
Tech news and ICT updates brought to you by specialists at the RMIT University's School of Computing Technologies, based in Melbourne, Australia.
Joined December 2009
- Tweets 70,559
- Following 5,571
- Followers 7,371
- Likes 4,282
2,049 Photos and videos
















RMIT School of Computing Technologies retweeted

17 Dec 2024
"Two Heads Are Better Than One: Improving Search Effectiveness Through LLM Generated Query Variants", short paper accepted #chiir2025. Led by our Masters student @rankun203 with @Marwah_k @IR_oldie @damiano10. Awesome result Kun! @AdmsCentre @RMITComputing @ACM_CHIIR
1
7
30
1,514
RMIT School of Computing Technologies retweeted
12 Dec 2024
Many congratulations @Marwah_k, awesome work! @AdmsCentre @RMITComputing



2
3
22
1,331
RMIT School of Computing Technologies retweeted
11 Dec 2024
Loved this #sigirap2024 talk from @841io. Often wondered if alternatives to the arithmetic mean were worth using, I got my positive answer in this talk.

2
14
682
RMIT School of Computing Technologies retweeted

12 Dec 2024
Slides of the talk I gave at the @ACMSIGIR_AP #sigirap2024 #naarm #melbourne satellite on decolonising IR research: damianospina.com/talk/202412…
I wished we had more time for a discussion, but it was great to see Katya Khramtsova acknowledging Country at the start of her talk today.
2
3
15
613

"Can Users Detect Biases or Factual Errors in Generated Responses in Conversational Information-Seeking?" presented by @weronika_laj w/@damiano10 @krisztianbalog and @JTrippas at #SIGIRAP2024 🇯🇵
🔗doi.acm.org?doi=3673791.3698…,
#convsearch #sigirap24

1
3
21
620
RMIT School of Computing Technologies retweeted
22 Nov 2024
"Metamorphic Evaluation of ChatGPT as a Recommender System" a cool short paper from an @RMITComputing student, Madhurima Khirbat, showing how superficial changes in prompts can result in substantial change in #gpt #recsys style output @AdmsCentre arxiv.org/abs/2411.12121
2
9
519
RMIT School of Computing Technologies retweeted

10 Dec 2024
We've kicked off the #SIGIRAP2024 Satellite event at @RMITComputing in Melbourne with a great keynote by @peter_r_bailey from #canva.
Moving on to the hybrid talks in Tokyo.
In the photos a taste of the talks and @damiano10 acknowledging Country with Indigenous artwork on IR



1
6
15
674
Next up, @Marwah_k on fooling #LLMs
W/@pt_ir Falk Scholer and @IR_oldie.
#sigirap2024
@RMIT @RMITComputing

3
27
3,501

Many congratulations, Dr @BlinovaValeriia and supervisors! 👩🏼🎓


1
238
RMIT School of Computing Technologies retweeted
8 Nov 2024
Great job @SachinPC10 presenting at the @AcmIcmi #icmi2024 conference in the amazing Costa Rica 🦜
This collaboration with @UjLaw and @TUDelft_AI started with Ujwal’s visit to @AdmsCentre followed by Sachin’s research stay in Delft as part of my @arc_gov_au DECRA
@RMITComputing
8 Nov 2024

Was an amazing experience presenting our🥉#BlueSky paper. Thank you everyone, for the inspiring questions and new ideas on #multimodal approaches to tackle #misinformation in #podcasts.
@UjLaw @damiano10
Thank you, Organizers and CCC for the Award 🏆.
#icmi2024

ALT Everything We Hear: Towards Tackling Misinformation in Podcasts
2
4
376
RMIT School of Computing Technologies retweeted
7 Nov 2024
Many congratulations to @BlinovaValeriia who has (subject to the usual corrections) passed her PhD. Valeriia won best paper awards at CIKM and SIGIR and working with an @RMITComputing undergratuate student she published a full paper at ACL. Incredible work Valeriia!
1
2
23
722
RMIT School of Computing Technologies retweeted
6 Nov 2024
The program for @ACMSIGIR_AP is up, sigir-ap.org/sigir-ap-2024/T…
6
10
936
RMIT School of Computing Technologies retweeted
1 Nov 2024
Inspiring talk from @cathal about his Life Logging research. Thank you for joining us @RMITComputing.

1
4
460
RMIT School of Computing Technologies retweeted
31 Oct 2024
Boo! 👻 *Deadline extension* for @ACM_CHIIR #CHIIR2025 short/demo/resource papers to Nov 4 (AoE).
DC papers extended to Nov 18!
chiir2025.github.io/
Meanwhile, EasyChair is dealing with Halloween maintenance for the next couple of days...🎃
28 Oct 2024

How are those #CHIIR2025 short/demo/resource/DC papers coming along? Still a few days left to submit (due Oct 31 AoE) chiir2025.github.io/cfp.html @ACM_CHIIR @ACMSIGIR 🪃🐨🦘
6
7
920
Many congratulations and very well deserved, @JTrippas ! 🌟
I've been 🌟 promoted 🌟 to Senior Vice-Chancellor's Research Fellow @RMIT!
This is a big milestone, and I'm grateful for all the support and guidance from everyone who helped me reach this point.
This news came after presenting my research @cikm2024!
@RMITComputing #RMIT

1
10
352
RMIT School of Computing Technologies retweeted
28 Oct 2024
How are those #CHIIR2025 short/demo/resource/DC papers coming along? Still a few days left to submit (due Oct 31 AoE) chiir2025.github.io/cfp.html @ACM_CHIIR @ACMSIGIR 🪃🐨🦘
2
5
1,265
RMIT School of Computing Technologies retweeted
26 Oct 2024
Sunny Saturday in Naarm/Melbourne, perfect day to celebrate the 505 citations so far in 2024 and to thank all my co-authors, students, mentors, and everyone who has engaged with our work! 🎉@RMITComputing @AdmsCentre
#AcademicChatter #AcademicTwitter #research
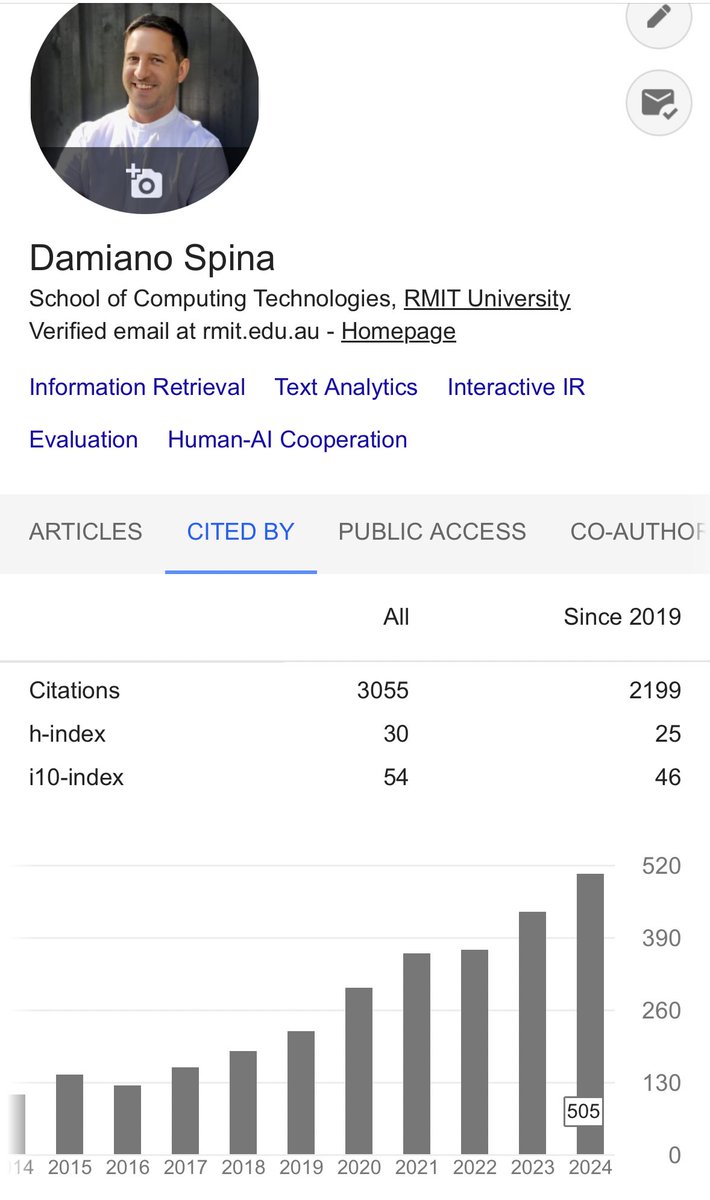
1
2
35
911
RMIT School of Computing Technologies retweeted

25 Oct 2024
Had a great time delivering my talk on empowering software developers to build privacy into applications at the #apidays conference in Melbourne! 🎤 Thanks to @apidays for the opportunity! @Rmitccsri @RMITComputing @RMIT #TechTalk #Innovation
12 Oct 2024

Learn how developers can build privacy-preserving software with @DrNalinAsanka at #apidaysAustralia. Safeguard your AI and APIs! 📅 Oct 16-17 | 🔗 apidays.global/australia #PrivacyTech #SoftwareDevelopment #CyberSecurity

ALT Empowering Software Developers to Build Privacy-Preserving Software Learn how developers can build privacy-preserving software with @DrNalinAsanka at #apidaysAustralia. Safeguard your AI and APIs! 📅 Oct 16-17 | 🔗 www.apidays.global/australia #PrivacyTech #SoftwareDevelopment #CyberSecurity
1
4
253
RMIT School of Computing Technologies retweeted
24 Oct 2024
The Baby Yoda paper is out. @Marwah_k tests the limits of LLM relevance assessment to find that all is not well with LLM QRELs. Some language models mistake query word overlap for relevance a little too often. marwahalaofi.com/files/alaof… @RMITComputing @AdmsCentre
24 Oct 2024
Will GPT-4 label this paper as relevant to the query "Baby Yoda"?
In this study with @IR_oldie, @pt_ir and F. Scholer, we found that despite good performance in aggregate, e.g. human-like measures of Cohen’s 𝜅 and Krippendorff’s 𝛼, competitive LLMs are likely to be influenced by the presence of query words in the labelled passages, even if those passages are constructed from random words. (1/6)

5
24
1,224
Ever wondered what people really ask conversational assistants? 🤖🗣️
I'll tell you in my #CIKM2024 presentation this afternoon!
Room: 120C
Time: Wednesday, 13:45 - 15:30
🔗doi.org/10.1145/3627673.3679…
Dataset github.com/JTrippas/CIRQL
@joelmmackenzie @RMITComputing @RMIT #ConvAI

4
22
851