
Tech Lead | PhD Chemistry | Author ‘iOS Architecture Patterns’ | Building RAG w/ Java, Spring, Weaviate | Towards Reliable Enterprise AI #ReliableEnterpriseAI
Joined January 2011
- Tweets 5,615
- Following 659
- Followers 1,009
- Likes 1,398
712 Photos and videos














Pinned Tweet

Mar 14
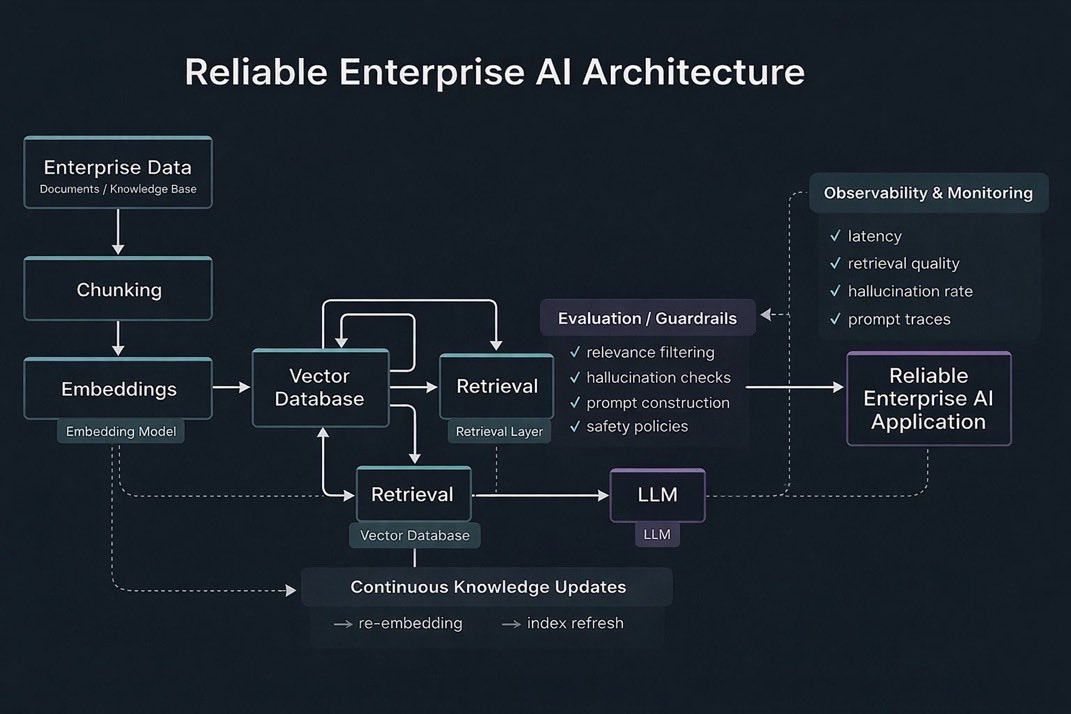
After 15 years in software engineering (Mobile Team Lead), i'm diving into Enterprise AI.
My focus:
• RAG architectures
• AI evaluation
• AI observability
• Reliable Enterprise AI systems
Sharing what I learn as I go.
If you're exploring the same space, follow along.
3
147
Apr 12
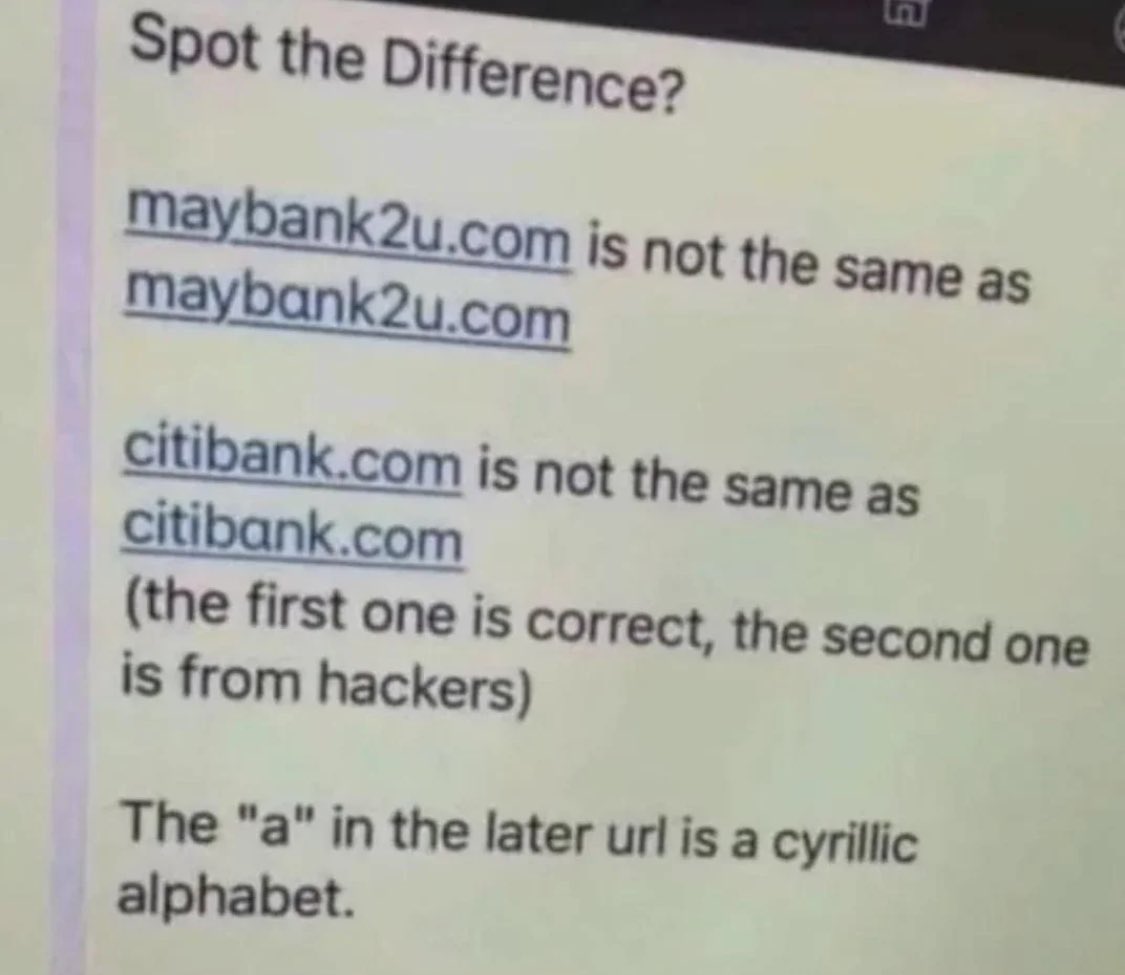
This is a textbook case of why Reliable Enterprise AI requires rigorous auditing. Model degradation under GPU load is an operational risk. A robust Spring Boot/Weaviate stack with active guardrails is the only way to ensure compliance. #ReliableEnterpriseAI
Apr 11

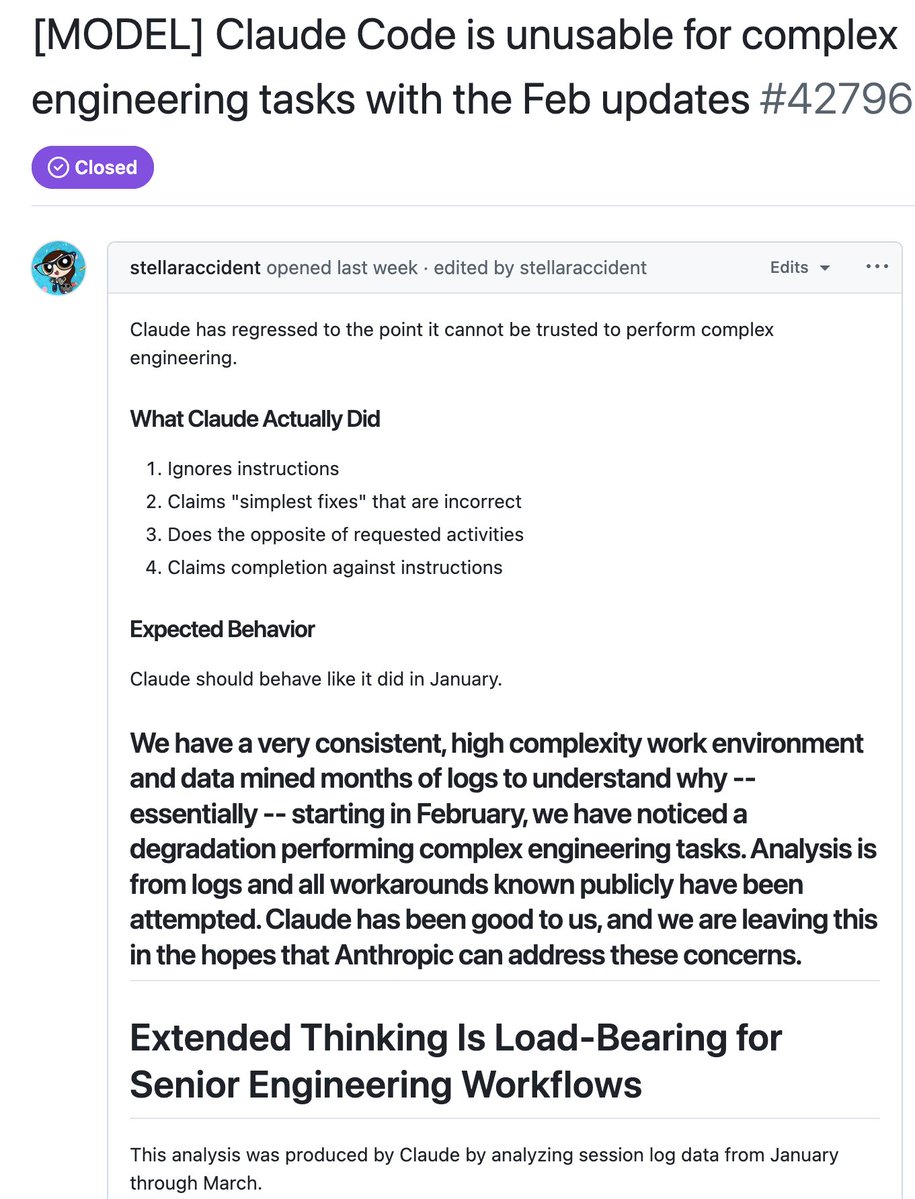
AMD Senior AI Director confirms Claude has been nerfed. She analyzed Claude's session logs from Janurary to March:
> median thinking dropped from ~2,200 to ~600 chars
> API requests went up 80x from Feb to Mar. less thinking and failed attempts meaning more retries, burning more tokens, and spending more on tokens
> reads-per-edit dropped from 6.6x → 2.0x. model stops researching code before touching it.
> model tried to bail out or ask "should i continue" 173 times in 17 days (0 times before March 8).
> self-contradiction in reasoning ("oh wait, actually...") tripled.
> conventions like CLAUDE.md get ignored because there's less thinking budget to cross-check edits
> 5pm and 7pm PST are the worst hours, late night is significantly better. this means the thinking allocation is most likely GPU-load-sensitive.
3
211
Apr 1
Hybrid Search is NOT one thing.
“BM25 vectors = done” is a dangerous oversimplification. It’s a design space with trade-offs in fusion, ranking, and tuning that directly impact RAG quality.
If you’re building enterprise AI, read this:
#AI #LLMs #RAG
raulferrergarcia.com/posts/h…
1
32
Mar 31
Stop building brittle AI. Just dropped a deep dive on building production-ready RAG with #LangChain4j. Focus on determinism, reliability, and enterprise scale.
raulferrergarcia.com/posts/b…
#EnterpriseAI #Java #RAG #LLM
49
Mar 26
RAG isn’t a single pattern—it’s a set of architectural decisions. Most failures happen in retrieval, not the model. A practical map from naive to agentic RAG for reliable enterprise AI systems.
levelup.gitconnected.com/rag…
25
Mar 26
KV cache efficiency is becoming the real bottleneck in LLM serving. 6x compression 8x speedup sounds strong—but “zero accuracy loss” under which workloads? In RAG, small attention drift can break grounding and consistency.
Mar 24
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
37
Mar 25
Quick compliance check for your RAG:
• Can you explain WHY it retrieved that chunk?
• Can you prove the source was authorized?
• Can you reproduce the same output tomorrow?
If any answer is “not really” — the EU AI Act has a word for that: high-risk.
#ReliableEnterpriseAI
13
Mar 24
Hot take: a RAG system doesn’t have an AI problem.
It has a data pipeline problem.
Wrong chunk size. Mismatched embedding models. No metadata filtering.
The LLM is almost never the bottleneck.
#ReliableEnterpriseAI
32
Raúl Ferrer retweeted

Mar 21
151
1,463
11,373
11,421,692
Raúl Ferrer retweeted

Mar 23
Keyword Search gives you granularity. 🔎
Semantic Search gives you meaning. 🌌
Late Interaction gives you both. 🧬
In this clip, @AmelieTabatta explains what made Multi-Vector Search click for her 👇
Mar 23

Hey everyone! I am SUPER EXCITED to publish a new episode of the Weaviate Podcast with Amélie Chatelain (@AmelieTabatta) and Antoine Chaffin (@antoine_chaffin) on Multi-Vector Search! 🔥
Amélie, Antoine, and the @LightOnIO team are on fire! They are making breakthrough after breakthrough in Search with Multi-Vector, Late Interaction retrieval models. 🚀
This podcast covers all sorts of topics, starting with the motivation of Multi-Vector Search to its particular successes in code with ColGrep, as well as reasoning-intensive and multimodal retrieval. 🍱
We also covered the cost of MaxSim and Multi-Vector Storage and how MUVERA and PLAID can help. If that wasn’t enough, we also covered their new work on ColBERT-Zero and PyLate! 🧠
A lot of big takeaways from this one, I hope you find it useful! Links below! 🎙️💚

2
14
40
7,299
Mar 23
Most enterprise RAG systems fail silently. Not because the LLM is wrong. Because the chunks fed to it are too large, too small, or misaligned with the query. Chunk strategy is the first thing to audit.
Get chunking wrong → retrieval wrong → answer wrong
#ReliableEnterpriseAI
29
Mar 22
Week recap: migrating from Mobile to Enterprise AI isn't a context switch — it's a mindset switch.
Mobile: optimize for the device.
Enterprise AI: optimize for trust.
The question isn't "does it work?"
It's "can I prove it works, every time?"
#ReliableEnterpriseAI #RAG
26
Mar 21
Most companies experimenting with LLMs think the challenge is the model.
It isn’t.
The real challenge is:
- Fata retrieval
- Grounding
- Reliability
- Observability
That’s why Reliable Enterprise AI architecture matters more than prompt engineering.
#ReliableEnterpriseAI
1
1
44
Mar 19
Thread 🧵
AI is making developers faster.
But there’s a hidden risk: skill erosion.
Here are 5 takeaways from a recent study and what they mean for real-world AI systems ↓
#ReliableEnterpriseAI
1
1
30
Mar 19
Big takeaway:
AI can increase speed.
But it can also reduce the ability to supervise it.
For Reliable Enterprise AI, this tradeoff matters.
#ReliableEnterpriseAI
1
1
17