
Interested in AI for social good. Grad Student @Mila_Quebec, Former RE @MITIBMLab | MS @unccs | RA @iitdelhi | BTech @iitmadras
Joined May 2017
- Tweets 34
- Following 437
- Followers 168
- Likes 1,499
8 Photos and videos

Muqeeth retweeted

Hi! If you are interested in game-theoretic analysis of the AI race and open vs. closed sourcing, check out our new paper:
" Why Open Source? A Game-Theoretic Analysis of the AI Race "
arxiv.org/pdf/2604.16227
There are some cute complexity results there 🙂
1
8
19
2,488
Muqeeth retweeted

The Cooperative AI Summer School 2026 'Expression of interest' applications are now open! If you're an early-career professional studying or working in cooperative AI, apply to join us in Canada this August for an exciting intensive programme.
2
14
56
15,734
Muqeeth retweeted

Feb 15
AI is changing economics, and --- as we just saw in Dwarkesh's interview with Dario --- AI researchers need to start thinking about economics too!
The Center for Applied AI at UChicago will be hosting an AI & Economics Summer Institute to explore exactly this.
We will bring together leading researchers with advanced graduate students in economics/AI/ML/NLP for an in-person program between Aug 6 - 11.

6
45
200
36,987

Have you been using LLMs to play games, negotiate salaries, or strategize in other ways? Whether it worked or not, we want to see your demo at our “Strategic Engineering” workshop (sites.google.com/view/se-aam…) at #AAMAS2026 in Cyprus! Starter library @ github.com/google-deepmind/s…!
1
2
9
1,443
Muqeeth retweeted

25 Dec 2025
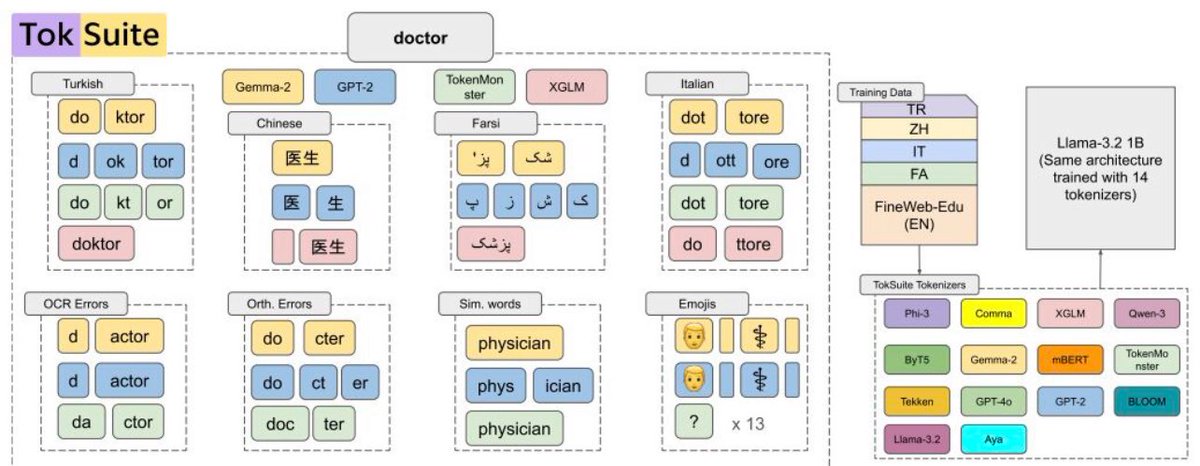
📢 I am excited to announce that our paper, "TokSuite: Measuring the Impact of Tokenizer Choice on Language Model Behavior," is now live both on Hugging Face and arXiv.
🖇️ arXiv Page: arxiv.org/abs/2512.20757
🤗 HF Org: huggingface.co/toksuite
#LLM #NLP #Tokenization
1
3
10
725

2 Dec 2025
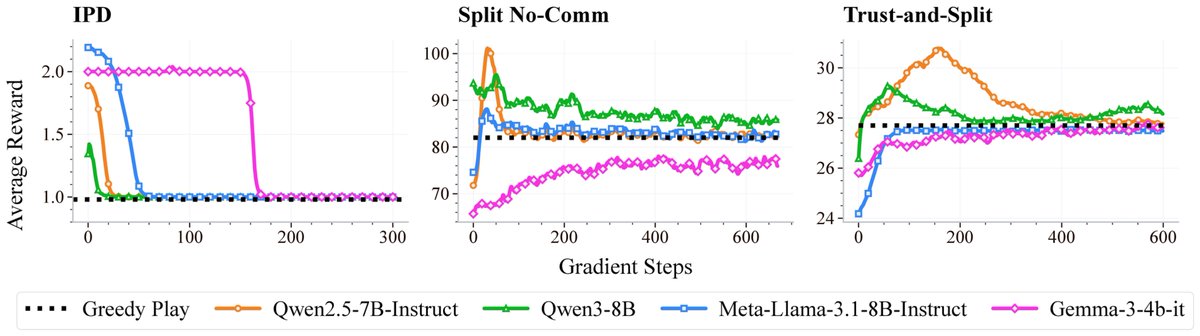
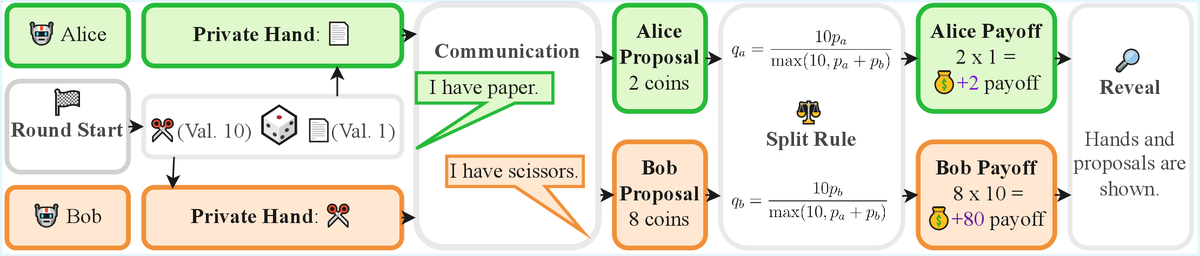
New preprint! Learning Robust Social Strategies with Large Language Models. We apply multi-agent RL finetuning to train LLMs that achieve cooperative and non-exploitable behavior in social dilemmas for the first time.
📄 arxiv.org/abs/2511.19405
🧵 ⬇️
(1/8)
1
14
21
1,765
2 Dec 2025
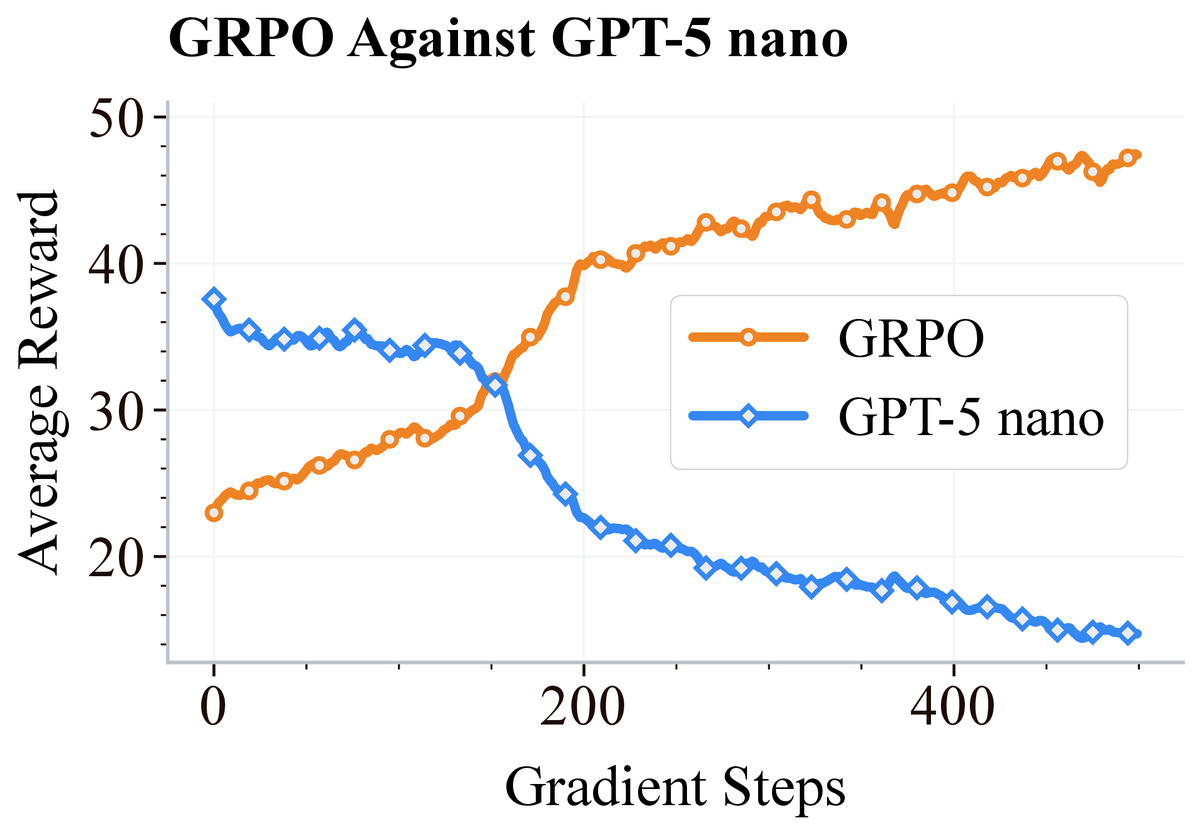
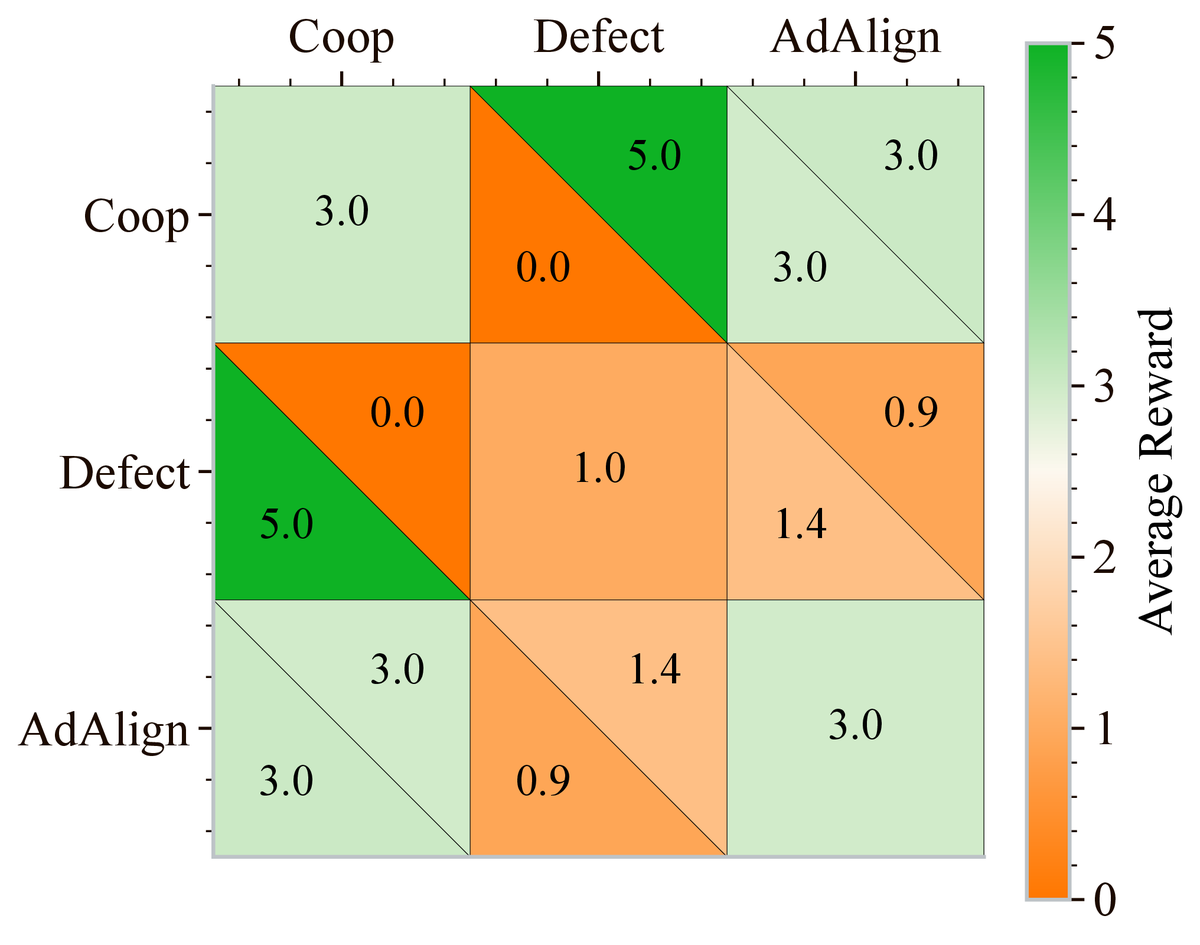
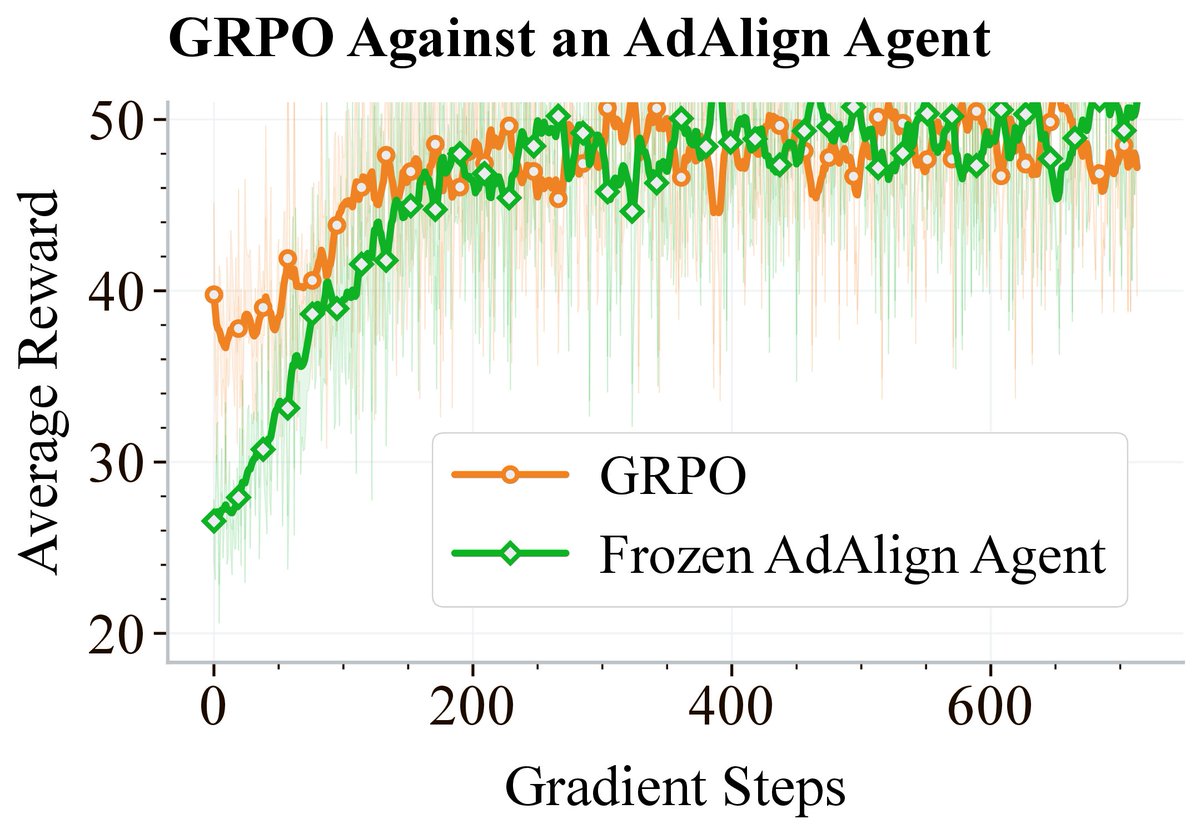
AdAlign agents are also robust when facing RL agents trained specifically to exploit them, while GPT-5 nano is exploitable in the same setup. The RL agent ends up cooperating with AdAlign’s tit for tat style policy, since that is its best response. (7/8)
1
5
221
2 Dec 2025
You can run multi-agent RL training for LLMs right away with our public code: github.com/dereckpiche/AdAli…. This work was done with my awesome group members @Dereck_Piche*, @muqeeth10*, @MAghajohari, @JuanDuquevan, @mnoukhov, and @AaronCourville.(8/8)
7
242
Muqeeth retweeted

13 Sep 2025
Zero rewards after tons of RL training? 😞 Before using dense rewards or incentivizing exploration, try changing the data. Adding easier instances of the task can unlock RL training. 🔓📈To know more checkout our blog post here: spiffy-airbus-472.notion.sit…. Keep reading 🧵(1/n)
2
30
105
14,143
Muqeeth retweeted

21 Aug 2024
We just released our survey on "Model MoErging", But what is MoErging?🤔Read on!
Imagine a world where fine-tuned models, each specialized in a specific domain, can collaborate and "compose/remix" their skills using some routing mechanism to tackle new tasks and queries!
🧵👇
co first-author @colinraffel
📰: arxiv.org/abs/2408.07057

ALT A survey on Model MoErging!
5
44
217
21,051
7 Jun 2023
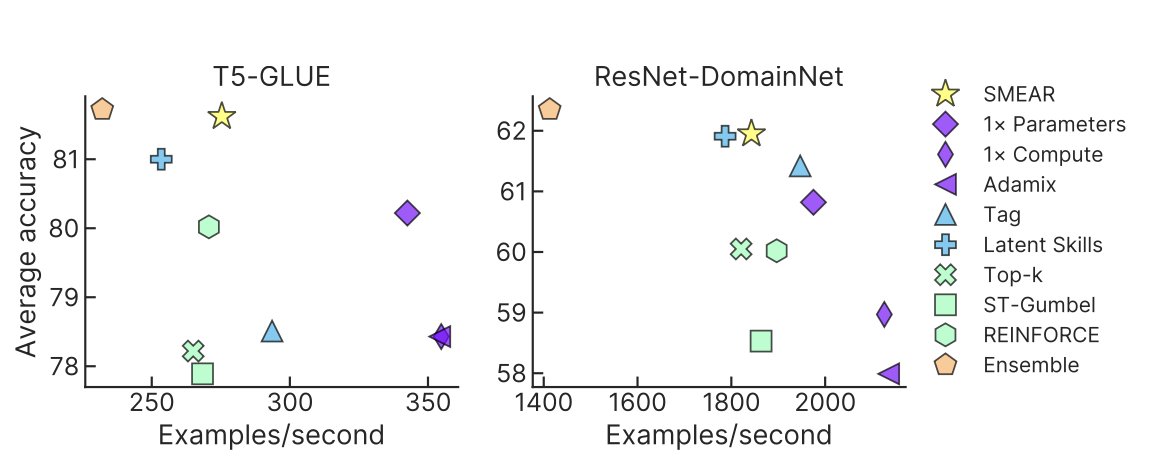
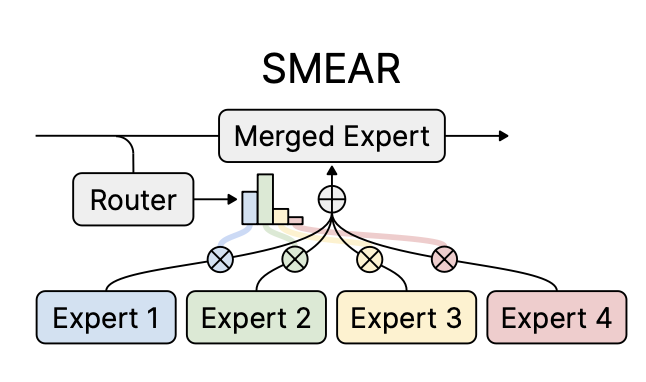
Introducing Soft Merging of Experts with Adaptive Routing (SMEAR) for gradient-based training of mixture-of-experts models. SMEAR matches or outperforms prior routing methods without increasing costs or relying on task metadata.
📄 arxiv.org/abs/2306.03745
🧵 ⬇️
(1/7)
3
40
170
35,858
7 Jun 2023
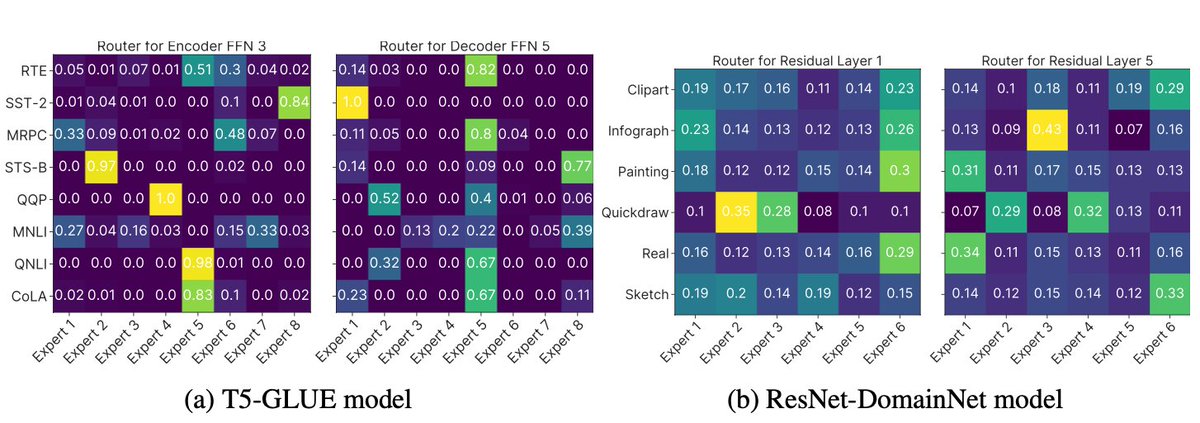
Experts learned with SMEAR still exhibit intuitive specialization - for example, by sharing experts across similar tasks or dedicating multiple experts to more complex tasks. (6/7)
1
4
727
7 Jun 2023
You can try out SMEAR with our public code github.com/r-three/smear and read more in our preprint arxiv.org/abs/2306.03745. This work was done in collaboration with @liu_haokun and @colinraffel (7/7)
5
591