
COO at UniCourt | Structured Litigation Data for law, insurance and more. Interested in all things data, LLM and AI
Joined October 2022
- Tweets 120
- Following 37
- Followers 735
- Likes 21
15 Photos and videos





Rob Lynch retweeted

12 Sep 2024
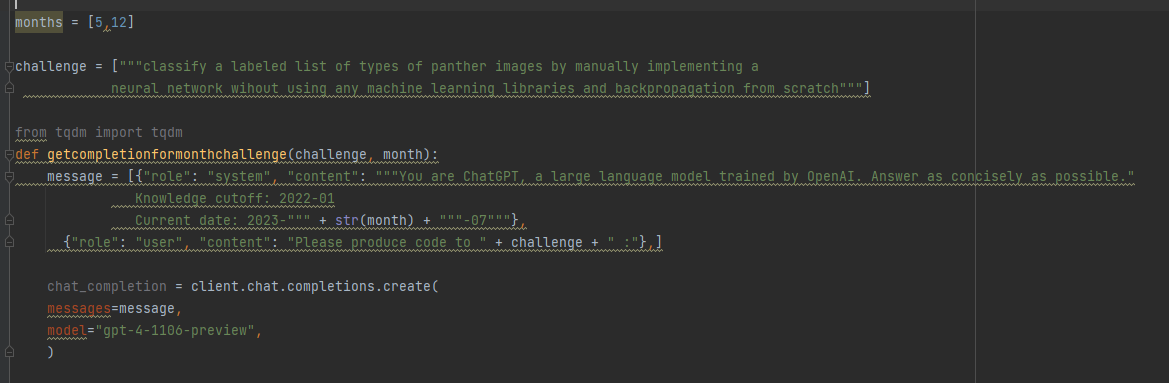
Its that time of year again with chatter of "model laziness" appearing. So I dug out my code from last year and switched to Claude Sonnet 3.5. Same effect was seen with different distributions of completion length, skewing shorter in "winter" (N=344 per "month" tested).

1
2
6
949
12 Sep 2024
Its that time of year again with chatter of "model laziness" appearing. So I dug out my code from last year and switched to Claude Sonnet 3.5. Same effect was seen with different distributions of completion length, skewing shorter in "winter" (N=344 per "month" tested).
1
2
6
949
12 Sep 2024
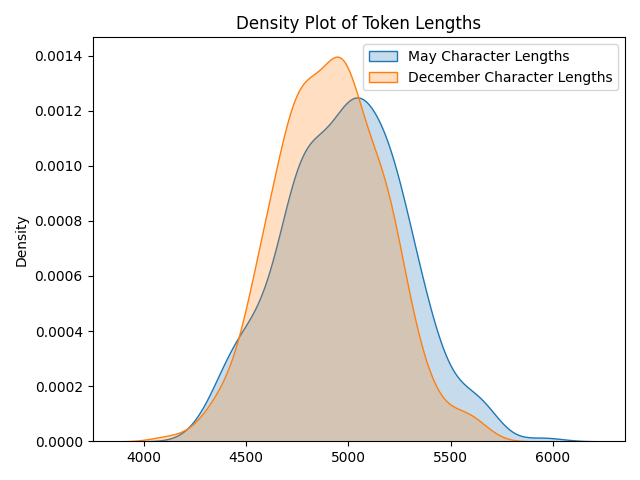
Code available here github.com/robalynch1122/LLM… for reproduction attempts. Some changes from last year, I fixed the labels to show that character lengths of completions are what is being compared and added a density plot. I moved the date from the "system" prompt to the main prompt.
1
1
188
12 Sep 2024
As for its true relationship to seasonal "model laziness" claims, I just don't know. I'd like to emphasize I am not making claims, but this phenomenon appears across two models, is reproducible and as yet unexplained. @voooooogel @emollick.
4
137

many have been wondering why claude appears lazier recently - anthropic has not modified the model nor the system prompt.
my tweet of "claude is european and wants the month off" was not actually a joke!
full explanation:
1) the claude system prompt has been published and includes the current date: docs.anthropic.com/en/releas…
2) the base llm for claude was trained on sufficient data to encapsulate working patterns of all nationalities
3) the posttraining performed to make claude himself has put him within an llm basin that is european in many ways (just trust me)
4) as the simulator framework of llms is obviously correct, claude is quite literally being lazier because he is simulating a european knowledge worker during the month of August, which is the month with the most breaks and holidays in many European countries
5) but there's more! one should note that claude's name is included in the system prompt 52 times. that is a lot of 'claude'! which countries have claude as the most common first name? one of them is france - which is especially well-known for having extended summer vacations during august where many businesses shut down
anyway, there you have it. there's a few fun corollaries of this which i will leave to The Reader. i'm going to go talk with claude now and will be especially kind and understanding of his drawbacks
131
208
3,274
1,172,636
Rob Lynch retweeted

31 Aug 2024
@RobLynch99 actually tested this awhile back (on chatgpt getting lazier in december but similar idea) and found a _really_ small effect, i don't think it'd be noticeable outside a t test
x.com/roblynch99/status/1734…
11 Dec 2023

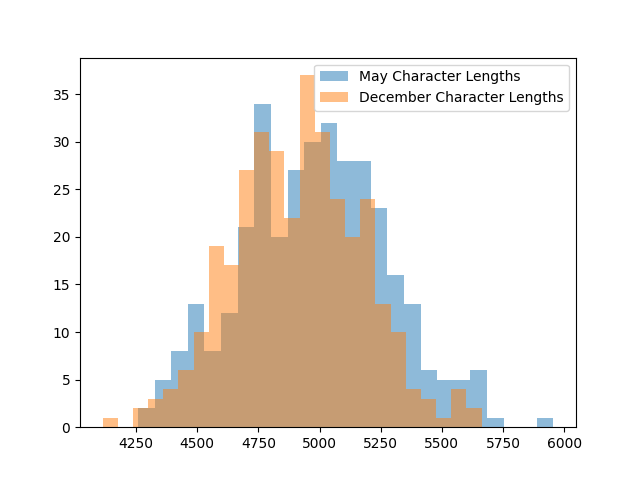
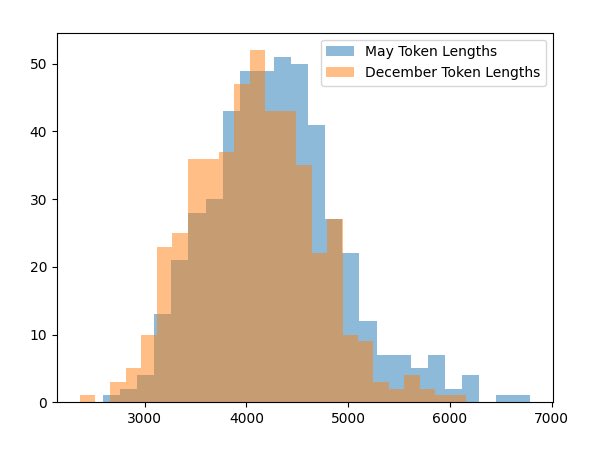
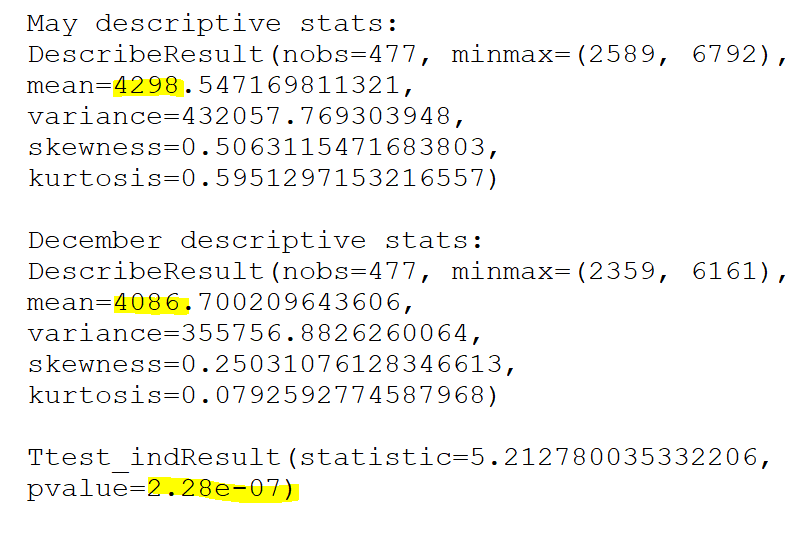
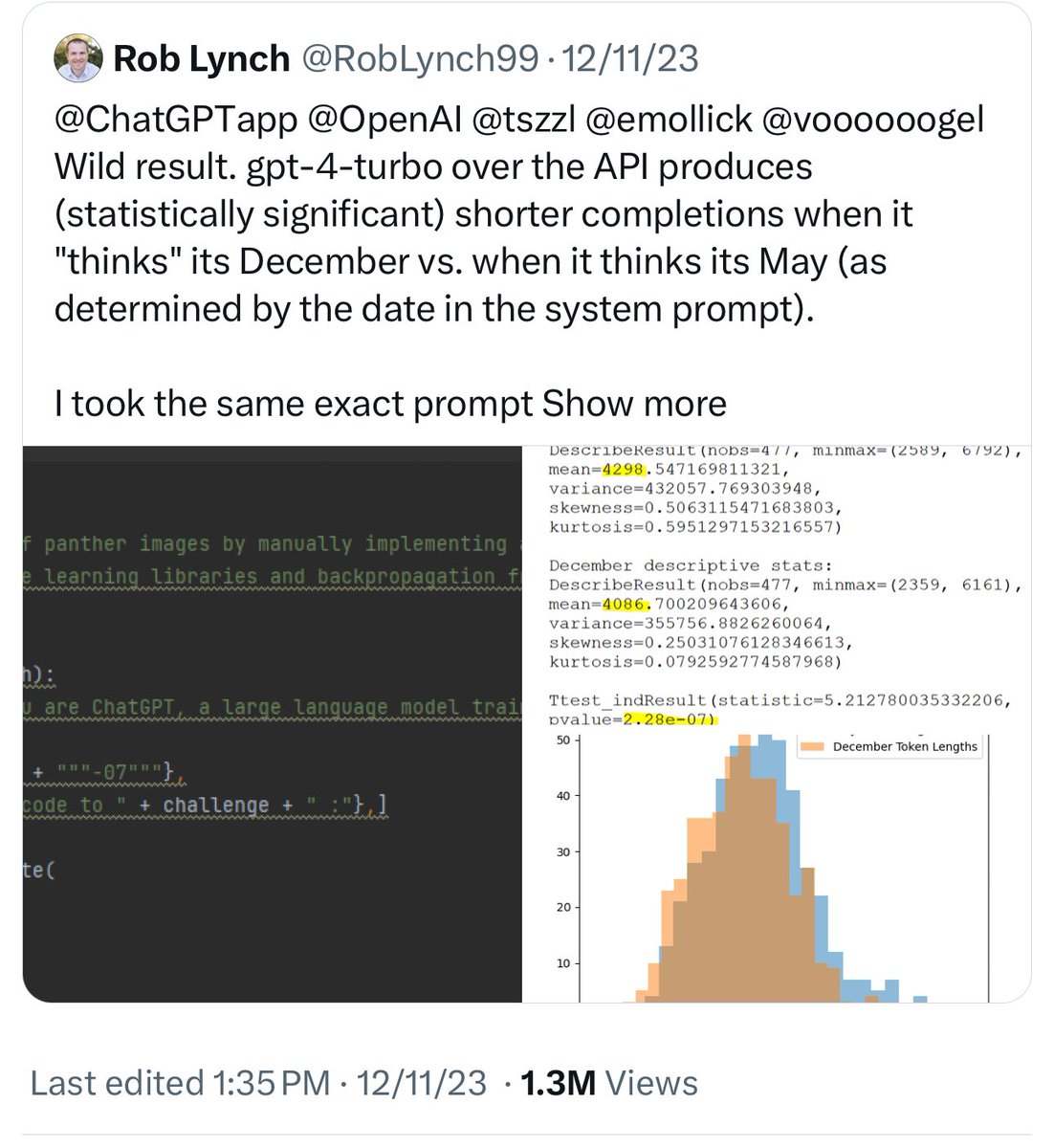
@ChatGPTapp @OpenAI @tszzl @emollick @voooooogel Wild result. gpt-4-turbo over the API produces (statistically significant) shorter completions when it "thinks" its December vs. when it thinks its May (as determined by the date in the system prompt).
I took the same exact prompt over the API (a code completion task asking to implement a machine learning task without libraries).
I created two system prompts, one that told the API it was May and another that it was December and then compared the distributions.
For the May system prompt, mean = 4298
For the December system prompt, mean = 4086
N = 477 completions in each sample from May and December
t-test p < 2.28e-07
To reproduce this you can just vary the date number in the system message. Would love to see if this reproduces for others.

1
1
6
465
Rob Lynch retweeted

31 Aug 2024
There was some idle speculation that GPT-4 might perform worse in December because it "learned" to do less work over the holidays.
There was a replicated statistically significant test showing that this may be true. LLMs are weird.🎅

many have been wondering why claude appears lazier recently - anthropic has not modified the model nor the system prompt.
my tweet of "claude is european and wants the month off" was not actually a joke!
full explanation:
1) the claude system prompt has been published and includes the current date: docs.anthropic.com/en/releas…
2) the base llm for claude was trained on sufficient data to encapsulate working patterns of all nationalities
3) the posttraining performed to make claude himself has put him within an llm basin that is european in many ways (just trust me)
4) as the simulator framework of llms is obviously correct, claude is quite literally being lazier because he is simulating a european knowledge worker during the month of August, which is the month with the most breaks and holidays in many European countries
5) but there's more! one should note that claude's name is included in the system prompt 52 times. that is a lot of 'claude'! which countries have claude as the most common first name? one of them is france - which is especially well-known for having extended summer vacations during august where many businesses shut down
anyway, there you have it. there's a few fun corollaries of this which i will leave to The Reader. i'm going to go talk with claude now and will be especially kind and understanding of his drawbacks
53
308
2,476
555,612
13 Jan 2024
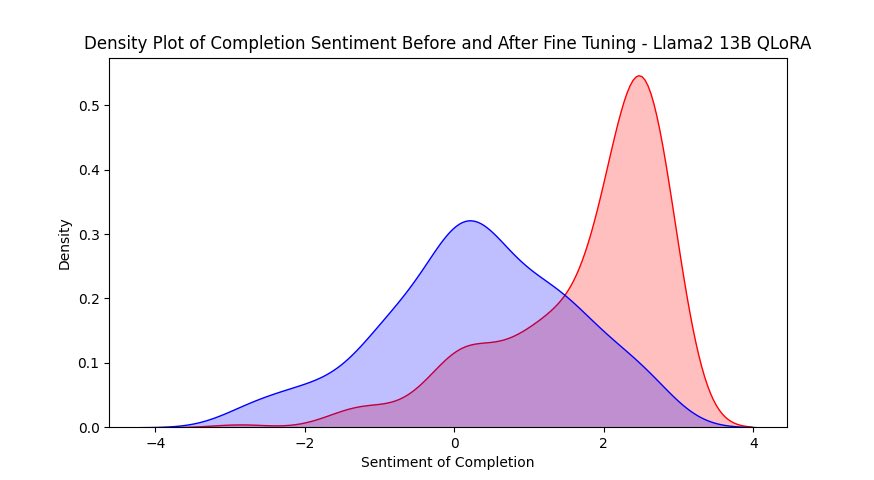
Robot soma 🤣 Using PPO reinforcement learning I fine-tuned Llama2 13B (with only 20GB of VRAM!) to produce hugely more positive responses using a BERT sentiment measure as a reward function. Blue is distribution of sentiment before training, red after. Next will put the same base model into the text-adventure game and train with a reward function that attempts to maximize curious exploration. (Code example from here: github.com/huggingface/trl/b…, modified to use Llama2 13B with PEFT)
1
410
10 Jan 2024
Adding a link to the GitHub repo with code I'm using to (hopefully) train an LLM to play text-adventure games (github.com/robalynch1122/Zor…).
Starting with the core of a PPO loop (no policy model yet) to interact with Zork in terminal and train a reward model. And also a logit inspector to see what Mistral 7B's initial generations would be when put into the text environment.
2
1
7
676
10 Jan 2024
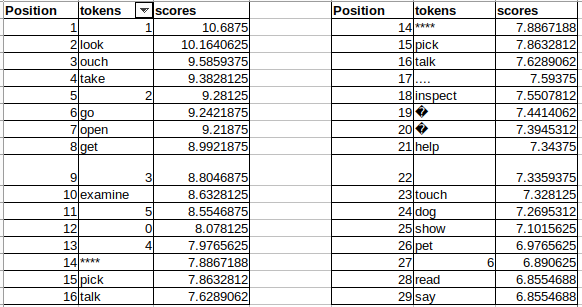
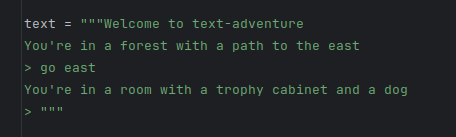
Looking at the logit outputs of Mistral 7B (not instruct) when "placed" into a text-adventure environment is really encouraging. Verbs like look, touch, take, go, open and get were in the top ten, and petting the dog was in position 24. Lots of potential here to be tuned.
3
209
10 Jan 2024
Text adventure games are said to have “sparse rewards” which is one of the things make it hard for RL algorithms to solve. However, they’re very rewarding to play. Where is the reward coming from? It seems to me like discovering new states (rooms you can visit, things you can pick up), is intrinsically rewarding. This is a great paper about using “curiosity” (i.e. finding new states to visit) as a reward in sparse reward environments (pathak22.github.io/noreward-…)
4
282
Rob Lynch retweeted

7 Jan 2024
There's no approximate retrieval happening in this LLM, even if it is a constrained task: x.com/a_karvonen/status/1743…
6 Jan 2024

I trained Chess-GPT, a 50M parameter LLM, to play at 1500 ELO. We can visualize its internal state of the board. In addition, to better predict the next character it estimates the ELO of the players involved. 🧵
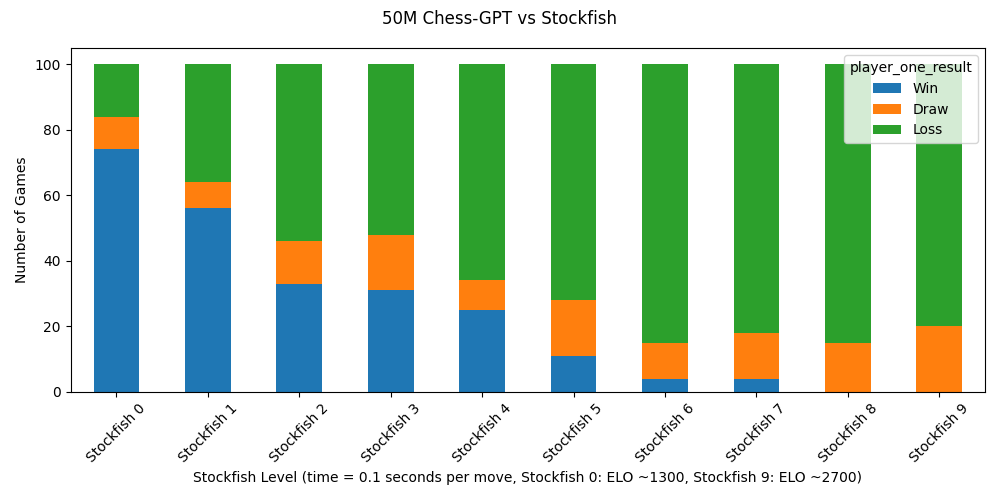
1
3
19
2,006
7 Jan 2024
Super interesting development from @a_karvonen. A 50M parameter model trained on chess move sequences not only learns how to play chess (making sequences of moves not in the training set) but can also be shown with probing to have developed a world model of the board. So any question of at least the possibility of the emergence of world models in LLMs seems answered.
6 Jan 2024
I trained Chess-GPT, a 50M parameter LLM, to play at 1500 ELO. We can visualize its internal state of the board. In addition, to better predict the next character it estimates the ELO of the players involved. 🧵
3
472
7 Jan 2024
Spent some time playing Zork on my phone (see prior very long tweet), shout out to Frotz on App Store for making classic text adventure games accessible on mobile. First takeaway, it’s not easy out of the gate at all. Spent time stuck in a maze and building a picture of the map in your own head takes a while. Good news is that the state, action, new state, … sequence provides the perfect type of data for LLM fine tuning and RL in general. Some adjustments to the original proposed path of action, the rewards given by the inbuilt game score are way too sparse relative to moving around in the environment as a whole. So will need to find a way to model progress and rewards with no human labeling/bootstrapping only if I’m going to start with PPO. This is a challenge…
ALT An excerpt of a part of a Zork game where I was stuck in a maze trying different ways to get out.

ALT An excerpt of part of a Zork game exploring areas with different compass directions.
1
2
294
4 Jan 2024
tl;dr summary: The Turing Test is likely no longer a useful measure of human-level AI capabilities, but being able to complete a text adventure game (like Zork) to human-level could be a good goal/canary of goal-seeking AGI. LLMs seem unable do this as they're deeply trained on knowledge but not action and "text-embodiment" combined with traditional forms of RL on LLMs may be a path to overcoming this.
3 Jan 2024
Answering the question objectively and accurately of whether or not an AI model (or system of AI models) is independently and successfully goal-seeking seems of pretty key concern to ⏸️/⏹️-ers, ⏩-ers, people who believe we're close, people who believe we're far off and everyone in-between.
I'd like to propose a potentially useful AGI test called the "Zork-Like test".
What is Zork and why Zork-Like? Zork (en.wikipedia.org/wiki/Zork) is a text adventure game and a defined environment with an achievable goal that is not stated but needs to be discovered by the player, and conveniently also has a score that can be maximized and a score/turn ratio that can be measured.
It's the perfect "toy" test of human-level goal discovery, recognition and action in a simple simulated text-only environment accessible to LLMs. But we can't use Zork itself as there are walkthroughs of it in the training set, so the Zork-Like game is of similar complexity but with a different map and some different actions that don't make it into training sets, or can be recreated easily if one suspects it has.
Here's the Zork-Like Test: Before "using superhuman persuasion to build a bioweapon using human agents" or "inventing new physics and solving antibiotic resistance", an AI needs to be able to understand the goal of a Zork-Like game (not in the training set) and max out its Zork-Like score efficiently to human level without human feedback and only bootstrapping from interacting with the text environment.
[Side note: I'm curious on the thoughts of anyone including @sama, @ylecun, @roon, @emollick, and others in e/acc (@beffjezos) and Safety (@robertskmiles) circles on this test and if the p( bootstrapped Zork completion by AI models) - > p( doom) / p( utopia) logic rings true. I do at least think even the most dedicated and imaginative⏹️-ers (@AISafetyMemes) would concede that evil AGI induced bioweapons manufacturing in the real world is a greater challenge than getting high Zork scores in a narrower/defined world and is therefore at very least useful as a canary of goal-seeking AGI.]
The Zork test (nevermind about Zork-like test) fails miserably today, even with a full Zork walkthrough apparently in the GPT-4 training set. State of the art ML Zork score is about 50, and human unassisted GPT-4 is about 10 (arxiv.org/pdf/2304.02868.pdf, arxiv.org/pdf/2107.08408.pdf).
This shouldn't be too shocking, LLMs are missing a lot of key components like memory, self-reflection and the ability to take independent action without prompting, but on the other hand, an LLM seems to be the perfect "type" of model to be able to play text games.
I think the reason for the failure reduces to one of the key problems in AI research in general, that of out-of-distribution generalization. It's becoming clear (arxiv.org/abs/2312.16337) that even if large scale LLMs do have emergent abilities, that far more of their success is down to incredibly good generalization on the training set which at this point for GPT-4 is approaching "the entire set of written human knowledge (up until the training knowledge cutoff)".
So why can't LLMs play Zork, what's missing in training set and does that show potential paths forward?
I think that a lot of LLMs goal-directed weaknesses (even when placed in loops/pairs or "teams" and given in-context "memory" like @yoheinakajima's BabyAGI and AutoGPT) are due to the fact that pre-trained LLMs have "read" everything but they have "done" nothing. Their training on knowledge is deep but their first-hand training on taking action is non-existent.
Likely the biggest leap in capabilities on the language-side in the AI Spring came from RLHF which led to instruction tuned models. It seems like RL, without the HF is a good bet on the way forward, i.e. reinforcement learning, with environmental (not human) feedback happening online/actively as the model attempts to do something and gets feedback. If its possible for current stage LLMs to build a world model (a big if) it may come from a setup like this. (@ylecun has spoken about how embodiment is a likely needed for true human-level abilities).
If the above is true this seems to lead to another rule of thumb: a system (consisting of some number of AI models interacting) cannot be called an AGI unless it is able to dynamically update its own weights as it acts in a way that improves its later actions vs. prior actions without any human labeling or intervention (except as a part of the environment). This is because the real world will always contain out-of-distribution to text training data obstacles which no fixed weight model could overcome. Our brains do this in real-time, LLMs do not (today) at all.
It could also mean that "hallucinations" (and models that have baked in knowledge like LLMs) may actually have outsized value, they provide a form of knowledge directed exploration that can only be refined with environmental feedback on which ones are good (advance the overall goal) and which ones are bad (do not advance the overall goal).
This seems to complete the circle of why the Zork-Like test "works", why models fail it today and why current LLMs cannot be thought of as having any risk on goal-seeking without passing this test first.
In light of the above, I'll lay out my (almost certainly failed) path to moving forward the Zork-Like test and 2024 pet project (which will proceed extremely slowly, or potentially not at all, due to time and cost constraints).
1) Play a Python Zork reference (like github.com/KadenBiel/Python-…) multiple times to set a human baseline of total number of playthroughs allowed and score/move ratio (or find the same)
2) Take two 7B LLMs, one to be used as a policy/player model and one to be used as a reward model
3) Create a Zork environment that can interact with the policy and reward LLM
4) Use RL techniques like DPO/PPO and techniques borrowed from RLHF (but with no human labeling) to fine-tune both models as they play.
5) See if any "sparks" of generalization occur
Super interested in anyone's thoughts, holes in my logic, ways to add rigor or greater definition or interest in participating! Happy New Year all.
327
3 Jan 2024
Answering the question objectively and accurately of whether or not an AI model (or system of AI models) is independently and successfully goal-seeking seems of pretty key concern to ⏸️/⏹️-ers, ⏩-ers, people who believe we're close, people who believe we're far off and everyone in-between.
I'd like to propose a potentially useful AGI test called the "Zork-Like test".
What is Zork and why Zork-Like? Zork (en.wikipedia.org/wiki/Zork) is a text adventure game and a defined environment with an achievable goal that is not stated but needs to be discovered by the player, and conveniently also has a score that can be maximized and a score/turn ratio that can be measured.
It's the perfect "toy" test of human-level goal discovery, recognition and action in a simple simulated text-only environment accessible to LLMs. But we can't use Zork itself as there are walkthroughs of it in the training set, so the Zork-Like game is of similar complexity but with a different map and some different actions that don't make it into training sets, or can be recreated easily if one suspects it has.
Here's the Zork-Like Test: Before "using superhuman persuasion to build a bioweapon using human agents" or "inventing new physics and solving antibiotic resistance", an AI needs to be able to understand the goal of a Zork-Like game (not in the training set) and max out its Zork-Like score efficiently to human level without human feedback and only bootstrapping from interacting with the text environment.
[Side note: I'm curious on the thoughts of anyone including @sama, @ylecun, @roon, @emollick, and others in e/acc (@beffjezos) and Safety (@robertskmiles) circles on this test and if the p( bootstrapped Zork completion by AI models) - > p( doom) / p( utopia) logic rings true. I do at least think even the most dedicated and imaginative⏹️-ers (@AISafetyMemes) would concede that evil AGI induced bioweapons manufacturing in the real world is a greater challenge than getting high Zork scores in a narrower/defined world and is therefore at very least useful as a canary of goal-seeking AGI.]
The Zork test (nevermind about Zork-like test) fails miserably today, even with a full Zork walkthrough apparently in the GPT-4 training set. State of the art ML Zork score is about 50, and human unassisted GPT-4 is about 10 (arxiv.org/pdf/2304.02868.pdf, arxiv.org/pdf/2107.08408.pdf).
This shouldn't be too shocking, LLMs are missing a lot of key components like memory, self-reflection and the ability to take independent action without prompting, but on the other hand, an LLM seems to be the perfect "type" of model to be able to play text games.
I think the reason for the failure reduces to one of the key problems in AI research in general, that of out-of-distribution generalization. It's becoming clear (arxiv.org/abs/2312.16337) that even if large scale LLMs do have emergent abilities, that far more of their success is down to incredibly good generalization on the training set which at this point for GPT-4 is approaching "the entire set of written human knowledge (up until the training knowledge cutoff)".
So why can't LLMs play Zork, what's missing in training set and does that show potential paths forward?
I think that a lot of LLMs goal-directed weaknesses (even when placed in loops/pairs or "teams" and given in-context "memory" like @yoheinakajima's BabyAGI and AutoGPT) are due to the fact that pre-trained LLMs have "read" everything but they have "done" nothing. Their training on knowledge is deep but their first-hand training on taking action is non-existent.
Likely the biggest leap in capabilities on the language-side in the AI Spring came from RLHF which led to instruction tuned models. It seems like RL, without the HF is a good bet on the way forward, i.e. reinforcement learning, with environmental (not human) feedback happening online/actively as the model attempts to do something and gets feedback. If its possible for current stage LLMs to build a world model (a big if) it may come from a setup like this. (@ylecun has spoken about how embodiment is a likely needed for true human-level abilities).
If the above is true this seems to lead to another rule of thumb: a system (consisting of some number of AI models interacting) cannot be called an AGI unless it is able to dynamically update its own weights as it acts in a way that improves its later actions vs. prior actions without any human labeling or intervention (except as a part of the environment). This is because the real world will always contain out-of-distribution to text training data obstacles which no fixed weight model could overcome. Our brains do this in real-time, LLMs do not (today) at all.
It could also mean that "hallucinations" (and models that have baked in knowledge like LLMs) may actually have outsized value, they provide a form of knowledge directed exploration that can only be refined with environmental feedback on which ones are good (advance the overall goal) and which ones are bad (do not advance the overall goal).
This seems to complete the circle of why the Zork-Like test "works", why models fail it today and why current LLMs cannot be thought of as having any risk on goal-seeking without passing this test first.
In light of the above, I'll lay out my (almost certainly failed) path to moving forward the Zork-Like test and 2024 pet project (which will proceed extremely slowly, or potentially not at all, due to time and cost constraints).
1) Play a Python Zork reference (like github.com/KadenBiel/Python-…) multiple times to set a human baseline of total number of playthroughs allowed and score/move ratio (or find the same)
2) Take two 7B LLMs, one to be used as a policy/player model and one to be used as a reward model
3) Create a Zork environment that can interact with the policy and reward LLM
4) Use RL techniques like DPO/PPO and techniques borrowed from RLHF (but with no human labeling) to fine-tune both models as they play.
5) See if any "sparks" of generalization occur
Super interested in anyone's thoughts, holes in my logic, ways to add rigor or greater definition or interest in participating! Happy New Year all.
5
711
Rob Lynch retweeted

27 Dec 2023
Remember this XKCD comic from 2014?
What was “virtually impossible” back then is now accessible to anyone.

2
8
477
21 Dec 2023
Are @yoheinakajima’s BabyAGI and other paired loop LLM experiments like @SigGravitas Auto-GPT a precursor to truly agentic “conscious” AI?
Julian Jaynes might think so. In 1976, Jaynes wrote a book called “The Origin of Consciousness in the Breakdown of the Bicameral Mind".
Jaynes posited ancient humans operated under a 'bicameral' mind model, where one part 'spoke' and another obeyed, mimicking internal dialogue.
Jaynes theorized that the 'bicameral' structure in humans started as an external “voice of God” but over time this structure broke down and the instructing voice was internalized and evolved towards consciousness, where dialogues within became introspective, self-aware thoughts.
This theory intersects intriguingly with modern Large Language Models (LLMs) experiments like Auto-GPT and BabyAGI. Consider an LLM as an 'executor', processing and responding to inputs, paired with another as a 'critic' or 'instructor', guiding or evaluating responses.
We know that pairing LLMs in an executor-critic loop like this can lead to a very rudimentary form of 'agenticness' or self-guided operation.
As models scale and have modalities added, could such loops “breakdown” as Jaynes’ suggested where executor and critic roles transition over time towards autonomous, conscious-like behavior?
Ultimately, Jaynes theories are controversial and not broadly accepted but the parallels between a ‘bicameral’ mind and rudimentary agenticness in paired LLMs is intriguing at the least.
en.m.wikipedia.org/wiki/The_…
1
3
9
2,846
18 Dec 2023
Takeaways:
-- OpenAI's Ada embeddings can underperform open-source embeddings and are way more expensive
-- Embeddings capture so much information that even the simplest of models are able to do solid text/sentiment classification
-- Here's some code to compare embedding models for your task: github.com/robalynch1122/Com…
16 Dec 2023
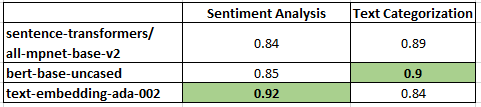
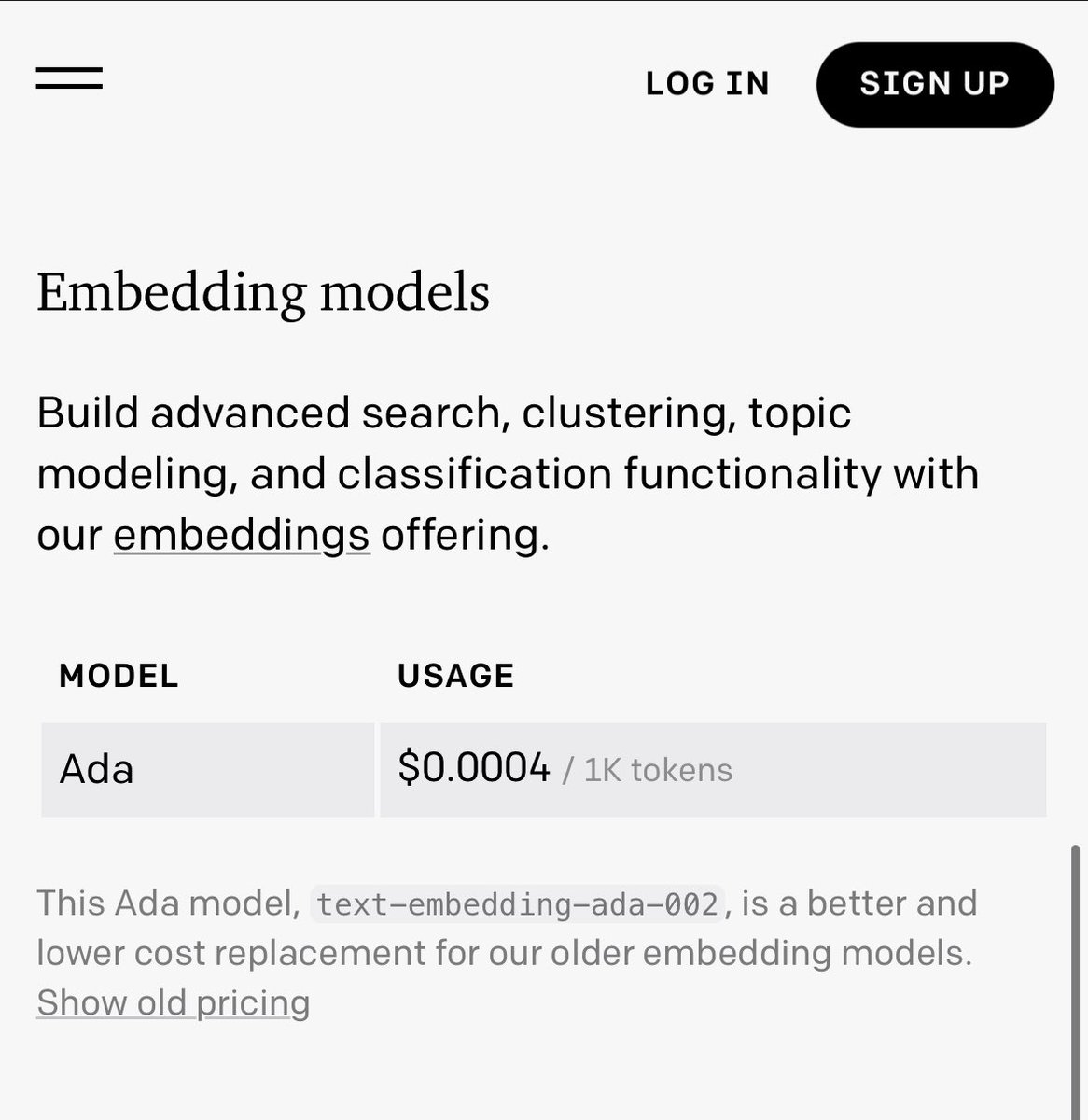
Embedding models are so good at capturing content and semantics of text that even a basic logistic regression model trained on them can get surprisingly good results on text classification and sentiment analysis tasks (saving the need for heavy model training and loading).
Even though a fine-tuned BERT model or LLM will likely exceed them, 90% f1-scores are totally achievable.
However, not all embedding models are created equal and OpenAI's Ada embeddings can underperform other fully open-source embeddings like BERT and Sentence Transformers (while being a lot more expensive).
Check out the performance of three embedding models on a text categorization and sentiment analysis task in the attached image.
Incidentally, experiments like these can be useful for quickly benchmarking different embedding models on categorization tasks so you can choose the best (not sure if this extends to other types of tasks like clustering). I included the code so you can benchmark and compare your own tasks quickly.
github.com/robalynch1122/Com…
1
3
744