
Father of Alon and Yonatan, co-founded Tvinci ( acquired by Kaltura). Managing Director ignite London.
Joined January 2008
- Tweets 521
- Following 1,396
- Followers 817
- Likes 1,987
48 Photos and videos















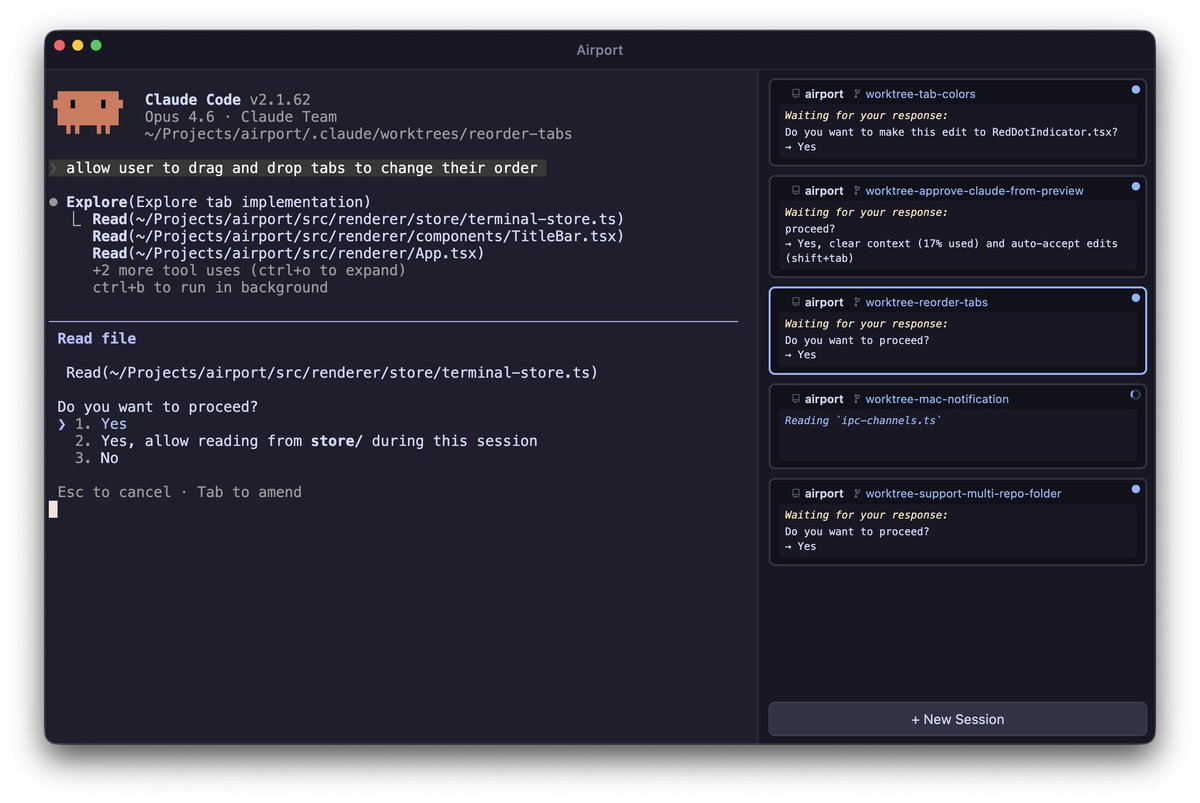
כלי אופן סורס בשם Airport שבנה תומר כהן מ-Mobb מאפשר לסדר מקבול משימות בקלוד קוד.
-תצוגת Review Plan (בקרוב תוכלו להוסיף לקלוד הערות לתיקון)
-מקבול משימות אוטומטי (תנו לקלוד משימות שירים אייג׳נט לכל משימה)
-ניהול workspaces (ניהול הפרויקטים במקום אחד)
get-airport.com
3
3
13
1,810
Ofer Shayo retweeted

28 May 2025
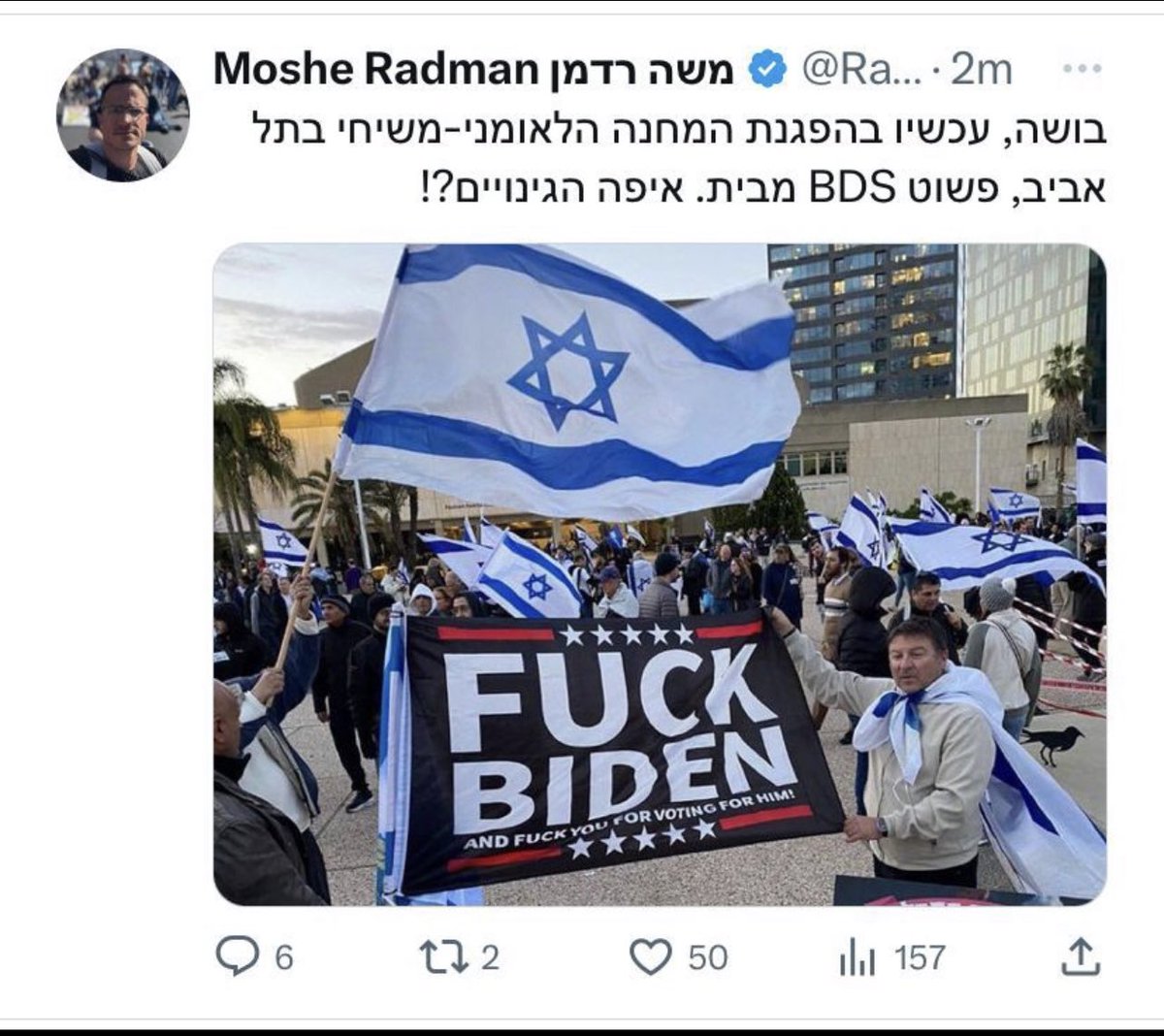
אם היה דירוג של הנאומים בכנסת, הנאום הזה היה זוכה בוודאות בתור נאום העשור.
נעמה המלכה @naamalazimi
39
175
1,319
20,335
Ofer Shayo retweeted

6 Dec 2024
In a new @TheStartupsMag article, @Ofer Shayo, Managing Director of #IntelIgnite London, shares his journey as a #founder and how the ups and downs he experienced along the way gave him the tools to put Intel Ignite’s co-founder-as-a-service model into action.

1
3
4
377
Ofer Shayo retweeted
27 Nov 2024
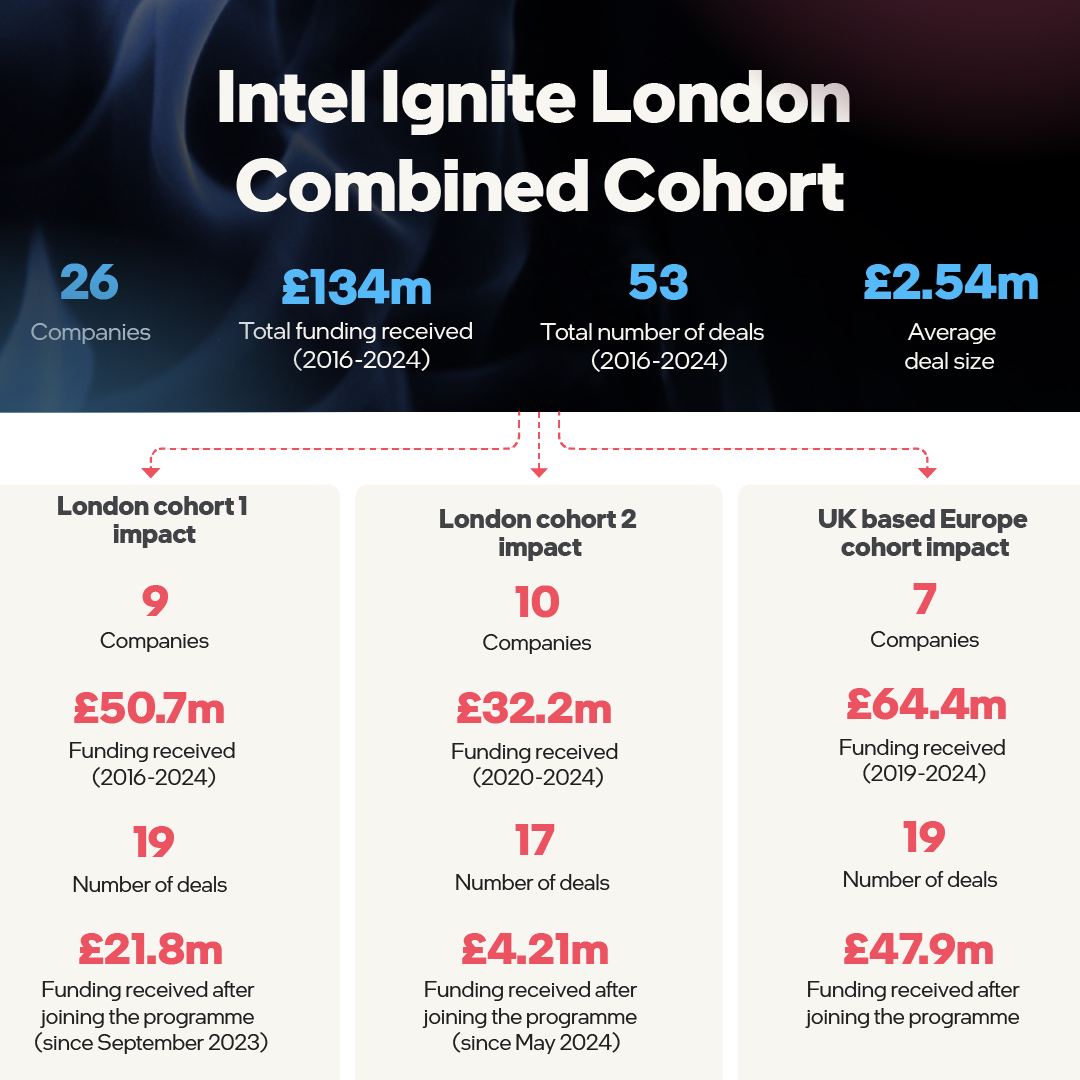
The report discusses the impact of #IntelIgnite’s global and London-based accelerator programs, showcasing key achievements of cohort companies, and features case studies with Intel Ignite London alumni @VaireHQ, @CryptoQuantique, @Tenyks_AI, and #StanhopeAI.
1
2
2
702
Ofer Shayo retweeted

6 May 2024
Watch & Share.
“Screams Before Silence” - A documentary on the sexual crimes committed by Hamas on and after October 7, is now available on @X.
@ScreamsBefore
4
73
149
16,271
Ofer Shayo retweeted
1 May 2024
Our own @Ofer Shayo, Managing Director of #IntelIgnite London, is in @TechRoundUK with advice for #founders to create an environment that prioritizes mental wellness, and how they can protect their own intel.ly/44kMrB9
#IamIntel #Startups #MentalHealthAwarenessMonth
1
4
232
Ofer Shayo retweeted
25 Apr 2024
What an incredible Q1 ‘24 for the Intel Ignite portfolio, who raised over $500M in funding and acquisitions! 🔥
Take a look below and check out the companies in our Q1 ‘24 portfolio funding recap! 👇
#IntelIgnite #IamIntel #Funding #Acquisition #DeepTech #Startups
1
2
262

Ofer Shayo retweeted

8 Mar 2024
2
3
340
Ofer Shayo retweeted

6 Feb 2024
Very excited to release our Model Hub unify.ai/hub 😍 - a collection of LLM endpoints with live runtime benchmarks all plotted across time 📈
We currently have 21 models provided by: @anyscalecompute, @perplexity_ai, @replicate, @togethercompute, @octoml, @MistralAI and @OpenAI, with many more on the roadmap.
We test across different regions (Asia, US, Europe), with varied concurrency and sequence length. By plotting across time, our dashboard highlights the stability and variability of the different endpoints, and their ongoing evolution across API updates and system changes. Our benchmarking code is open source: github.com/unifyai/aibench-l…
Following the great work from @withmartian last week, we mention several new findings in the thread below, focusing on llama-2-70b-chat and mixtral-8x7b-instruct-v0.1 ⬇️
Our unified API also makes it very easy to test and deploy these different endpoints in production, without needing to create several accounts 🔑
Our Hub is a work in progress, and we will be releasing new features every week 🚀
We are granting everyone $5 starting credits with a free top up of $2.50 every week, compatible with all major LLM providers (more coming soon!).
You can sign up here console.unify.ai. Please tell us what you think, and we’ll quickly incorporate feedback into the next weekly release! 😊
As always - let’s unify AI! 🟢💪
16
65
309
34,704
Ofer Shayo retweeted

18 Jan 2024
Bring Back Baby Bibas!

1,104
2,307
10,293
324,616

The RestartIL (restart Israel) event in London today was packed and echoed a resounding message of resilience and hope
We must continue building and planting the seeds for a better future and not let terror win.
Particularly inspiring was the talk by Izhar Shai, who lost his son Yaron on October 7th, and turned his energy into commemorating each one of the victims of that day with a new startup that will be founded.
The quote below, mentioned by Saul Singer, author of Startup Nation and now a new book called the "Genius of Israel" is a strong message on why I'm optimistic on the future of Israel. Each Israeli feels needed and everyone has a part in mending what was broken on October 7th for the generations to come.

1
1
470
Ofer Shayo retweeted

4 Dec 2023
We are excited to share that we have graduated from the inaugural batch of the @IntelIgnite deep tech accelerator program in London!
Better yet, we got a nice trophy. Patrick Camilleri was presented with it at the House of Lords.

3
4
224
Ofer Shayo retweeted
4 Dec 2023
Shiri (32)
Carmel (39)
Noa (26)
Eden (24)
Naama (19)
Eden (28)
Daniella (19)
Karina (19)
Inbar (27)
Doron (30)
Romi (23)
Liri (18)
Agam (19)
Amit (28)
Arbel (28)
All are young women.
All are still there.
4 Dec 2023

BREAKING: State Department spokesman Mathew Miller says it seems that the reason Hamas refused to release all the women who it held hostage was because the terror group didn't want them to tell what they went through while in captivity in Gaza
161
891
2,679
258,441
Ofer Shayo retweeted
25 Nov 2023
Emily wasn’t “lost”, she was abducted by terrorists who hold information about civilian hostages as a bargaining chip.
Emily wasn’t “found”, she was exchanged for prisoners held for terror offences.
You’re the PM of Ireland, Emily is an Irish citizen. Your prayers didn’t do a damn thing. Neither did your tweet.
25 Nov 2023

This is a day of enormous joy and relief for Emily Hand and her family. An innocent child who was lost has now been found and returned, and we breathe a massive sigh of relief. Our prayers have been answered.
Community note
Emily wasn’t lost. She was abducted by terrorists from Hamas.
edition.cnn.com/videos/world/2…
107
814
4,887
176,181
Ofer Shayo retweeted

20 Nov 2023
Silence is complicity.
Thank you @sherylsandberg.
#BelieveIsraeliWomen
3,928
2,667
9,354
710,285