
Interested in retinal circuits and computations, vision and neuroscience. Researcher at the @InstVisionParis @oliviermarre@qoto.org
Joined September 2018
- Tweets 2,328
- Following 161
- Followers 704
- Likes 1,188
25 Photos and videos









Pinned Tweet

9 Jul 2022
Please RT: postdoc positions open in the lab to work on a @ERC_Research -funded project on retinal circuits and computations. Don't hesitate to DM or email me for details. oliviermarre.free.fr/Postdoc…
4
43
53
Olivier Marre retweeted

May 7
Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
307
1,674
11,182
3,159,790
May 7
Nice point by @TonyZador . AI is certainly a fantastic approximator, but it is unclear if it gives the level of compression necessary for understanding the brain. The question remains how much compression can we afford when trying to understand such a complex system. My take...

Prediction without understanding sustained astronomy through a thousand years of epicycles, writes @TonyZador. AI is now offering neuroscience the same deal.
thetransmitter.org/machine-l…
1
2
9
1,286
May 7
...would be that there is certainly compression to be done, but as much as in the law of gravitation. See also: trialsanderrors.substack.com…
57
May 4
Talking about blue brain, digital twins and the likes: The danger of building a brain from scratch: trialsanderrors.substack.com…
41
Olivier Marre retweeted

New paper: Back into Plato’s Cave
Are vision and language models converging to the same representation of reality? The Platonic Representation Hypothesis says yes. BUT we find the evidence for this is more fragile than it looks.
Project page: akoepke.github.io/cave_umwel…
1/9
6
68
338
89,598
Olivier Marre retweeted

Mar 11
In this short piece we make the case for latent equivariant operators methods✨, an alternative to classical and equivariant nets that shows promise for out-of-distrib classif. We lay out the challenges ahead for scaling these methods to larger datasets 🧐
follow @minhinhtrng 👀
Mar 11

Modern vision models lacks robustness when objects appear in unusual poses.
@StphTphsn1 and I study latent equivariant operators as a remedy and discuss caveats of these operators.
Below is a summary of the work, accepted at the GRaM Workshop at ICLR @iclr_conf 2026. 🧵

2
10
58
8,314
Olivier Marre retweeted

Mar 11
Modern vision models lacks robustness when objects appear in unusual poses.
@StphTphsn1 and I study latent equivariant operators as a remedy and discuss caveats of these operators.
Below is a summary of the work, accepted at the GRaM Workshop at ICLR @iclr_conf 2026. 🧵
1
13
56
10,301
Olivier Marre retweeted

Mar 8
Focus on the black cross and the red dots will appear to follow waves even though they move straight.
105
929
7,057
1,061,660
Jan 14
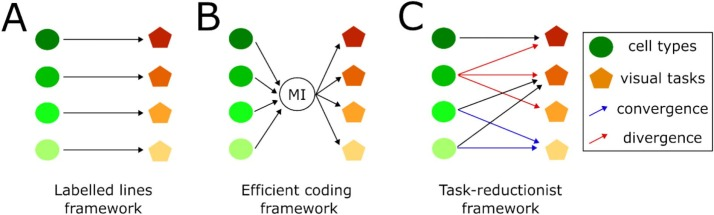
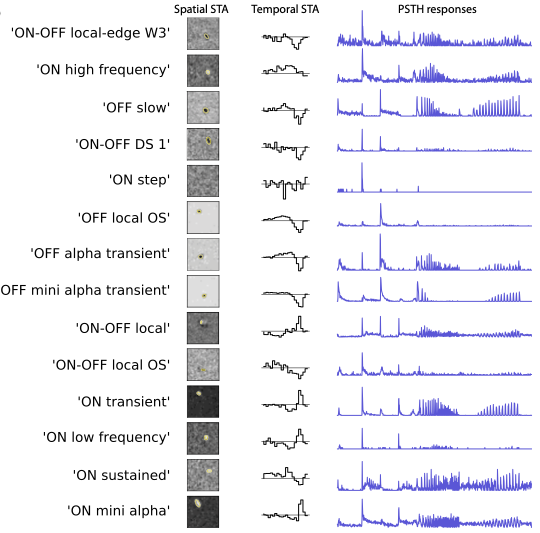
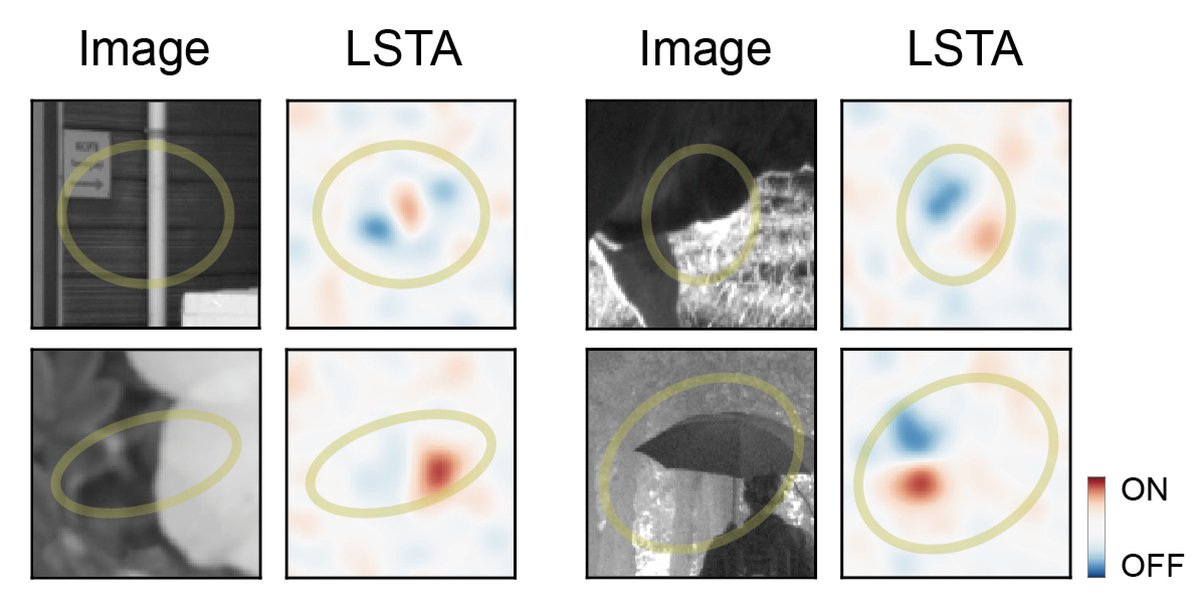
How does our visual system process natural scenes ? How can we approach this question ?
Happy to share this recent review written with Samuele Virgili where we ask these questions at the level of the retina.
sciencedirect.com/science/ar…
1
2
99
Olivier Marre retweeted

22 Jul 2025
Why do video models handle motion so poorly? It might be lack of motion equivariance.
Very excited to introduce: Flow Equivariant RNNs (FERNNs), the first sequence models to respect symmetries over time.
Paper: arxiv.org/abs/2507.14793
Blog: kempnerinstitute.harvard.edu…
1/🧵
9
85
462
57,762
Olivier Marre retweeted

4 Dec 2025
Our @NeurIPSConf 2025 paper - Spotlight selection (~top 3%) - will be presented tomorrow in San Diego by my co–first author @simoneazeglio. We welcome your feedback!
📍 Fri Dec 5, 11 AM-2 PM PST, Exhibit Hall C,D,E #2005
📄 𝐏𝐚𝐩𝐞𝐫: tinyurl.com/ilocal-paper
6
2
5
1,593
Olivier Marre retweeted

2 Jul 2025
🧵 What if two images have the same local parts but represent different global shapes purely through part arrangement? Humans can spot the difference instantly! The question is can vision models do the same?
1/15
6
121
601
77,911