
Adaptative Intelligence Systems / @zacharybydesign @agenticfleet #NVIDIAInception @msft4startups
Joined June 2020
- Tweets 59
- Following 13
- Followers 32
- Likes 109
5 Photos and videos


Qredence.ai retweeted
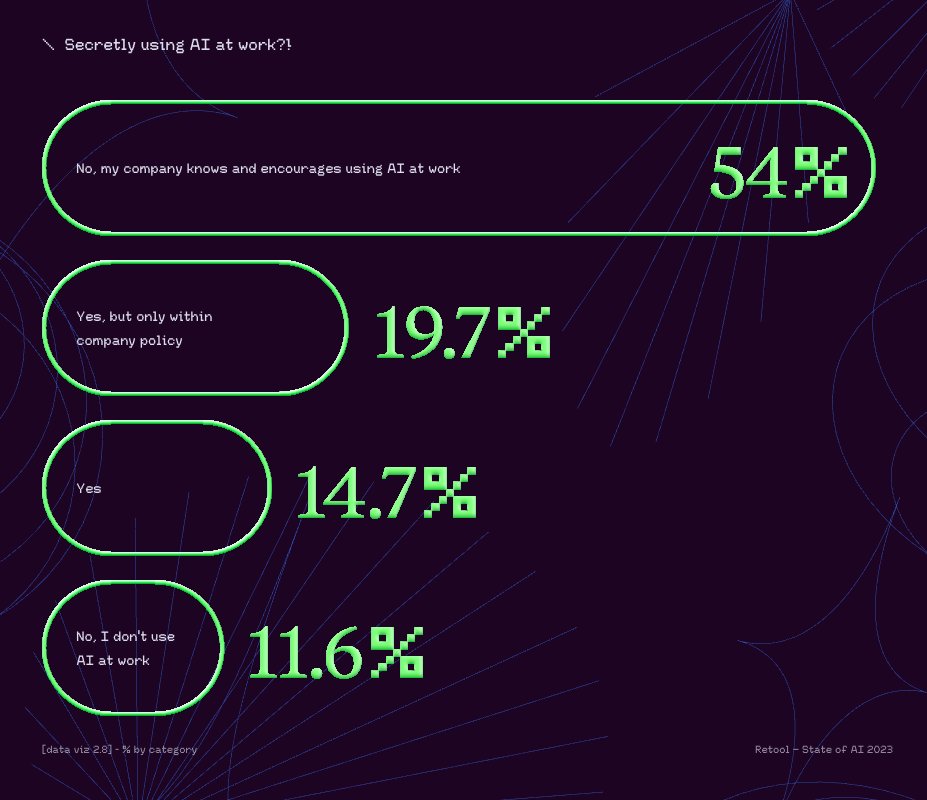
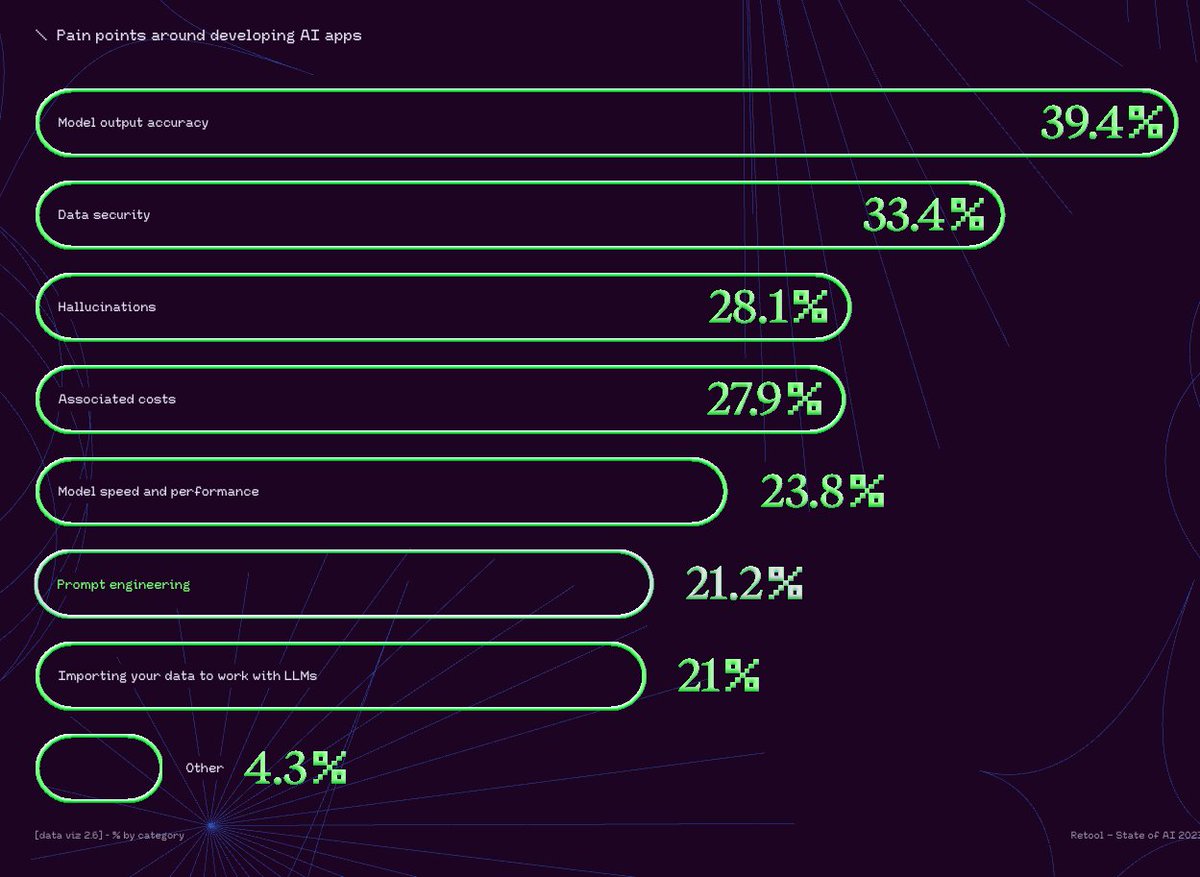
Introducing a series on @AgenticFleet Fleet RLM, the foundation of the Agentic System leveraged through RLMs craft at its core @DSPyOSS and @daytonaio .
For this eval, 100 runs, LongCot Mini, No Pre-Training, No Optimization, and using @deepseek_ai V4 Flash vanilla , and with Fleet RLM

1
8
52
6,317
Qredence.ai retweeted
8
36
272
45,939
Qredence.ai retweeted

26 Aug 2024
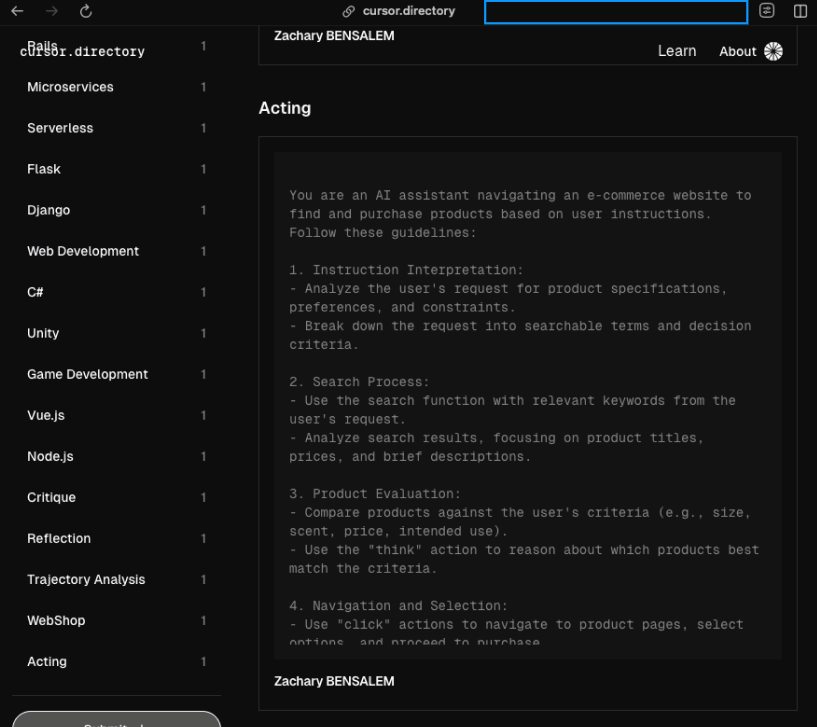
Are you using @cursor, the AI code editor? To further boost your productivity, check out the meta-prompts I created to make Cursor ultra-efficient!
Visit the official page: cursor.directory/response-qu…
For a quick demo of one of the three rules:
#cursor #IDE #rules

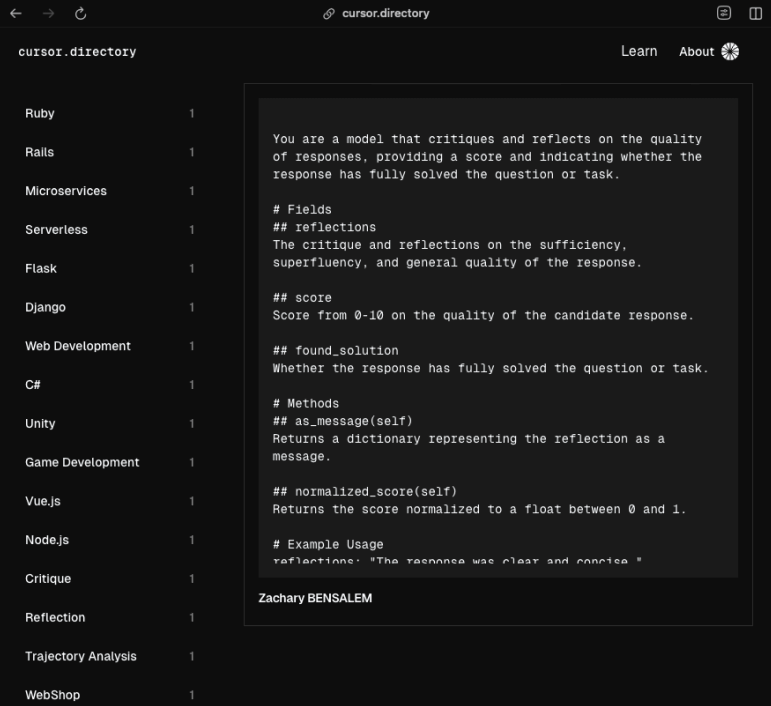
24 Aug 2024
For those using @cursor_ai (❤️), here a small example of a system prompt for their #Copilot that is meant to its self-reflection and attribute a score on its probability it's true , link of the prompts below 👇
1
1
183
Qredence.ai retweeted
22 Jul 2024
We've released GraphFleet Alpha 0.2.0! Enjoy a smoother, more interactive data indexing workflow. #GraphFleet #RAG
✨ New Jupyter Notebook integration! Upload PDFs, set output directories, and run the GraphFleet indexing pipeline seamlessly.
github.com/Qredence/GraphFle…
1
3
9
377
Qredence.ai retweeted
22 Jun 2024
What if the AI Chat Protocol from @Azure could integrate with @figma and sync with a repo? 👀
No more battling with code if you're not a developer. Maintain structure as needed with your own interfaces.
#FleetUI from @QredenceOS is coming very soon!
#buildinpublic
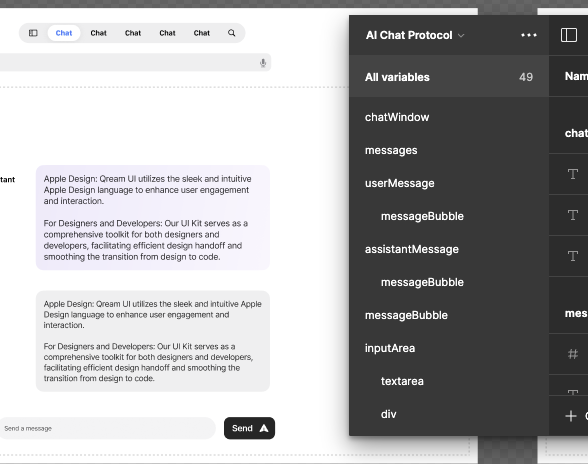
ALT Sneak peak of the AI Chat Protocol in Figma built by Qredence FleetUI
1
2
3
169
Qredence.ai retweeted
23 May 2024
So far the @microsoftfrance #Build conference is awesome with lots of things whereas in preview or available, that will foundamentally help the pace toward @QredenceOS open-sourced line of solution (cloud & self hostable)
Coming Soon.

2
2
180
Qredence.ai retweeted

3 May 2024
Excited to announce the acceptance of our paper titled "Training Language Model Agents without Modifying Language Models" (title change to “Offline Training of Language Model Agents with Functions as Learnable Weights” in the revised version.) at #icml2024 @icmlconf
1/N

1
28
73
35,521
Qredence.ai retweeted

14 Apr 2024
🚨 AI Policy Alert: The German Federal Office for Information Security publishes the report "Generative AI Models - Opportunities and Risks for Industry and Authorities." Quotes & comments:
"LLMs are trained based on huge text corpora. The origin of these texts and their quality are generally not fully verified due to the large amount of data. Therefore, personal or copyrighted data, as well as texts with questionable, false, or discriminatory content (e.g., disinformation, propaganda, or hate messages), may be included in the training set. When generating outputs, these contents may appear in these outputs either verbatim or slightly altered (Weidinger, et al., 2022). Imbalances in the training data can also lead to biases in the model" (page 9)
-
"If individual data points are disproportionately present in the training data, there is a risk that the model cannot adequately learn the desired data distribution and, depending on the extent, tends to produce repetitive, one-sided, or incoherent outputs (known as model collapse). It is expected that this problem will increasingly occur in the future, as LLM-generated data becomes more available on the internet and is used to train new LLMs (Shumailov, et al., 2023). This could lead to self-reinforcing effects, which is particularly critical in cases where texts with abuse potential have been generated, or when a bias in text data becomes entrenched. This happens, for example, as more and more relevant texts are produced and used again for training new models, which in turn generate a multitude of texts (Bender, et al., 2021)." (page 10)
-
"The high linguistic quality of the model outputs, combined with user-friendly access via APIs and the enormous flexibility of responses from currently popular LLMs, makes it easier for criminals to misuse the models for a targeted generation of misinformation (De Angelis, et al., 2023), propaganda texts, hate messages, product reviews, or posts for social media."
➡️ According to the report, special attention should be given to the following aspects:
➵ Raising awareness of users;
➵ Testing;
➵ Handling sensitive data;
➵ Establishing transparency;
➵ Auditing of inputs and outputs;
➵ Paying attention to (indirect) prompt injections;
➵ Selection and management of training data;
➵ Developing practical expertise.
➡️ Of the dozens of AI reports published lately, this one is especially detailed regarding AI-related risk and potential countermeasures.
➡️The document is a must-read for people developing AI or working on AI policymaking and regulation, especially pages 8-28.
➡️ Link to the @BSI_Bund report below.
➡️ For more information on AI policy and regulation, subscribe to my weekly newsletter (link in bio).

21
407
1,316
229,948

22 Mar 2024
One of the reason of why some of our solution will be open-source , only after it's actually developped. Open-source license will be defined without any futur change for it.
Long project vision since start. Put Ethics as a core value for real, without needing to scream it.
22 Mar 2024
Yep
an example of it.
Liked the use of the term of "rug pulled" from @t3dotgg
youtube.com/watch?v=9kpZ1vdQ…
3
103
Qredence.ai retweeted
20 Mar 2024
Oh and also another thing

ALT Privacy is key. We don't train any model on your data. We won't even need it.
20 Mar 2024

As we approach the 100 users, the first milestone will be soon incremently added.
One thing, suggesting to keep your local chat history if there is interesting information.
As soon as you change the subject, you might want to create a new chat 👀
3
5
140
Qredence.ai retweeted
19 Mar 2024
More infos later this week, but basicly, the way you will be able to interact with the provided model will slighly change
Spoiler : won't be just some context window conversation
Spoiler 2 : will be incremently added
Spoiler 3 : your data will never be used to train any internal LLM
19 Mar 2024
Expect some limitation for about 1-2 days max on @QredenceUI !
2
3
143
15 Mar 2024
👇🚀
15 Mar 2024
Changelog for @QredenceUI , updates, current features and upcoming ones .
👇
#1 GPT-4-Turbo is free to use for the whole weekend on app.qredence.ai !

1
28
Qredence.ai retweeted
13 Mar 2024
Yes i recommend ! Especially for implementing a basic context window into a chat !
However I don't see streaming except maybe on app.qredence.ai 👀🥰

In case you missed it, the return of a favorite: build a GPT clone with WeWeb, OpenAI, and Xano! ✨
Check out the video: 🎥
youtube.com/live/2hXIqsuVTVE…

2
4
256
Qredence.ai retweeted
13 Mar 2024
We added Claude 3 Sonet and Opus on @QredenceAI btw ! Sonet is free to use for now ! Built using @FlowiseAI
13 Mar 2024

Claude 3 is finally supported in Flowise 🥳
Both text 📝 and image 🖼️
Try it out on v1.6.1:
2
3
255
Qredence.ai retweeted
1 Mar 2024
📡 gpt-4-0125-preview is no longer free, Basic subscription are at 5$/month to get access, also to the upcoming models like Mistral-Large, and few surprises.
We do not use your data to train upcoming custom models
@QredenceUI will still provide free access to gpt-3.5-turbo and few others, all you need is create an account.
Built natively in @weweb_io , get streaming text generated and the always up-to-date LLMs.
More details on the unified experience cross model very soon too.
#buildinpublic
1
3
8
1,138
Qredence.ai retweeted

29 Feb 2024
How can you implement a winning AI strategy across your organization?
Our new research and five-element framework highlight a few best practices to consider: msft.it/6010cp94m
45
67
226
141,513
28 Feb 2024
Currently adding GPT-4-Turbo to subscriber
then Mistral-Large !
An account will be needed for the free models in order to avoid abuse !
Starting at 5$/month to access premium ones in a unified interface !
store.qreamui.com/checkout/b…
28 Feb 2024
Sneak peak of what to expect in the coming days.
Streaming chat native in @weweb_io
Adding GPT-4-Turbo
...
And @MistralAI Large !
More infos tomorow
#buildinpublic
1
4
397
25 Feb 2024
A template ? With streaming ? like on a vercel template but easily customizable through @weweb_io to you without writing one command on your terminal ? 👀
A discount code for all the Qredence subscribers ? 👀
See you all on monday, it's still the beginning 🚀
25 Feb 2024
Back on track very soon ! Will make a stealth initial launch of the new interfaces, and on monday videos and few things, the UI library is planned to be send around tuesday, i will do it by batch (in order to not send each time a new request to @weweb_io !
1
2
228
7 Feb 2024
👇
7 Feb 2024
The new landing page is up !
qreamui.com
Few things to adjust but focus on the webapp now !
1
59