- Tweets 68
- Following 49
- Followers 203
- Likes 24

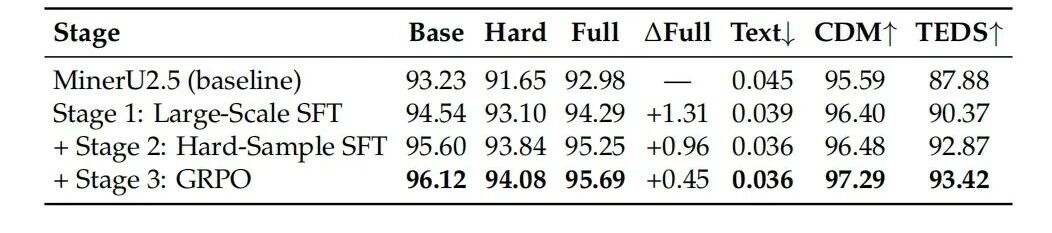



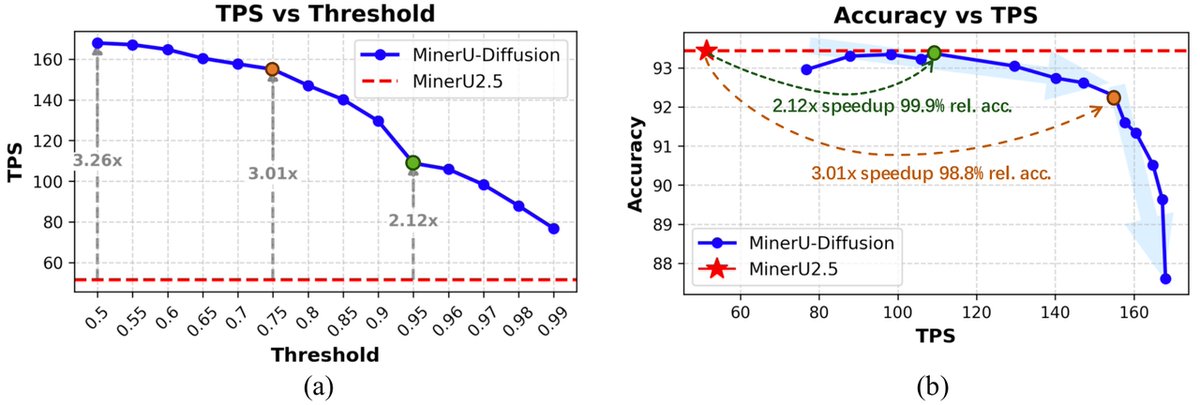

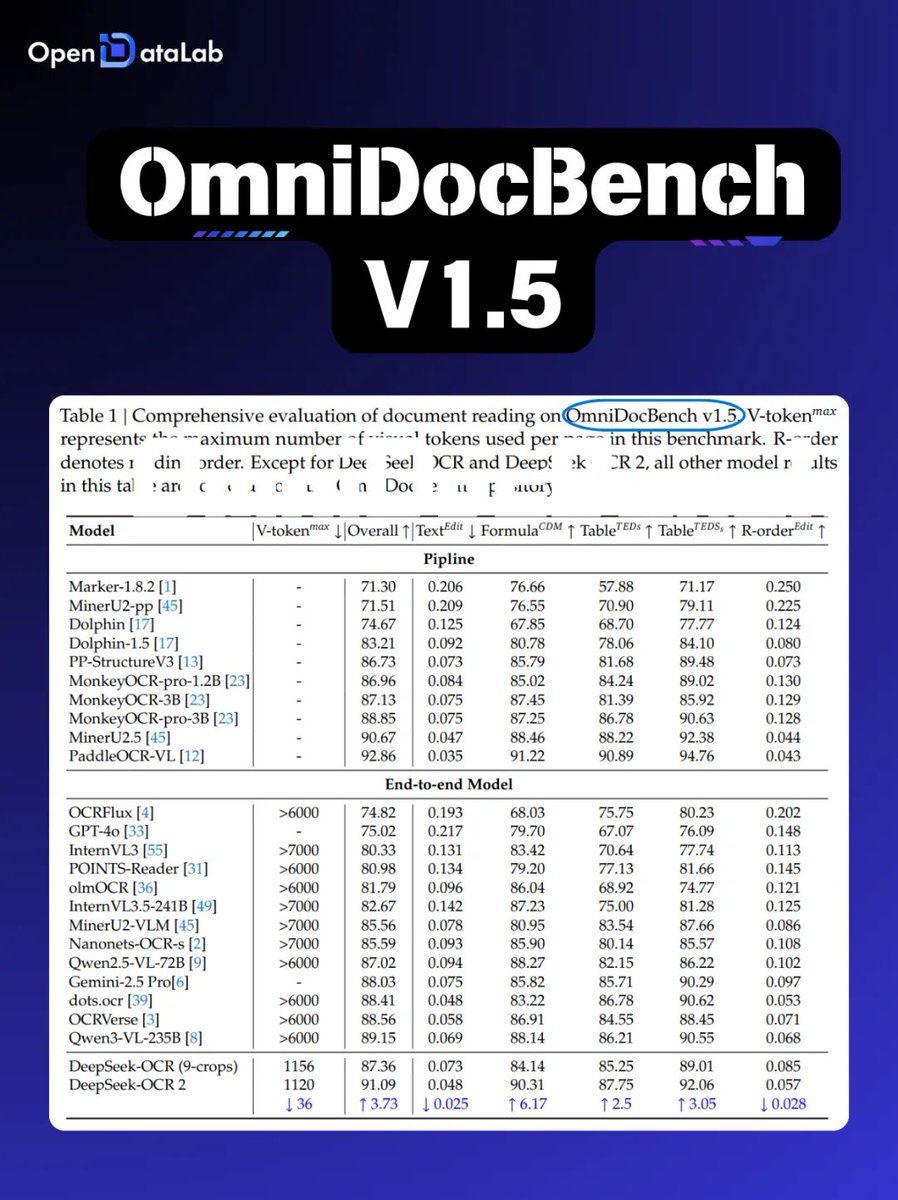








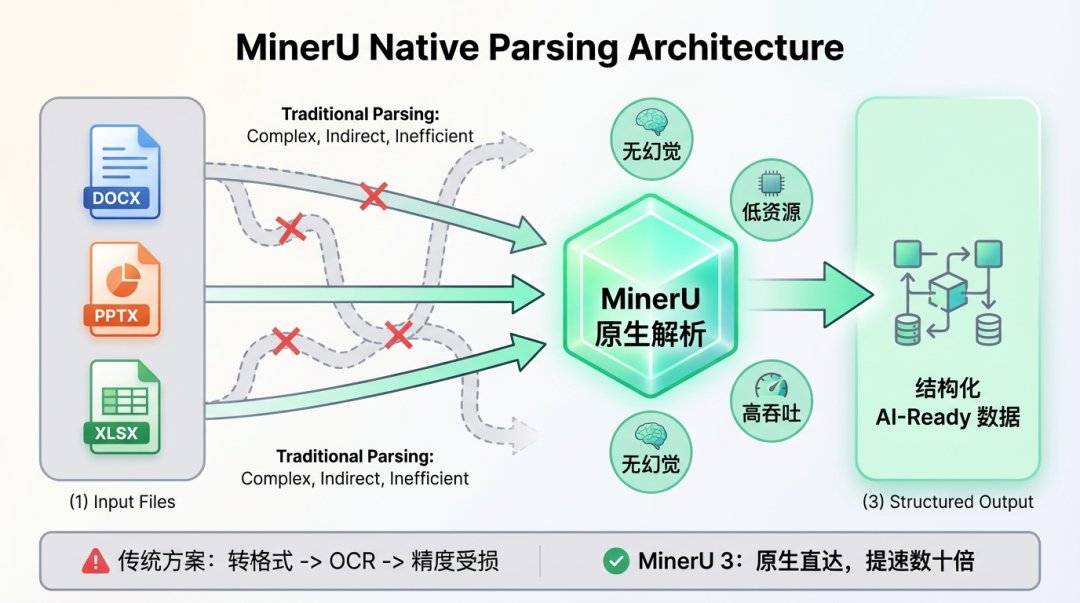
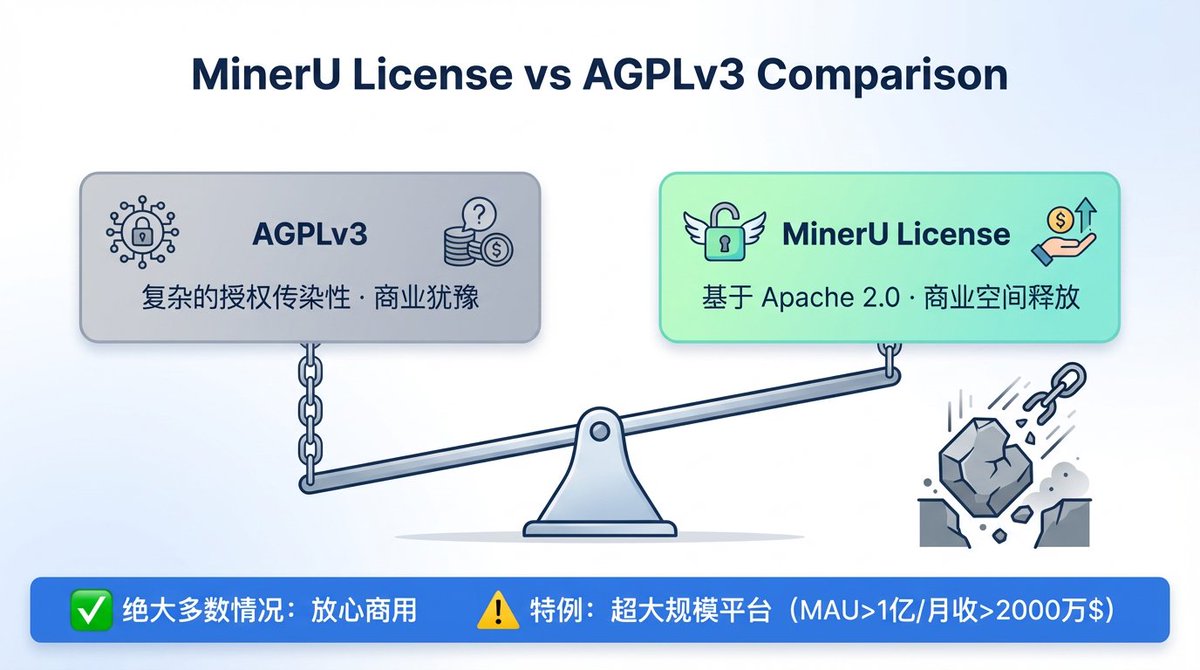
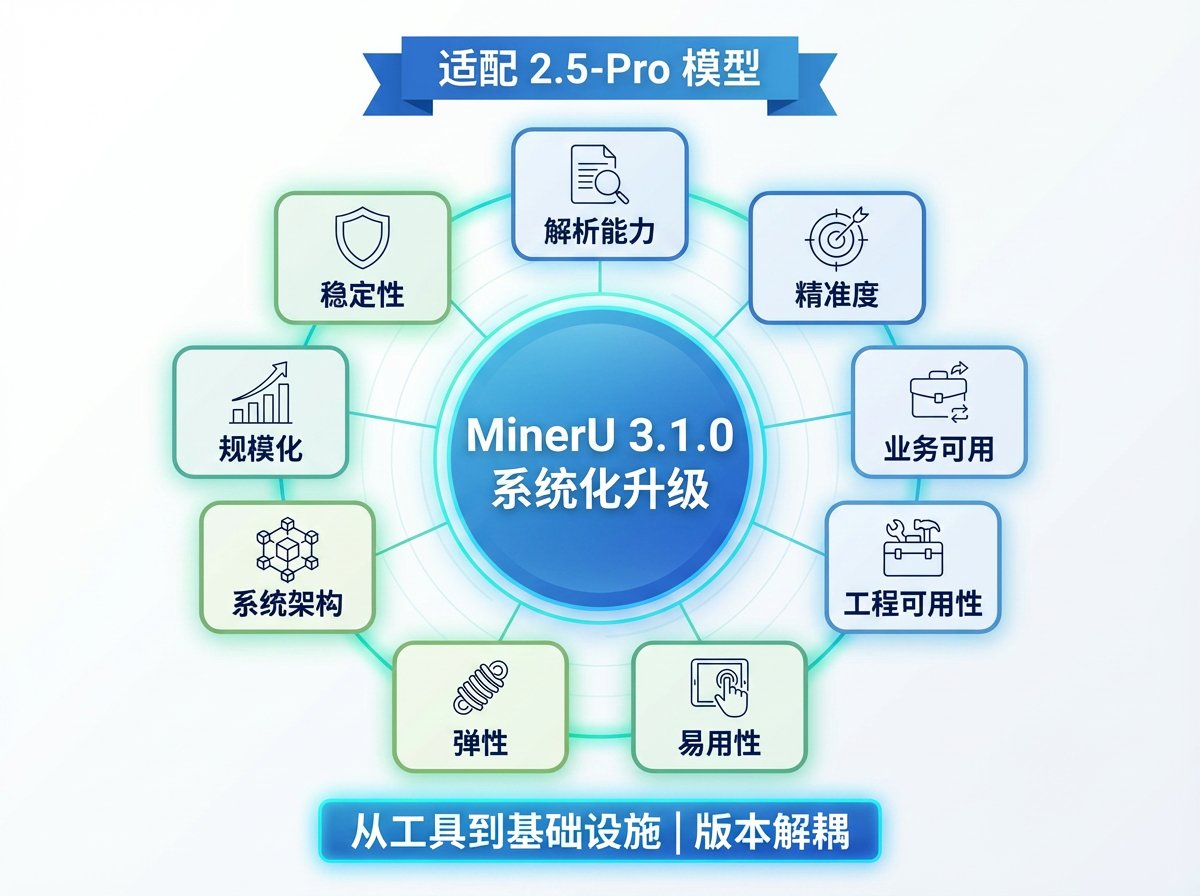
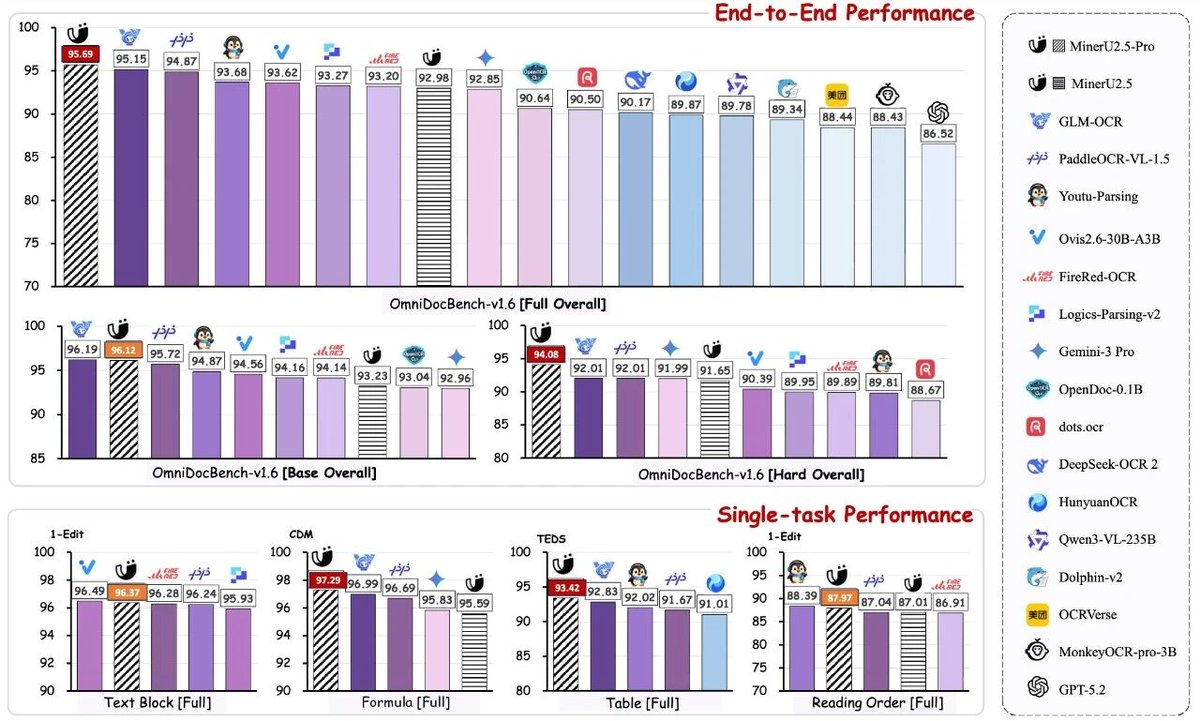








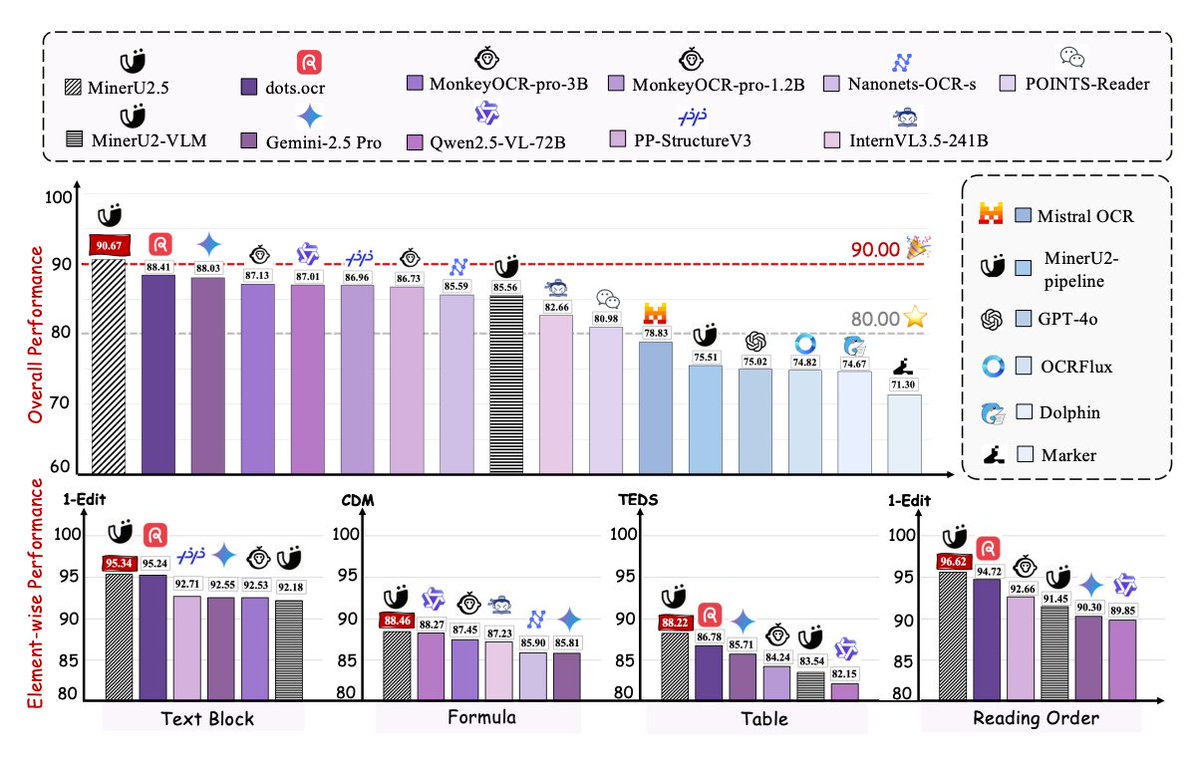
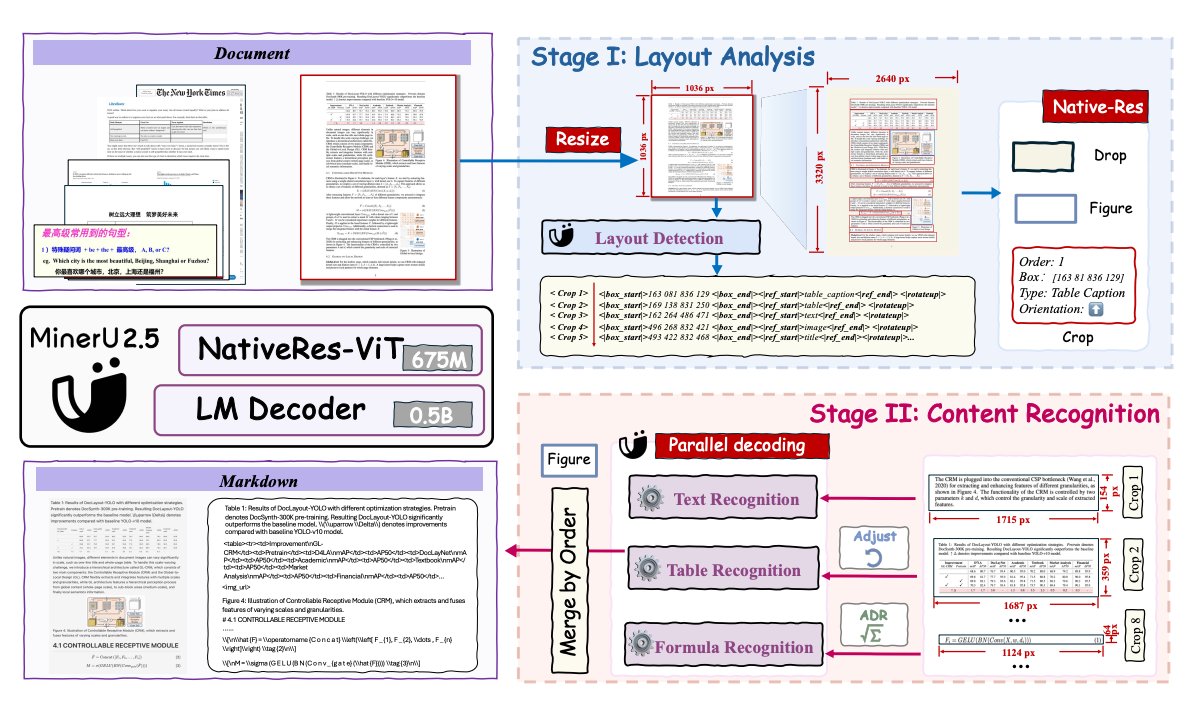

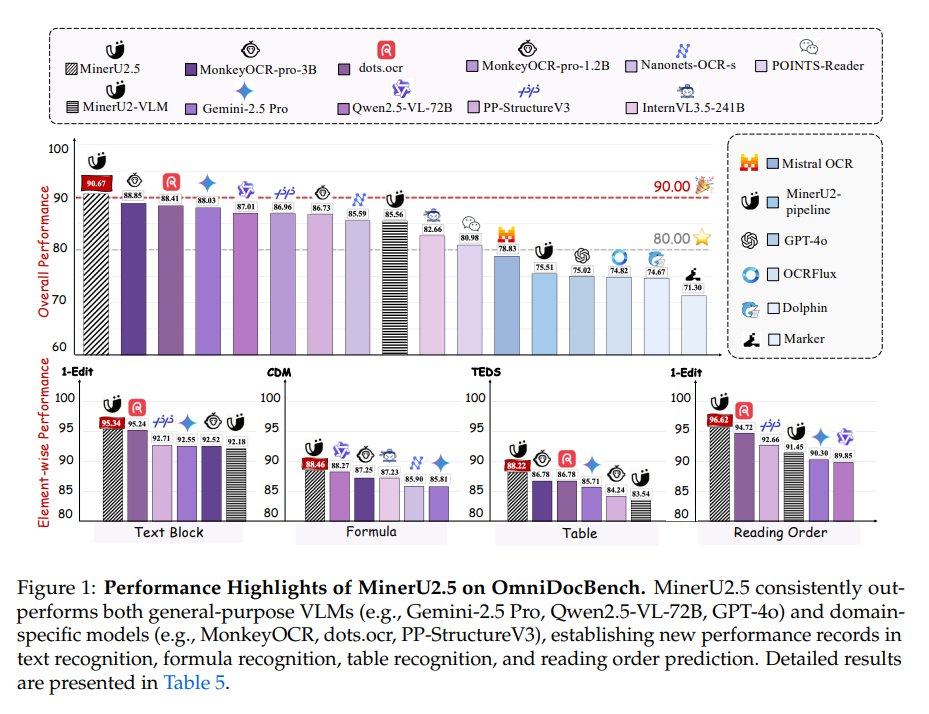
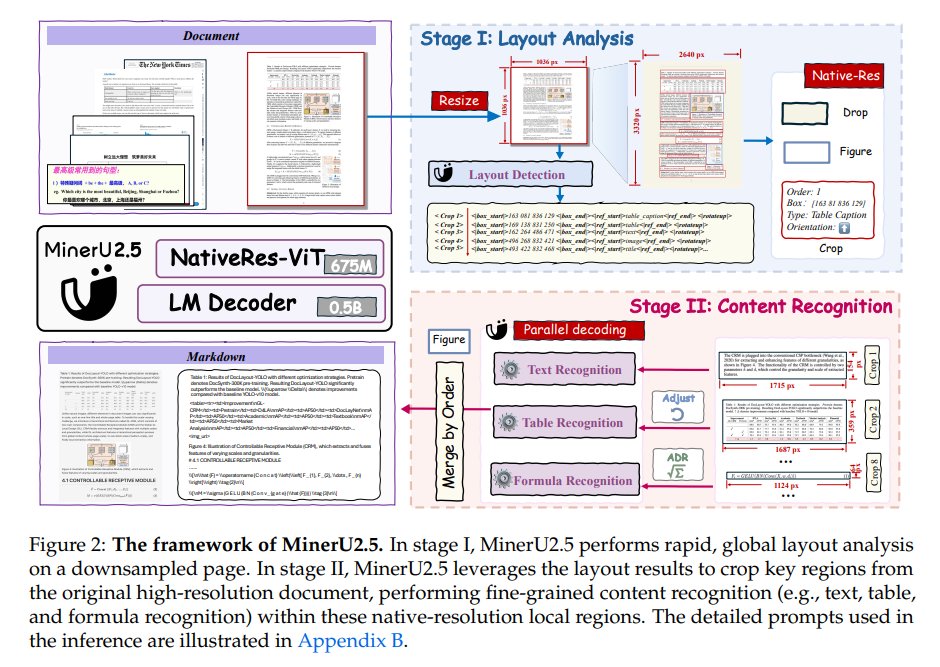
ALT Our OpenDataLab team is excited to share the report, which details our work on a solution that balances high efficiency with strong performance. Here's a look at our results for your reference and for discussion! 💖 📝 Our Core Idea: The Balance Between Efficiency and Precision Lightweight Exploration: Our model is only 1.2B parameters. In an era of massive models, we wanted to explore the potential of smaller models on high-resolution tasks. Engineering Efficiency Breakthrough: MinerU2.5 uses a unique decoupled architecture to effectively reduce computational redundancy. In our tests, its document page throughput is over 4x faster than similar models (like MonkeyOCR-Pro-3B), greatly improving deployment efficiency and cost-effectiveness! 🔥 Data Comparison with Top-Tier Models On standard benchmarks like OmniDocBench, we compared MinerU2.5 against general and specialized models to test its stability and robustness: Performance: MinerU2.5 delivers solid, competitive performance a