
Joined October 2012
- Tweets 4,586
- Following 806
- Followers 1,405
- Likes 19,970
856 Photos and videos














Pinned Tweet

17 Apr 2023
If you're interested please do check out the game, it has been a really fun project for me, it's totally free and I hope you enjoy it, can't wait to hear what you think -)
buff.ly/3MPQajk
1
2
11
2,942
Robin Lord retweeted

5 Mar 2025
Want an easier way to handle GA4 BigQuery? We're launching Pipeline!
Enterprise level GA4 data in 15 minutes, with no SQL or data engineering.
Session level dimensions, multi touch attribution, Looker Studio connector. All ready to go.
2
1
5
1,180
4 Feb 2025
Excited to share a new game I've been working on!
In Divided We Fall you control an adorable bouncy cube as it takes on a perilous dungeon.
As you progress - your challenge is to create the levels for you to bounce across, using HTML & CSS skills you pick up
1
62
4 Feb 2025
If you're brand new to HTML and CSS - don't worry! There's a bunch of guidance, links to learn from, and the option to just take an answer if all else fails. If you're a seasoned pro - you can jump in and test your HTML skills in a brand new way.
1
36
4 Feb 2025
Really excited to hear what you all think of it! Go here to check out the game: divided-we-fall.therobinlord…
You'll need to be on something like a laptop to play, purely because this kind of thing would be too much of a pain to do on a small touch screen 😊
34
Robin Lord retweeted

20 Feb 2024
Great post for SEO's looking for an introduction to LLMs through the language of how SEO's look at information gathering, retrieval, etc by @RobinLord8.
moz.com/blog/know-about-llms…
1
1
5
317
14 Feb 2024
It has been SO useful to get an idea of how historic GA4 data might have looked, before it was live on site has been wildly useful. Here Dave is sharing a way to do it, free! Check it out!
14 Feb 2024

📊 New Post - How to backdate your GA4 analytics history before having GA4 tracking set up 📊
aira.net/blog/how-to-backdat…
2
360
28 Dec 2023
Jason has long been my go-to source for breaking down Google and Meta legal developments, particularly when it comes to things like tracking, looks like he'll be my go-to for OpenAI and LLM copyright law developments too!
27 Dec 2023

ok, I've now read the full NYT complaint filed this morning vs OpenAI and Microsoft. I'm impressed - it's future-focused around fair value for work vital to democracy. It also contains 220k pages of exhibits although the pages of Ex J stood out to me. more on that in a minute. /1

1
316
13 Dec 2023
I think this sentiment is important *but* it's worth bearing in mind that many consultants in agencies don't have say over what clients are sold and assigned to them and certainly can't fire them. Totally agree with what Tory says here in terms of fighting to educate
1
6
695
13 Dec 2023
A good friend of mine works for a large Airbnb competitor.
He told me that their biggest hiring challenge is SEOs often struggle with having *so* much free reign to make changes because so many are used to 90% of their time being spent on politics.
1
3
80
13 Dec 2023
I don't really have a point to wrap this up, other than - I'm not disagreeing with the underlying points being made 😊
1
69
10 Dec 2023
It's becoming a more and more common solution to inject recent data into short term memory (context window) as a way to fill in gaps in Large Language Model knowledge and paper over hallucination. Nice approach here, using Wikipedia as a database
9 Dec 2023

8/n That was the 4th reveal yesterday. The 5th reveal was work by Stanford to develop an architecture that leads to more factual LLMs. WikiChat uses Wikipedia and the following 7-stage pipeline to makes sure its responses are factual.
github.com/stanford-oval/Wik…
2
284
30 Nov 2023
Many are liking this because it casts their poor impulse control and hierarchy blindness as a social good rather than just a problem.
Well, that's why I liked it anyway.
30 Nov 2023

Every company needs 2-3 senior engineers who have fuck you money or just have 0 fear of getting fired.
Then when the architect or tech fellow or whoever unveil their new plan, those engineers unmute to say wtf is this, we're not moving everything into Lambda, are you high???
1
242
20 Nov 2023
Interesting summary of the drawbacks of building your own GPT-esque bot. It brushes over the fact that these things aren't all-or-nothing (you can augment GPT with your own data in a vector database) but even "just" RAG is a big data pipelining problem.
medium.com/@aldendorosario/l…
156
Robin Lord retweeted

11 Sep 2023
Another amazing example of "Everything is selection".*
This experiment is really neat, so let's go through it.
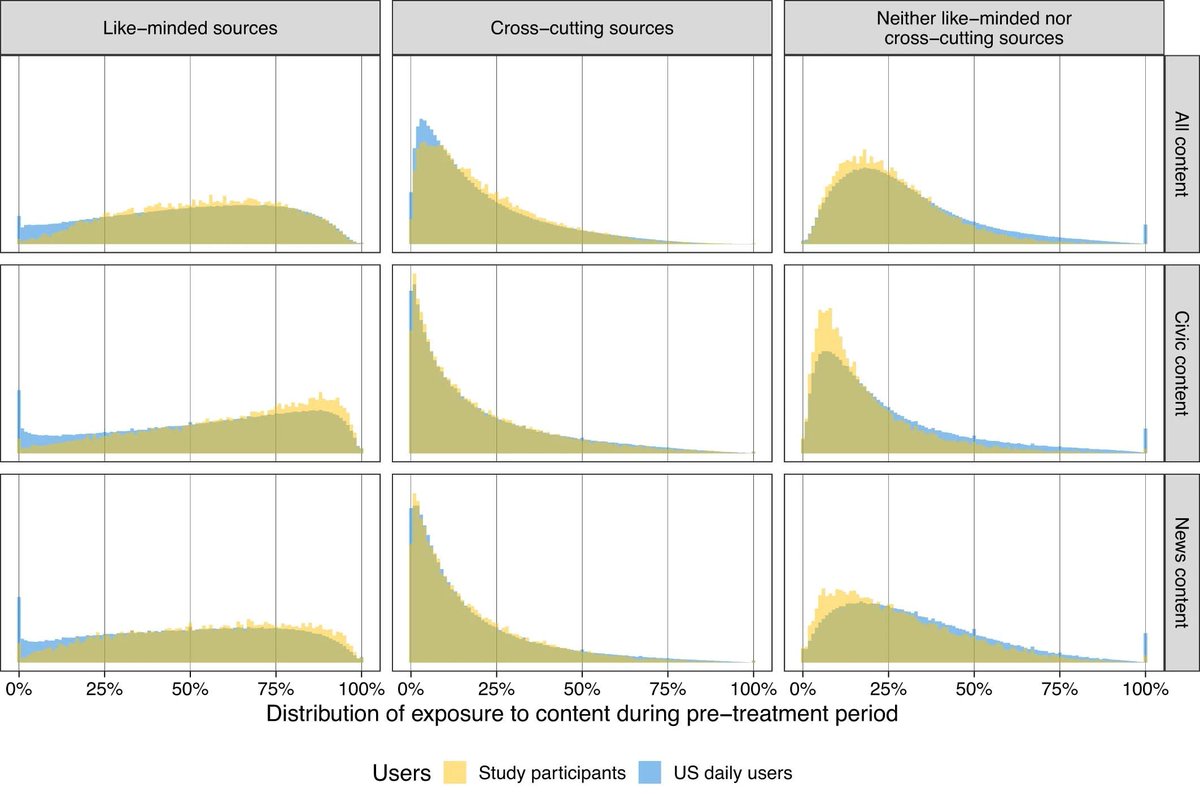
Facebook users are exposed to more like-minded than cross-cutting news sources. In yellow, you see how this looks for people who were enrolled in this study and in blue, you see daily users in general:
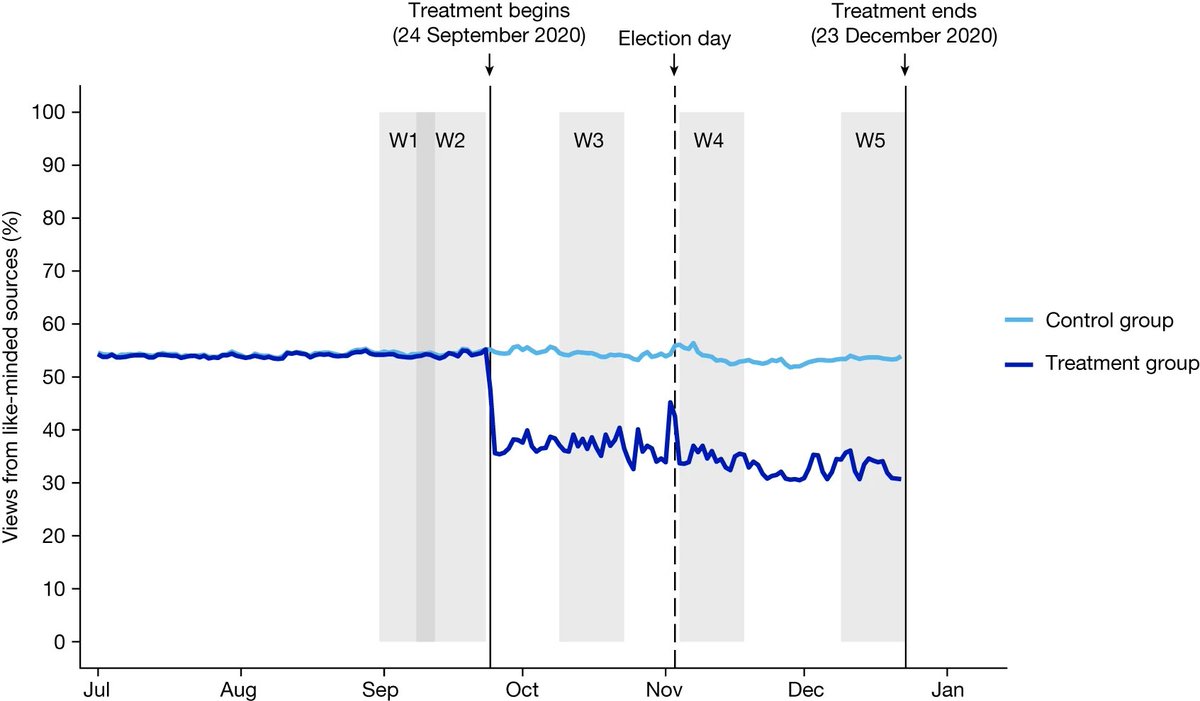
Researchers randomized blinded groups of people to a passive control condition or to receive more exposure from cross-cutting sources. The treatment worked at changing their exposures. Just look:
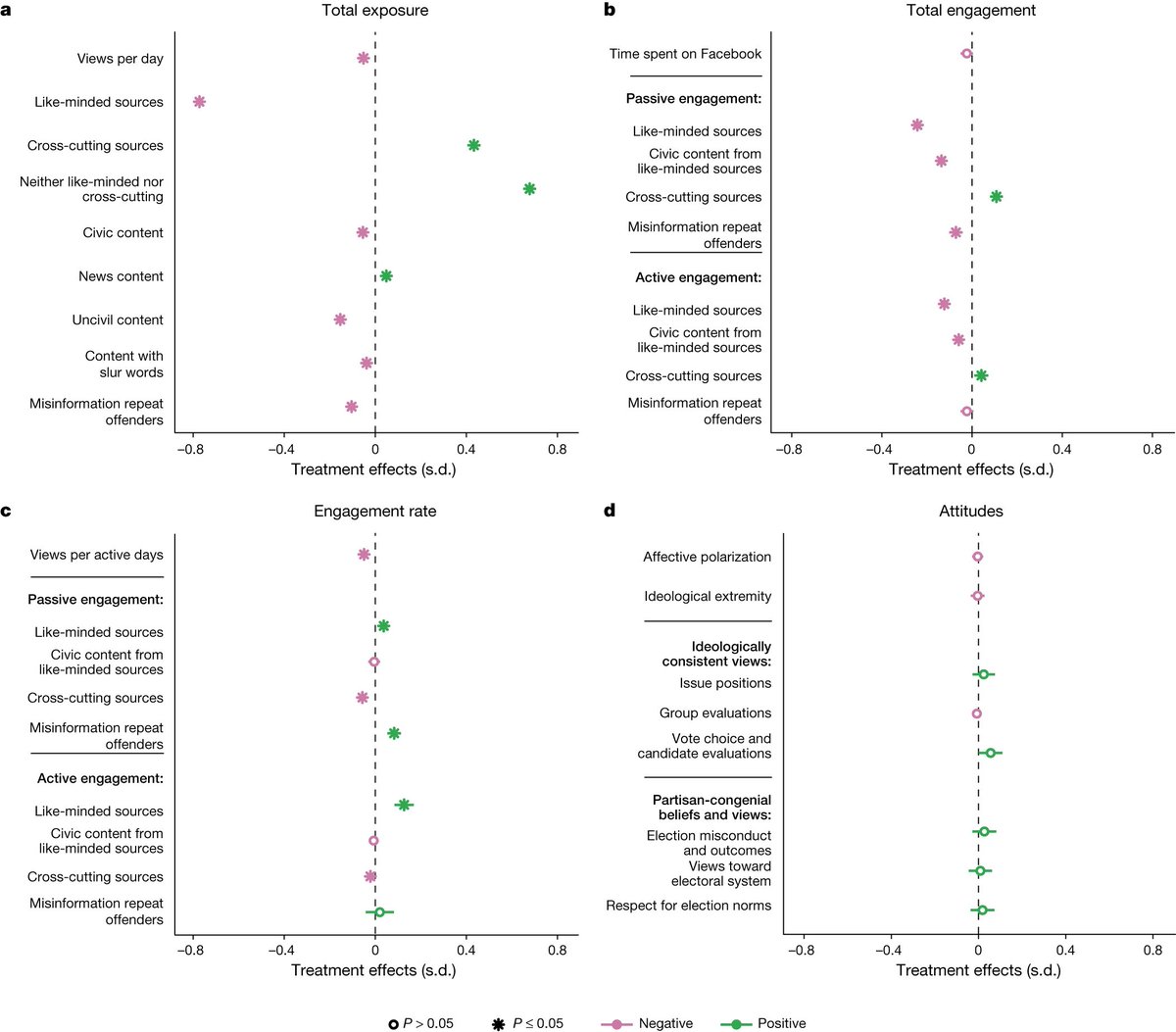
And then the researchers assessed people's attitudes later on and apparently nothing changed:
Strong attitude-news source exposure associations weren't causal, they were down to selection into the receipt of news sources. Receiving more cross-cutting ones just didn't seem to do all that much.
The researchers described the typical belief:
"Many observers share the view that Americans live in online echo chambers that polarize opinions on policy and deepen political divides. Some also argue that social media platforms can and should address this problem by reducing exposure to politically like-minded content. However, both these concerns and the proposed remedy are based on largely untested empirical assumptions."
But while "Participants in the treatment group were exposed to less content from like-minded sources but were actually more likely to engage with such content when they encountered it." it was also true that "reducing exposure to content from like-minded sources on Facebook had no measurable effect on a range of political attitudes, including affective polarization, ideological extremity and opinions on issues."
The researchers bounded the possible effect between ±0.12 SDs.
Public conversations often feature longwinded discussion of something like this that ends up being a reflection of selection. I assume that will be the case forever, because people appear to think things like social interactions and intuitively important exposures are vital to people's worldviews, even though they're probably not vital to their own.
Ask yourself this: would the generally left-leaning believers in the power of news exposure to change people's views find themselves transformed into right-wingers if they watched Fox News for an hour every day? Would the generally right-leaning believers in, say, QAnon, find themselves transformed into liberals if they watched MSNBC for an hour every day?
If you believe the answers are "yes", you still need to think about selection.
Source: nature.com/articles/s41586-0…
* More accurately, the majority of 'large' effects are selection.
11 Sep 2023

It would appear people are in echo chambers because they are polarized, not that they are polarized because they are in echo chambers.

9
36
252
86,150
10 Nov 2023
On Tuesday, OpenAI announced that GPT4.5 is able to handle MUCH more data at a time.
So, earlier this week, we put together a new tool for @airadigital's Utility Belt to make the most of that.
Tabs Summariser helps make data easier to understand, by giving top level insights
1
6
584
10 Nov 2023
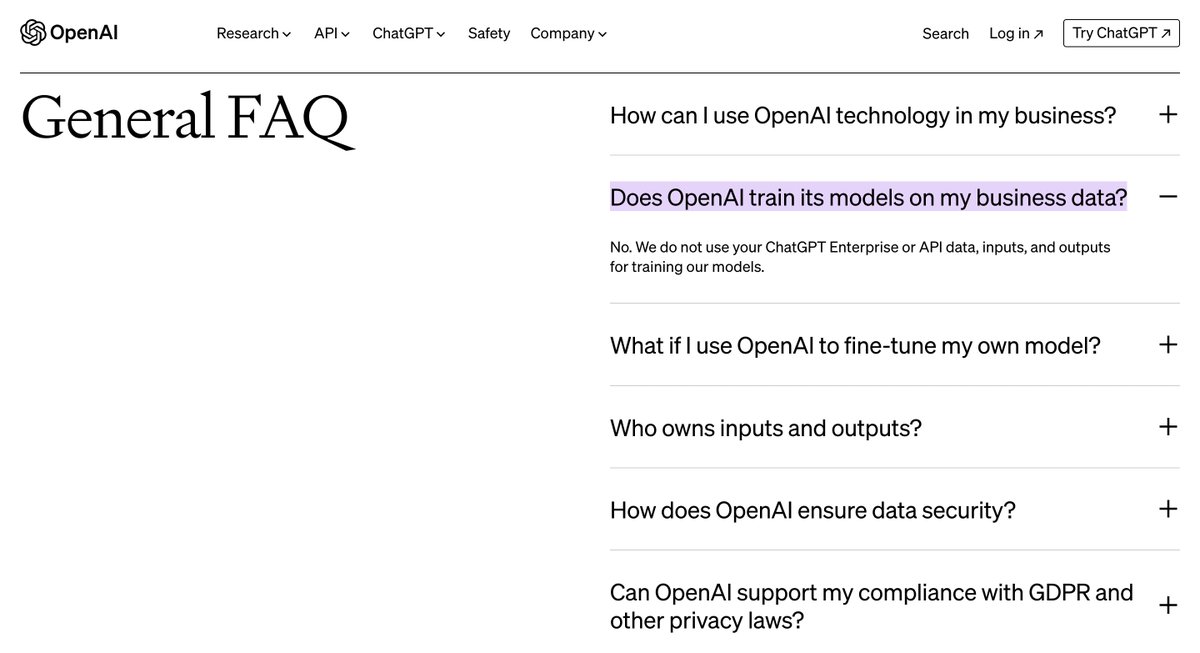
As a final note on data safety - if you're thinking of trying something like this, it's really worth doing it through the API.
While there are ways of turning off training in ChatGPT - OpenAI guarantee that API inputs and outputs won't be used to train models
1
80
10 Nov 2023
(Shout out to @dom_woodman for originally encouraging me to make summary tabs for sheets years ago. When I've done it I've often been glad, and when I've not bothered I've often regretted it!)
1
1
67