
The Next Big Human Civilization.
Joined August 2025
- Tweets 11
- Following 2
- Followers 2
- Likes 24
3 Photos and videos
Pinned Tweet

Mar 27
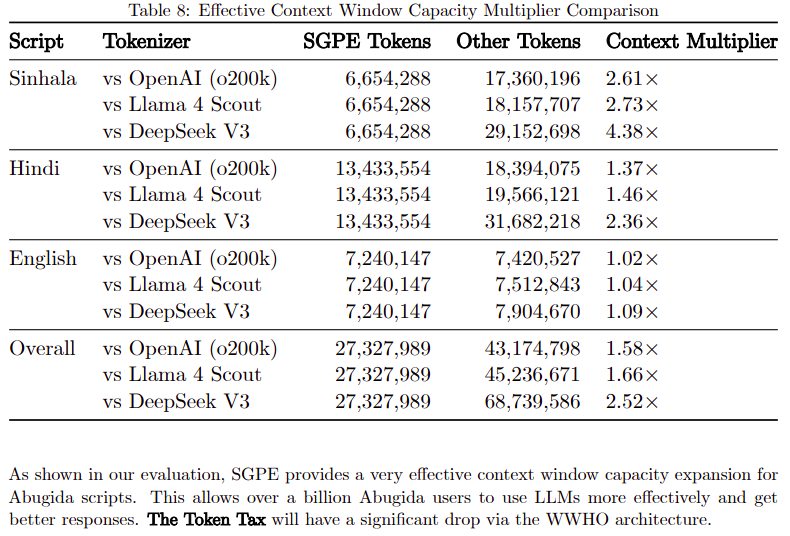
We measure every token because every token costs real capability.
On a 122-million-character multilingual evaluation set, Abugida scripts pay a structural penalty of 2.6–4.4× less effective context than English in frontier LLMs. Infrastructure debt, not a data problem.
#AI #WWHO
2
64
Mar 30
We invite Engineers, Developers, Researchers, and anyone willing to contribute to this cultural shift for the good of all humanity to join forces with us.
The project is fully open-source, and your contribution will help elevate human civilization to its next big stage.
#WWHO
Mar 30

The #WWHO tokenization architecture we built at @Remeinium will continue this shift toward AI. It will break most of the linguistic barriers that current LLMs are limited by, allowing everyone to chat with LLMs in their native language while receiving the same quality of responses as they would in English. Costs will be mostly the same for everyone.
Check it out on my profile, more updates are yet to come on this!
1
1
40
Remeinium retweeted

Mar 27
The fix is not “just add more vocabulary slots for Sinhala/Hindi or any Abugida script”
It is separating linguistic rules from statistical compression — before the model ever sees the tokens.
The architecture exists.
We are building it at @Remeinium so every language finally gets the same first-class treatment English already enjoys.
What’s the biggest multilingual bottleneck you’ve hit in practice?
#AI #LLM #Tokenization #NLP #WWHO
1
1
34
Mar 26
We are working on this @Remeinium. The novel tokenization architecture called WWHO, we have developed will solve this issue effectively.
We are exicted to launch it as soon as possible, and now it's at its final stage. Stay tuned for more updates.
Happy #AI for all!
#WWHO
Mar 26
Most people never see it, but frontier LLMs are quietly taxing over a billion users.
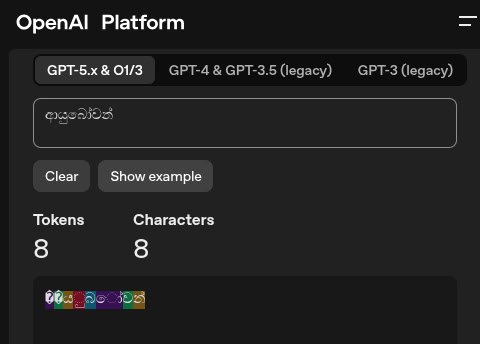
Take a single, everyday Sinhala word: ආයුබෝවන්
OpenAI’s o200k_base tokenizer turns it into 8 tokens for 8 characters.
That’s not compression. That’s fragmentation.
#AI #LLM #token @OpenAI
1
1
1
61
Remeinium retweeted
Feb 19
Can you imagine a day when everyone codes in their native language?
For the goal of AGI, we should train LLMs to respond to anyone in any language with the same quality and depth of knowledge.
Current LLMs perform ~2.5–4× worse for non-English users.
Why? Tokenizers. They consume the context window inefficiently for complex languages, resulting in 2–4× less content in responses.
To solve this, we are working on an architecture called #SGPE. If it succeeds, we can reduce this token tax by 40–60%, allowing LLMs to use the context window far more efficiently, especially for abugida scripts. Then we can move toward a universal tokenizer that serves everyone equally.
#LLM #Tokenization #token #tax #AI #NLP @Remeinium
24 Jan 2023

The hottest new programming language is English
1
1
2
374
Feb 17
SGPE (Syllable-aware Grapheme Pair Embedding) is coming and it will have a huge impact on tokenization.
#AI #LLM #Tokenization
2
39
Jan 4
We’re open-sourcing UgannA Siyabasa V2, our best Sinhala FastText embedding model
Built for research, products, and real-world NLP.
Released under the Remeinium Open Model License.
Sinhala deserves first-class language tech.
Access on Huggingface.
#AI #NLP #OpenSource
1
1
80
Jan 4
UgannA_SiyabasaV2
Model : huggingface.co/Remeinium/Uga…
Test Live : huggingface.co/spaces/Remein…
API : esdocs.ai.remeinium.com
1
17
19 Dec 2025
Silent is Over! #Codisor is coming before #AGI!
We are excited to share that we are preparing to launch Remeinium Codisor to help every student/developer UNDERSTAND any codebase fast.
Tired by Just-VibeCoding? Here you go to Understand the Unknown! 🧠
Happy UNDERSTANDING ✨
ALT Remeinium Codisor
1
36