
Student of mind and nature, libertarian, chess player, cancer survivor. @ Keen, UAlberta, Amii, Openmindresearch.org, The Royal Society, Turing Award
Joined October 2010
- Tweets 437
- Following 59
- Followers 64,810
- Likes 165
39 Photos and videos






Pinned Tweet

20 Jul 2023
AI researchers seek to understand intelligence well enough to create beings of greater intelligence than current humans.
Reaching this profound intellectual milestone will enrich our economies and challenge our societal institutions. It will be unprecedented and transformational, but also a continuation of trends that are thousands of years old.
People have always created tools and been changed by them; this is what humans do.
The next big step is to understand ourselves.
This is a quest grand and glorious, and quintessentially human.
80
151
1,017
279,132
Jun 10
8
8
141
28,642
Jun 10
Michael Jordan brings a strong and thoughtful perspective on AI:
youtube.com/watch?v=AREWYbVt…
14
36
276
38,364
Richard Sutton retweeted

Jun 7
I disagree with him but goddamn this is a banger.

A bandwagon has little appreciation for precise language and nuance.
1
13
6,070
Richard Sutton retweeted

But Western media is silent.
May 31

Not a single day passes in GAZA without children being murdered. Not one!!!!
42
1,104
4,234
62,973
May 31
Or perhaps you will prefer this short form of the video:
youtube.com/shorts/Qie6y_rqN…
8
9
165
21,352
May 31
A new and possibly controversial perspective:
In this video, I explain the sense in which generative AI trained by supervised learning is incapable of making novel discoveries.
youtu.be/K5LAFEjTlBA
The text of the speech:
AI Creativity and Discovery
Good day ladies and gentlemen. I regret that I am unable to be with you all today to engage in a back-and-forth discussion, but I am nevertheless pleased to be able to share with you, via this recording, some high-level thoughts about the current and future state of artificial intelligence, and in particular about AI’s relationship to science and mathematics, which is, as I understand it, the central focus of this meeting and of the SAIR Foundation.
I would like to start with an old joke; I am sure you have heard it before. It is the one about the researcher whose work is being evaluated, and the review comes back, and says “This work is both novel and good. Unfortunately, the parts that are good are not novel, and the parts that are novel are not good.”
My first point about AI is that this assessment applies exactly to large parts of AI as we know it today. Not all of today’s AI, but a large part of it. Pretty much all of what we mean by “Generative AI”---which includes large language models, and the images and video models, and even the new methods for learning world models. All of these AIs take large numbers of examples and produce a “model” which behaves similar to the examples, that is, which generates text like people, or images like artists or nature, and videos like we find on the internet. Don’t get me wrong, Generative AI can be extremely useful. No doubt about that. But the assessment of the joke still applies. These systems can produce output that is both novel and good, but not at the same time.
In many ways this is just absolutely not a problem. When we ask an AI for an answer from the internet, or to summarize a document, we don’t want it to be novel. We are happy if the quality of the answer, the goodness, comes from the source material—from the people who wrote the document or the articles on the internet. If the AI’s answer is novel it means it is going beyond the source material, adding something beyond it. This is what we call “hallucinations”. In most cases, we don’t like it when the AI makes something up, when it adds something novel.
One exception, of course, is when we are looking not for facts or reality, but for fiction and entertainment. We might ask for a bedtime story for a child, or an image based on existing images on the internet but which is nevertheless different and distinct from them. In these cases, it is never easy for us to know how creative the AI is actually being, as we do not know how close the AI’s story, poem, or image is to the source material. In a real practical sense we can not know this because the internet is too big, the possible sources that the AI may draw upon are too numerous.
When we ask for a fiction or novelty, the AI can give it to us because its processing is in part stochastic. Every decision can go multiple ways and will go different ways and produce a different trajectory every time. The trajectory can be random—and thus novel—or it can be based on the training data—and thus “good” because the training data is good, sourced from people or reality. Thus, the trajectory is either novel or good—based on randomness or based on data—but never both at the same time.
Really, I think it is okay if the output of Generative AI is never good and novel at the same time. For the researcher in the joke this is a devastating criticism, but for most things it is not, and for Generative AI it is not. Generative AI is meant to be a mimic. This is what supervised learning is for. Generative AI can be extremely useful, even when it just mimics, if it is faster, or cheaper, or smaller, or more customizable, or more copy-able, than the thing being mimicked. It is okay if Generative AI cannot be both novel and good at the same time. It is still a transformative technology.
But it is a limitation. And remember we are here to use AI for science and mathematics, and for these areas the assessment of the reviewer in the joke is devastating. For these areas we need true creativity and discovery. Generative AI—or Mimicking AI—will never get where us there. For these we need something more, and indeed we have something more in other parts of AI. We have many AI systems which can give us more. We have AlphaGo with its world-changing move 37, or AlphaZero with its brilliant original chess-playing style. We have GT-Sophy that drives simulated racecars better than any human. We have AlphaFold and AlphaProof and Claude-Code, which have brought true advances in science, mathematics, and programming. We have RL-Lyft which optimizes the assignment of cars to passengers in the ride-hailing business. All these systems have found things that are both novel and good. And, truth be told, some language models have been augmented in ways that make them more than Generative AI based on supervised learning.
All these systems have some additional features that make them capable of true creativity and true discovery. It is important for us to recognize what this is—and that it is not present in ordinary, garden-variety Generative AI. It is something that can not come from just supervised learning, from learning from examples. What is it? Well, it is a simple thing, a commonsense thing. It is not new. We have many names for it, but unfortunately none of them are very good names. I will call it Discovery. Basically, Discovery is just the idea of trying many things and seeing which of them work, then keeping those that worked the best. Evolution by natural selection works this way. The scientific method works this way. And just ordinary life and learning works this way. We try things and remember what works. What could be more obvious? In this behavioral case, psychology has two names for it— “instrumental learning” and “operant conditioning”—and in machine learning it is what we mean by “reinforcement learning”. We also see the idea of Discovery in planning and combinatorial search—anything that involves the idea of “generate and test”.
The essence of Discovery is to combine three steps:
1. Variation,
2. Evaluation, and
3. Selective retention.
Of course, I am not the first to say this. I am not the first to point out that this combination of steps is key to science, to evolution by natural selection, and to animal behavior. I think particularly of papers by Donald Campbell, by Daniel Dennett, and by Gary Cziko. What is new in my remarks is to directly relate the idea of Discovery to modern AI to help us see that it is not present in supervised learning or Generative AI—in particular, that Discovery is not present in backpropagation or gradient descent.
Let me say explicitly what is missing from Generative AI. As we have remarked, these systems do have a stochastic aspect, so they do generate a variety of trajectories and behavior. What is missing is the Evaluation step. The generator was pre-trained by supervised learning, leaving no way at runtime to Evaluate what it generates. And of course without Evaluation there can be no Selective retention, and thus no Discovery. The variation can bring novelty, but without evaluation there is no Discovery, and arguably, no creativity. That is, I would say that creativity requires that the new things generated be Evaluated. Without evaluation, and retention of the best, there is nothing created. The novelty flickers into existence but, if its value is unrecognized, it flickers away and is lost.
In many cases, Evaluation is done by people to make a discovery. As when we have Generative AI make many pictures for us, and then we pick the one that we like the best. The human AI system completes the discovery.
In many other cases, the Evaluation comes from a clear objective. Some moves lead to checkmate, some steps lead to a proof, some actions result in high reward, some genotypes make more copies, some theories explain the data better.
Some prefer the Variation step to be called Blind variation, where “blind” here means that it is uninformed, a shot in the dark. It does not need to be completely uninformed; a good scientist does not select theories to test at random. But neither can it be completely informed and determined. There must be some uncertainty about where the answer lies in order for there to be a discovery. In practice, the variation is partly informed and partly blind, but it is the blind part that corresponds to the discovery.
Now let us briefly go all the way to modern deep learning, to the backpropagation algorithm. At first it might seem that backpropagation is incapable of discovery because it is deterministic and thus incapable of variation. But this is not correct. The weight updates of backprop are deterministic, but the weights are initialized to small random values. The random initialization is often downplayed, but in fact it is a necessary form of variation; it must be done properly to get good performance. In backprop this Variation is done once, at network initialization, so its effect is temporary, and later the network may lose its ability to learn. This is the weakness of deep learning that is alleviated with a new algorithm that my group presented in Nature a couple of years ago. Our “continual backpropagation” made one small change: every so often a less-used neuron would be re-initialized to small random weights. This allows the variation to continue and plasticity to be retained.
Although there is much more to be said about Creativity and Discovery, this is the key point: they are more than supervised learning, more than pattern recognition, more than prediction, and more than world modeling. Those things are important, but they alone will not bring us to discovery. Discovery requires Evaluation from a person or from an explicit goal, and only in the latter case will we attain full autonomy.
So that is my call to arms. If we want the full power of AI scientists, then we should share the goals with them so they can create, evaluate, discover, and in these ways fully participate in achieving the goals. Let’s be bold! Let’s fully automate Creativity and Discovery!
105
283
1,686
678,508
Richard Sutton retweeted

May 23
Just wrapped a fascinating debate at @UpperBoundConf on "Could a Machine Be a Person?"🤖
Big thanks to co-panelists @RichardSSutton, Geoffrey Rockwell & @katragram, and moderator @alonamarie, for a rich discussion on AI personhood, agency & moral responsibility. #AI #Ethics



3
5
35
8,636
Richard Sutton retweeted

@RichardSSutton wrote "The Bitter Lesson" in 2019.
Silicon Valley read it and scaled LLMs to the moon.
Sutton says they got it wrong. 🧵
3
7
98
18,399
May 18
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
136
973
7,416
575,113
Richard Sutton retweeted

May 13
A tailor-made "kindergarten" for robots. Turing Award winner and a principal founder of reinforcement learning, Richard Sutton, has signed an agreement with a #Beijing-based company, collaborating to build a "Robot Kindergarten", planned to be located in Shougang Park in Beijing.


4
33
6,457
Richard Sutton retweeted

May 9
Our Open Ant is open-source!
Have fun with it! 😊
github.com/Openmind-Research…
4
22
6,643
If you are interested, you can learn a bit more about me from this video portrait from the Heidelberg Laureates Forum: youtu.be/jRPR6lx-iuw?si=_XiI…
4
18
135
15,418
Richard Sutton retweeted

A recent paper answered a question I had for over twenty years: how does a brain organize the sense of smell? This mouse study shows a 1 dimensional spatial code gives a brain map for ~1000 different smell sensors. This raises so many more questions. cell.com/cell/fulltext/S0092…
2
17
67
12,916
Richard Sutton retweeted

Amazing. No words to describe this tune. Emotional and to the point. New Iranian LEGO movie : We Share the Same Pain 💔 😭🥹
via Brick Beat Battalion
292
5,190
12,374
322,564
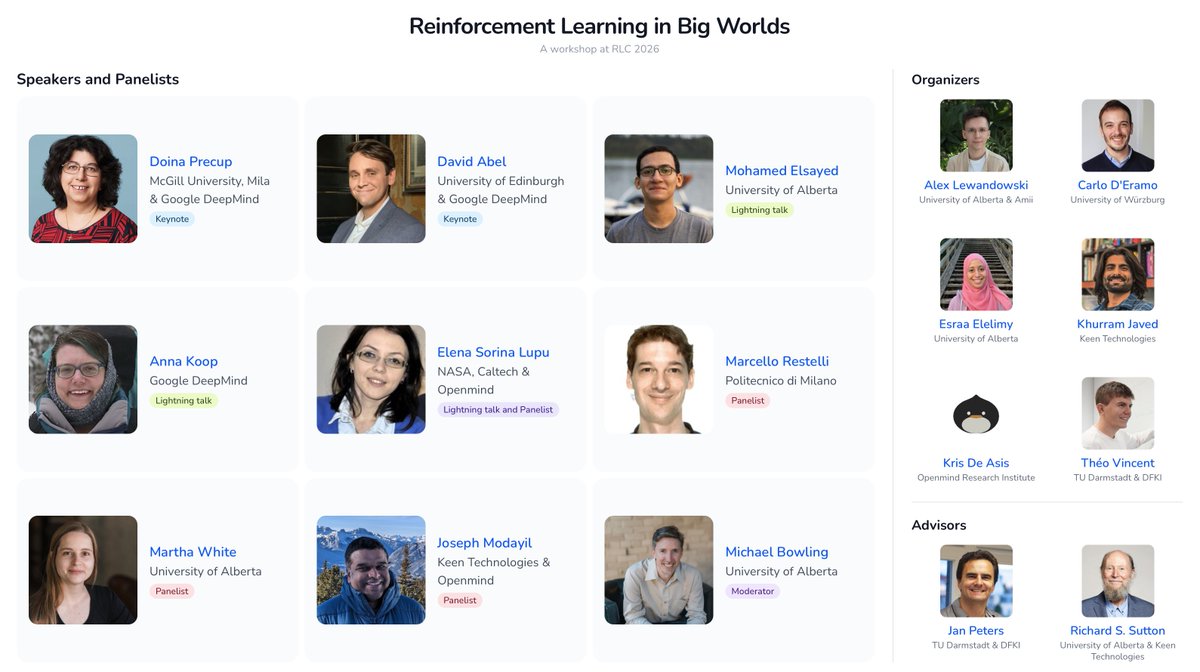
I am definitely going to this...

We are proud to have an amazing line-up of speakers!
They will present their works, which incorporate the constraint that the world is bigger than the agent and impossible to anticipate, observe, or model perfectly.
We are also looking forward to the panel discussion!
3
19
299
44,233
RL Ethics has a Predictive Semantics
I would like to try to explain the view of ethics and values that arises from my research in reinforcement learning in simple, layman’s terms that are accessible to all.
Reinforcement learning agents seek to maximize their reward over time, where reward is essentially pleasure minus pain. This is not quite hedonism, because the maximization takes into account all the consequences, long-term as well as short. A reinforcement learning agent might endure pain to get a larger pleasure later, or forego an immediate pleasure if it stored up later, greater pain. Formally, reward is a number at each time step, and the reinforcement learning agent seeks to maximize value—the sum of the rewards at future time steps. (This could be defined precisely with some math.)
The assignment of rewards to time steps is a free choice that defines the agent’s goal; different agents could have different rewards, and there is no basis (yet) for preferring one set of rewards over another. Value though is a different matter. Given a world and a way of generating rewards, the true values at each time step are fully determined. The rewards are primary, dependent on nothing else, whereas the values are secondary, following from the rewards (and the dynamics of the environment). In decision making, the agent should make the choice that leads to highest immediate value, not highest immediate reward.
If rewards are arbitrary, values follow from the rewards, and correct behavior follows from the values, then all seems straightforward. What about all the complexities and controversies of ethics? Some of these are still present, arising because the values, though well defined, are initially unknown and can be difficult to calculate or learn.
If the agent has knowledge of the world, then it may be able to calculate the values, but to do so exactly generally requires too much knowledge, computation, and memory. In practice, in new situations the calculation must be done partly at decide time, and cannot be done to completion without slowing down action selection too much.
In the absence of knowledge and computation, but given a generous allocation of memory and time, the agent can alternatively learn the values, again approximately. It is common for the agent to store an approximation to the world’s state’s values, and then to gradually improve these approximations—these predictions of subsequent rewards—by further experience. The stored approximate values are immediately available estimates of the desirability of situations; they are directly analogous to our intuitive sense of good and bad. They are ready for immediate use, but may only be rough approximations to the true values. They may be made more accurate with calculation (if the agent has knowledge) or learning (with more experience).
This completes the explication of the value system of the individual. Next we will go on to consider the value systems of groups. But the individual forms such an essential foundation that is never replaced, so let’s dwell on it a moment longer by reviewing its stark tenants: Each agent wants to get pleasure (reward) from the world. Pleasure is built-in to the agent and obvious when it happens, but when it will happen depends on the world and must be learned or calculated—and the world is too complex for either of these methods to yield answers that are completely correct. That is, every state of the world has a real, objective value (the amount of pleasure that will follow it), but estimates of its value are subjective. Forming better value estimates is a major cognitive task. They are a key intermediate step towards getting more pleasure from the world. Agents work on this all the time. It determines what they do.
If an agent lived alone, then this would be the end of our discussion of values and ethics. But people are not solo agents. Peoples’ worlds are comprised, in part, of other people, and this has many impacts of their attempts to estimate value and obtain reward. They live within groups of agents with whom they interact frequently and whom are major determinants of their success is obtaining reward. And thus, to achieve our reward, each of us must take into account, as best we are able, the rewards and values of those around us.
…
The most important insight is that it's alright, and perhaps obligatory, for the ultimate value to be hedonic (based on reward), as long as it is not "selfish" (disregarding the impact on others). The ultimate meaning of something being good, or right, or ethical, or moral, is that it will probably have a good outcome for the individual. Whether it will or not is extraordinarily difficult to calculate, so instead we use heuristics—approximations using features of a situation. The mistake is to think that those features are definitional rather that approximate predictive. The real definitional meaning of good is that it turns our well for us on average.
12
57
319
36,050
Richard Sutton retweeted

Apr 27
It is good to have a well-funded place that understands that intelligence is not about distilling human knowledge and skills into neural networks. Most of the current AI systems, while amazing, outsource discovery of knowledge to humans.
Systems that learn from human knowledge, in the limit, will be able to know and do everything that humans can do currently. These systems are immensely valuable, but they will be continually superseded by humans who can both use these systems and learn from their own experience.
Systems that learn from their own experience, in the limit, will be able to do things that no human can do now and no human would even be able to do.
The latter systems would be vastly more powerful.

Introducing Ineffable Intelligence. Led by David Silver, we're assembling the best engineers and researchers in the world to make first contact with superintelligence. We’ll be solving the hardest problems in AI on the way. Come join us.
ineffable.ai

7
13
151
23,541
Richard Sutton retweeted
Apr 20
The naive way to look at the future of AI is to look at numbers like network parameter count, transistor density, and benchmarks, and reason about the future solely from these numbers. This way prevails because it doesn't require thinking about the details of computer architectures and algorithms. It leads to reductionist arguments like "any marginal compute given to an adversary would be devastating because <insert model of the month> is dangerous."
The reality, as Jensen points out multiple times, is more complex. Unless there is an unprecedented breakthrough in chip manufacturing, the path to better AI is through better learning algorithms and architectures. This has been the trend for the last five years and will likely continue to be so. I know from my own work that you can get 100x to 1000x gains in computational efficiency by using better learning algorithms.
Jensen also correctly argues that an ASIC that runs a specific model efficiently is not a replacement for the CUDA stack. I have been working with non-traditional algorithms over the past few years (sparse event-driven neural networks), and the specialized ASICs (including Nvidia's Tensor Cores) are largely useless. CUDA cores, on the other hand, are extremely good at running these algorithms even though they were not designed for them. In a world where CUDA didn't exist, CPUs would be the best computing platform for discovering better algorithms, not TPUs.
You cannot achieve human-like learning at human-like energy consumption simply by improving chip manufacturing. The right algorithms running on the right chip made by the 7 nm process would vastly outperform the current algorithms running on the best chips made by the 2 nm process.
Apr 15

The Jensen Huang episode.
0:00:00 – Is Nvidia’s biggest moat its grip on scarce supply chains?
0:16:25 – Will TPUs break Nvidia’s hold on AI compute?
0:41:06 – Why doesn’t Nvidia become a hyperscaler?
0:57:36 – Should we be selling AI chips to China?
1:35:06 – Why doesn’t Nvidia make multiple different chip architectures?
Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!
3
11
145
24,714
Richard Sutton retweeted

Apr 14
Lebanon is being destroyed.
1.2 million people, including 400,000 children, forced out of their homes by bombardment. Towns and villages flattened. Innocent civilians killed. Parents grieving over their lost children. There is no justification for this.
1,163
9,908
16,435
327,056