
Joined November 2014
- Tweets 10,242
- Following 5,400
- Followers 5,410
- Likes 20,707
295 Photos and videos






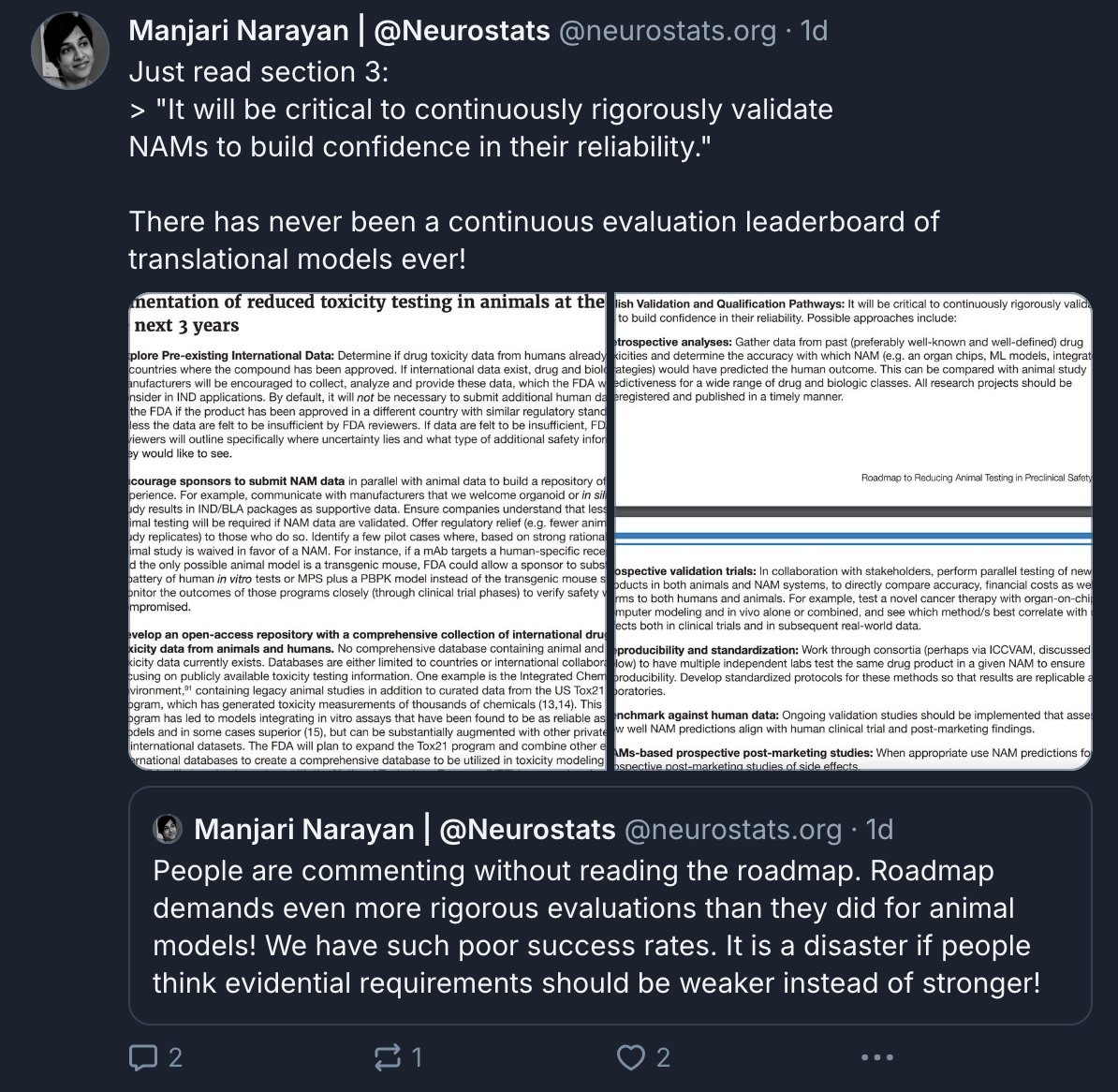

Pinned Tweet

7 Nov 2025
Neurostats 2.0 continues at blog.neurostats.org/
Surrogate Science is coming soon


1
8
1,107
Jan 19
Codecrastinating by bringing old projects to life.
Jan 18

Claude Codecrastination: when you avoid the thing you're supposed to do by cranking out 17 other things you've been wanting to do for a while.
428
Jan 19
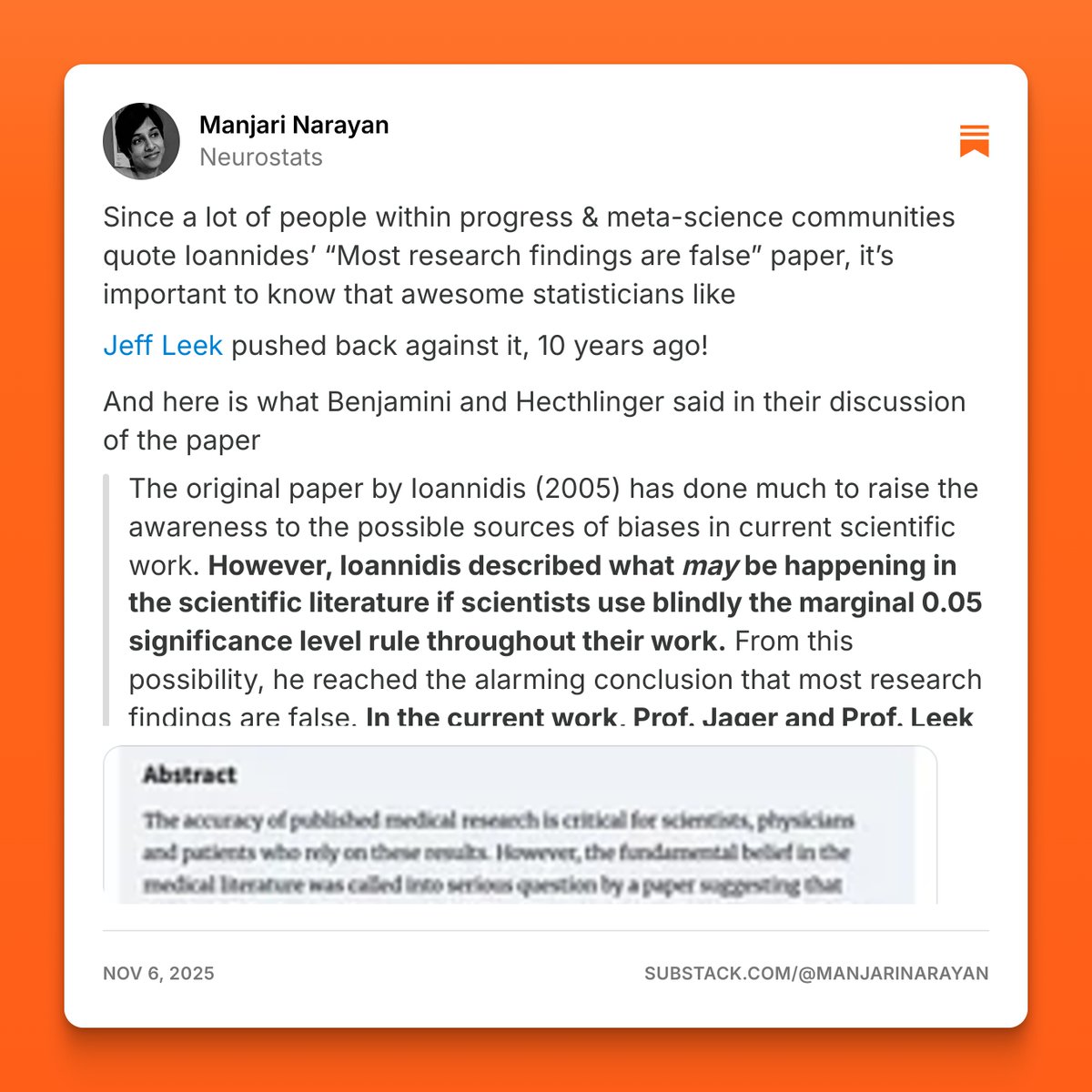
Super interesting to see this. I've been testing how this can play out in science and scientific decision making — we really aren't vigilant about how wrong stuff in the scientific literature might create self-fulfilling loops that extend stagnation

It's so great that there are now multiple orgs doing transparent, rigorous testing of basic premises about how LLMs work and how their behavior can be influenced. So glad that Geodesic exists and excited to work with them on more like this!
3
504
Jan 17
I wish more people asked themselves
"What would John Tukey do?"
He sure as hell would have been exciting things, not stuck on old problems. I mean he worked on information retrieval in his retirement in the 90s.
Jan 17

I found myself similarly disoriented. I suspect we haven't found new abstractions that actually make sense for theory to be cool again.
But you have to develop a taste for different research problems.
1
7
577
Jan 17
I found myself similarly disoriented. I suspect we haven't found new abstractions that actually make sense for theory to be cool again.
But you have to develop a taste for different research problems.
Jan 17

🌶️ Some (perhaps) spicy thoughts. It’s been a while since my last tweet, but I wanted to write about how disorienting it has been from academia to an LLM lab 😅
The kind of research I was trained to do during my PhD almost doesn’t exist here. The obsession with mathematical elegance and novelty is mostly gone. Everything is about scaling data and compute. For a while, that really got to me. At my lowest point, I felt like I’d lost interest in building LLMs altogether. I didn’t feel intellectually challenged anymore.
What made this even stranger was that, at a technical level, things worked. If there was a capability I wanted to teach a model, scaling the right data and compute always got me there, no exception (so far).
But recently, I found a way to reconcile with myself..
I realized the real competition isn’t in the ML recipe anymore. Most teams do roughly the same thing. What actually matters is how fast you can iterate, test ideas, and recover from mistakes. And that speed is mostly backed by infrastructure 🏗️ Faster loops, fewer bugs, better tooling.
Seeing this made me excited again! Infra is its own deep, hard, and intellectually fun problem space.
In 2026, I want to become an ML researcher who’s really good at infra. And I'll come back to ML problems with that edge, and will be excited to share what I find 😌
2
1,123
6 Dec 2025
🧵
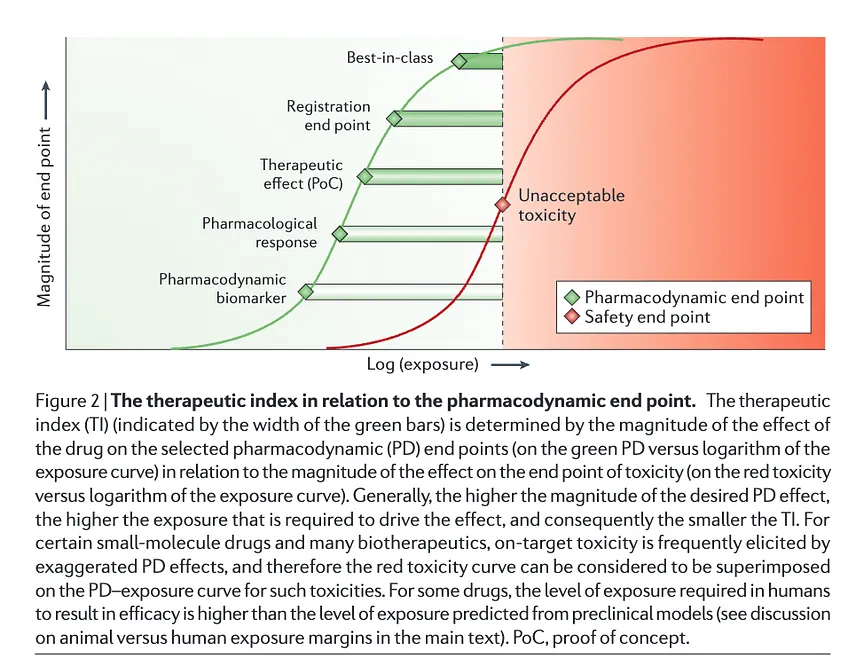
Personal Hamming Problem #1:
Raise the bar for quantifying risk-benefit tradeoffs in drug development.
By risk-benefit tradeoff I mean instantiation of the therapeutic index at some stage of the pipeline.
#Neurips2025
1
1
270
6 Dec 2025
But modern ML and statistics has a much richer set of solutions I am excited about.
Easier solution: Use generalized probability indices that trade off two outcomes both of which have their own sources of measurement error
Even better: modern multi-multicalibration
More 👇
1
171
Manjari Narayan retweeted

17 Nov 2025
🔥 Exactly! Genetic variation is comparatively clean to interpret, but dynamic biological measurements (transcriptomic, epigenetic, imaging, physiological) are deeply entangled with life-course factors: environment, development, health status, social, & reverse causation...
1/3
1
2
2
347
17 Nov 2025
One an start with what the mathematics of a proper scoring criterion ought to be for a problem, what kinds of properties a transformation ought to have, etc..
I've seen this problem emerge in many bio/health competitions over 10 years across kaggle, DREAM, etc..
15 Nov 2025

The recent very welcome @Arcinstute challenge made this painfully clear: defining evaluation metrics is hard. In some cases, trivial data transformations—and even random data—can score astonishingly high.
Great AI performance ≠ biological meaning. 4/6

1
341
Manjari Narayan retweeted

15 Nov 2025
The recent very welcome @Arcinstute challenge made this painfully clear: defining evaluation metrics is hard. In some cases, trivial data transformations—and even random data—can score astonishingly high.
Great AI performance ≠ biological meaning. 4/6
1
1
17
2,321
17 Nov 2025
OMG yes. Glad to see someone else making this point.
Measurements of dynamic biological processes are subject to more novel kinds of confounding and selection bias than genetic markers. 'omics/imaging in biology ignores these challenges of life-course epidemiology
15 Nov 2025

I was just making that point in a 3-tweet thread here. In addition to my closing suggestions there, I would mention the need for life course molecular (omics) epidemiology - high powered.
1
1
2
348
17 Nov 2025
Being fast has advantages when high quality feedback is really quick. But surely deep thinking / pondering / working from first principles has its place for problems that are either have long-horizon/low quality feedback.
Where is the Jim Simon of pharmaceutical forecasting?
15 Nov 2025

You also don’t need to be a gold medalist of the IMO to be a great mathematician. He isn’t drawing a contrast between smart and stupid. It’s a contrast between shallow and deep thinking.
1
804
Manjari Narayan retweeted

15 Nov 2025
You also don’t need to be a gold medalist of the IMO to be a great mathematician. He isn’t drawing a contrast between smart and stupid. It’s a contrast between shallow and deep thinking.
1
40
3,061
17 Nov 2025
Interesting to see do-calculus and causal inference make its way into interpretability.
15 Nov 2025

Thanks! It's the sort of work that I mean to advocate for in the talk. (We have an ICML paper on using causal interp for correctness prediction: openreview.net/forum?id=Ofa1…) The more we can prove out the value propositions in your post, the better – for safety and for interp.
4
1,311
Manjari Narayan retweeted
16 Nov 2025
I did a postdoc at CMU. I was grateful that @ericxing took a chance on me, and was supportive of the work I wanted to do. I was given space and trust, which made all the difference.
1
41
3,706
10 Nov 2025
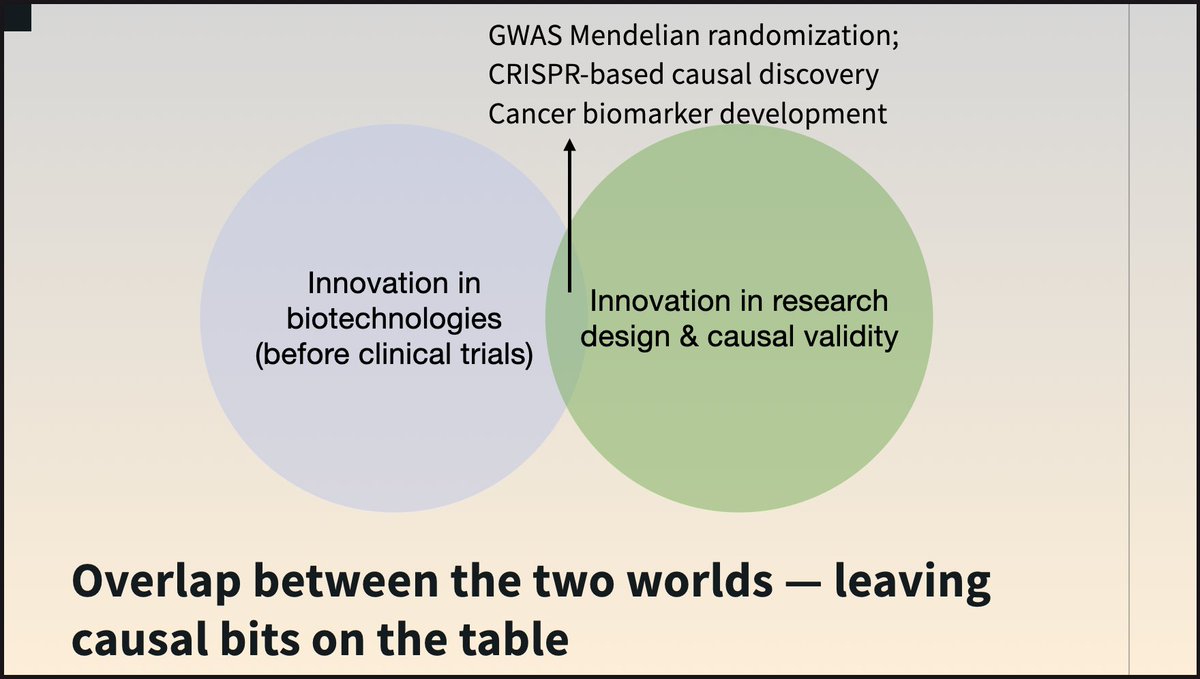
A year ago, I gave a keynote whose thesis was that we leave many potential improvements in the validity of every pharmaceutical forecasting problem on the table.
A call to action for researchers who care about causal validity to go into less comfortable areas of biopharma.
9 Nov 2025

You have heard of AI slop in the context of short video creation. But the same principle applies when it comes to improving drug discovery: we absolutely do not need a deluge of new hypotheses; we need better predictive validity (as per @JackScannell13).
writingruxandrabio.com/p/wha…
1
1
7
1,938
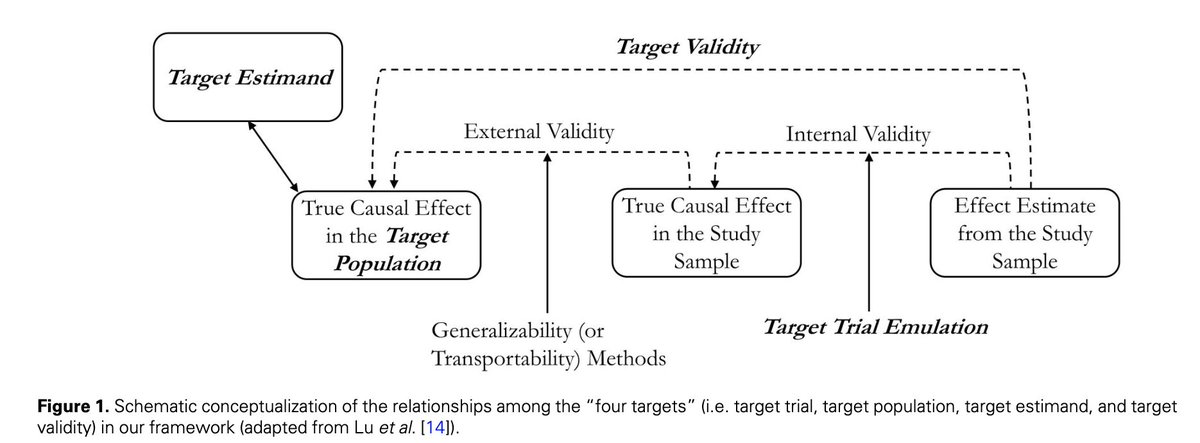
10 Nov 2025
The concept of target validity is grossly under-utilized outside of the frontiers clinical research in epidemiology and medicine. But I see adoption of its analogs as the path to solving the the kinds of predictive validity problems plagues bipharma R&D @JackScannell13
1
1
239
11 Nov 2025
But I slightly disagree with @RuxandraTeslo here. Exploring a deluge of novel and denovo therapeutic molecules needs to be matched by an abundance of validity increasing feedback loops
1
174