
The voice layer for modern apps and agents. Real-time, scalable voice APIs: TTS, STT, turn-taking & voice cloning. Devs: build → gradium.ai/#models
Joined September 2025
- Tweets 133
- Following 1
- Followers 3,613
- Likes 136
48 Photos and videos












Pinned Tweet

2 Dec 2025
Gradium is out of stealth to solve voice. We raised $70M and after only 3 months we’re releasing our transcription and synthesis products to power the next generation of voice AI.
80
156
1,136
472,196
Jun 11
¡Hola Barcelona☀️
Jun 11

Next speaker are @ConstanceGriso and Timothé from @GradiumAI talking about Phonon, their on device model
Really cool demo

1
10
767
Jun 10
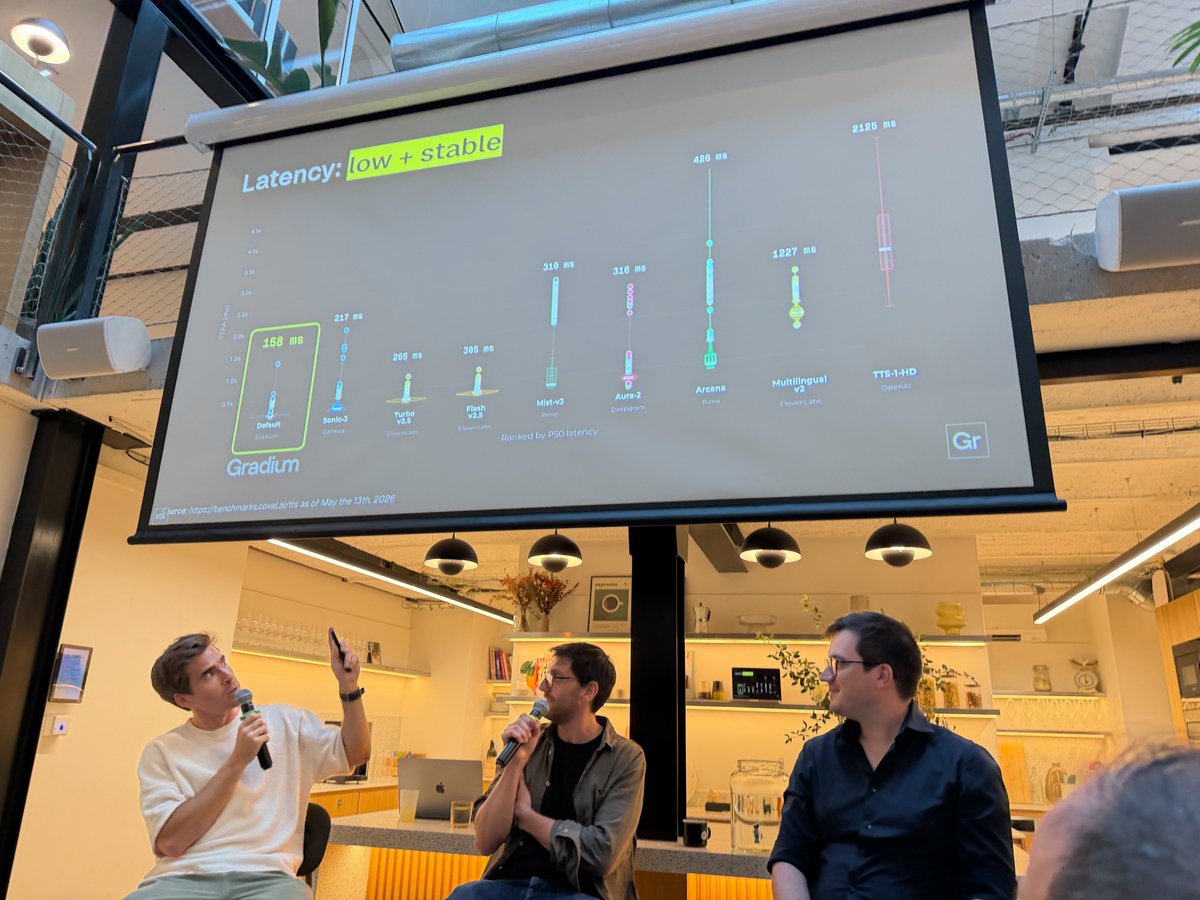
We upgraded Gradium TTS for the cases voice agents can't get wrong: phone numbers, codes, email addresses read back right the first time. Couple of examples: English: 97% on emails, top of the field. French: leads every competitor we benchmarked. Samples methodology → gradium.ai/blog/gradium-tts-…
2
3
36
7,980
Jun 10
In this joint work with @kyutai_labs, we design a reward model for conversational dynamics to teach full-duplex models how a human behaves in conversation, using cues to know when to interrupt, backchannel or stay silent.
Jun 10

New paper: Multi-Faceted Interactivity Alignment in Full-Duplex Speech Models
We use RL to post-train speech models (Moshi and PersonaPlex) to talk more like a human: to know when to respond, when to wait, and when to nod along with “yeah”s and “okay”s when listening.
1
4
23
2,929
Jun 9
We'll be at @VivaTech next week showcasing our models. Come find us at Booth 7.2 | 2F13 with @awscloud all week, and on the @LaFrenchTech booth on Wednesday.
@neilzegh is giving two talks: Wed 17th, 5:20pm, @nvidia Stage 1 and on Fri, 10am, Théâtre AWS
2
7
423
Jun 9
Learn how to build an audiobook voice agent using Gradium and @pipecat_ai
Gradium's TTS handles the narration and Pipecat's built-in WebRTC transport delivers the audio to the browser.
8
4
42
9,846
Jun 5
Reasoning LLMs typically take 2-3 seconds to start emitting tokens. In a voice agent, that's 2-3 seconds of silence after the user finishes speaking.
The @MiniMax_AI team just shipped a community contribution to Gradbot with two models running in parallel. MiniMax-M2-her produces a short acknowledgement that starts streaming to TTS immediately, while MiniMax-M2.7 runs in the background reasoning and tool calls.
Thanks to @davidtaoweiji for this contribution. Checkout our readme for more details.
github.com/gradium-ai/gradbo…
3
8
94
5,485
Jun 4
A full house at the @joinhexa office in Paris yesterday.
Our CTO @olivierteboul joined the discussion by sharing why low latency matters for voice agents and how Gradium models support enterprise use cases for voice AI.

1
2
12
681
Jun 2
"I'd like to cancel my flight from Boston to..." You pause to check a date. The agent cuts in: "Got it, where to?" Now you're talking over it to finish your own sentence.
That's acoustic turn detection. Semantic VAD waits because it knows you're not done: gradium.ai/blog/semantic-vad
1
8
20
3,102
Gradium retweeted

May 28
Yesterday we hosted our first Voice AI Dinner in Berlin. Where should be the next one?

5
2
26
2,184
Gradium retweeted

May 28
👉 slator.ch/ConversationalAIOp…
At SlatorCon London, we discussed voice #AI capabilities and deployments, and how voice AI 🗣️🤖 is shifting the operational infrastructure ⚙️ of enterprises with Neil Zeghidour, Co-Founder and CEO at @GradiumAI, Arkadiusz Kwapiszewski, Head of Agent Design & Engineering at @polyaivoice, and Peadar Coyle, CTO & Co-Founder at AudioStack.
#VoiceAI #ConversationalAI #LanguageAI @neilzegh @Springcoil
1
5
3
719

Berlin was geht ab, Tavily ist jetzt in town! We're here with @GradiumAI showing off our new voice integration and hosting a hackathon alongside @nebiusai and @cursor_ai. You won't want to miss this one.
luma.com/juded1wb
1
4
8
1,352
May 26
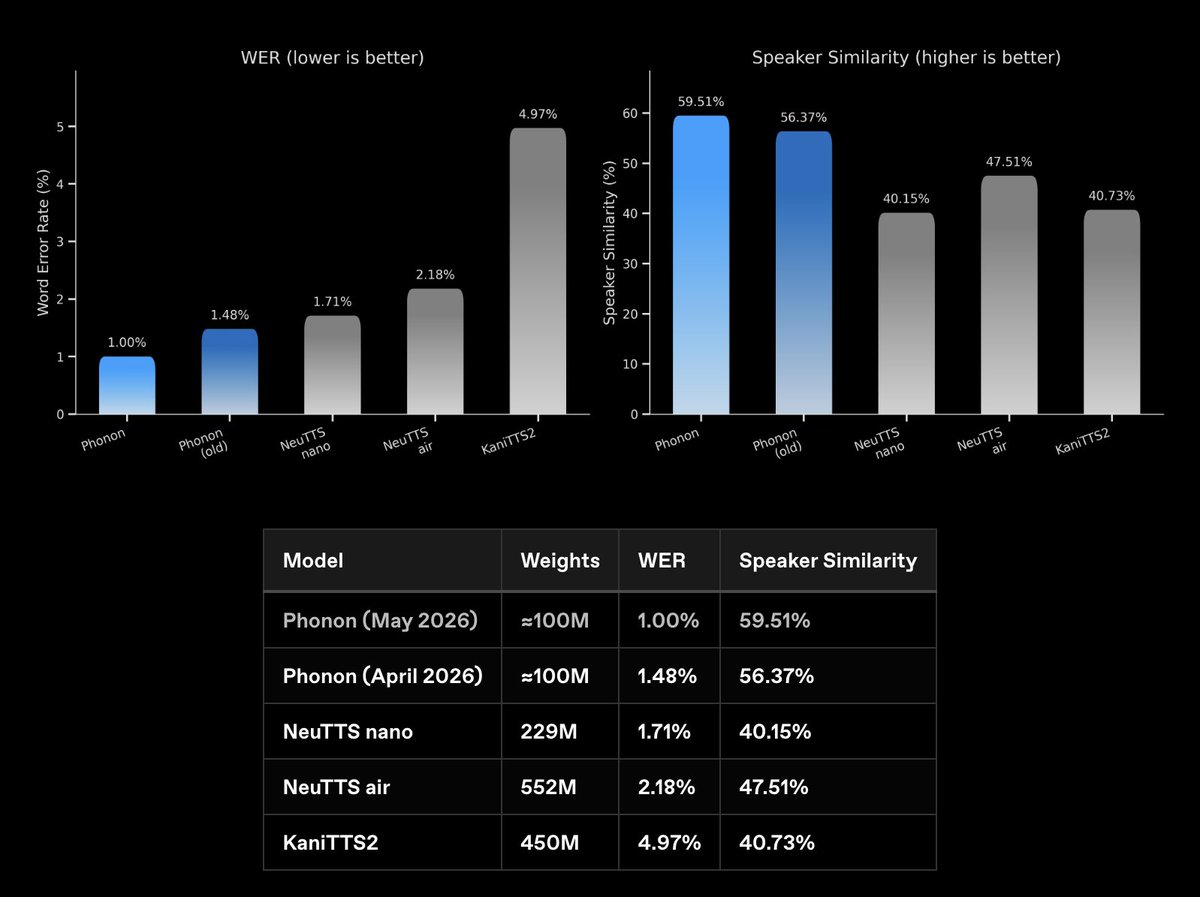
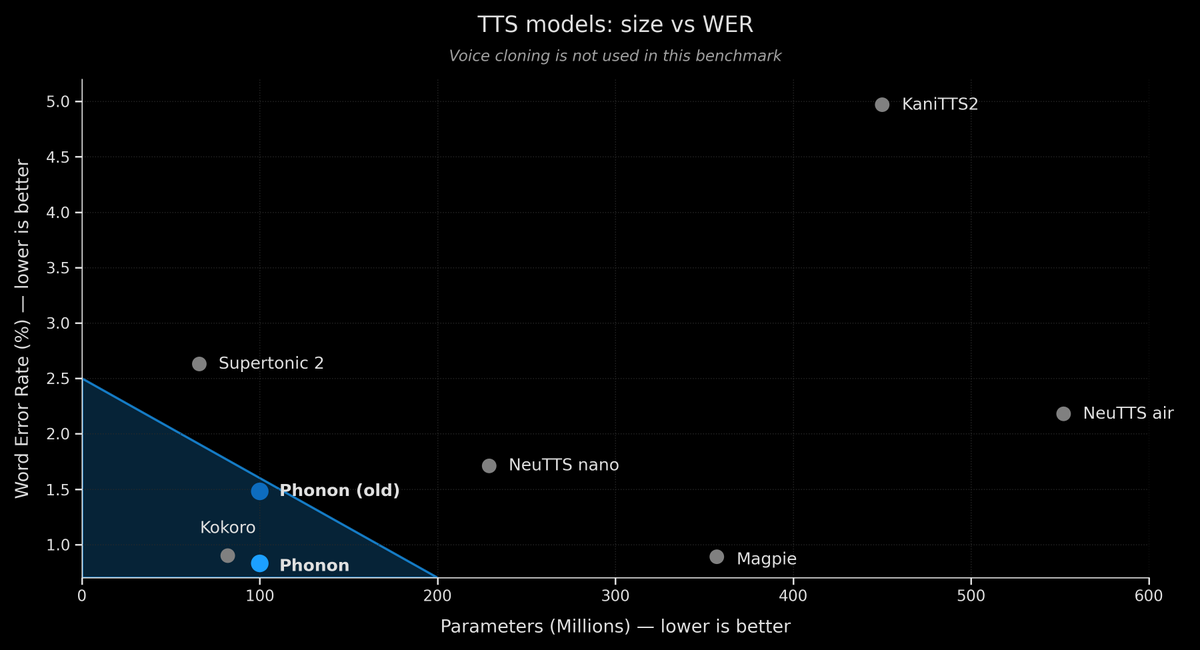
Our on-device TTS model Phonon (100M params) now reaches 1.00% WER on the Seed-TTS English benchmark.
Smaller than every model it already beats.
2
19
121
23,206
May 26
The 100-token input padding is gone.
Short replies like "yes, that works" used to need filler before generation.
Now they don't, so voice agents return first audio much faster on the short turns that fill real conversation.
1
1
15
1,156
May 26
int8 quantization, no audible quality loss. Lower memory, faster inference. All on-device.
gradium.ai/blog/phonon-updat…
18
936
Gradium retweeted
May 25
Gradium TTS is particularly good at transferring all characteristics including reverb, bandwidth (e.g. phone speech), even typical podcast mic saturation on plosives ("p" sound). All samples in the video just generated from 10 samples without any processing.

I'm just as surprised nobody in AI voice tech has realized a voice needs background and environmental noise to sound realistic
Even @ElevenLabs the leader in voice AI can not produce voice with background noise, or environment reverb sound
AI voices are always going to sound non-passable as human if they don't have that
And it's only me and this other guy even talking about it
3
10
55
11,085
May 25
This week, Gradium will be at the Applied AI conference in Berlin.
Catch @neilzegh on the stage talking about how real-time voice interactions are scaled.
Our Chief of Growth @ConstanceGriso will also be there to answer questions around integrations, evaluations, or what we're shipping next.
2
9
649
Gradium retweeted
May 22
Voice #AI is having it’s moment at #SlatorCon — and leaders Neil Zeghidour (@GradiumAI), Arkadiusz Kwapiszewski (@polyaivoice), and Peadar Coyle (AudioStack) are discussing:
🗣️ conversational AI agents
🌍 #multilingual voice systems
🎵 synthetic audio & media
💡 emotionally aware AI experiences
#VoiceAI #ConversationalAI #AudioAI #GenerativeAI #SlatorConLondon

2
2
3
433
Gradium retweeted

May 21
"My boss is having trouble with a chicken ordering app. Can you make one right now?"
May 21

Meet Colin, Lexi, and Gizmo.
One is part of Gradium's GTM team.
One is his dog.
And one is the AI assistant he built himself.
This is their day in Paris.
2
10
1,265
May 21
Meet Colin, Lexi, and Gizmo.
One is part of Gradium's GTM team.
One is his dog.
And one is the AI assistant he built himself.
This is their day in Paris.
8
9
40
27,145
May 21
Gizmo sits in on meetings, helps Colin prep for calls, and navigates his entire workday in real time.
It's his digital clone. And uses Colin's cloned voice.
1
6
680
May 21
By 8 PM, Gizmo had booked Colin's massage.
Gizmo is built on @openclaw with Gradium as the Speech provider.
Just ask your Openclaw agents to switch to Gradium today.
docs.openclaw.ai/providers/g…
1
1
7
491