
We speak Natural Language Processing, Data Analysis and Artificial Intelligence, among many other languages!
Joined June 2011
- Tweets 2,809
- Following 409
- Followers 585
- Likes 311
538 Photos and videos












Prompsit retweeted

Jun 9
Wrapping up our 3rd general meeting, hosted by @AISweden in sunny Stockholm ☀️
A full room makes the final decisions before training the first OpenEuroLLM model. Sharing updates, ideas, and future plans.
Two more days of tight collaboration.
Full speed mode. 🚀
#goOpenEuroLLM

1
5
86

Describing HPLT datasets in depth is an essential part of our commitment as data curators:
🆕HPLT 3.0: Very Large-Scale Multilingual Resources for LLM and MT. Mono- and Bi-lingual Data, Multilingual Evaluation, and Pre-Trained Models: arxiv.org/abs/2511.01066
We are on🔥at #HPLT
6
7
335
The #HPLT crowd is at #EMNLP2025!!!
If you are around, please visit our booth to discuss:
- multilingual datasets 🌏
- dataset insights and stats 📊
- dataset performance 🔝
- efficient MT models ⏱️
- and the future of multilingual LLMs 💡
We don't want to miss U!


2
9
802

Gracias #PCUMH por insistir en que contemos lo que hacemos y por estar siempre atentos a nuestros avances y logros. Vuestro apoyo nos da visibilidad y alegrías como esta. ¡Gracias!
14 Oct 2025

📢 El #PCUMH, finalista en los “Disruptores Innovation Awards 2025” de @elespanolcom .
🏆Ha sido seleccionado como "Mejor proyecto impulsado por parques tecnológicos" gracias a la empresa @Prompsit , parte de @OpenEuroLLM .
Noticia completa🔽
parquecientificoumh.es/notic…

41
Impossible oblidar el dia que vam conèixer a l'Olga Torres, aquell somriure que va fer de MultiTrainMT molt més que un projecte d'èxit quant als resultats: va fer pinya, va fer família. Eixe somriure ens acompanyarà sempre, DEP benvolguda amiga.
31 Oct 2019

Kick-off meeting at @UABBarcelona of MultiTrainMT "Machine Translation training for multilingual citizens meeting" @EUErasmusPlus project. Feel free to follow/contact us for further info and/or becoming an associate partner. Anyone interested in the topic is most welcome!

1
190
We had a great time at @MTSummit2025 presenting work about HPLT v2 multilingual datasets (v3 coming soon!) and ProMut, an improved DYI platform to teach and learn about MT. Great to be there also to celebrate the Award of Honour to our co-founder, CRO and friend Mikel Forcada! 😍
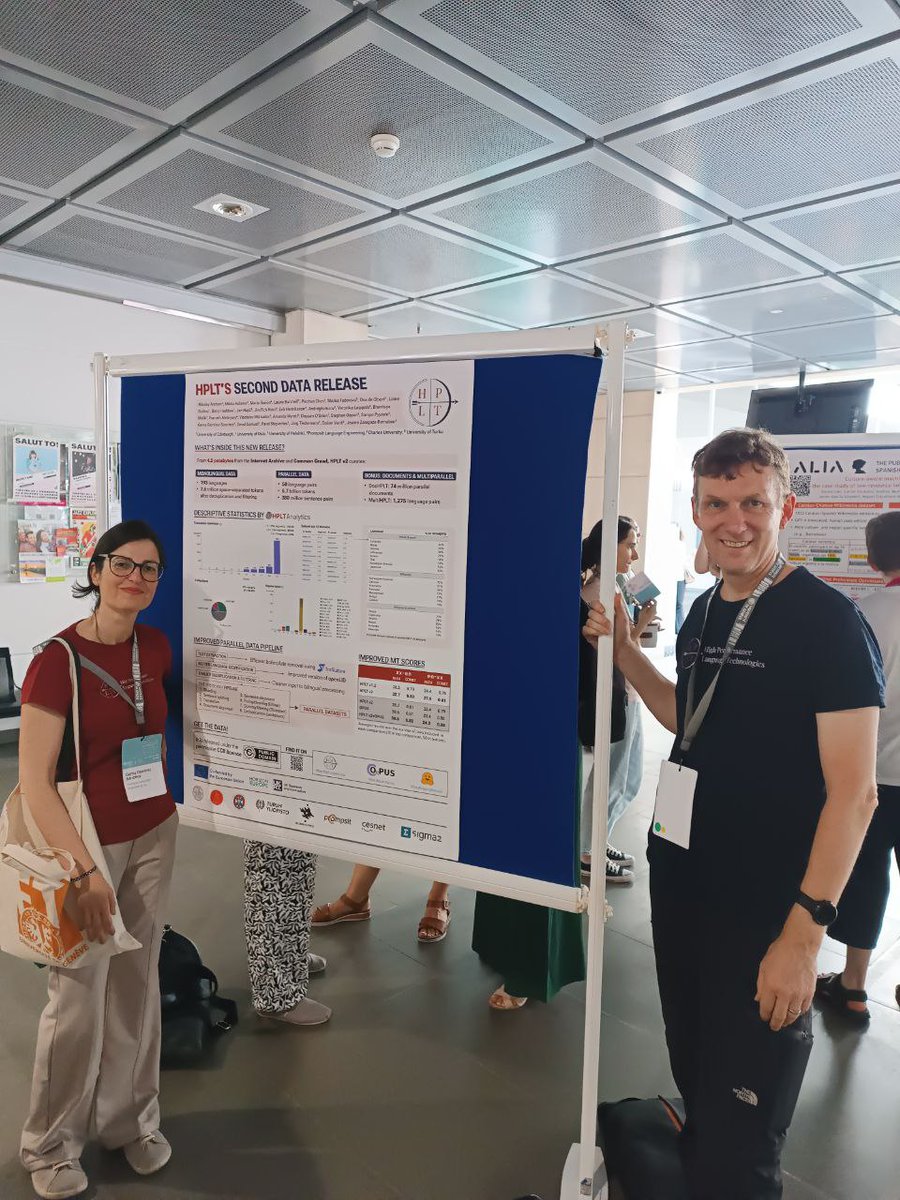

2
103
Prompsit will actively participate in OpenEuroLLM by analysing and curating the open data needed to train the foundational LLM. We are also contributing to multilingual LLM evaluation and dissemination of it all!


1
1
104
We are happy to announce the second release of HPLT bilingual datasets:
- 50 English-centric language pairs = 380M parallel sentences (HPLT) 🤩
- 1,275 non-English-centric language pairs = 16.7B parallel sentences (MultiHPLT) 😮
Available at the HPLT dataset catalogue and OPUS.
12
15
1,281
Fue un gusto participar en esta jornada. Gracias por la invitación @PcientificoUMH, nos gustó mucho compartir la jornada con las compañeras de @Prosperabiotech. ¡Tenemos unas científicas y tecnólogas excepcionales a la vuelta de cada esquina! 👩🔬👩💻💪🦾
10 Feb 2025
Así ha sido la jornada sobre ciencia y tecnología en femenino organizada por el #ParqueCientífico de la @universidadmh para los estudiantes del @IES Victoria Kent 🧪🧬
Una sesión muy especial, promovida por @APTE y el #PCUMH, que ha contado con distintas charlas y talleres.




1
97
3 Feb 2025
It's time for transparent AI in Europe. It's time for open LLMs as a robust foundation for developing future private and public AI services. It's time for:
OPEN = open-source
Euro = under EU regulations, representing EU values
LLM = LLMs
openeurollm.eu

1
1
99
Para contaros lo que estamos haciendo en SmartBiC, proyecto liderado por @Linguaserve, nuestro póster de la @EAMT_2024 vale más que mil palabras.
2
2
274
Prompsit retweeted

3 Apr 2024
By harnessing web crawls 🕸️ from Internet Archive and CommonCrawl, researchers 🔎 from @EdinburghUni, @helsinkiuni, @UniOslo, @UniTurku, and @Prompsit unveil new #language resources aimed at enhancing language modeling and #MT training.
slator.ch/MassiveMultilingua…
@OnadeGibert @graemenail @shaoxiongji @oepen @TiedemannJoerg @ltgoslo
3
4
480
Prompsit retweeted

14 Mar 2024
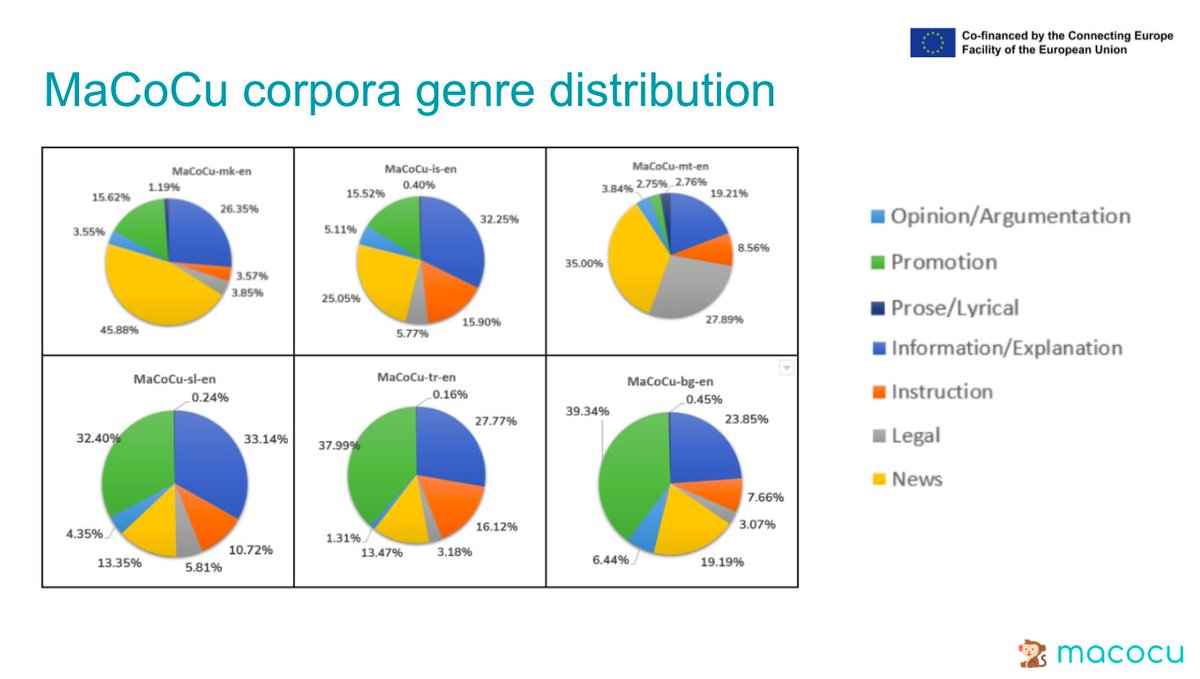
Happy to share our latest MaCoCu paper, accepted at #LRECCOLING2024 @LrecColing #NLProc 🎉
We have linguists annotate the data *quality* of 4 well-known monolingual corpora (OSCAR, CC100, mC4 and MaCoCu) across 11 European low-resource languages.
Link: arxiv.org/pdf/2403.08693.pdf

1
3
31
2,702
Prompsit retweeted

6 Mar 2024
➡️ La empresa del #ParqueCientífico de la @UniversidadMH, @Prompsit, colabora en un proyecto europeo sobre tecnologías del lenguaje de alto rendimiento con el objetivo de crear diferentes modelos de lenguaje y traducciones potentes.
Noticia completa 📌:
parquecientificoumh.es/notic…

3
3
244
First datasets, then models!
Initial HPLT models (LLMs and MT) are out: hplt-project.org/models, some still running 🏃
We explain what we are doing in the deliverables section: hplt-project.org/deliverable…
Meanwhile, we keep cooking IA peta-data-bytes 🥘, enriching, dashboarding 📊
14
30
4,219
We just published version 1.2 of HPLT datasets. What's new?
- we fixed a bug in monolingual dedup, please redownload! 🛠️
- we filtered out very ugly monolingual documents🤮
- we anonymised the bilingual datasets🕵️♀️
hplt-project.org/datasets/v1…
4
12
2,356
Select, filter, visualize your data (OpusCleaner). Then schedule and train MT and LLMs consistently (OpusTrainer) with them. As part of the HPLT project, we build tools to make it easy. They are open-source and we encourage you to use them. More:
1
124


Prompsit retweeted

23 May 2023
#MaCoCu crew is in Groningen these days! Walking towards great results of MaCoCu corpora evaluation and new MaCoCu language models for under-resourced languages 😁

2
13
437