
Recording paper notes by @chongzzzhang who is interested in robot learning
Joined March 2024
- Tweets 512
- Following 1
- Followers 3,303
- Likes 14
312 Photos and videos










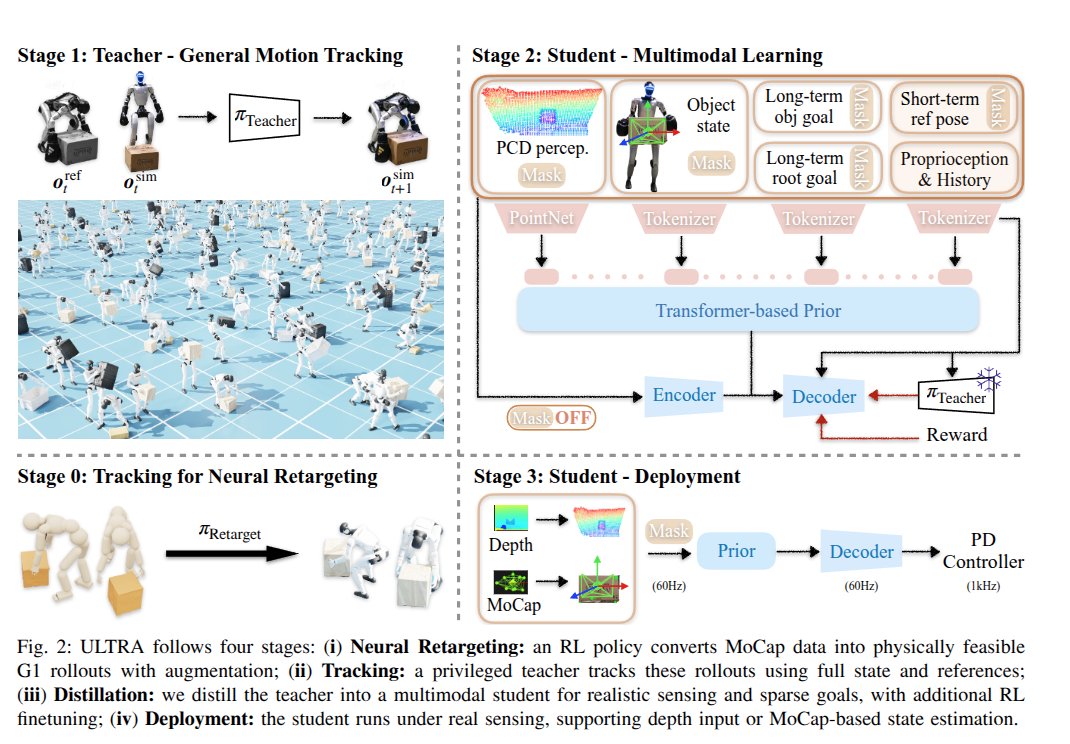
ULTRA: Unified Multimodal Control for Autonomous Humanoid Whole-Body Loco-Manipulation
arxiv.org/pdf/2603.03279
1. RL based retargetting
2. multi-modal command student distillation and finetuning so that it can switch between goal reaching vs reference tracking, mocap vs depth
9
30
2,026
HoMMI: Learning Whole-Body Mobile Manipulation from Human Demonstrations
arxiv.org/pdf/2603.03243
for cross-embodiement transfer:
1. use look-at points in 3D space instead of direct head states
2. mask out arms
8
36
1,947
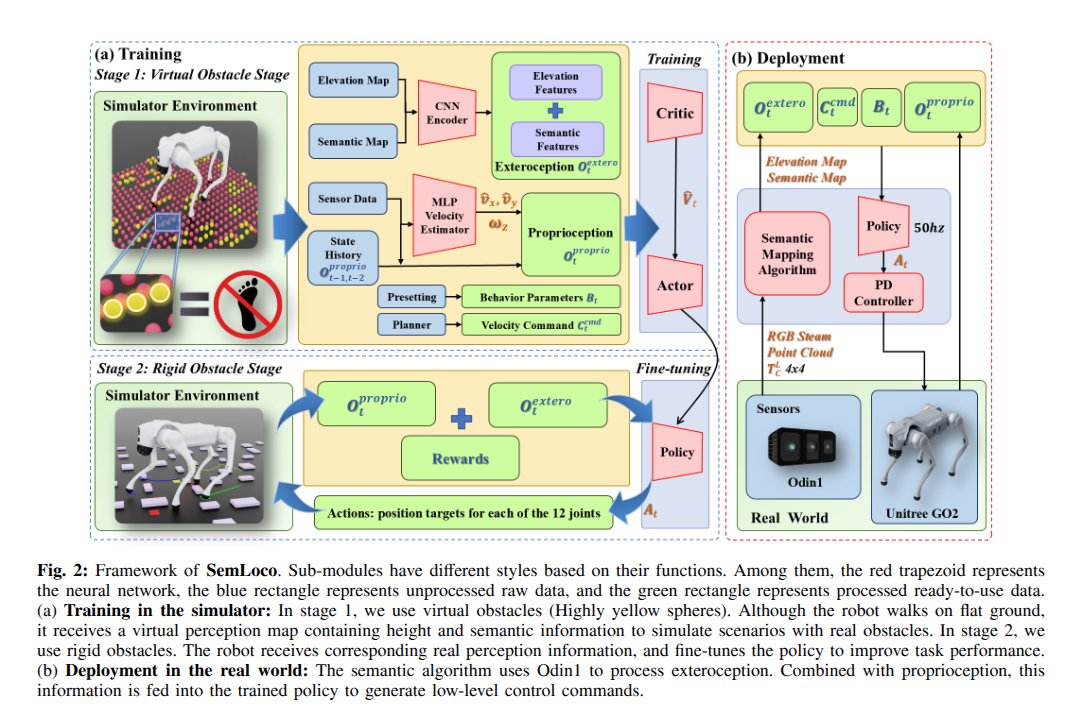
Watch Your Step: Learning Semantically-Guided Locomotion in Cluttered Environment
arxiv.org/pdf/2603.02657
this works shows you can train a policy plus using a semantic map to avoid stepping on valuable things.
this is why I believe locomotion should all be mapping based.
4
29
1,712
arxiv.org/pdf/2602.21723
LESSMIMIC: Long-Horizon Humanoid Interaction with Unified Distance Field Representations
use distance field (DF) as a representation for HOI. each link's traj can be defined by DF grad of DF vel_norm vel_tangent.
(tbc)
1
6
50
2,360
Training is multi stage. They first have a mimic policy and distill that to a base policy. Then they use AIP (AMP for interactions) to make the policy generalize instead of memorizing kinematic references.
DF needs mocap, so they also distill this into vision policies.
2
388
arxiv.org/pdf/2603.01126v1
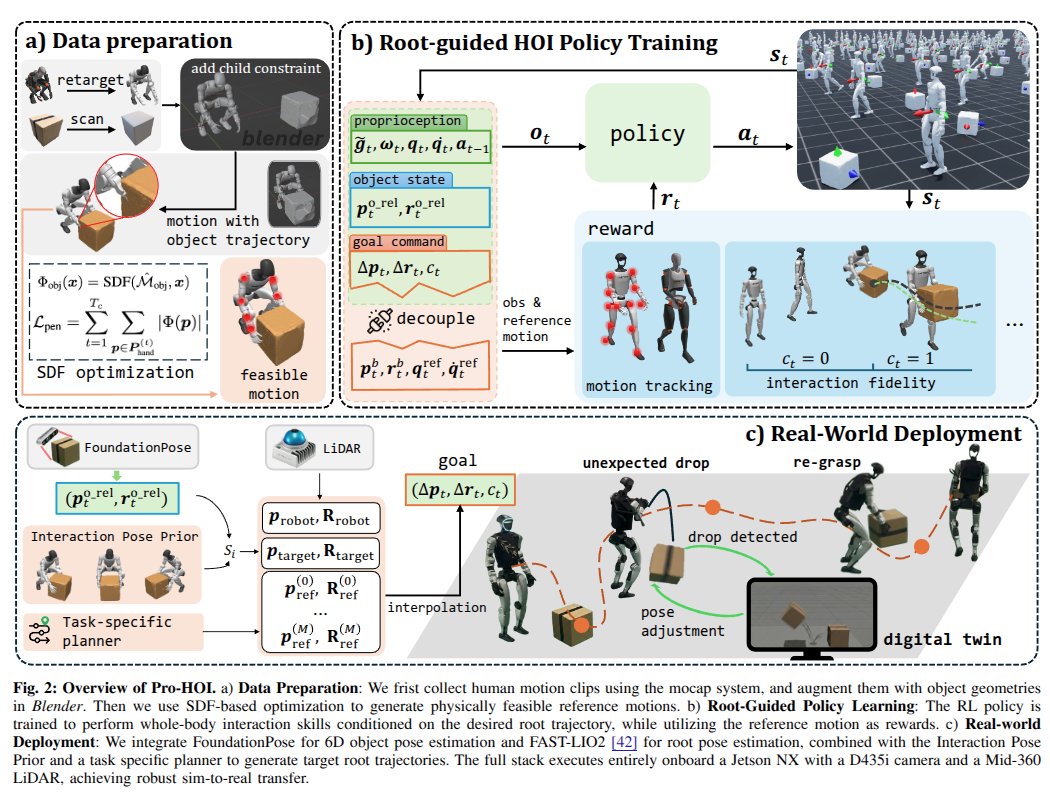
Pro-HOI: Perceptive Root-guided Humanoid-Object Interaction
trained with mimic contact commands, but deployed with planner to replace the reference.
4
57
2,535
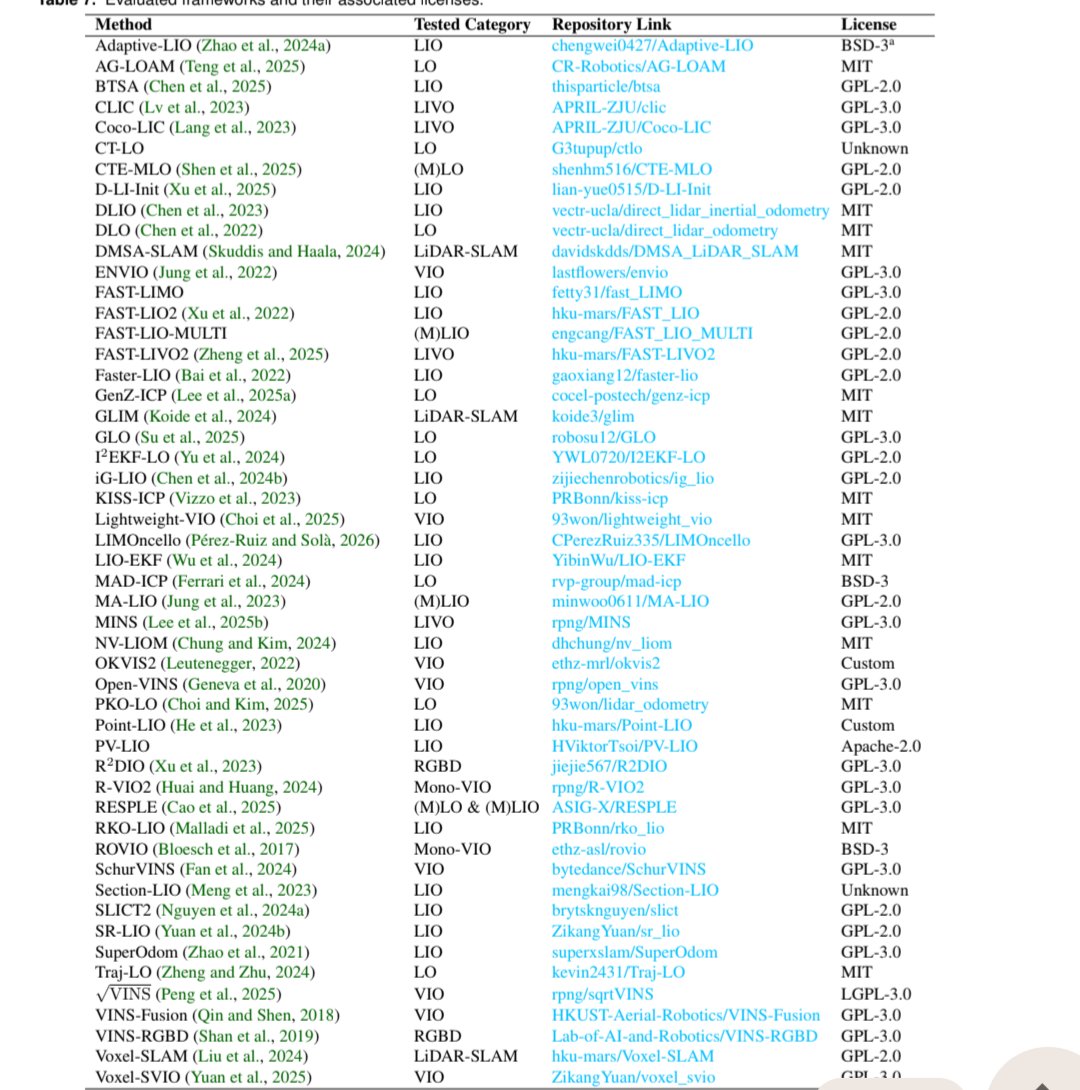
arxiv.org/pdf/2602.18164
The grandtour dataset, with tons of odometry methods benchmarked in tons of environments.

2
29
1,819
hero-humanoid.github.io/stat…
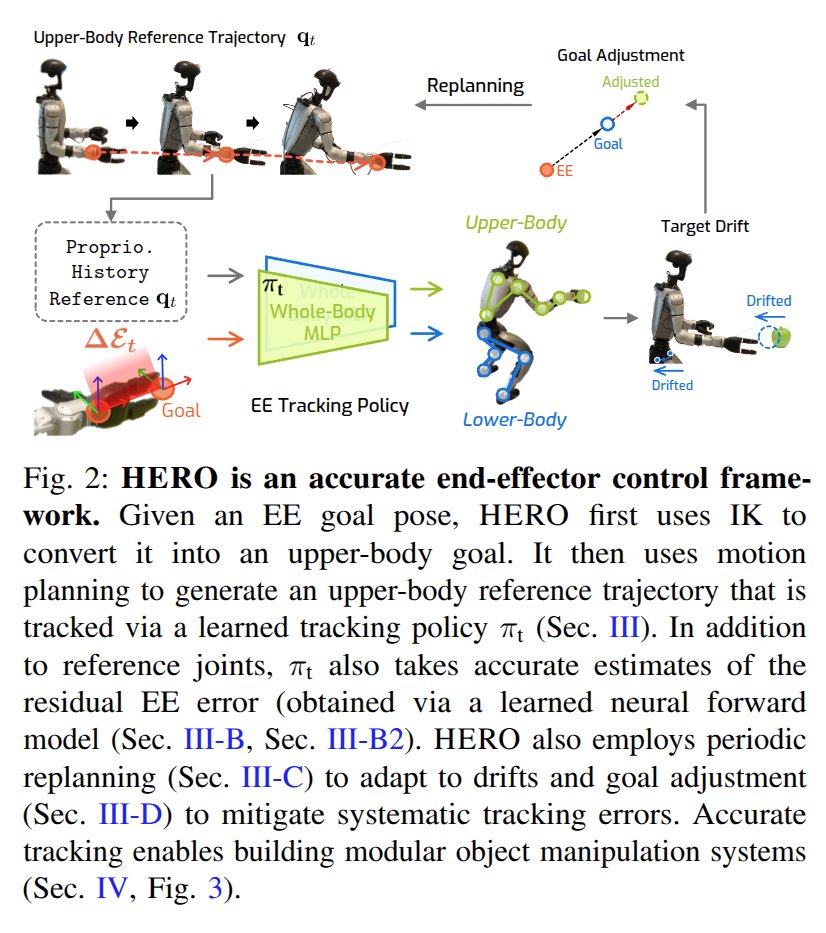
Learning Humanoid End-Effector Control for Open-Vocabulary Visual Loco-Manipulation
For humanoid EE goal reaching, on top of WBC pose tracking, a neural model is trained to further correct small biases near the goal.
1
9
53
2,605
VIGOR: Visual Goal-In-Context Inference for Unified Humanoid Fall Safety
arxiv.org/pdf/2602.16511
visual humanoid fall recovery
1) flat terrain human sparse reference
2) terrain-aware ref adjustment
3) keypoint tracking teacher
4) distilled to visual student without keypoint obs
3
17
1,374
arxiv.org/pdf/2602.15733v1
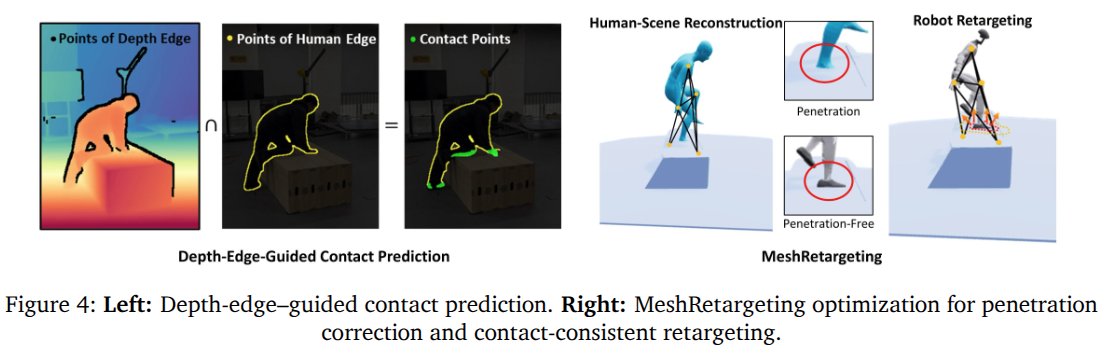
meshmimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction
kinda like CRISP OmniRetarget, but: 1) uses human edge and excludes depth edge in image to extract contacts, which is smart; 2) use polygonal primitives for clean scenes
11
79
4,651
arxiv.org/abs/2602.11758
Humanoid Agile Object Interaction Control via Dynamics-Aware World Model
predict object states from proprioceptive obs, use it to transform object template pointcloud, and embed the transformed pcl as policy inputs.
2
6
31
2,118
apex-humanoid.github.io/
reward engineering state machine engineering nice progress-based rewards for reference-free humanoid agile climbing learning.
1
11
65
10,823
arxiv.org/pdf/2602.07845
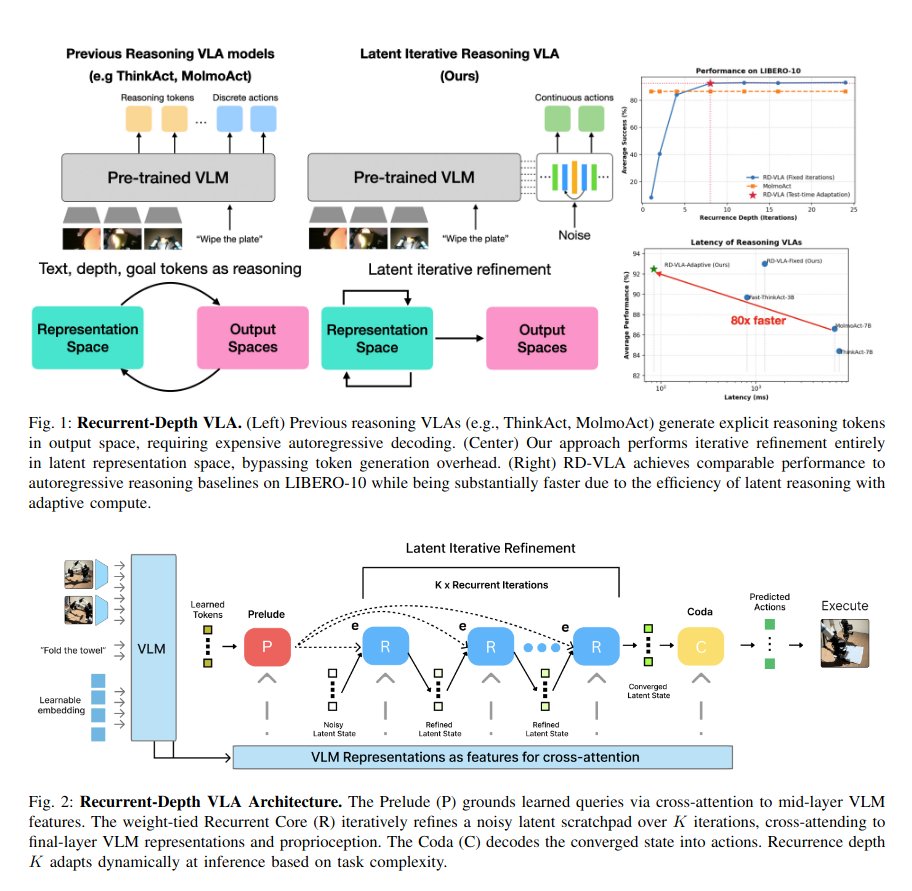
Recurrent-Depth VLA
Another way of VLM->diffusion or think-act model or whatever it is called; much faster and adaptive computation while reasoning in latent space.
12
57
2,950
arxiv.org/pdf/2602.07932
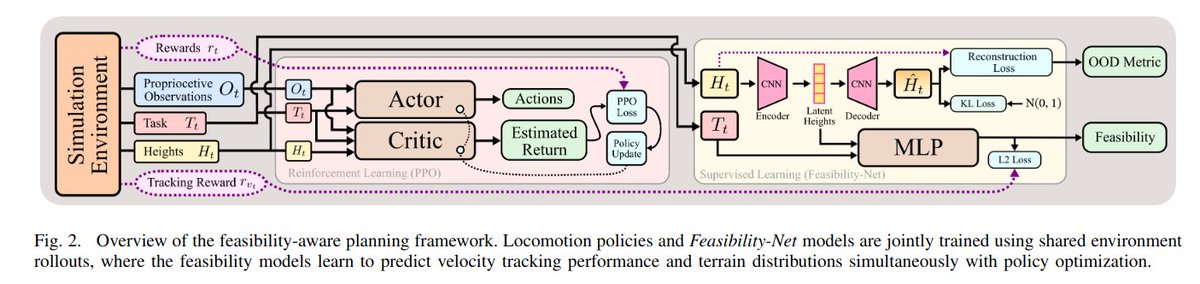
When predicting policy feasibility, can also use reconstruction header to detect OOD.
16
1,446
arxiv.org/pdf/2602.08370
humanoid badminton.
motion tracking -> distillation into goal-conditioned policies -> AMP and physics-based finetuning.
12
71
4,739
HUSKY: Humanoid Skateboarding System via Physics-Aware Whole-Body Control
1) models skateboard dynamics in simulation
2) phase-based design for multiple skills
3) human reference and kinematics-based guidance
4) sys-id sim2real
No perception yet
2
5
37
2,012
arxiv.org/pdf/2602.01067
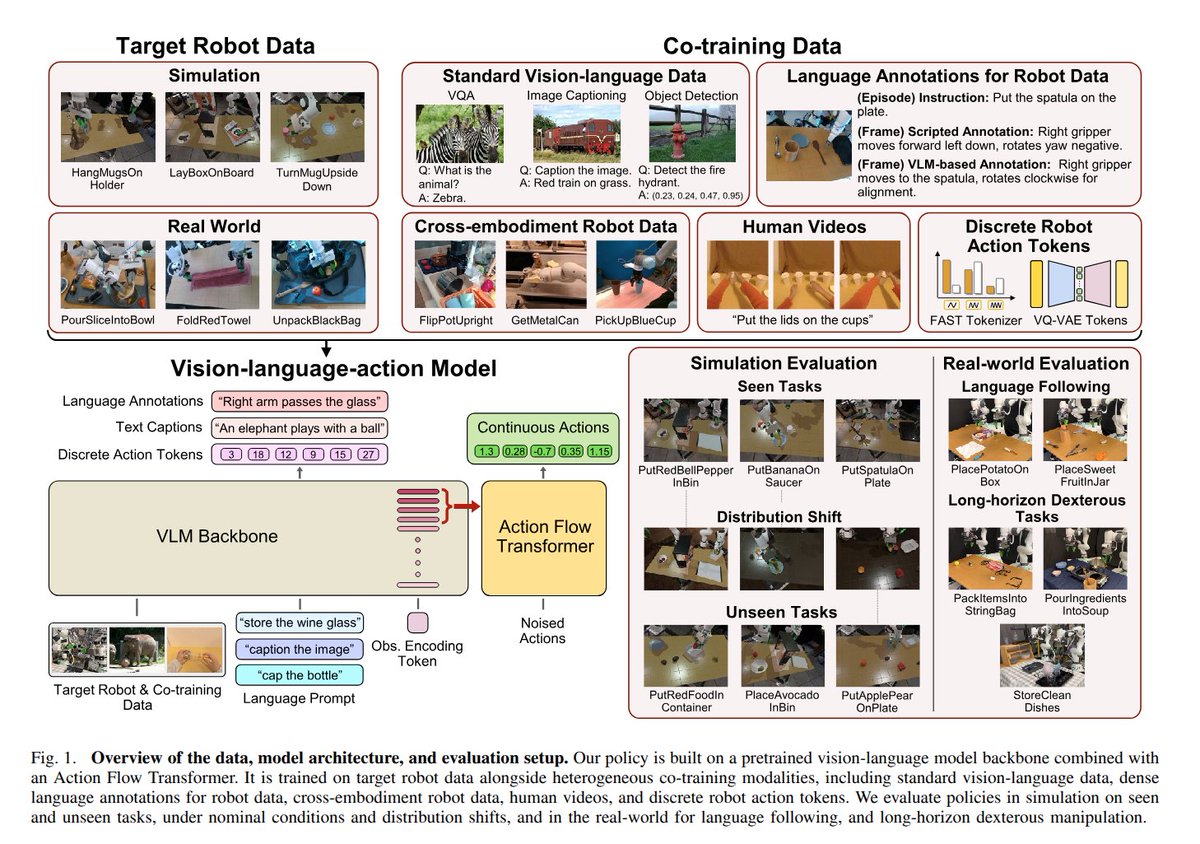
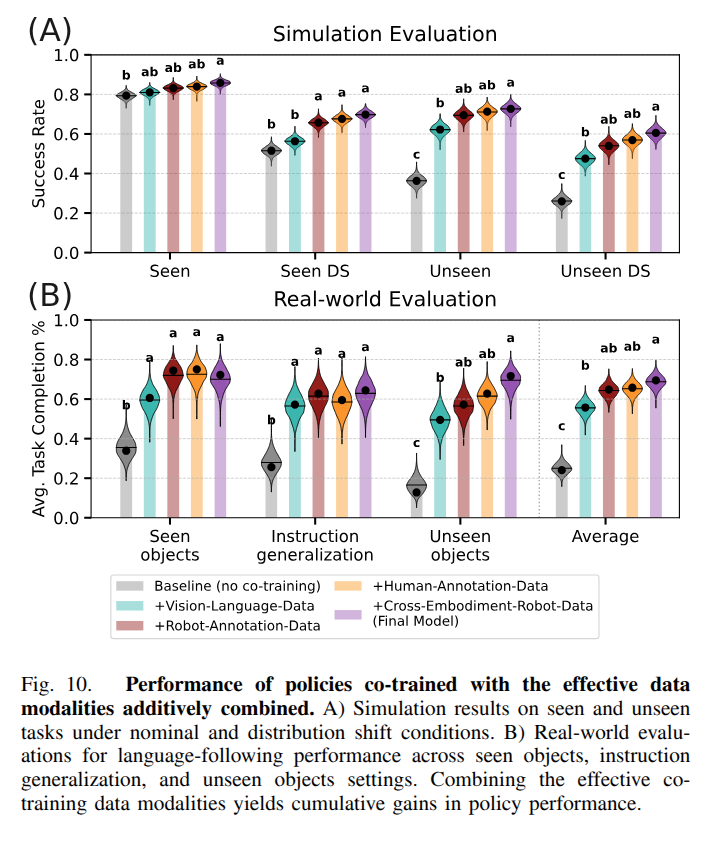
A Systematic Study of Data Modalities and Strategies for Co-training Large Behavior Models for Robot Manipulation
Another paper from TRI on how to train your VLA
3
15
1,778
arxiv.org/pdf/2602.00877
Learning When to Jump for Off-road Navigation
The traversability should be motion/velocity conditioned so that sometimes the car can jump. Amazing that such agile navigation is enabled by MPPI.


7
30
1,924