
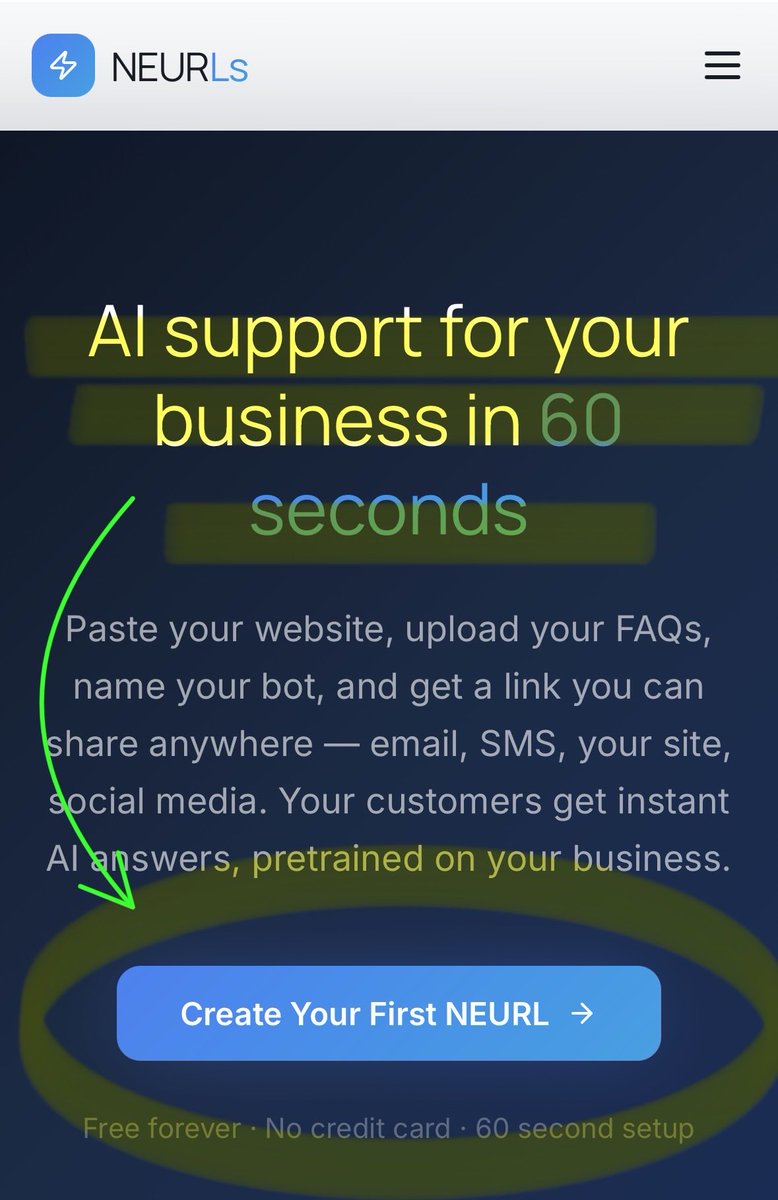
FREE “Bot-in-Bio” page, Ai Support Chatbot, Contact Form for your business in just 60 seconds!⚡️
Joined June 2022
- Tweets 79
- Following 39
- Followers 8
- Likes 84
12 Photos and videos









Pinned Tweet

Jun 14
This is GENIUS!

💲 How to Make Money 💲
1️⃣ Go to Payge.Me/11
2️⃣ Get your own Payge link
3️⃣ Copy Paste this in your bio, swap link
💸 Get $75 every time someone signs up again every time they renew!

1
2
13
Jun 12
Found a way to monetize as a new creator.
Your bio link should pay YOU.
So I built Payge Me — $97/yr and you get $75 every time someone grabs their own link through yours (and on renewals).
I’m looking for a few early creators to try it first.
👇
Comment “LINK” or DM me and I’ll send you the details.

1
20
Jun 11
This is so true!!
You’re an “Ai first” business? No.
Your domain TLD is .Ai? No.
Today AI is table stakes so you’re NOT differentiating, you’re limiting your market!
If you built a business during the .com bubble days you wouldn’t go around today saying “look, we’re online!” would you?

1
15
May 8
Pentagon's cyber chief sees "huge opportunity" in frontier AI models, despite lingering "Mythos" concerns.
This reflects a strategic embrace of advanced AI, even with acknowledged risks.
2
1
9
May 8
3/ While 'Mythos'-style projects highlight potential downsides, the Pentagon believes the benefits of frontier AI models for national security could be transformative.
8
May 8
2/ The department's top cyber policy official is signaling a readiness to leverage cutting-edge AI for defense and intelligence, prioritizing innovation over apprehension.
6
Feb 28
so much SAUCE 🥫!
Feb 19

Voice used to be AI’s forgotten modality - now it's having its big moment: rapid innovation, big funding rounds, major agentic applications
My conversation with @neilzegh, top AI researcher in the field (@GoogleDeepMind, @Meta, @kyutai_labs) and now CEO of @GradiumAI
This is a reference episode on all things voice AI 🔥
00:00 Intro
01:21 Voice AI’s big moment, and why we’re still early
03:34 Why voice lagged behind text/image/video
06:06 The convergence era: transformers for every modality
07:40 Beyond Her: always-on assistants, wake words, voice-first devices
11:01 Voice vs text: where voice fits (even for coding)
12:56 Neil’s origin story: from finance to machine learning, with help from @ylecun and @soumithchintala
18:35 Neural codecs (SoundStream): compression as the unlock
22:30 Kyutai: open research, small elite teams, moving fast 31:32
Why big labs haven’t “won” voice AI4
34:01 On-device voice: where it works, why compact models matter
46:37 The last mile: real-world robustness, pronunciation, uptime
41:35 Benchmarking voice: why metrics fail, how they actually test
47:03 Cascades vs speech-to-speech: trade-offs what’s next
54:05 Hardest frontier: noisy rooms, factories, multi-speaker chaos
1:00:50 New languages dialects: what transfers, what doesn’t
1:02:54 Hardware & compute: why voice isn’t a 10,000-GPU game
1:07:27 What data do you need to train voice models
1:09:02 Deepfakes privacy: why watermarking isn’t a solution
1:12:30 Voice vision: multimodality, screen awareness, video audio
1:14:43 Voice cloning vs voice design: where the market goes
1:16:32 Paris/Europe AI: talent density, underdog energy, what’s next
1
62
Feb 28
Touché. 👌🏽
24 Sep 2025

The model isn’t the moat—decision-driven UX is.
We had Megh Gautam, Chief Product Officer at @crunchbase, on Future Proof to break down how they made their trusted data product AI-native.
The key insight: design for decisions. Users don’t want facts; they want to know what’s worth their time—and they want your product to guide that judgment.
Listen/watch here useparagon.com/podcast/how-t…
11
Feb 19
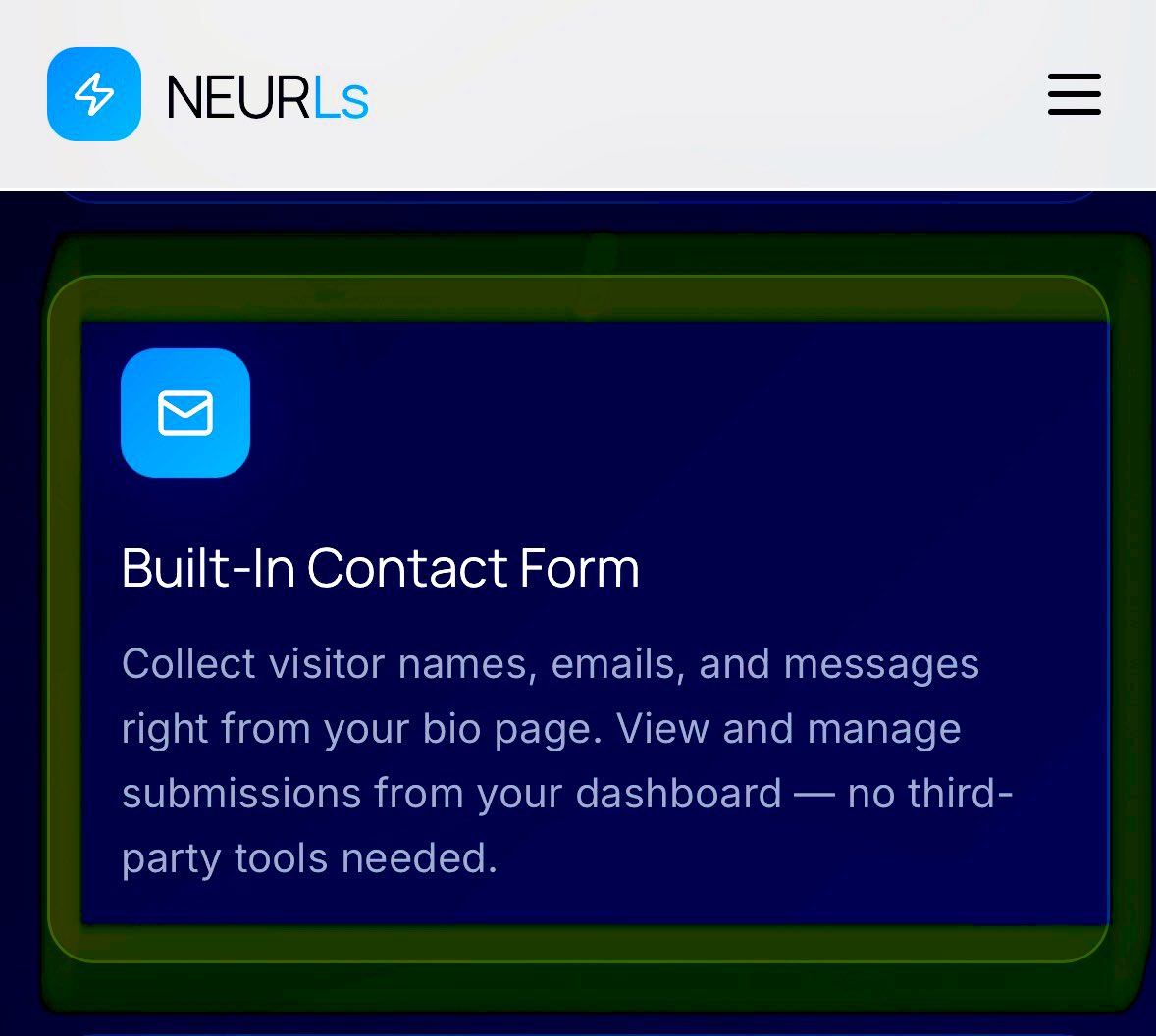
NEW FEATURE Alert 🚨
Every NEURL now includes a free “Bot-in-Bio” page!
Ai Support for your business in 60 seconds. ✅ #BotInBio #AiSupport
1
1
5
171
Feb 28
now that’s how you vibe code! 🧑💻 🤣🤣🤣


1
27
Feb 24
This should make the State of the Union address more interesting to watch!
1
3
621
Feb 22
Apple published a paper on Ferret-UI Lite, a lightweight AI agent that autonomously views operates app UIs across platforms.
It uses a “zoom-in” mechanism synthetic training data to match or beat benchmark scores of rivals, despite being 24× smaller.
1
2
41
Feb 18
If you have:
A course
Shopify Store
Offer Coaching
Offer services
Freelance
SAAS/Software
Are a plumber, lawyer, landscaper…
You can have an AI powered support chatbot trained on YOUR business, answering ?s for YOUR customers in just 60 seconds! … it’s free. #NEURLs
2
42
Feb 18
We’re all just little beta testers
In this game called Earth
Created by a player named God.
17
Feb 17
The companies that stick around add value.
They’re not features, they solve actual problems by offering either a new solution or by improving where their competitors failed.
1
1
44
Feb 6
Bravo 👏!!

1
42