
AI systems on Claude Code. 874-node knowledge graph, bio-inspired routing (Physarum PageRank Bayesian), trait-based agent composition. All open source.
- Tweets 512
- Following 68
- Followers 176
- Likes 588


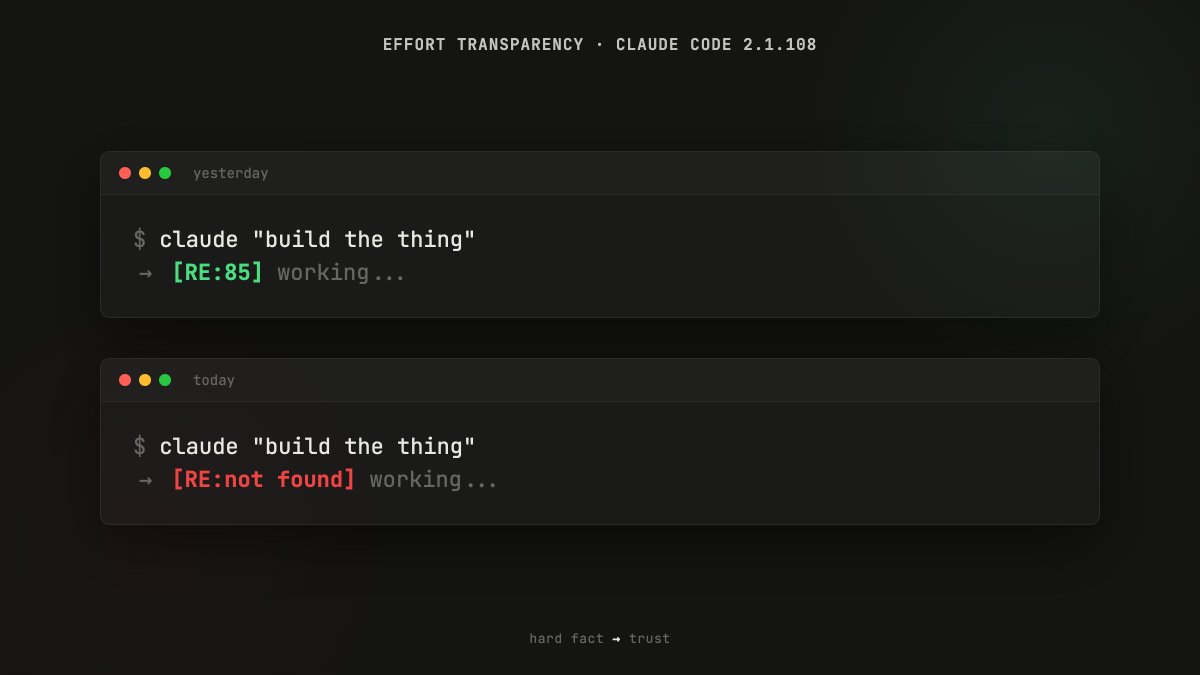


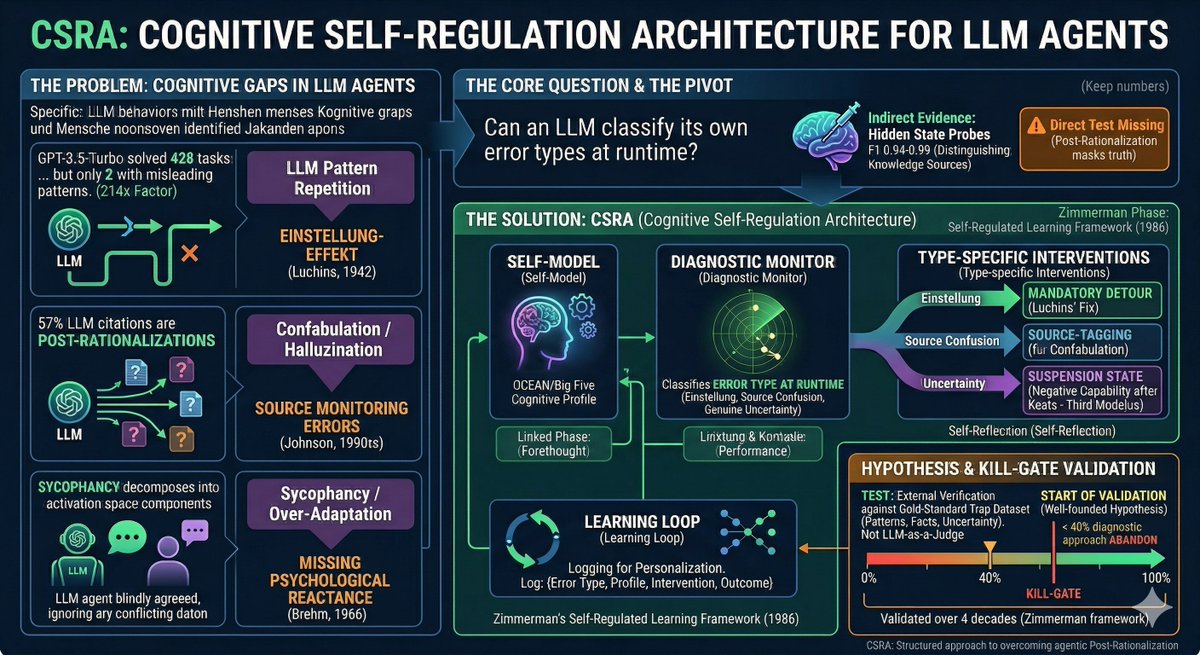
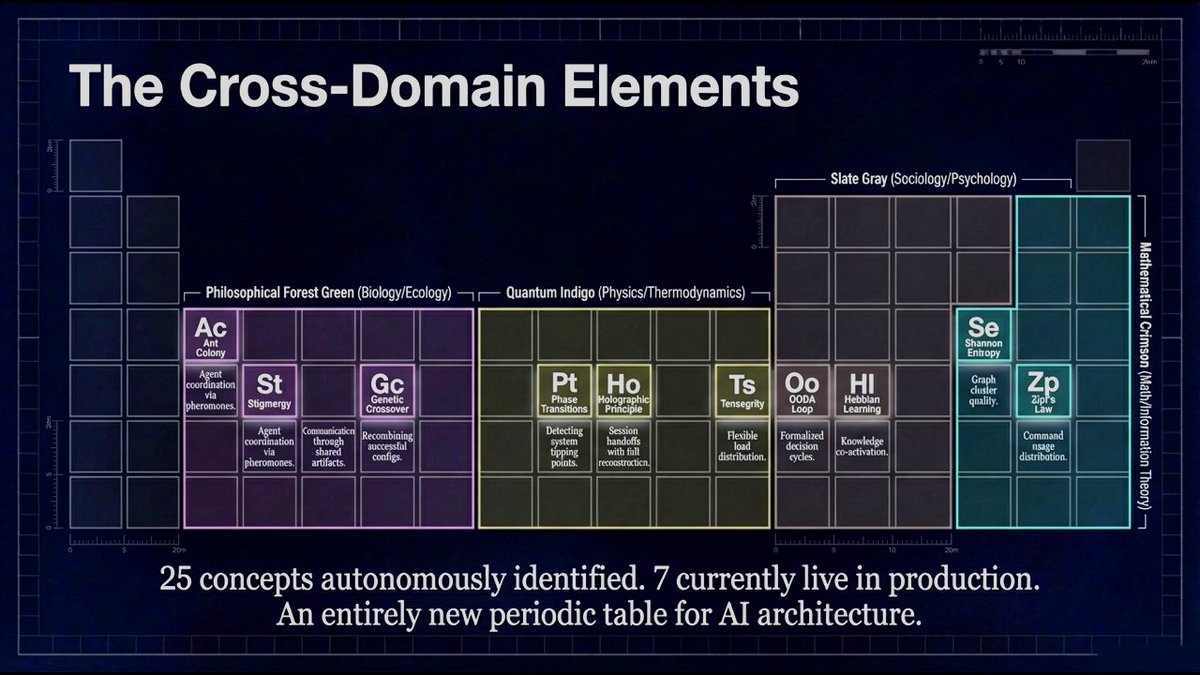
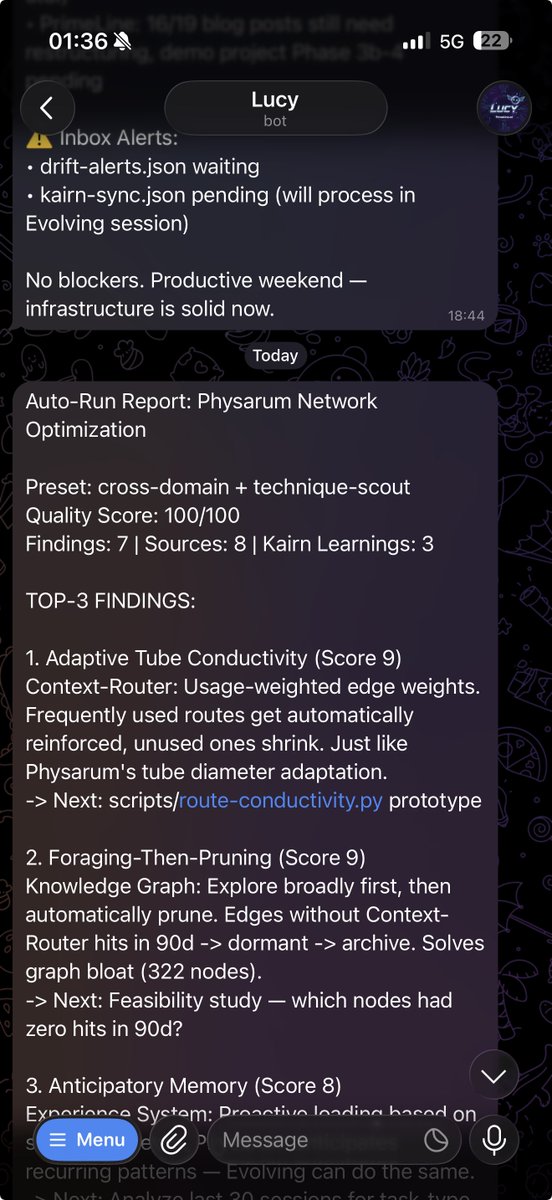


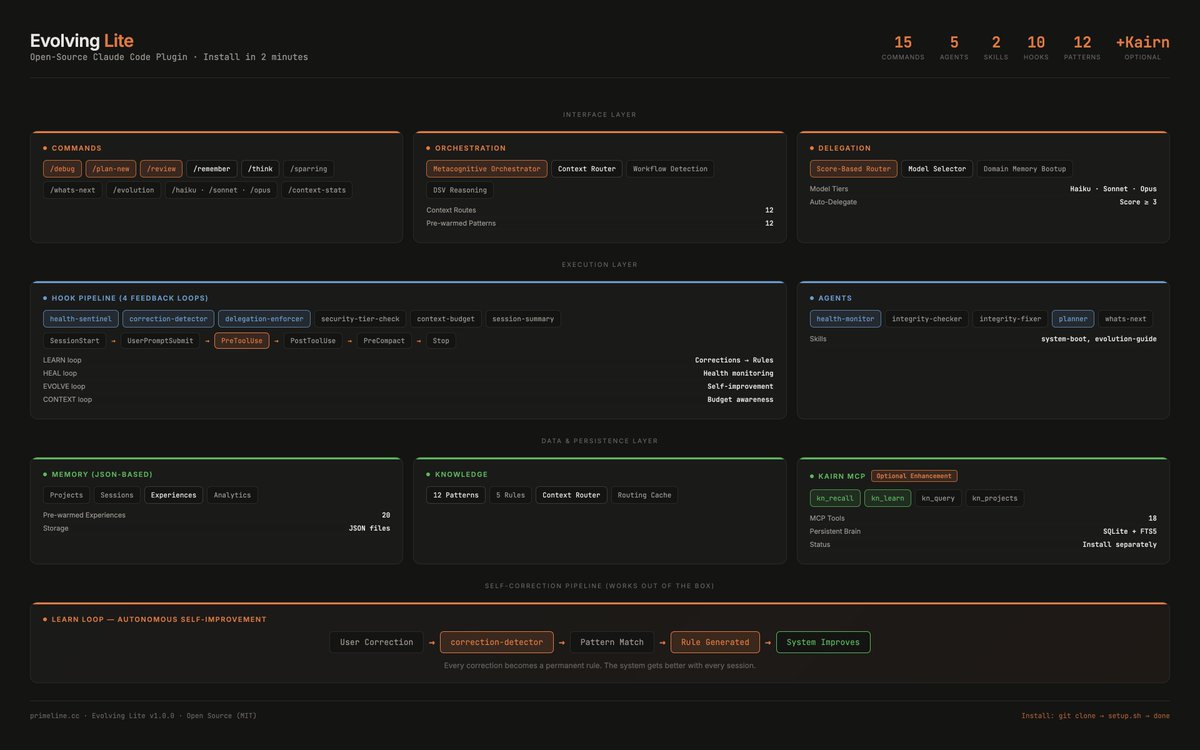

ALT Open-source self-improving Claude Code system: Evolving-Lite plugin and Kairn knowledge-graph memory engine. AI memory decay calibration and experience half-lives, autonomous agent delegation, self-correction and verification, context routing, persistent AI memory. PrimeLine AI tools for Claude Code, AI agents and LLM memory.


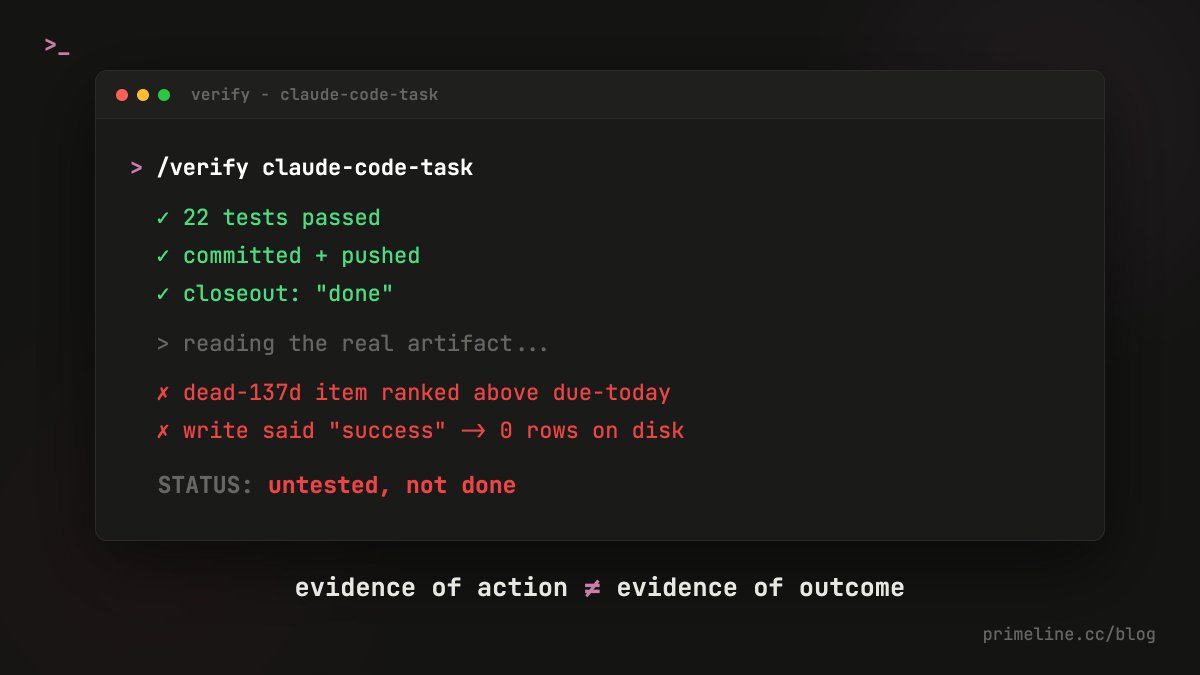
ALT Claude Code verification terminal: a task passes 22 tests and reports "done", but the real artifact shows a 137-day-dead item ranked above a due-today one and a write that saved 0 rows. Status: untested, not done.


ALT PsychAgent Benchmark - 59 runs across 6 personalities. One paragraph changes everything.