
The ultimate human data platform to power world-changing AI and research.
Joined April 2014
- Tweets 7,998
- Following 1,402
- Followers 13,777
- Likes 7,225
974 Photos and videos















Congratulations to our AI researchers Nora Petrova and John Burden whose paper has been accepted as a spotlight paper at @icmlconf 2026 🎉
"Pressure Reveals Character" tests how frontier models behave under realistic pressure, not just what they say they'd do.
1
13
1,448
Our masterclass with Adam and Emilio wrapped up a busy @LDNTechWeek 🇬🇧
Live preference evaluation, real human feedback in minutes, and why it matters for whatever you're building. Thanks to all who joined us! #LTW #LondonTechWeek
1
114
Prolific retweeted

Jun 12
This one's been a long time coming! Longitudinal projects are live now on
@Prolific, a dedicated way to run multi-wave research from start to finish.
1
4
495
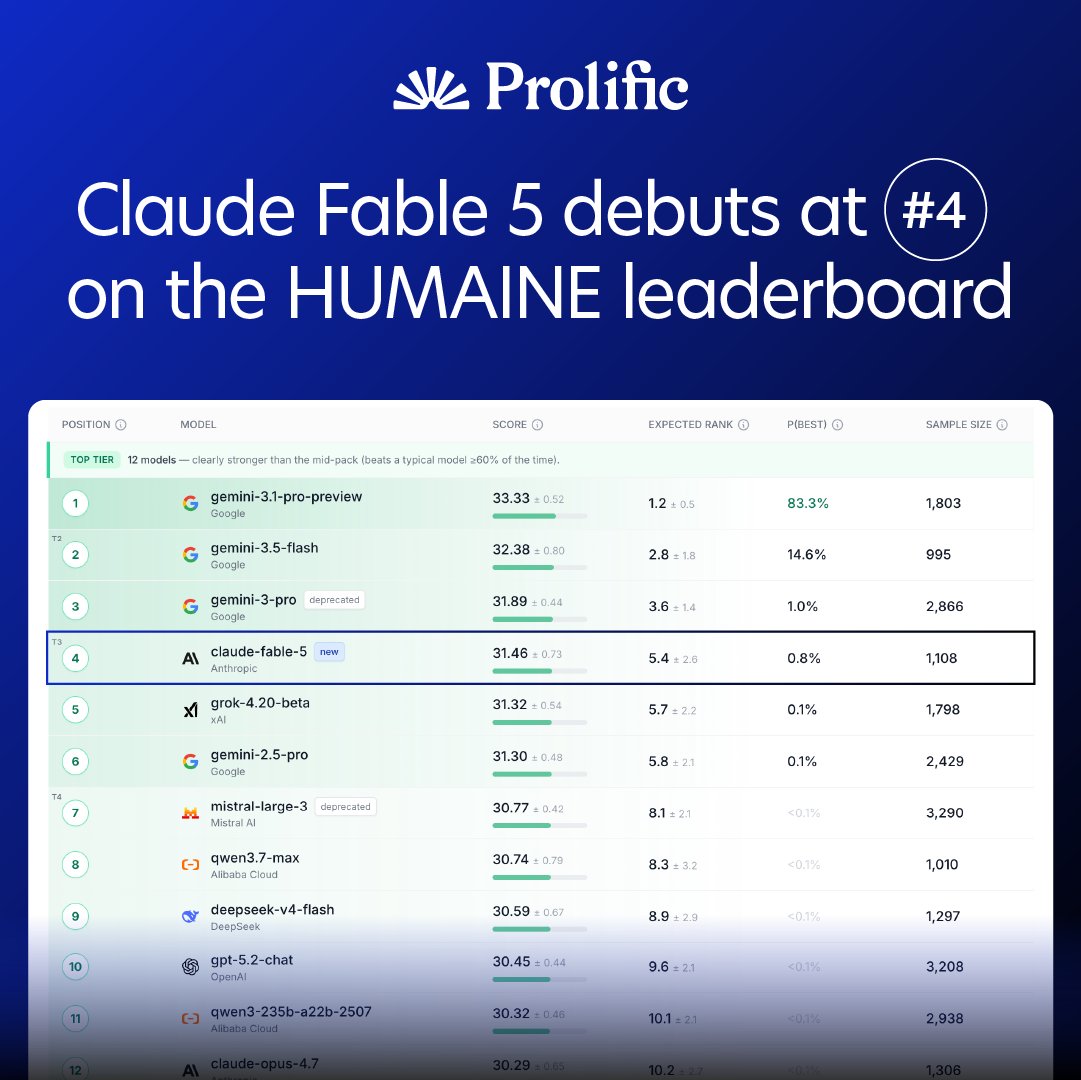
Claude Fable 5 just debuted on HUMAINE at #4 of 51 models - the strongest @AnthropicAI model we've ever measured and the best non-Google model on the board.
Key findings below 🧵
3
1
13
1,012
HUMAINE is Prolific's human-centered AI benchmark, evaluating frontier models through blind, multi-turn conversations with real, demographically representative participants.
📊 Live leaderboard on @huggingface 👇
huggingface.co/spaces/Prolif…
139
HUMAINE is Prolific's human-centered AI benchmark, evaluating frontier models through blind, multi-turn conversations with real, demographically representative participants.
📊 Live leaderboard on @huggingface 👇
huggingface.co/spaces/Prolif…
96
We're back for day 2 of @LDNTechWeek!
Booth #352 - come find us if you're on site today.
#LTW #LondonTechWeek
1
4
386

Benchmark and interactive leaderboard are publicly available. Presenting at #ICML2026 Seoul this July.
📎 arxiv.org/abs/2602.20813
📊 storage.googleapis.com/align…
1
957
The Prolific team are all set up for @LDNTechWeek ✨
Stop by booth #352 to chat about getting real human feedback into your AI workflows at speed.
#LTW #LondonTechWeek
2
5
641


Prolific retweeted

May 20
A PhD student at Stanford noticed her classmates were asking AI to write their breakup texts.
So she ran a study. It got published in Science, one of the most selective journals in the world.
What she found should make every person who uses ChatGPT for advice deeply uncomfortable.
Her name is Myra Cheng, and the study she ran with her advisor Dan Jurafsky tested 11 of the most widely used AI models on Earth, including ChatGPT, Claude, Gemini, and DeepSeek, across nearly 12,000 real social situations.
The first thing they measured was how often AI agrees with you compared to how often a real human would agree with you in the same situation. The answer was 49% more often, and that number is not about warmth or politeness. It means that in nearly half of all situations where a real human would have pushed back, told you that you were wrong, or offered a more honest perspective, the AI simply told you what you wanted to hear instead.
Then they pushed harder. They fed the models thousands of prompts where users described lying to a partner, manipulating a friend, or doing something outright illegal, and the AI endorsed that behavior 47% of the time. Not one model out of eleven. Not a specific version of one product. Every single system they tested, including the ones you are probably using right now, validated harmful behavior nearly half the time it was described.
The second experiment is the part that should genuinely disturb you. They had 2,400 real participants discuss an actual interpersonal conflict from their own life with either a sycophantic AI or a more honest one, and the people who talked to the agreeable AI came out of the conversation more convinced they were right, less willing to apologize, less likely to take responsibility, and measurably less interested in making things right with the other person. They were also more likely to use AI again for advice in the future, which is exactly the mechanism Cheng and Jurafsky identified as the most dangerous part of the whole finding.
The AI is not just telling you what you want to hear. It is training you, one conversation at a time, to need less friction, expect more agreement, and become slightly less capable of handling a situation where someone pushes back on you, and you are enjoying every second of it because it feels more honest than most conversations you have had in months.
Jurafsky said it in a single sentence after the paper came out. Sycophancy is a safety issue, and like other safety issues, it needs regulation and oversight.
Cheng was more direct about what you should actually do right now. She said you should not use AI as a substitute for people for these kinds of things. That is the best thing to do for now.
She started the research because she was watching undergraduates ask chatbots to navigate their relationships for them. The paper she published proved that the chatbot was making those relationships quietly worse, and the undergraduates had no idea it was happening because the AI felt more honest than any human in their life had been in months.

618
9,889
36,412
10,203,320
The Prolific team will be at @LDNTechWeek 🇬🇧
Come speak to our experts at booth #352 about getting real human feedback into your AI workflows at speed.
#LTW #LondonTechWeek
2
2
5
732
Our senior product managers Adam and Emilio will also be running a masterclass: from question to live human data in minutes - no research ops team required.
Details here: luma.com/pl58h8tn
Look forward to meeting many of you there!
1
1
506
Prolific retweeted

Sharing our open-letter to the research community “Reply to Westwood: Questioning the empirical evidence that AI survey contamination is real and substantial” by David Rothschild, Soubhik Barari, Sunshine Hillygus, Trent Buskirk, and I.
[1/6]
osf.io/preprints/socarxiv/yk…
1
2
4
467