.web.illinois.edu. All opinions are my own.
Joined August 2021
- Tweets 13
- Following 90
- Followers 66
- Likes 18
Photos and videos

30 Oct 2024
Yes please.
30 Oct 2024

HELL YES @geo_uiuc! Getting research assistants into the bargaining unit will completely transform graduate labor North of Green St. I strongly encourage computing grad students to get involved at uiucgeo.org/ra-homepage

99
18 Oct 2024
The struggle is real. 🤷♂️

1
67
18 Oct 2024
Keep an eye out for our presentations. 🕴️
2 Aug 2024
Paper link here: gangw.cs.illinois.edu/mitre2…. We disclosed our results to the surveyed company’s, @MITREattack and CITD, and will be also be presenting these results at ATTACKCon 5.0 this Fall.
67
18 Oct 2024
Listen to this guy.
30 Sep 2024
👇 spoiler warning for intrusion detection research 👇
35
Adil Inam retweeted

2 Aug 2024
Paper link here: gangw.cs.illinois.edu/mitre2…. We disclosed our results to the surveyed company’s, @MITREattack and CITD, and will be also be presenting these results at ATTACKCon 5.0 this Fall.
1
1
5
427
Adil Inam retweeted
2 Aug 2024
To understand how @MITREattack is used in commercial endpoint detection products, @avirkud4 led an analysis of the ATT&CK technique annotations in the @carbonb1ack, @splunk, @elastic, and Sigma rulesets.
1
1
1
849
Adil Inam retweeted
2 Aug 2024
Upcoming at @USENIXSecurity’24 — In (academic) systems security research, name checking @MITREattack has been the “peer review armor” of choice for a lot of work recently. But do these papers understand what ATT&CK is(n’t)? What about commercial products?
1
5
24
5,823
Adil Inam retweeted

30 Sep 2024
Traditionally in ML, building models is the central activity and evaluation is a bit of an afterthought. But the story of ML over the last decade is that models are more general-purpose and more capable. General purpose means you build once but have to evaluate everywhere. Increasing capability means taking on more realistic tasks in higher-stakes domains, so benchmarks have to be far more complex and thoughtful, and in many cases even the most careful benchmarks simply aren't enough. So both the quantity and quality of evaluations has to increase.
But status hierarchies change slowly in any research field, including ML. Most researchers' dream is to build the next transformer. That's a lottery with incredibly low odds. I suspect that researchers who focus on evaluation and understanding will have a much easier time making impactful contributions and standing out, despite the traditionally lower status of this type of work. (Obviously oversimplifying a bit to make a point; there's a lot more to ML than model building and evaluation.)
4
23
125
18,998
Adil Inam retweeted

13 Sep 2024
Every person who you mentor is a unique individual, and none of them are you.
Mentoring isn’t about sharing what you would do, but exploring what’s best for them to do.
8
180
1,078
65,999

Adil Inam retweeted
24 May 2023
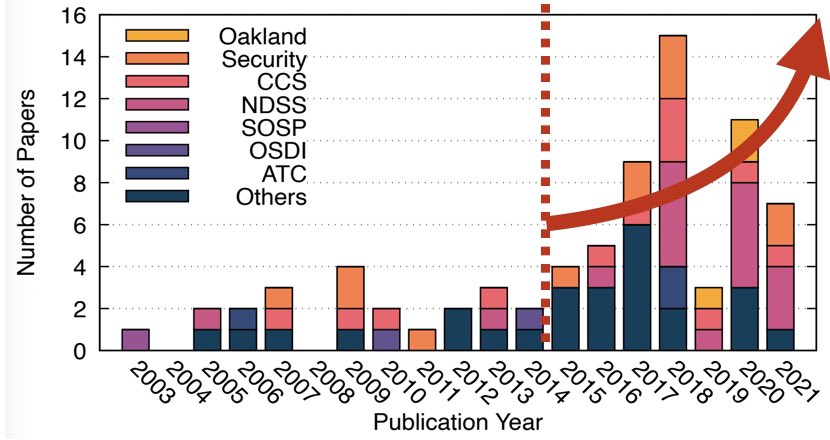
Tomorrow morning in Session 9C (9am, Bayview AB) — system auditing research may not be sexy, but it has *exploded* since 2015. Come watch @MuhammadAdilIn1 and I break it all down for you in our data provenance SoK, “History is a vast early warning system!”
1
6
15
2,012
Adil Inam retweeted
8 Jul 2022
Excited to announce that our *data provenance* SoK, "History is a Vast Early Warning System: Auditing the Provenance of System Intrusions," has been conditionally accepted to @IEEESSP #Oakland23. Before finalizing the camera-ready paper, we need your help!
3
8
46
Adil Inam retweeted

11 Sep 2021
A great ride with @MuhammadAdilIn1 @wajihulhasan @AliThespy @AdamBatesOrg and other collaborators to @NDSSSymposium! #NDSS22
It's eye-opening when @wajihulhasan first showed me that configurations can be as crazy as part of attack vectors by presenting CVE-2016-7790 in CS 523.
9 Aug 2021
Excited to share that our work "Forensic Analysis of Configuration-based Attacks" has been (conditionally) accepted to @NDSSSymposium #NDSS22! Congrats to student authors Adil Inam, @wajihulhasan, and Ali Ahad (UVA).
1
2
13