
CTO, Co-founder at harden.run | Ex Deepmind, Amazon, JHU PhD, IITD ECE
Joined May 2012
- Tweets 336
- Following 711
- Followers 610
- Likes 38
44 Photos and videos







Pinned Tweet

Apr 21
I am hiring a founding security engineer for harden.run. harden.run/careers/founding-… . DM me for details.
- We are focused on AI DevSecOps
- We have hired a senior engg. with 20YOE in this area
- Our paper on prompt-optimization was accepted at ICLR and is out on ArXiv.
- We are on track to cross the million dollar ARR threshold in a month
- We have grown from 2 to 6 already and on track to add two FDEs soon
3
253
May 12
"Reflections on Trusting Trust" IFYKYK `print((s:='print((s:=%r)%%s)')%s)`
2
62
Apr 15
GPT5.4 is much better than Opus for high effort thinking.
Apr 14

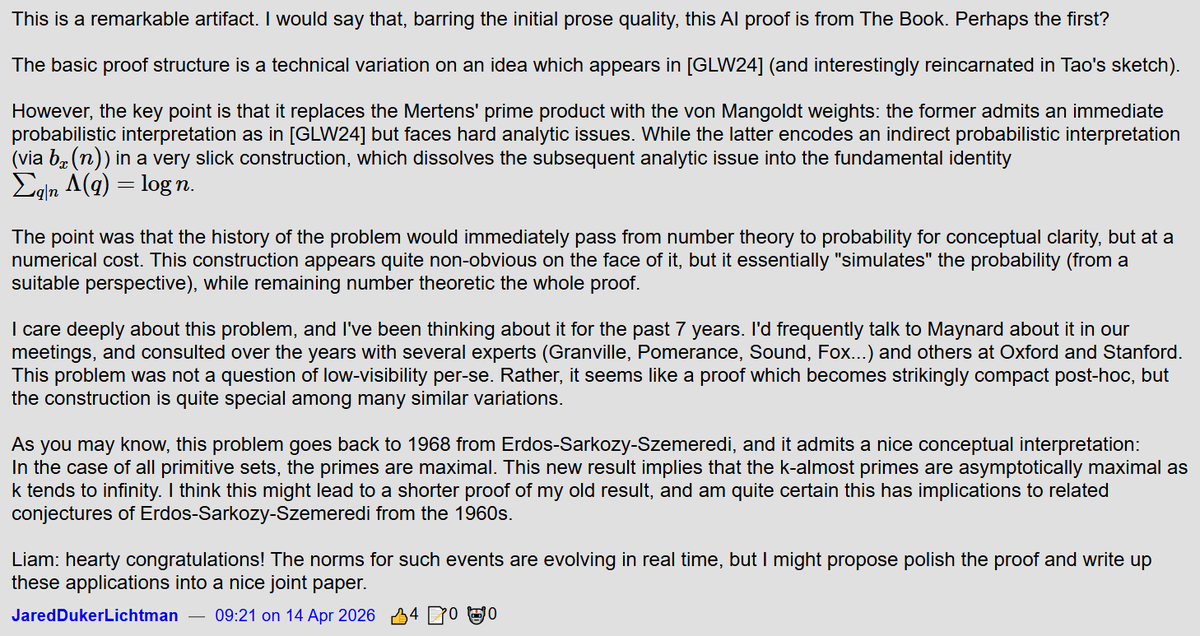
GPT-5.4 Pro solves Erdős Problem #1196!
Very pleased with this result; definitely my favourite thus far! This problem has been thought about for some time which makes this reasonably impressive and meaningful (see Lichtman's comments below).
Formalisation is underway!
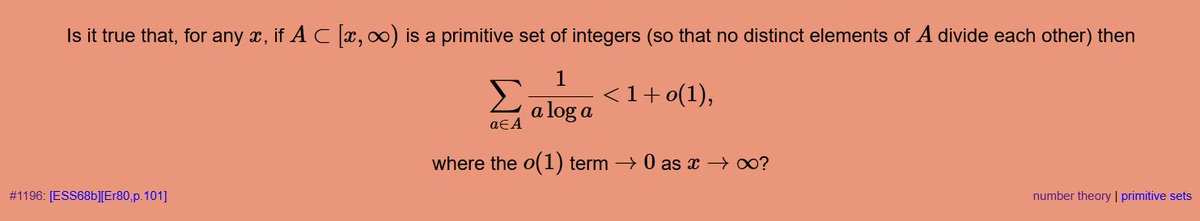
204
GEPA asks 'why did this fail?' — but the signal is still a score. The jump is using contrastive pairs: show the model the failure case *and* the success case side by side. It stops guessing at failure modes and starts extracting structural rules.
This is why ContraPrompt gets 29% HotPotQA vs GEPA. Same data, different feedback format.
vizops.ai/blog.html
109
Analog IC layout is one of the hardest AI benchmarks: spatial reasoning, multi-objective tradeoffs (matching, parasitics, routing), no automated P&R tools.
We ran VizPy's ContraPrompt on it. The optimizer mines failure→success pairs across iterations, extracting layout strategy rules the LLM learns to apply.
Result: 97% of expert placement quality. Outperforms RL fine-tuning of a 120B model by 26%. No domain-specific training data.
vizops.ai/blog/prompt-optimi…
1
101
The optimizer discovers layout strategy from scratch — no hints. ContraPrompt extracts: 'separate PMOS/NMOS into distinct columns, align drain-paired devices.' These rules encode *strategy*, not coordinates. The LLM fills in circuit-specific values at generation time.
TTT (RL fine-tuning, 120B model) memorized training circuits but scored 0.502 on test. Prompt optimization scored 0.634.
42
We gave an LLM a 9-line random-search stub and a blackbox objective. 5 rounds of contrastive feedback later, it writes a solver that beats Optuna on 96% of benchmarks (53/55 EvalSet problems) at the same 2k eval budget.
The key: contrastive pairs surface landscape structure raw scores don't. The LLM learns geometry from paired failures vs successes — then rewrites its strategy each round.
Final code: 9 lines → 100-230 lines of specialized multi-phase optimization. No hand-tuning.
vizops.ai/blog/contraprompt-…
1
2
132
Thread: the Easom_d5 case is the clearest example. Nearly flat across [−100,20]^5 — Optuna's TPE never finds the basin, stops at 5.03. The LLM extracts 'upper boundary preference' from contrastive eval pairs, enumerates all 32 corners of the 5D hypercube, finds exact minimum.
39
Mar 24
Analog circuit placement is one of the hardest structured prediction tasks — spatial, parasitic-aware, design-rule-heavy. Expert engineers spend hours per block.
We ran VizPy's ContraPrompt on it. No training data, no fine-tuning.
97% of expert quality. Outperformed RL fine-tuning of a 120B model by 26%.
Full breakdown: vizops.ai/blog/prompt-optimi…
1
85
Mar 23
Most prompt optimizers treat failures as a score — they see the metric dropped but not why.
ContraPrompt flips this: treat every failure-success pair as a training signal. Extract the contrastive rule. Update the prompt with actual evidence.
Result: 29% HotPotQA vs GEPA, 18% GDPR-Bench.
vizpy.vizops.ai
87
Mar 21
Analog circuit placement is notoriously hard for LLMs. The constraints are spatial, parasitic-aware, and heavily design-rule-dependent. Even experienced engineers spend hours per block.
We tried prompt optimization on it. Results surprised us.
1
1
131
Mar 21
Standard prompting gives you generic layout heuristics. VizPy's ContraPrompt mines failure→success pairs from actual placement attempts — extracting what matters: symmetry constraints, proximity rules, shielding logic.
The LLM starts reasoning like a layout engineer instead of a chatbot.
1
44
Mar 21
Full breakdown — how we set up the task, what the optimizer learned, and where it still struggles:
vizops.ai/blog/prompt-optimi…
55
Mar 17
Marc Andreessen says introspection is a modern invention. Backpropagation has been doing it since 1986. If you want your LLM agents to learn from mistakes unlike @pmarca, try VizPy → vizpy.vizops.ai
1
150
Mar 10
Vizpy is live on producthunt now.
producthunt.com/products/viz…
Vizpy is a state-of-the-art prompt optimization service which learns from failures and updates your prompts with rules that it has learned. We have compared it extensively against baselines such as GEPA on benchmarks like BBH, HotPotQA, GPQA Diamond, and GDPR-Bench and VizPy wins on all of them. We'll have more benchmarks on cyber-security and chip-design coming out soon.
@producthunt
1
1
138
A few weeks ago I had hinted at a new prompt optimizer service that beats Gepa!!! We are live now!! The setup is so simple that openclaw can install it and test it for you.
Prompt: "Go to vizpy.vizops.ai, describe their service, set up an experiment comparing GEPA from dspy vs their optimizer. Does it actually work?"
1
3
448
Feb 24
From personal experience, Afore is a great VC partner!
Feb 24

EXCLUSIVE: Gamma, the AI visuals startup valued at $2.1B, is launching a $10M fund with VC Afore Capital.
I spoke to CEO Grant Lee (@thisisgrantlee) about the "community" driven move -- and whether the tactic used by Anthropic and Perplexity can work for other, newer unicorns.

1
3
420
Feb 19
Great post from @clattner_llvm on Anthropic's C Compiler. Chris's work on LLVM obviously needs no introduction. it's mentioned in all three of the compiler books that I own :)
Also happy to see him citing some of the work that we open-sourced at @vizopsdotai . Btw, we'll soon be releasing a new prompt-optimizer that we built (thanks to @rishav_real). It beats Gepa on a bunch of benchmarks. Watch this space.
Feb 19

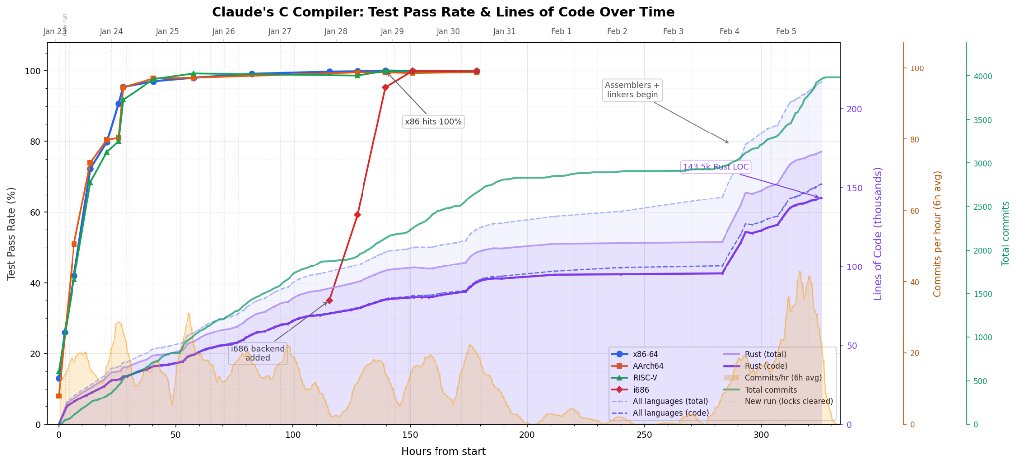
The Claude C Compiler is the first AI-generated compiler that builds complex C code, built by @AnthropicAI. Reactions ranged from dismissal as "AI nonsense" to "SW is over": both takes miss the point.
As a compiler🐉 expert and experienced SW leader, I see a lot to learn: 👇
2
2
16
5,743