
QuestDB (YC S20) is the fastest open source time series database. github.com/questdb/questdb
- Tweets 2,456
- Following 266
- Followers 2,305
- Likes 751















ALT QuestDB banner introducing the new array_agg() SQL function. Headline reads "Many rows in, one array out." with the code snippet array_agg(price) → DOUBLE[]. A diagram shows a column of price values (1.1922, 1.1928, 1.1925, 1.1927, 1.1926, 1.1924, 1.1929) converging into a single DOUBLE[] array, labeled "1 array, order preserved."
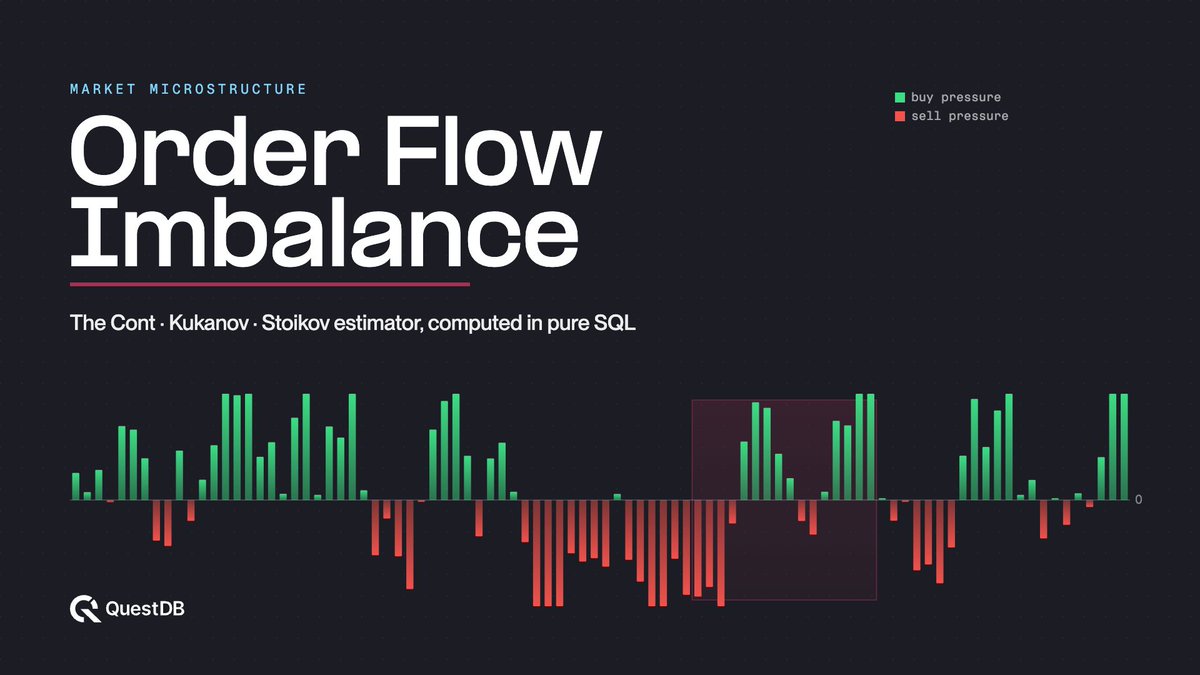
ALT A wide dark-navy data-visualization banner. Headline reads "Order Flow Imbalance" with the subtitle "The Cont · Kukanov · Stoikov estimator, computed in pure SQL." Below, a time series of order-flow imbalance is drawn as a diverging bar chart around a zero baseline: green bars pointing up indicate net buy pressure and red bars pointing down indicate net sell pressure. A translucent highlighted window frames one contiguous slice of the series. A legend labels green as "buy pressure" and red as "sell pressure," and the QuestDB logo sits in the lower-left corner.
ALT QuestDB banner titled "SQL extensions for time-series." Subtitle: "Some operations are verbose, others are hard to optimize, and some patterns do not map cleanly to relational semantics. QuestDB extends SQL where time-series workloads need different primitives." On the right, six numbered feature cards in a 2×3 grid name the extensions: 01 LATEST ON, 02 SAMPLE BY, 03 Time-aware joins, 04 Designated timestamps, 05 Temporal filtering, 06 Order books as arrays.
ALT QuestDB banner titled "Out-of-order data, handled by design." A process pill reads "WAL → SPLIT → SQUASH". To the right, three stacked timelines tell the story: (1) nine timestamp chips in WAL arrival order, with two chips marked "late" highlighted in pink because their timestamps came earlier than the chips before them; (2) the same chips re-sorted chronologically, with pink dashed seams dividing the partition into three sub-partitions and the middle segment labeled "split insert"; (3) a single solid pink bar labeled "one ordered partition · 9 rows", showing the consolidated result after the background squash.
ALT QuestDB banner titled "Exactly once, by upsert key." A SQL snippet reads DEDUP UPSERT KEYS(ts, symbol). To the right, a small diagram shows six incoming WAL rows on the left collapsing into four stored rows on the right. Two pairs of incoming rows share the same timestamp and symbol — they're highlighted in pink and bracketed with a "key match" label, with the older value struck through. Curved arrows fold each duplicate group into a single canonical row in the deduped output column. A counter at the bottom reads "6 rows in" → "4 rows stored."
ALT Diagram explaining QuestDB covering indexes and covering sidecars for high-cardinality SYMBOL queries. The top section shows rows stored in timestamp arrival order, where values for the same symbol are scattered across the column file, requiring many random reads for queries like WHERE sym = 'AAPL'. The lower section shows the new covering sidecar layout, where rows for each symbol are physically grouped contiguously, allowing sequential reads over compressed per-key blocks. Additional panels show the compression strategies used for different data types, including ALP for floating point values, FoR bit-packing for integers, linear prediction plus FoR for timestamps, and FSST compression for text.
ALT QuestDB banner: "Parquet partitions, from day one." A SQL snippet reads PARTITION BY DAY FORMAT PARQUET. On the right, a timeline of daily partitions shows three older partitions in the native row-oriented format (Dec 02–04) followed by a pink "Format → Parquet" boundary, then five future partitions written as Parquet with column stripes (Dec 05–09). Existing partitions are retained; future ones are written as Parquet from inception.