
Tinkering. Culture Maxi. ❤️ Artists
Joined April 2009
- Tweets 22,007
- Following 6,069
- Followers 15,072
- Likes 23,676
Photos and videos

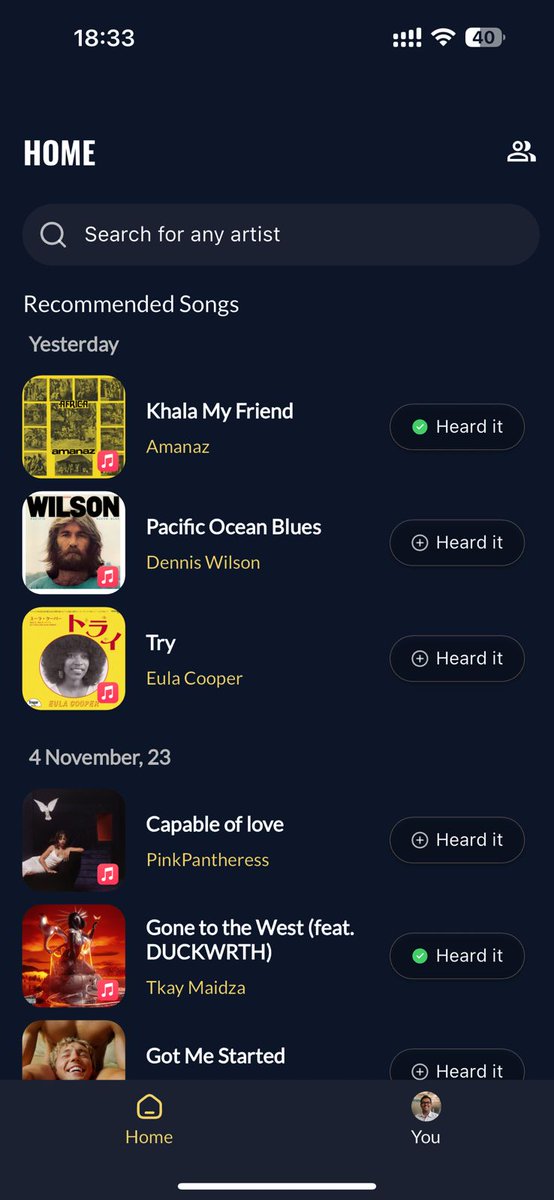
I really wanted to find 1 new song that I could vibe with, every day.
Couldn't find a product that did this, so we BUILT one.
3 new songs. 10 AM. Daily.
Available only for Apple Music users. DM me and I'll share the app link.
The more music you listen to on @AppleMusic, the better the recommendations get!
Spotify coming soon.
3
10
32
7,911



Full breakdown vs the field:
pdfmux: 0.905 (free, CPU)
docling: 0.877
marker: 0.861
mineru: 0.831
We now beat Docling on tables too (0.911 vs 0.887) and Docling is a dedicated ML table extractor.
github.com/NameetP/pdfmux
1
1
88
We also trained a tiny ML heading classifier (sklearn, 212KB) as a fallback.
When font-size heuristics find zero headings on a page, the model gets a shot. It runs on 12 features — size ratio, bold, text length, y-position. No text content features to avoid overfitting.
Fixed docs that had no font-size variation at all.
1
1
42
The big unlock: image table OCR.
Some PDFs embed tables as images; literally, a screenshot of a table baked into the PDF.
Every extractor just... skips them. We don't anymore.
RapidOCR renders the image at 300 DPI, extracts text with bounding boxes, and then clusters by x/y coordinates to reconstruct rows and columns.
1
108
pdfmux v1.5.0 — now 99.5% of the #1 paid AI extractor. At zero cost per page.
0.905 overall on the 200-doc opendataloader benchmark.
Tables: 0.887 → 0.911
Headings: 0.844 → 0.852
Reading order: 0.918 → 0.920
98 docs improved. 3 regressed. Here's how 👇

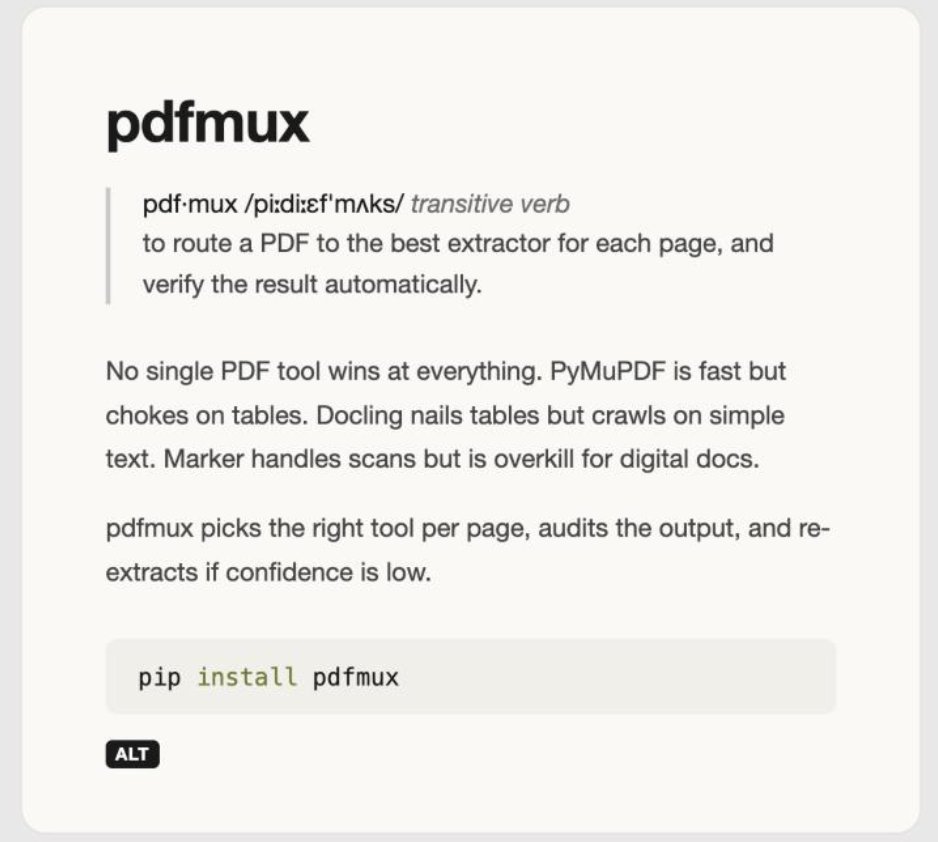
new project — pdfmux
pdf·mux / transitive verb
to route a PDF to the best extractor for each page, and verify the result automatically.
No single PDF tool wins at everything. PyMuPDF is fast but chokes on tables. Docling nails tables but crawls on simple text. Marker handles scans, but is overkill for digital docs.
pdfmux selects the right tool for each page, audits the output, and re-extracts if confidence is low. It doesn't compete with these libraries; it orchestrates them.
Tinkerin. Still early but you can try it: pip install pdfmux
1
3
659
Nameet retweeted

Mar 23
The largest uncaptured lending market on earth has been mispriced for decades. Not because the risk was real because the infrastructure to read it didn't exist.
Wrote about what that looks like on the ground, through one woman in a town that doesn't appear in any fintech pitch deck.
open.substack.com/pub/sairee…

ALT A woman in a town you've never heard of built three businesses with no collateral, no credit history, and near-perfect repayment. What Tehseen reveals about the largest mispriced lending market on earth.
1
2
399
Nameet retweeted

Mar 21
For years, I’ve listened to @AcquiredFM and wondered: what capture’s the essence of emotion of Indian companies?
It’s the word धंधा. 'Business' is too cold. 'Trade' is too small. Dhanda is a life’s work.
It’s the soul of the Indian hustle, built on unique constraints, family legacies, and an audacity that borders on madness.
Today, I’m launching India’s first AI-led long-form podcast to tell those stories from the inside out.
From India, for the world. This is the origin story of our legends.
Here’s the trailer:
19
19
155
12,536
So @nathancgy4 the lead author of this paper is 16 🤓
Mar 16

Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
github.com/MoonshotAI/Attent…

293
New: pdfmux now exports to JSON; because AI agents don't read PDFs, they parse them.
Real use case: extract every table from a 200-page SEC filing as structured JSON → pipe it straight into Claude for financial analysis.
No regex. No pandas. No prompt engineering to "find the revenue table."
Just: pdfmux 10-K.pdf -f json
new project — pdfmux
pdf·mux / transitive verb
to route a PDF to the best extractor for each page, and verify the result automatically.
No single PDF tool wins at everything. PyMuPDF is fast but chokes on tables. Docling nails tables but crawls on simple text. Marker handles scans, but is overkill for digital docs.
pdfmux selects the right tool for each page, audits the output, and re-extracts if confidence is low. It doesn't compete with these libraries; it orchestrates them.
Tinkerin. Still early but you can try it: pip install pdfmux
4
625
new project — pdfmux
pdf·mux / transitive verb
to route a PDF to the best extractor for each page, and verify the result automatically.
No single PDF tool wins at everything. PyMuPDF is fast but chokes on tables. Docling nails tables but crawls on simple text. Marker handles scans, but is overkill for digital docs.
pdfmux selects the right tool for each page, audits the output, and re-extracts if confidence is low. It doesn't compete with these libraries; it orchestrates them.
Tinkerin. Still early but you can try it: pip install pdfmux
3
8
1,615
read more here
pdfmux.com/blog/real-world-p…
1
91
Universal basic income could come in different forms in the future :)
Mar 8

Shenzhen is so underrated. government just rolled out free OpenClaw setup for everyone , 3 months of free computing power, a 50% subsidy on data services, and a 30% hardware subsidy.
1
233
Nameet retweeted

Mar 8
Shenzhen is so underrated. government just rolled out free OpenClaw setup for everyone , 3 months of free computing power, a 50% subsidy on data services, and a 30% hardware subsidy.
81
198
2,466
222,724
Nameet retweeted

Mar 1
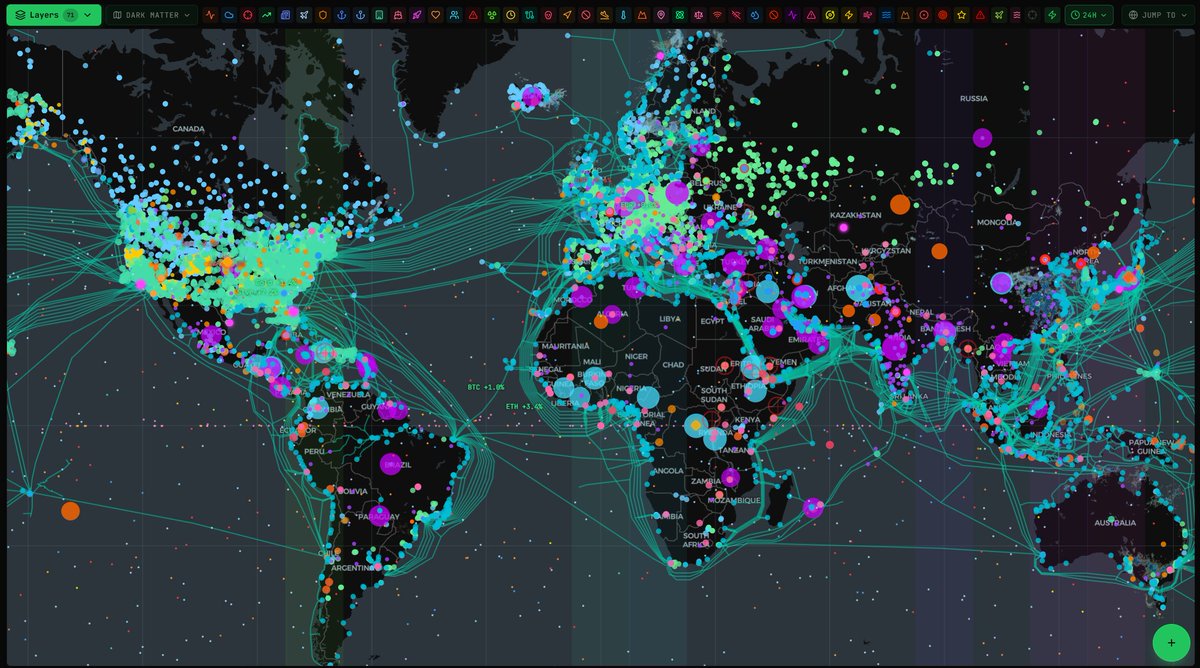
I built this as a side for personal use. But, it turned out to be so much more and so much better than I ever hoped, I am releasing it as a product for everyone.
It's called Situation Deck (SitDeck) and it's a free OSINT dashboard with 180 live data sources. It puts the entire world and almost everything happening in it on one screen.
Here's what it is, why it exists, and why/how I'm giving it away for free.
Mar 1

Announcing SitDeck.com:
A free, real-time, AI-powered OSINT dashboard w/ 180 data feeds, 55 widgets, 70 map layers, alerts & more.
Conflicts. Earthquakes. Flights. Nukes. Cyber threats. Elections.
All live. All in one place.
Monitor the situation. For free.
211
1,517
14,880
1,698,316