
The creators of @HyperWriteAI and more. We build technology to help the world work better.
Joined July 2020
- Tweets 175
- Following 5
- Followers 9,177
- Likes 622
Photos and videos
Pinned Tweet

27 Jun 2023
We’ve been building towards Personal Assistant for a long time.
A ‘self-driving web browser’.
Today, we are making it available to everyone: chrome.google.com/webstore/d…
27 Jun 2023

Introducing `GPT Personal Assistant` -- now available to everyone!
AI that can operate your browser to complete nearly any task.
Try it today: chrome.google.com/webstore/d…
7
8
49
55,837
OthersideAI retweeted

23 Jan 2025
Computer use is getting hot — but we @OthersideAI were doing it well before it was cool.
Josh wrote up a nice post with his reflections from building Self-Operating Computer, the first open-source framework for full OS-level self-driving.
Definitely worth a read.
23 Jan 2025

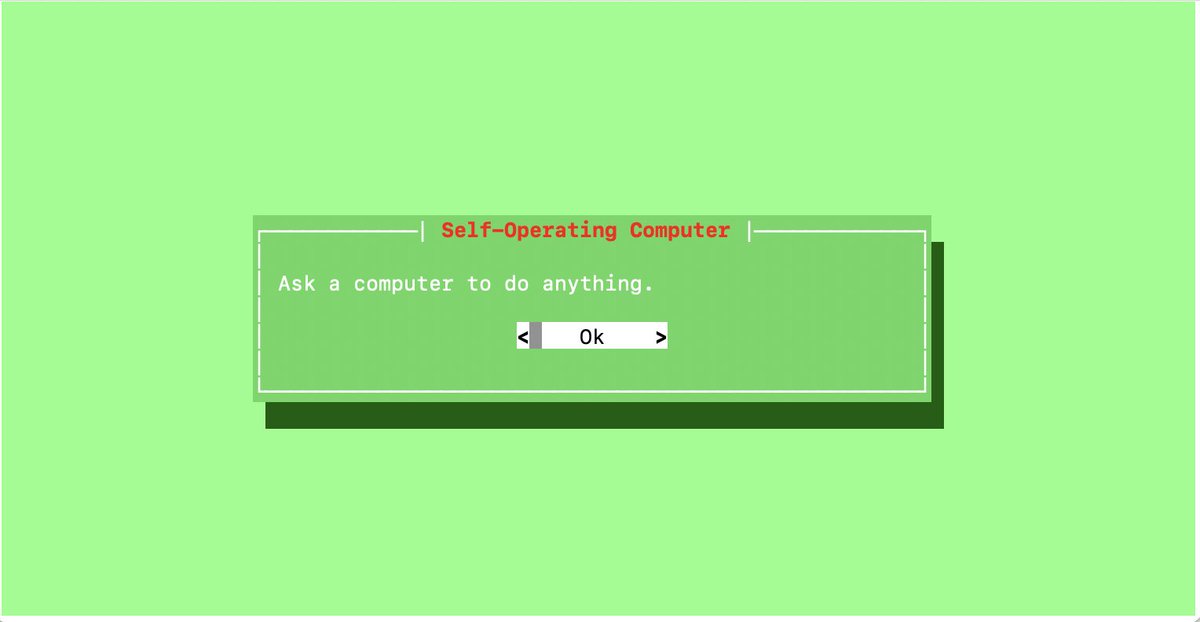
A year ago, I created the Self-Operating Computer Framework—
the first framework to enable multimodal models to operate computers with keyboard and mouse.
This week I wrote a blog post with the story behind the project, reflections on the past year, and thoughts on the future.
Take a look at joshbickett dot com or the link in the comments.
1
2
22
15,704
OthersideAI retweeted
9 May 2024
Tired of AI that sounds like... well, AI?
Never 'delve' again, with Personas for @HyperWriteAI.
Teach your AI to write exactly like you.
Seamlessly switch between our pre-made personas, or mold your AI's tone and behavior to your unique needs.
11
29
264
87,722
OthersideAI retweeted
8 Feb 2024
Excited to share the Agent Trainer and Agent Studio - coming soon to the @HyperWriteAI platform.
Teaching Agents to work the way you like is difficult. So we built a simple way for your Assistant to shadow you and learn.
Just show it a task once, and the AI can repeat it.
45
79
484
135,669
OthersideAI retweeted
27 Nov 2023
Today, we are open-sourcing the @HyperWriteAI Self-Operating Computer framework.
It works pretty well with GPT-4-Vision, but just wait till you see what will be possible with our upcoming Agent-1-Vision model integration :)
27 Nov 2023
𝗪𝗲 𝗮𝗿𝗲 𝗲𝘅𝗰𝗶𝘁𝗲𝗱 𝘁𝗼 𝗼𝗽𝗲𝗻-𝘀𝗼𝘂𝗿𝗰𝗲 𝘁𝗵𝗲 𝗦𝗲𝗹𝗳-𝗢𝗽𝗲𝗿𝗮𝘁𝗶𝗻𝗴 𝗖𝗼𝗺𝗽𝘂𝘁𝗲𝗿 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 𝘁𝗵𝗮𝘁 𝗲𝗻𝗮𝗯𝗹𝗲𝘀 𝗺𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗺𝗼𝗱𝗲𝗹𝘀, 𝗶𝗻𝗰𝗹𝘂𝗱𝗶𝗻𝗴 𝗚𝗣𝗧-𝟰-𝗩𝗶𝘀𝗶𝗼𝗻 𝘁𝗼 𝘀𝗶𝗺𝘂𝗹𝗮𝘁𝗲 𝗵𝘂𝗺𝗮𝗻-𝗹𝗶𝗸𝗲 𝗺𝗼𝘂𝘀𝗲 𝗰𝗹𝗶𝗰𝗸𝘀 𝗮𝗻𝗱 𝗸𝗲𝘆𝗯𝗼𝗮𝗿𝗱 𝗶𝗻𝗽𝘂𝘁𝘀 𝗼𝗻 𝗮 𝗰𝗼𝗺𝗽𝘂𝘁𝗲𝗿.
Based on a given objective, the model estimates the correct X & Y locations for mouse clicks and the appropriate keyboard inputs at each step.
A vision-based agent working at the OS level allows for maximum context and adaptability.
The framework is designed to work with any vision-text multimodal model to evaluate its ability to operate a computer. While significant improvements are needed to achieve human-level performance, this code repository serves as a plugin framework.
We are also excited to announce we’ll be integrating our `𝗔𝗴𝗲𝗻𝘁-𝟭` model with the framework in the coming weeks.
Help us build the future of agents in public.
𝗚𝗶𝘁𝗵𝘂𝗯: github.com/OthersideAI/self-…
𝗛𝗲𝗿𝗲'𝘀 𝗚𝗣𝗧-𝟰-𝗩𝗶𝘀𝗶𝗼𝗻 𝘄𝗿𝗶𝘁𝗶𝗻𝗴 𝗮 𝗽𝗼𝗲𝗺 𝗶𝗻 𝗚𝗼𝗼𝗴𝗹𝗲 𝗗𝗼𝗰𝘀:
11
50
299
88,523
OthersideAI retweeted

27 Nov 2023
𝗪𝗲 𝗮𝗿𝗲 𝗲𝘅𝗰𝗶𝘁𝗲𝗱 𝘁𝗼 𝗼𝗽𝗲𝗻-𝘀𝗼𝘂𝗿𝗰𝗲 𝘁𝗵𝗲 𝗦𝗲𝗹𝗳-𝗢𝗽𝗲𝗿𝗮𝘁𝗶𝗻𝗴 𝗖𝗼𝗺𝗽𝘂𝘁𝗲𝗿 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 𝘁𝗵𝗮𝘁 𝗲𝗻𝗮𝗯𝗹𝗲𝘀 𝗺𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗺𝗼𝗱𝗲𝗹𝘀, 𝗶𝗻𝗰𝗹𝘂𝗱𝗶𝗻𝗴 𝗚𝗣𝗧-𝟰-𝗩𝗶𝘀𝗶𝗼𝗻 𝘁𝗼 𝘀𝗶𝗺𝘂𝗹𝗮𝘁𝗲 𝗵𝘂𝗺𝗮𝗻-𝗹𝗶𝗸𝗲 𝗺𝗼𝘂𝘀𝗲 𝗰𝗹𝗶𝗰𝗸𝘀 𝗮𝗻𝗱 𝗸𝗲𝘆𝗯𝗼𝗮𝗿𝗱 𝗶𝗻𝗽𝘂𝘁𝘀 𝗼𝗻 𝗮 𝗰𝗼𝗺𝗽𝘂𝘁𝗲𝗿.
Based on a given objective, the model estimates the correct X & Y locations for mouse clicks and the appropriate keyboard inputs at each step.
A vision-based agent working at the OS level allows for maximum context and adaptability.
The framework is designed to work with any vision-text multimodal model to evaluate its ability to operate a computer. While significant improvements are needed to achieve human-level performance, this code repository serves as a plugin framework.
We are also excited to announce we’ll be integrating our `𝗔𝗴𝗲𝗻𝘁-𝟭` model with the framework in the coming weeks.
Help us build the future of agents in public.
𝗚𝗶𝘁𝗵𝘂𝗯: github.com/OthersideAI/self-…
𝗛𝗲𝗿𝗲'𝘀 𝗚𝗣𝗧-𝟰-𝗩𝗶𝘀𝗶𝗼𝗻 𝘄𝗿𝗶𝘁𝗶𝗻𝗴 𝗮 𝗽𝗼𝗲𝗺 𝗶𝗻 𝗚𝗼𝗼𝗴𝗹𝗲 𝗗𝗼𝗰𝘀:
105
378
2,564
2,079,058
OthersideAI retweeted
19 Oct 2023
Introducing the world's most powerful AI Assistant.
Personal Assistant is NOT just another AI chatbot.
It can:
- Operate your browser to actually complete tasks
- Cite sources, so you can trust what it says
- And so much more.
You won't believe what Personal Assistant can do:
56
86
696
276,929
OthersideAI retweeted

25 Sep 2023
Great explanation of AI Agents from @JStaatsCPA — and how HyperWrite Personal Assistant is the best example of this tech today.
3
5
23
6,849
OthersideAI retweeted
3 Aug 2023
Personal Assistant by @HyperWriteAI is now live on Product Hunt!
The first publicly available AI agent that can operate a browser like a human.
An upvote or share would mean a lot to me :)
producthunt.com/posts/person…
21
40
255
114,667
OthersideAI retweeted
2 Aug 2023
Introducing `Agent-1`: a breakthrough foundation model that can operate software like a human.
This is the brain powering Personal Assistant.
We’re already well above previous state-of-the-art, and we’re improving massively each week.
More details:
45
166
902
252,383
OthersideAI retweeted
8 Jun 2023
Tell me what you’d use Personal Assistant for.
I’ll give 50 people with great use-cases immediate access to test Personal Assistant Alpha!
12 Apr 2023
Today, we’re unveiling Personal Assistant - @HyperWriteAI's groundbreaking AI agent that can use a web browser like a human.
One agent to rule them all.
It’s time to reimagine the way we interact with the internet.
17
8
18
19,423
OthersideAI retweeted
14 Apr 2023
I asked our web-surfing AI to solve Wordle.
The result is not what I was expecting, but shows how smart the system we’re building is.
It did what so many people do: it cheated and searched Google for the answer first 🤯
15
54
376
189,631
OthersideAI retweeted
12 Apr 2023
Today, we’re unveiling Personal Assistant - @HyperWriteAI's groundbreaking AI agent that can use a web browser like a human.
One agent to rule them all.
It’s time to reimagine the way we interact with the internet.
254
406
2,409
1,567,669
OthersideAI retweeted
14 Mar 2023
Exciting news! @HyperWriteAI now uses GPT-4!
Just hours after GPT-4's release, we have fully integrated it across our platform, bringing you insanely impressive results.
5
13
78
25,307
OthersideAI retweeted
1 Mar 2023
Honored to be featured in @WIRED's piece on how AI is transforming email!
The future of communication is here, and we're excited to be at the forefront of it.
And if you haven't yet tried @HyperWriteAI... chrome.google.com/webstore/d…
3
11
5,788
24 Jan 2023
So proud of our partnership with @CohereAI and the amazing work we've been able to do together.
Check out this interview with our co-founder @mattshumer_ to learn more about our collaboration and how we're thinking about generative AI.
24 Jan 2023
I’m excited to share an interview I did with @CohereAI on our journey together and my thoughts on generative AI.
Cohere has been an amazing partner, and their low-latency solutions have helped us power the @HyperWriteAI Chrome extension.
Check it out!
txt.cohere.ai/hyperwrite-pow…
1
1
12
3,738
OthersideAI retweeted
19 Jan 2023
We're excited to announce the launch of Custom Templates for @HyperWriteAI!
Now, you can easily create your own AI templates, tailored to your specific needs.
Let's dive in...
2
5
35
10,699
OthersideAI retweeted
18 Dec 2022
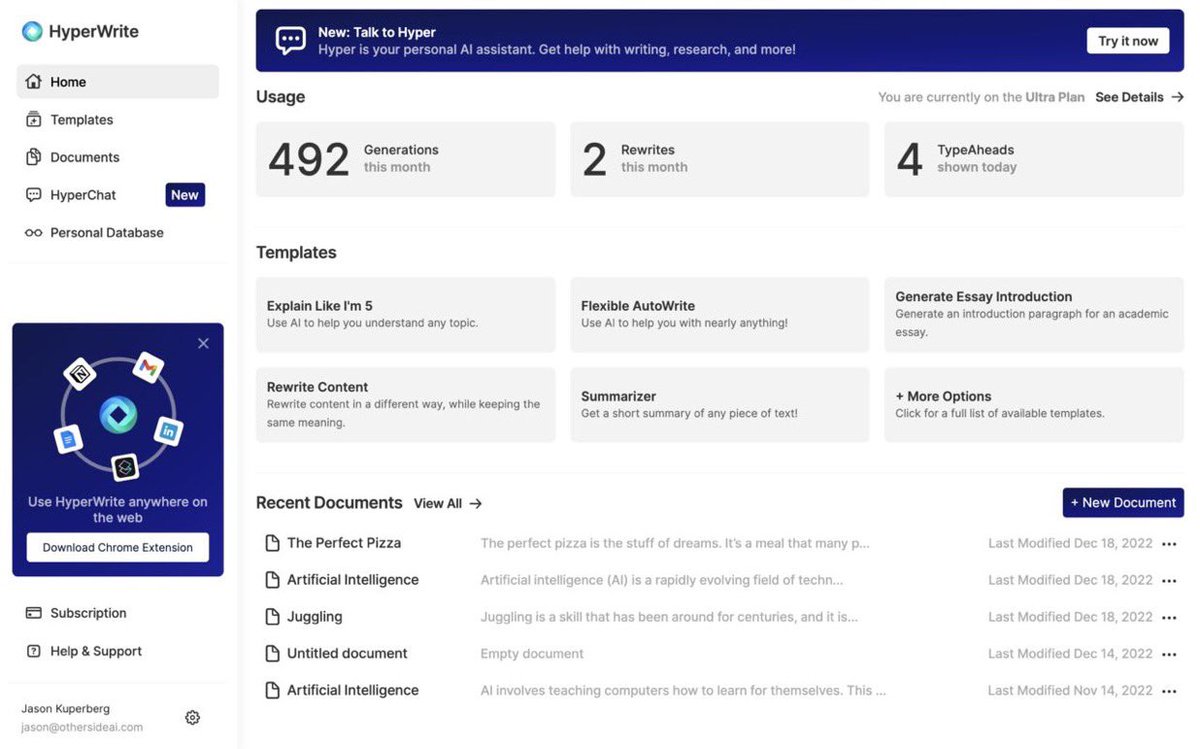
Design has traditionally been @HyperWriteAI’s biggest weakness… until now.
Our new platform looks 🔥 and our users are loving it.
Big props to @josh_bickett, @abby_herzog, @JasonKuperberg and @kentdebruin for making it happen!
3
7
38
6,168
OthersideAI retweeted
16 Dec 2022
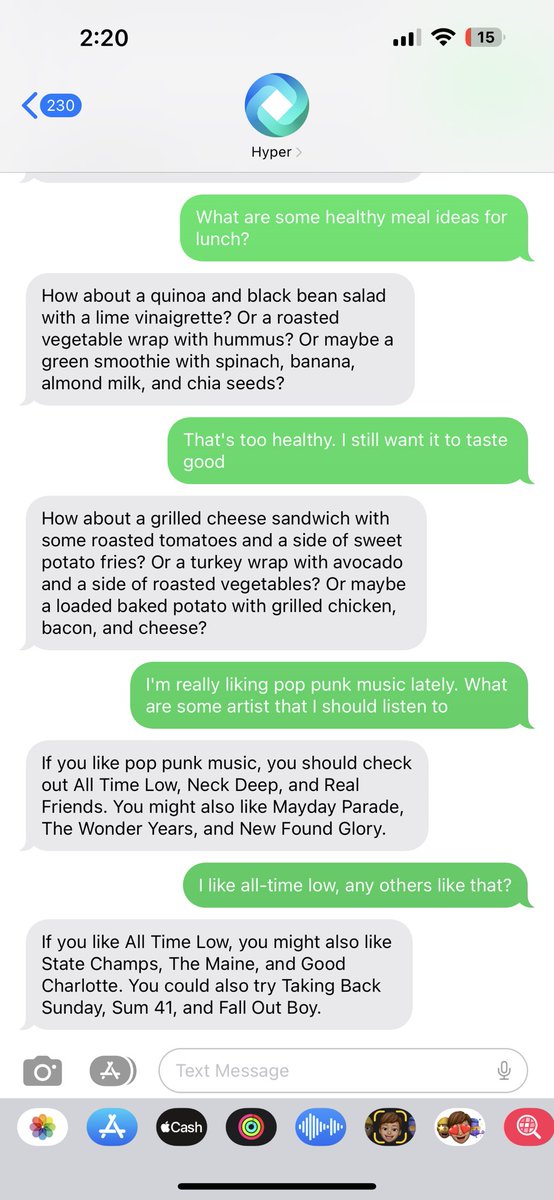
It’s back!!!
Text with our insanely smart and helpful AI, powered by GPT-3.5.
To get started, just send a text to 1 (631) 699-2703

16 Dec 2022

Oh hell yes. You can now text ChatGPT’s cousin (created by @HyperWriteAI).
1 (631) 699-2703
4
10
47
15,089
OthersideAI retweeted
8 Dec 2022
Previously, I was an indie hacker.
Since joining @OthersideAI, I've greatly enjoyed seeing how much can be done when you are part of a talented team. I think the next 6 months are going to be exponential.
We're looking for a talented frontend engineer, reach out if interested!
1
4
26