
came for the bants, stayed for the rants
Joined July 2015
- Tweets 7,148
- Following 465
- Followers 73
- Likes 49,991
37 Photos and videos












RahulJo retweeted

Jun 12
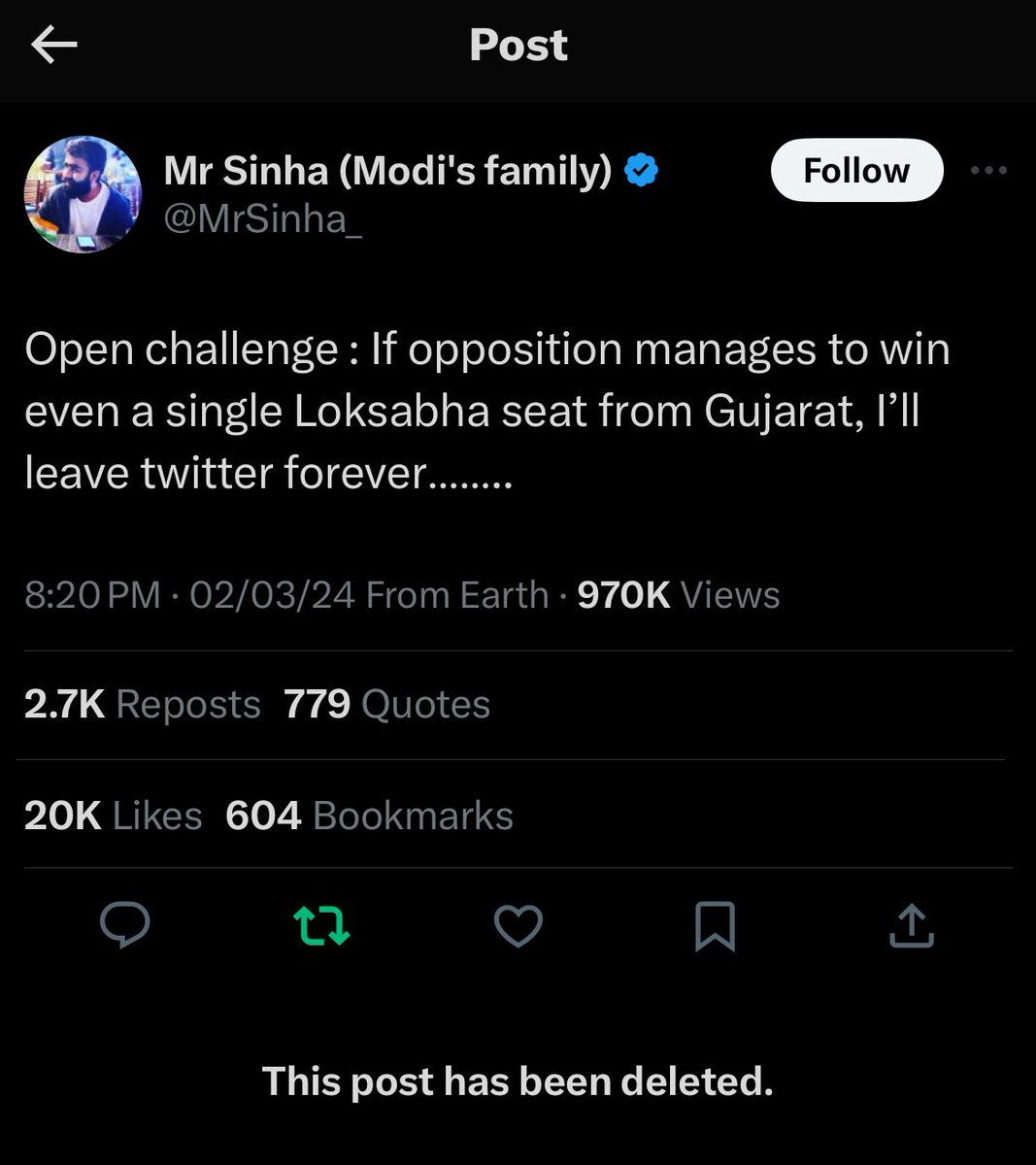
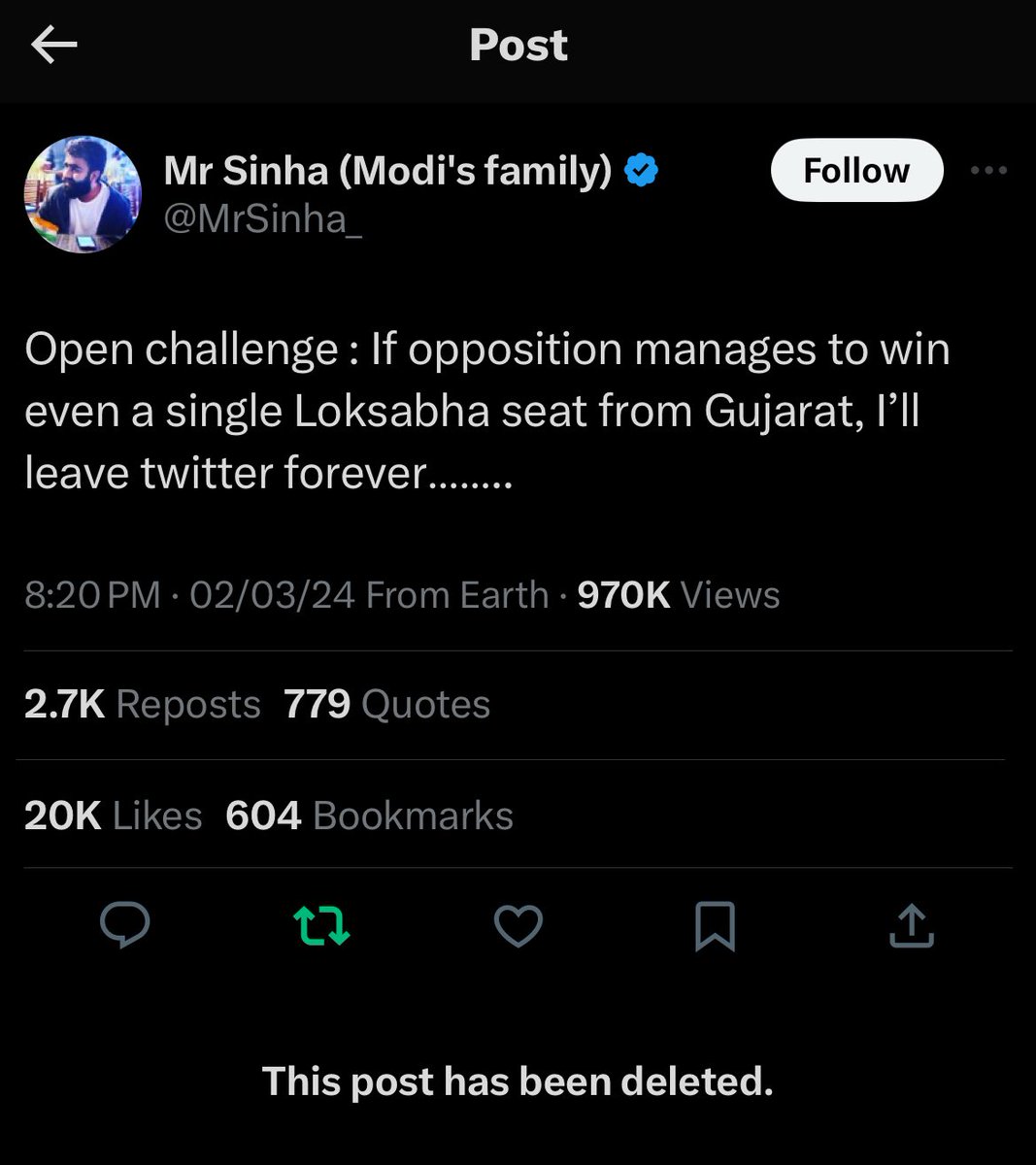
🚀 Introducing Gemini-SQL2, our breakthrough text-to-SQL capability powered by Gemini 3.1 Pro! We've achieved state-of-the-art results on the highly competitive BIRD benchmark, translating natural language into execution-ready SQL queries. 🧵👇

131
619
6,674
659,281

Watch @ElonMusk provide a technical update on SpaceX’s capability to manufacture, launch, and operate AI satellites at scale → spacexipo.com
1,412
3,151
18,135
25,224,055
RahulJo retweeted

May 26
Absolutely mind-blowing work. 🤯
This reminds me of when we were exploring the concept of 'thinking with visual primitives'. We noticed the model excelled in synthetic scenarios, but real-world generalization for complex tasks still faced bottlenecks. Back then, I kept thinking: "If only someone could provide manual annotations for these real-world scenarios..."
Using point-form visual primitives for reasoning would be powerful for tasks like state tracking, spatial topology, and logical testing, but they may heavily rely on high-fidelity, real-world labeled data. I think it’s the same across other domains too. The journey toward AGI cannot skip the hard, grounded work of human-labelled data. Massive respect to this effort! 🫡
May 23

You might not believe it, but I simply manually annotated over 2,000,000 human body parts with ultra-precise detail. Probably no one else could do that.

2
8
78
30,859
RahulJo retweeted

May 24
that deepfake of Michael Scott introducing @Karpathy to Dario and the Anthropic crew is the absolute best AI video I have seen so far
14
44
375
35,460
RahulJo retweeted

May 20
Monte Carlo Tree Search training corrects the model move by move, while current LLM training only tells it whether the whole trajectory worked.
MCTS is preferable if you can get it. But nobody's managed to get MCTS to work for language models.
In his blackboard lecture @ericjang11 talked to me about why:
29
94
1,112
183,829

RahulJo retweeted

Learning from rich textual feedback (errors, traces, partial reasoning) beats scalar reward alone for LLM optimization. GEPA demonstrated this for context-space optimization (prompts and agent harnesses), delivering frontier results at a fraction of the cost of RL.
But context-only optimization is bounded by the base model's capability ceiling; weight updates can reach further.
Very excited about this new line of work on Fast-Slow Training (FST), which interleaves context and model weight optimization!
The idea is a clean division of labor between two interleaved loops:
🔹 Fast loop (context): GEPA reads rich rollout feedback updating the context layer. The context becomes a fast-updating scratchpad of what the model needs to know about this task, right now.
🔹 Slow loop (model parameters): RL updates the model's parameters conditioned on the evolving context. Because the prompt already carries task-specific nuances, the model parameters are freed from absorbing them and focus on what actually generalizes across tasks and pushes the frontier.
⦁ 3× more sample-efficient than RL on math, code, and physics reasoning
⦁ ~70% lower KL divergence from base at matched accuracy
⦁ Plasticity preserved: FST checkpoints respond better to additional RL on new tasks than RL-only ones
⦁ Continual learning across changing tasks (HoVer → CodeIO → Physics) where RL stalls the moment the task switches
FST is a direction towards:
⦁ Addressing RL's pain points: entropy collapse, sparse rewards, long-horizon exploration
⦁ Providing a clean channel for rich feedback into weight updates
⦁ Demonstrating model-harness co-evolution
⦁ Discovery: Using fast context updates for broad exploration, while leveraging a continually improving model.
Check out the full thread below:
May 13

Can LLMs adapt continually without losing base skills?
Fast-Slow Training (FST) pairs "slow" weights with "fast" context.
FST vs. RL:
• 3x more sample-efficient
• Higher performance ceiling
• Less KL drift (better plasticity)
• Continual learning: succeeds where RL stalls

13
43
188
33,496
RahulJo retweeted

May 12
This is it.
Everything learned spending millions on longevity.
From: Your Immortal Unc and Auntie.
To: Our Immortal nieces and nephews.
0. Sleep is the world's most powerful drug.
1. Be in your bed for 8 hours
2. Same bedtime every night, any time before midnight
3. Don’t eat right before bed
4. Calm foods for dinner
5. No screens 1 hour before bed
6. Avoid added sugar (be aware it’s in everything)
7. Avoid all things in an American convenience store
8. Avoid fried foods
9. Shoes off at the door
10. Eat whole foods, particularly veggies fruits nuts legumes berries
11. Walk a little after meals or air squats
12. Get your heart rate high routinely
13. Lift heavy things
14. Stretch daily
15. Water pik, floss, brush, tongue scrape, morning and night
16. Make an effort to drink water
17. Get sunlight when you wake up (UV is low)
18. Protect skin in midday sun
19. Stand up straight
20. See at least one friend once a week
21. Avoid plastic where you can (in all things)
22. Circulate air in rooms
23. When stressed, breathe, learn to calm your body
24. Go to the dentist
25. Avoid sitting for long times
26. Protect your hearing, the world is too loud
27. Alcohol is bad for you
28. Finish coffee before noon
29. Avoid bright lights after sunset
30. If obese, look into a GLP
31. Sleep in a cold room
32. Texting while driving is dangerous
33. Turn off all notifications
34. Limit social media use
35. Don’t smoke anything
36. If you struggle to sleep, read a physical book before bed
37. 1 hour before bed have a calm wind down routine: bath, read, light walk, listen to music
38. The body is a clock and loves routine. Have a daily morning and evening schedule.
39. Avoid long distance travel where you can
40. Baby steps first: incorporate new things slowly
41. Do less… most things don’t work.
Bonus points if you get your blood checked.
Start here, it will change your life.
1,037
4,864
43,294
5,714,807

RahulJo retweeted

May 5
The day a blind man sees. The first thing he throws away is the stick that has helped him all his life
655
4,352
60,028
2,587,718
RahulJo retweeted

Feb 4
you can outsource your thinking
but you cannot outsource your understanding
283
4,188
18,510
2,867,097
RahulJo retweeted

Apr 23
Kimchi has been found to fine-tune immunity at the cellular level.
In a groundbreaking human clinical trial, researchers employed cutting-edge single-cell genetic analysis to explore kimchi's impact on the immune system. Over 12 weeks, overweight adults received either a placebo or powder from two varieties of kimchi. The findings show that kimchi not only enhances immune defenses but also promotes their regulation.
Scientists from the World Institute of Kimchi observed that participants consuming kimchi exhibited heightened activity in antigen-presenting cells (APCs), which play a key role in identifying pathogens such as bacteria and viruses. Simultaneously, CD4 T cells developed a more balanced profile, incorporating both effector cells for fighting threats and regulatory cells to prevent overreactions. This dual effect equips the immune system to mount effective responses while avoiding harmful inflammation.
The trial utilized single-cell RNA sequencing (scRNA-seq), a precise technique that examines gene expression in individual immune cells, uncovering nuanced changes undetectable by standard blood tests.
Fermentation method influenced outcomes: both spontaneous and starter-culture kimchi yielded benefits, but the starter version demonstrated superior effects, including enhanced antigen detection and reduced extraneous immune signaling.
This represents the world's first clinical demonstration of kimchi's immunomodulatory action at the genetic level, highlighting its promise for managing hyperactive immune conditions.
["Single-cell RNA sequencing reveals that kimchi dietary intervention modulates human antigen-presenting and CD4⁺ T cells." npj Science of Food, 2025]

40
247
1,416
100,501
RahulJo retweeted

Apr 23
This is a 1953 photo of two 4-year-old Australian boys playing in an asbestos sandpit.
At the time, very little was known about the devastating effects of asbestos, and people commonly used asbestos sandpits for their children to play in.
The boy on the left, Philip Noble, later grew up to become a footballer before dying of mesothelioma at 36.
The boy on the right, Ross Munroe, later became a high school principal and also died of mesothelioma at 38.

128
454
6,982
1,076,464
RahulJo retweeted

Apr 24
post-training/RL details of deepseek-v4:
i) they replace the mixed RL stage used in deepseek v3.2 with on-policy distillation. they still use RL but RL is mainly used to create strong domain specialists first. then they consolidate those specialists into one final model through OPD.
ii) for each domain they start with supervised fine-tuning on high-quality domain-specific data. after that they run RL using GRPO guided by domain-specific prompts and reward signals. the paper does not provide all reward formulas but the important structural point is that each specialist gets its own domain-conditioned reward distribution.
iii) deepseek-V4 supports three explicit reasoning modes: non-think, think high & think max. they trained distinct specialist models under different RL configurations to support different reasoning capacities. for each mode they apply different length penalties and context windows during RL training which changes the model’s output reasoning length.
iv) one of the more interesting parts is for hard-to-verify tasks they say they discard conventional scalar reward models and instead use a Generative Reward Model or GRM. they curate rubric-guided RL data and use a GRM to evaluate policy trajectories. crucially they apply RL optimization directly to the GRM itself and the actor network natively functions as the GRM (that means the same model family is learning both generation and evaluation...i guess this is closer to LLM-as-judge trained with RL...implicitly moving from reward-as-score to reward-as-deliberative-evaluation).
v) deepseek-v4 treats long-horizon tool use as a state-retention problem...instead of flushing reasoning after every user/tool boundary it preserves the full reasoning trace across agentic tool conversations, making context management part of the trained policy interface.
vi) also it collapses auxiliary routing decisions search/no-search, query generation, domain classification, URL reading, etc. into special tokens appended to the main model context...reusing the existing KV cache instead of paying redundant prefill for separate router/controller models.
vii) deepseek-v4 uses full-vocabulary logit distillation. that means instead of only comparing teacher and student on the sampled token they compare the full probability distribution over the vocabulary at each position.
viii) for agentic post-training and evaluation, deepseek builds DeepSeek Elastic Compute (DSec). it is a production-grade sandbox platform with three rust components: a) apiserver b) edge c) watcher...these communicate through custom RPC and scale over deepseek’s 3FS distributed filesystem...the paper says a single DSec cluster manages hundreds of thousands of concurrent sandbox instances...also for each sandbox DSec keeps a globally ordered trajectory log recording every command and result.
ix) the paper does not go in full details of async-rl...it focuses more on fault-tolerant asynchronous execution than on off-policy correction under stale rollouts (also on RL/OPD execution). it does not fully reveal the behavior-policy staleness semantics of the RL/OPD loop.
Apr 24

🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: huggingface.co/deepseek-ai/D…
🤗 Open Weights: huggingface.co/collections/d…
1/n

6
28
290
31,839


RahulJo retweeted

Apr 23
Thanks to the entire Claude community for giving feedback and continuing to build with us.
Read the full post-mortem here: anthropic.com/engineering/ap…
104
117
2,389
600,164
RahulJo retweeted

Apr 22
Every agent will need its own computer. And with new Hosted agents in Foundry, every agent gets its own dedicated enterprise-grade sandbox, with durable state, built-in identity and governance, and support for any harness or framework.
Read more:
devblogs.microsoft.com/found…

189
412
3,308
526,449
RahulJo retweeted

Apr 21
Columbia CS Prof Vishal Misra explains why LLMs can’t generate new science ideas.
Bcz LLMs learn a structured map, Bayesian manifold of known data & work well within it, but fail outside it.
True discovery requires creating new maps, which LLMs can't do
67
223
1,271
113,466
RahulJo retweeted

Apr 20
Meet Kimi K2.6 agent - Video hero section, WebGL shaders, real backends. From one prompt.
🔹 Video hero sections - cinematic aesthetic, auto-composited
🔹 WebGL shader animations - native GLSL / WGSL, liquid metal, caustics, raymarching
🔹 Motion design - GSAP Framer Motion
🔹 Backend database: Kimi wires up auth database backend in one pass.
🔹 Website stack - React 19 TypeScript Vite Tailwind shadcn/ui
🔹 3D w/ physically-based lighting - Three.js React Three Fiber
105
414
4,902
386,582
RahulJo retweeted
Apr 19
Demis Hassabis’s “Einstein test” for defining AGI:
Train a model on all human knowledge but cut it off at 1911, then see if it can independently discover general relativity (as Einstein did by 1915);
if yes, it’s AGI.
373
453
5,993
673,697