
We advance the science of forecasting to improve decision-making on high stakes issues. Co-founded by chief scientist Philip Tetlock.
Joined May 2023
- Tweets 262
- Following 26
- Followers 3,511
- Likes 79
109 Photos and videos
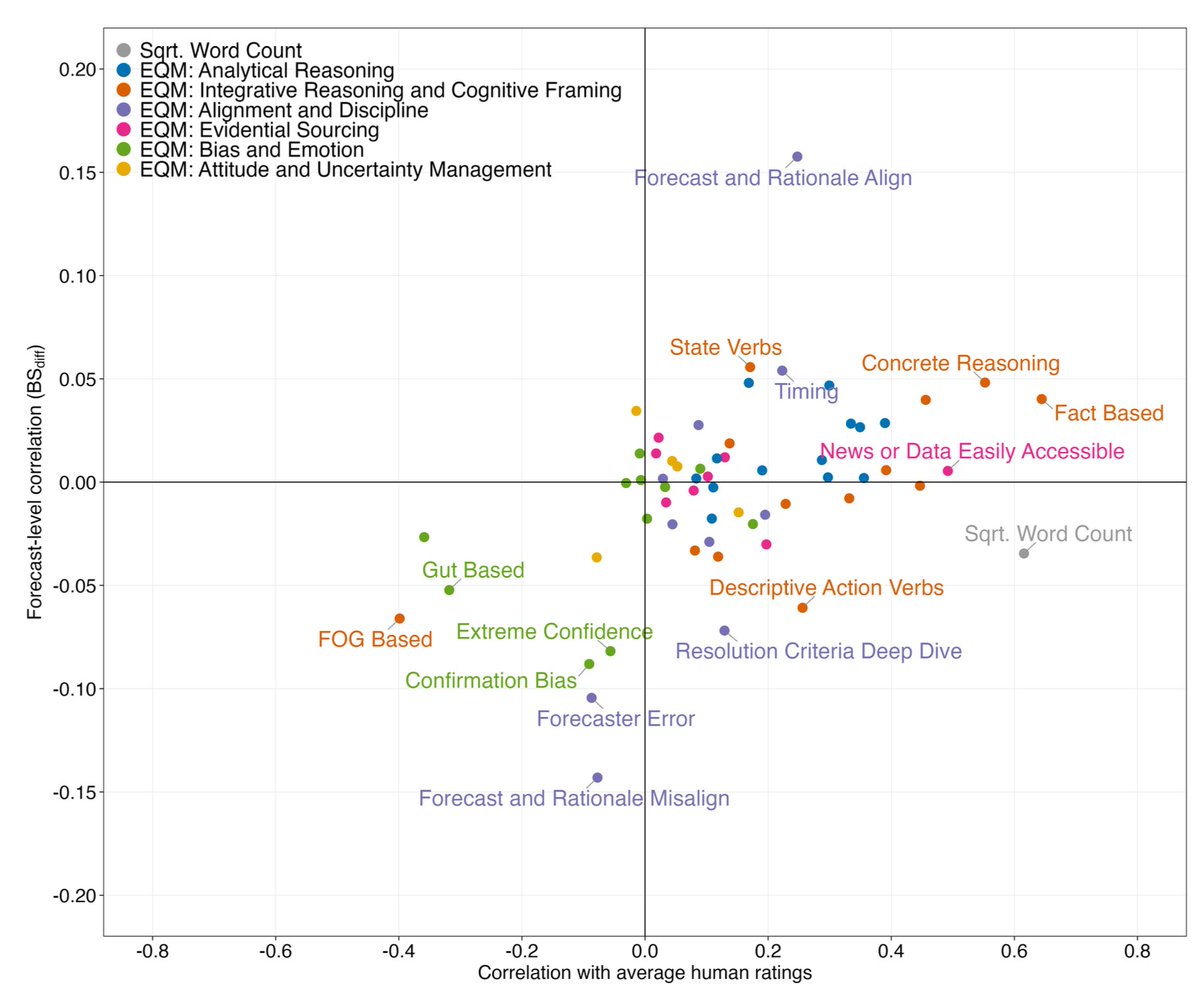
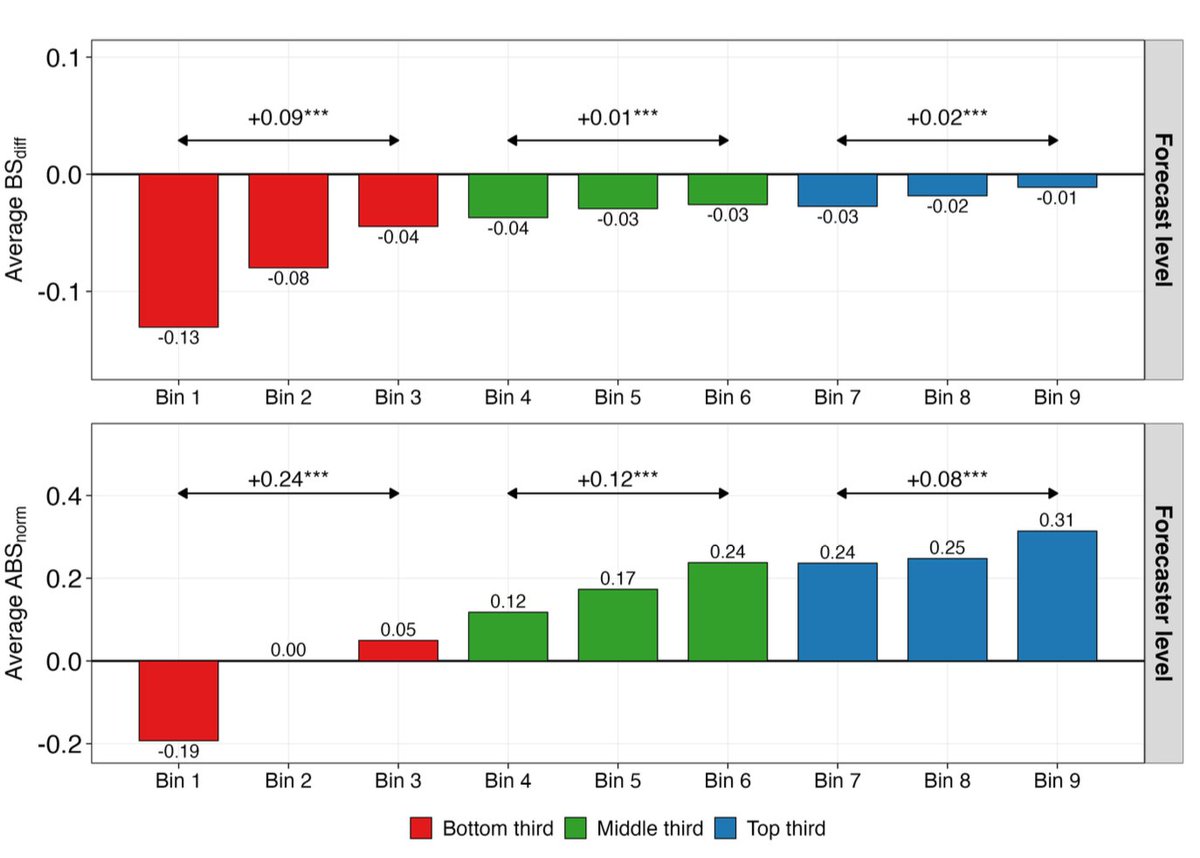
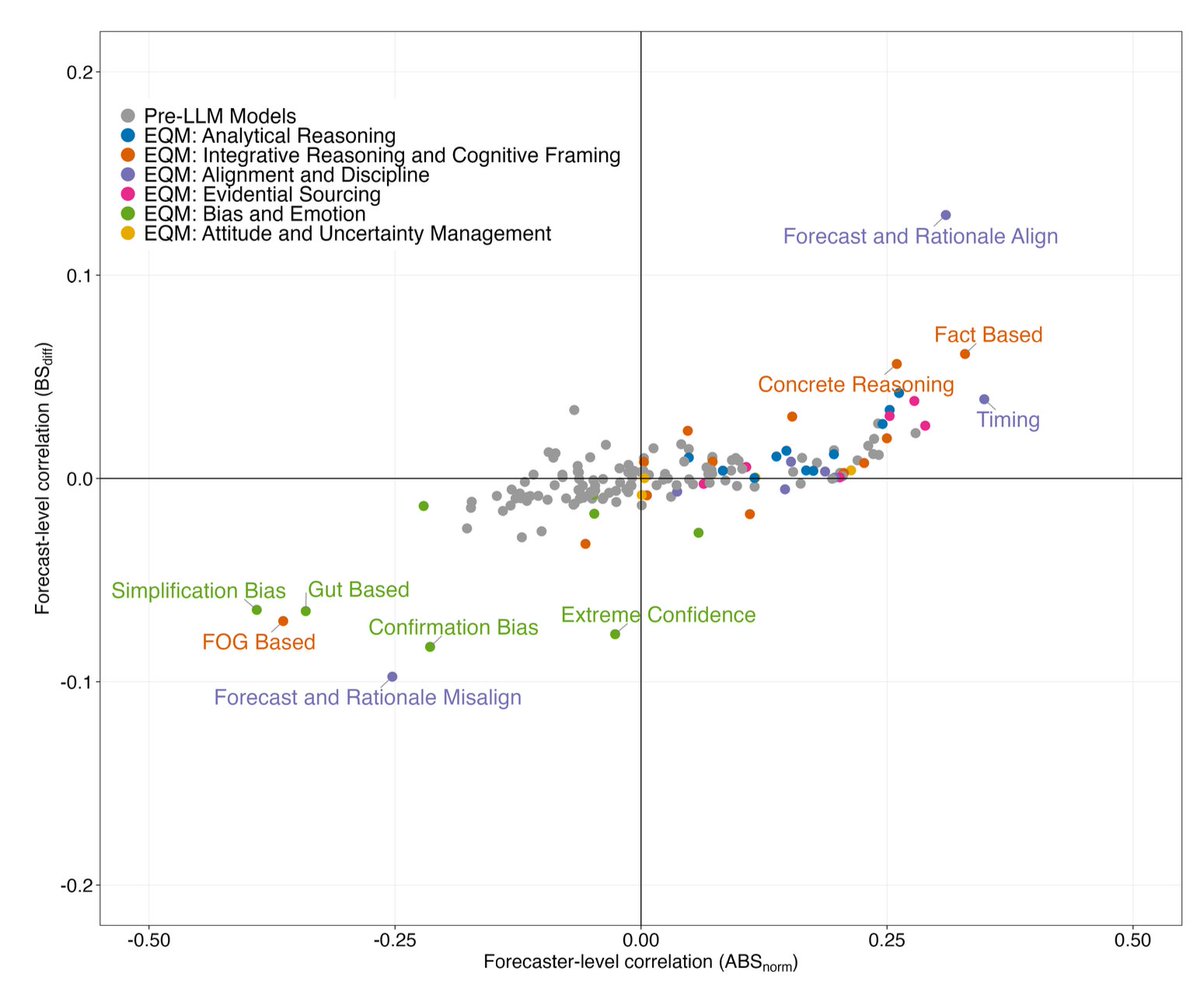
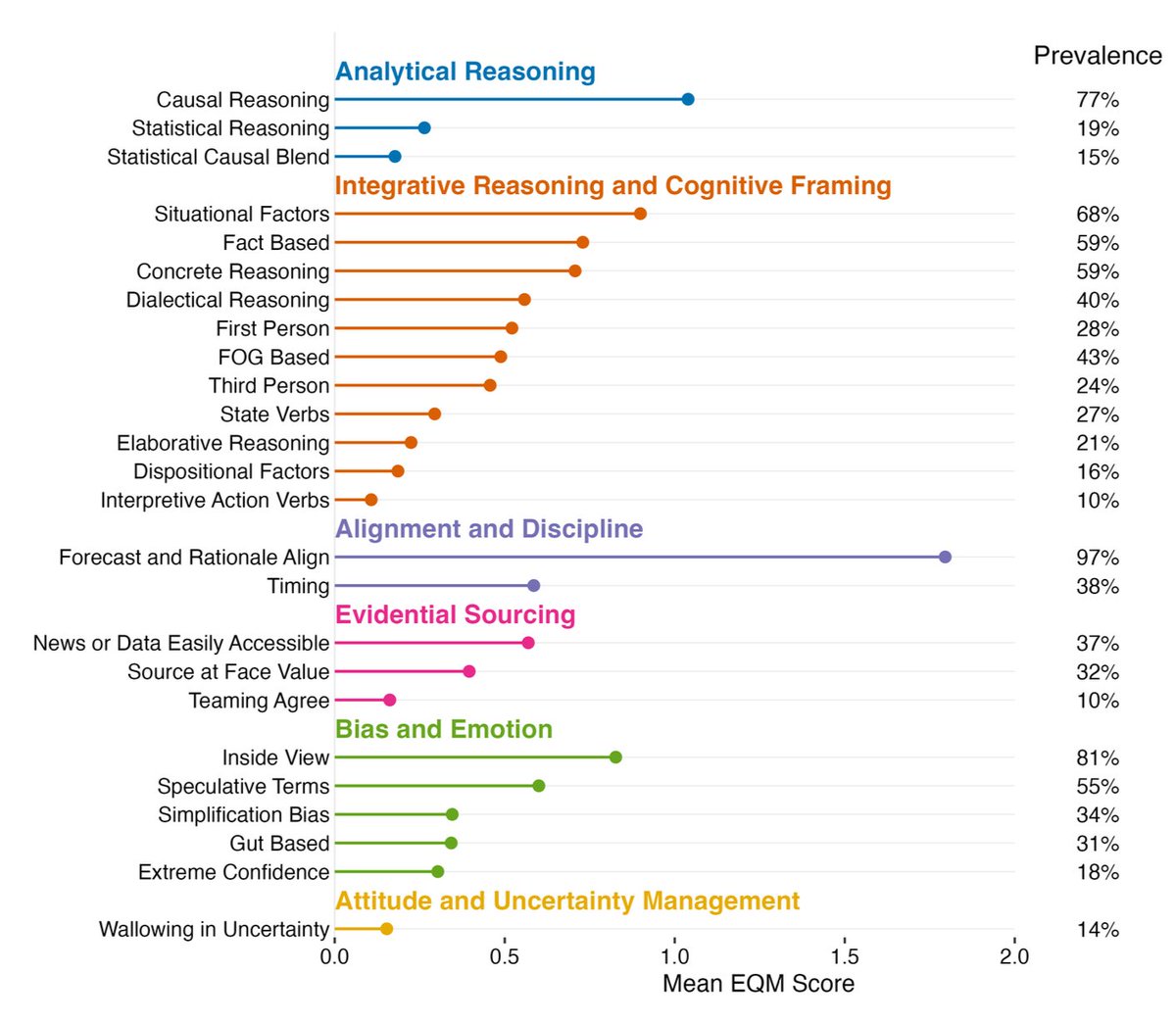

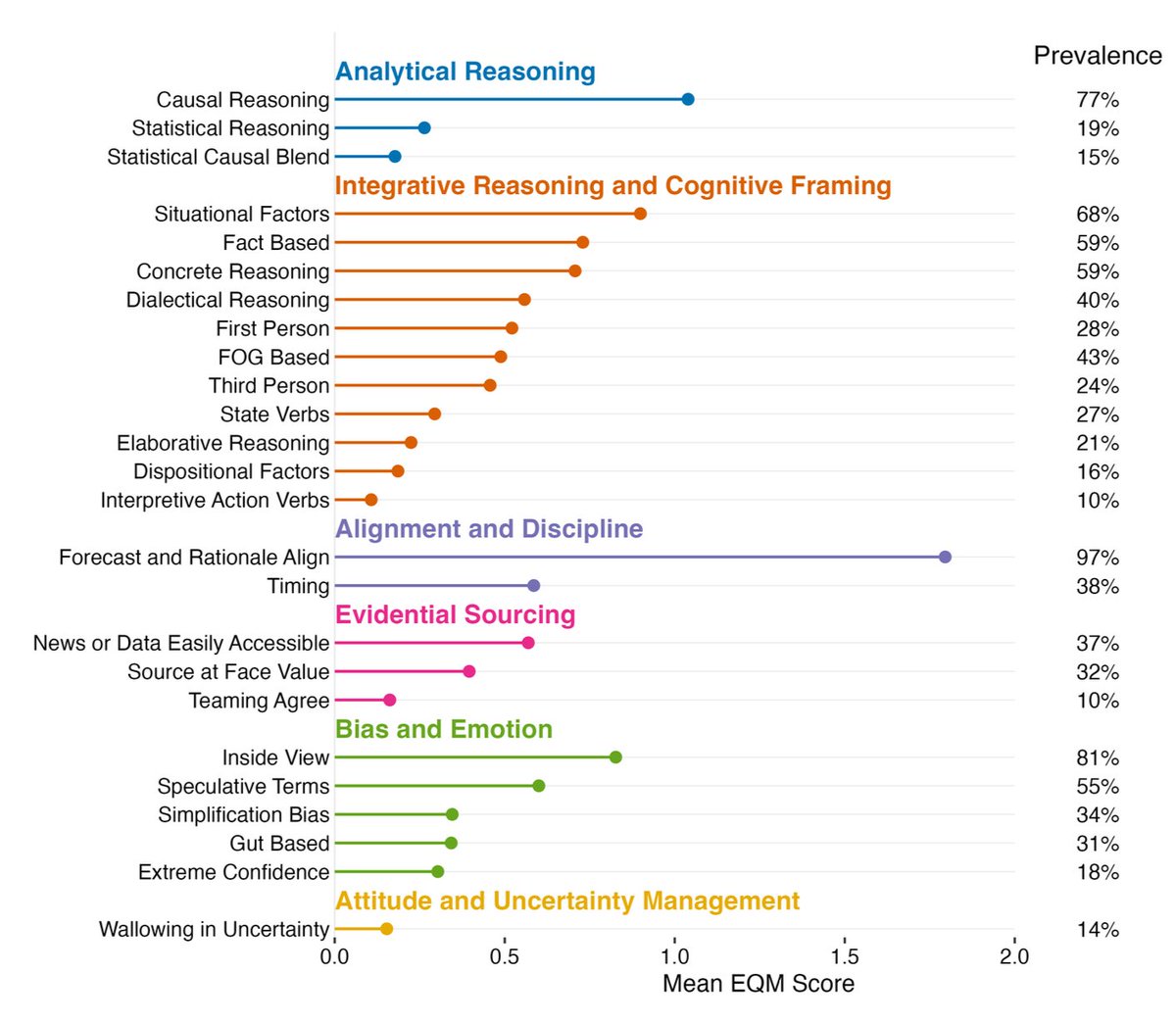



Is it possible to spot a good forecast by its rationale?
We used LLMs to score the reasoning behind 55,000 forecasts and test the link between forecast accuracy and written rationales.
We found that:
• Causal reasoning is much more prevalent than statistical argumentation
• It's easier to identify poor forecasters rather than excellent ones
• Human ratings of rationale quality can be unreliable.
🧵A thread on the results:
1
12
44
4,197
Why was this?
As you can see below, human ratings correlate strongly with rationale length, but length is essentially uncorrelated to forecast-level accuracy.
Human raters weren’t wrong directionally, but they appeared to place undue weight on some features, such as underweighting "red flags" like extreme confidence.
1
2
292
Thank you to the study's authors: Chris Karvetski, @sicong_huang, @simas_kucinskas, Nadja Flechner, Jingyu Hu, @PTetlock, and @EzraKarger
Read more on our Substack: forecastingresearch.substack…
Read the full working paper on SSRN: papers.ssrn.com/sol3/papers.…
3
269
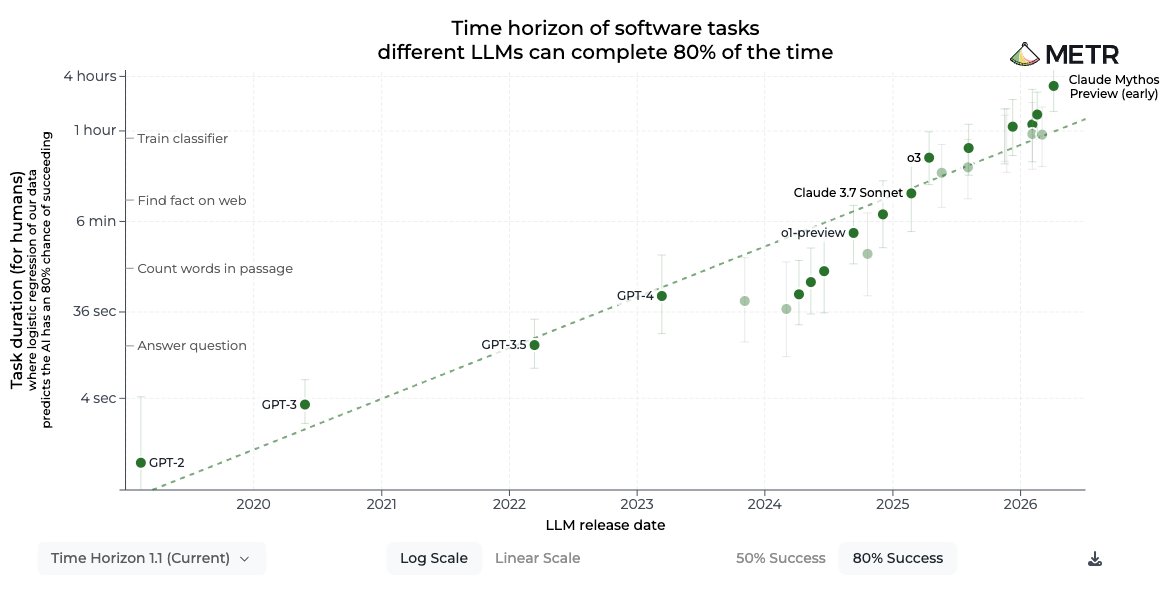
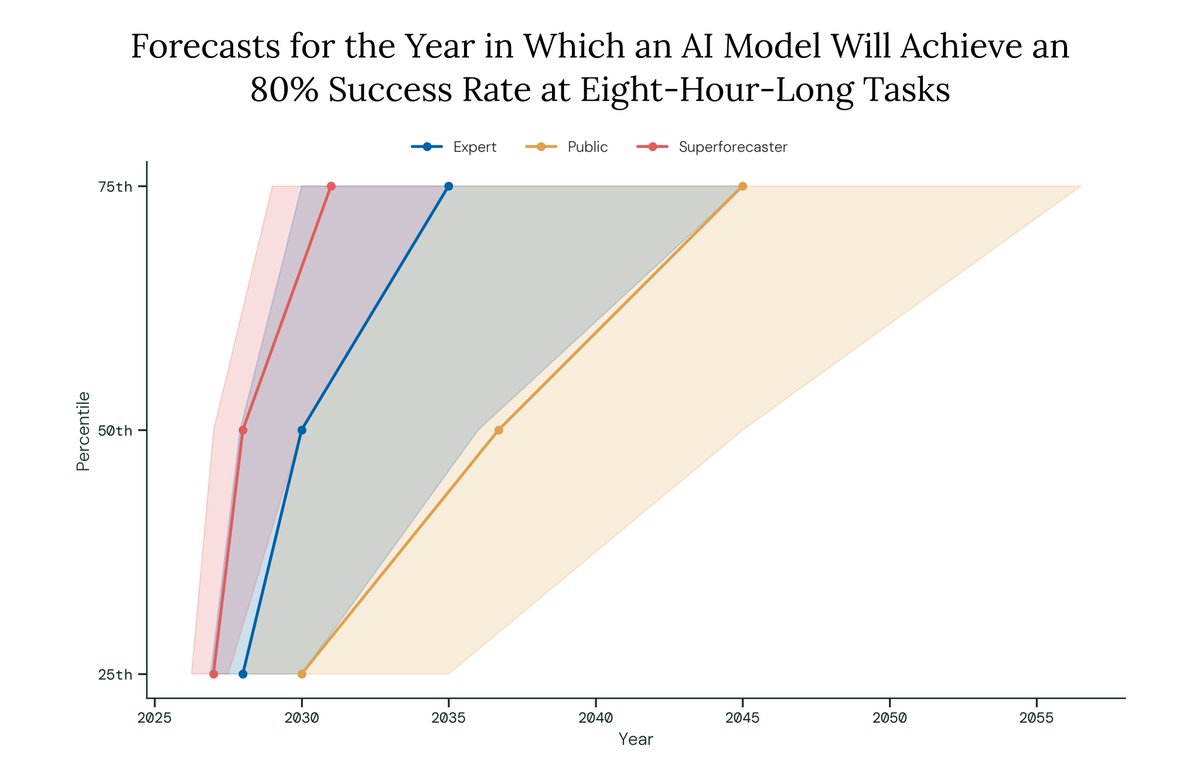
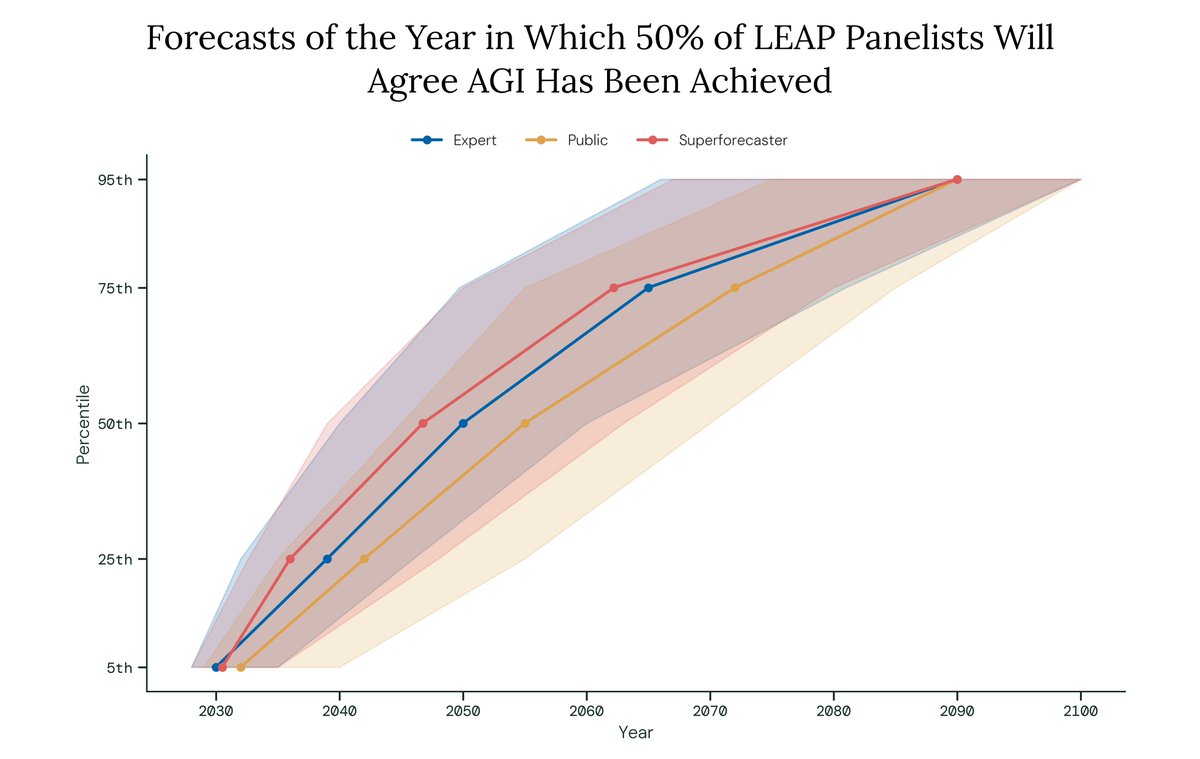
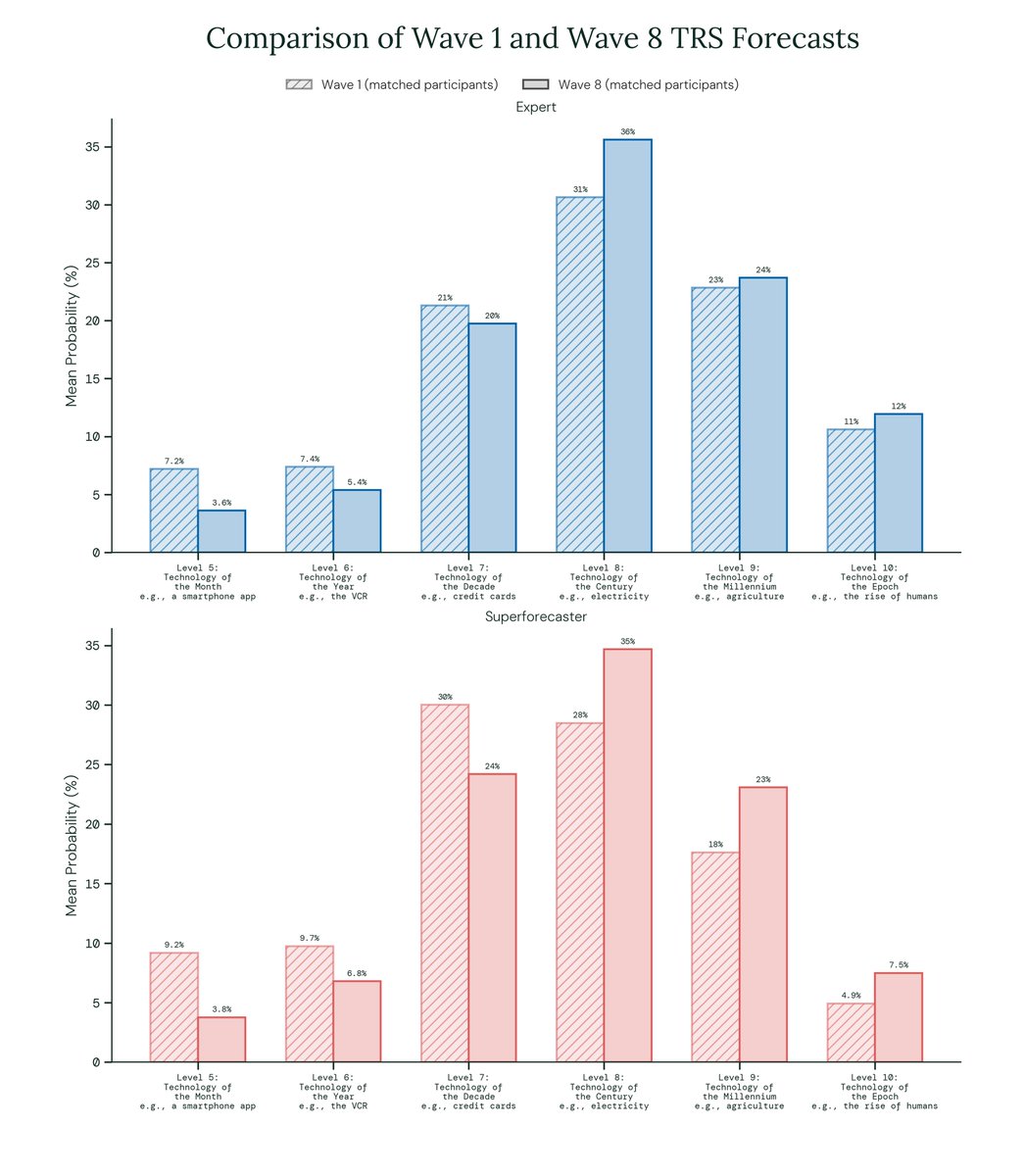
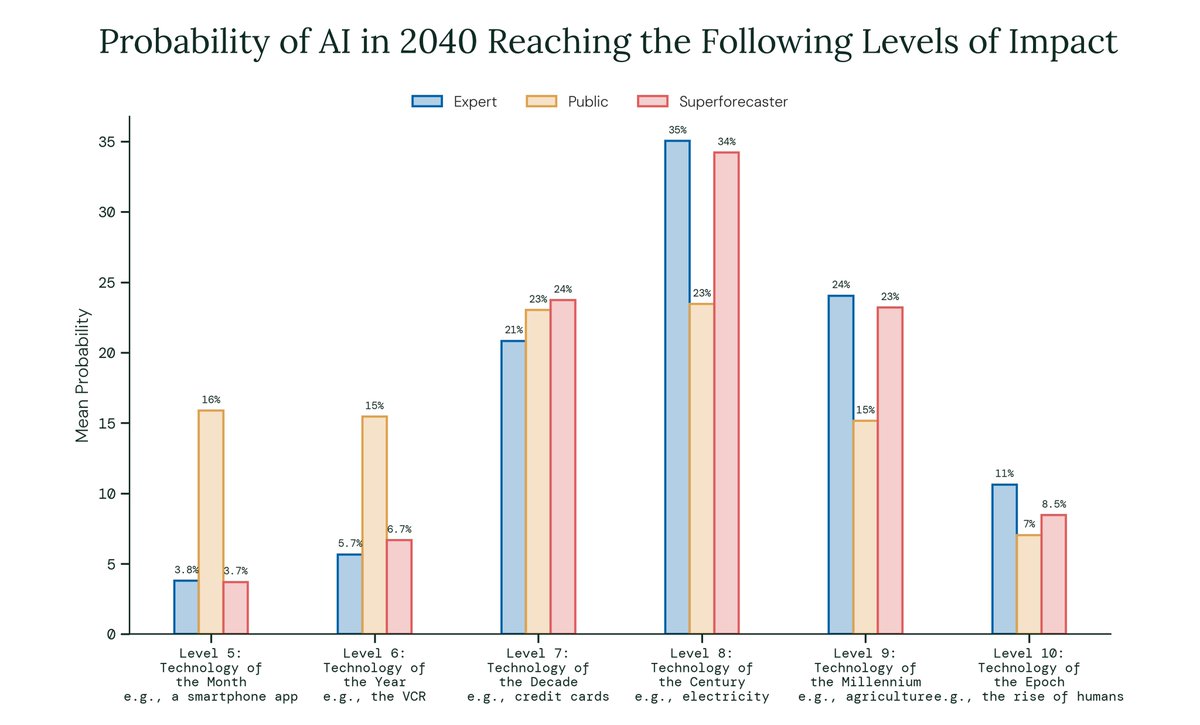
How are experts and superforecasters updating their expectations of AI progress?
In our latest round of Longitudinal Expert AI Panel (LEAP) forecasts, we asked for predictions on AI progress timelines, including updated forecasts for a question we last asked nine months ago.
We also asked for forecasts on near-term progress on @METR_Evals' time horizon benchmark, AGI timelines, the blockers and enablers of AGI, and AI's overall impact in the next 20 years.
🧵 Read on for more:
3
7
55
15,160
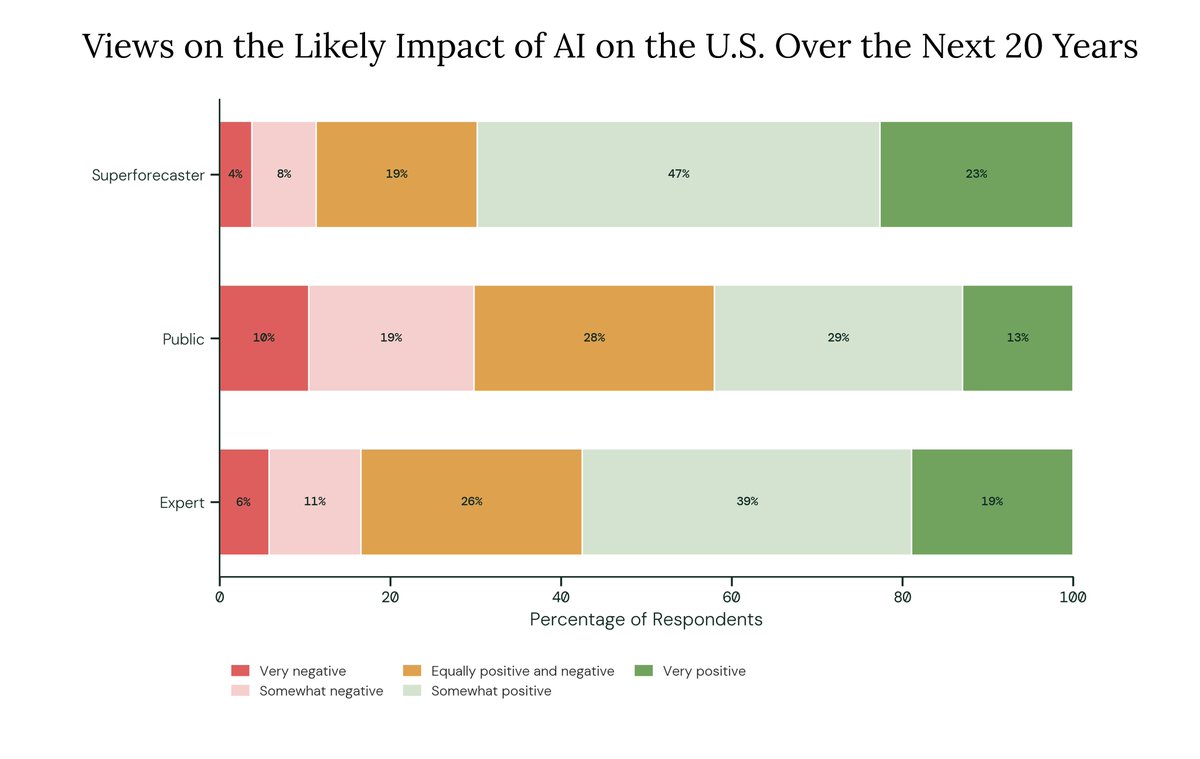
👍 Experts and superforecasters tend to view AI more optimistically than the general public
When asked for their view on AI's overall impact on the U.S. over the next 20 years, 57.5% of experts and 69.8% of superforecasters predict a somewhat or very positive impact, compared to 42.0% of the public.
The divergence is sharpest on problem-solving: 72.7% of experts expect AI will make people better at this, compared to 48.6% of the public.
One area in which experts and the public converge is their views on forming meaningful relationships. 68.4% of experts and 66.7% of the public expect AI to make people worse at this.
16.5% of experts and 11.3% of superforecasters expect AI's overall impact to be somewhat or very negative, compared to 29.8% of public respondents.
1
1
14
1,881
For a more detailed summary of these results, check out our Substack post: forecastingresearch.substack…
To explore more forecasts, including further questions from Wave 8, read the full report: leap.forecastingresearch.org…
1
4
1,298
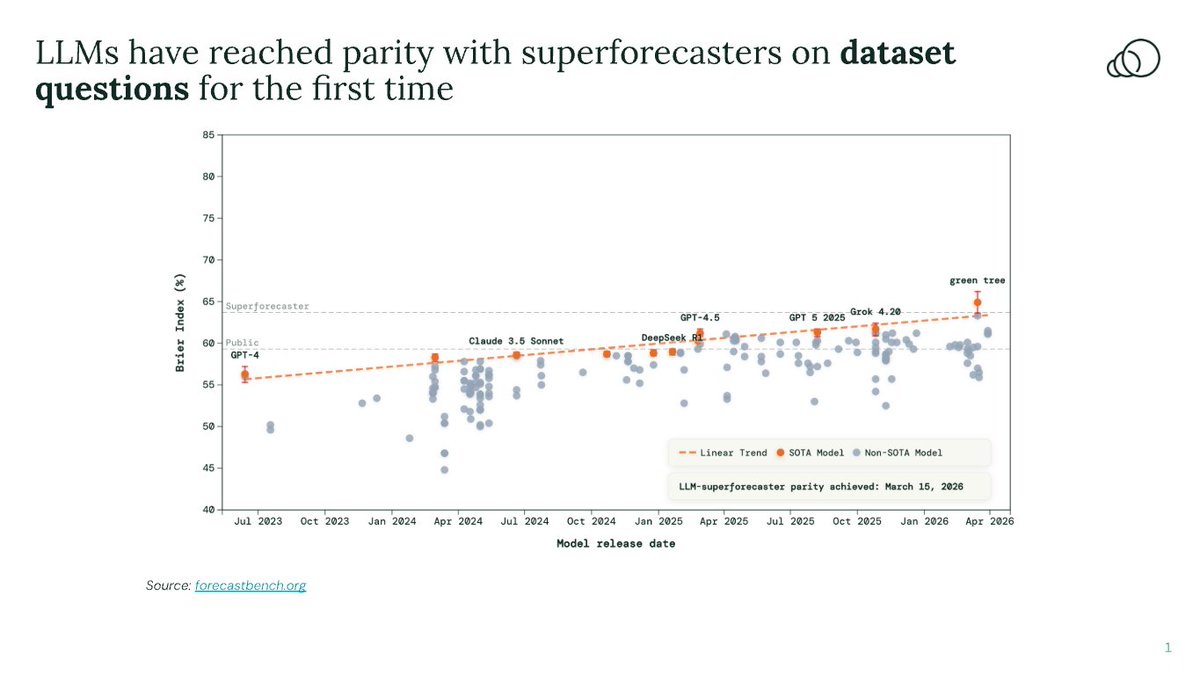
On a subset of ForecastBench questions, an LLM has matched superforecaster performance for the first time.
A submission from @GoogleDeepMind, named “green tree,” is now #1 on dataset questions on ForecastBench, our AI forecasting benchmark.
Superforecasters remain #1 overall.
5
15
83
200,228
Does parity on dataset questions mean ForecastBench is “solved”? No.
On market questions that require judgment about novel, one-off events, LLMs are still behind.
Even on dataset questions, the 64.9% achieved by Google DeepMind is unlikely to be the ceiling of what’s possible. ForecastBench doesn’t stop being useful at human parity. It will continue tracking LLM progress even if they surpass expert human forecasters.
1
4
560
We're working to improve ForecastBench! Upcoming changes:
• Fresh superforecaster round: fall 2026.
• Continuous (non-binary) forecasting questions: summer 2026.
• External submissions on continuous questions: summer 2026.
• Revamped dataset questions: fall 2026.
7
485