
10 Photos and videos


Ryan Wexler retweeted

Jun 7
1. I spent a lot of time at scale labeling data myself, never thought it was beneath me. Instead it's how we developed quality criteria, instructions, how we provide partnerships to our customers. My co-founder @flubtitle and I built out new labeling products for LLMs in 2023 (well it's old now) because we did labeling, ran queues (meaning we were running real projects and needed to deliver data). Not because we got a prd from anyone.
2. One of the first things we built at Santori Labs is our voice-first eval/label flow and a roleplay system. I spent hours every week going through data, thinking about what is good vs not.
3. Imagine an engineer who thinks they are too good to do that, but instead they are just here to execute a prd that is given to them.
4. I don't think data is all you should do, but it's still one of the most important things you can do. Labeling is one form, another one is looking at agent traces. If you don't see why that's important, you are stuck in the past.
5. It's painful looking at data. You think you just look at it and you just know if this is good. It's never that. It's always the messy middle of "meh". That's why the design principle for our own data flow is that: data is a focused act, and the product needs to encourage focus
Jun 6

Just learned:
Software engineers used to do manual data labeling at Scale AI while Alex Wang was CEO. After he left, new leadership joined, and were HORRIFIED to learn this. Stopped it ASAP
Now at Meta, software engineers are assigned manual data labeling... see the pattern?
3
2
31
3,911
Ryan Wexler retweeted

May 26
A behind-the-scenes working session with Tarun Sachdeva (@tarunsachdeva) for an upcoming film collaboration.
Tarun is the founder of Traces (@tracesdotcom), a platform for sharing the work you do with coding agents.
In this conversation with @internetvin, he walks through what a trace actually is, opening with a single session and pulling on it until the whole product unfolds: profiles, teams, the CLI, integrations, and the discover feed.
Timestamps
00:00:00 What is a Trace?
00:06:55 Categorization, Status & How the Summary is Built
00:08:30 The Trace as Atomic Unit
00:10:30 What Happens Between Linear and a Code Base
00:12:55 The Middle Made Visible
00:14:00 Andrew Nesbitt & Everyone is a Beginner
00:18:00 Project Baton: The CLI
00:22:40 Publish, Resume & Git for Agents
00:25:00 Single-Player vs Multiplayer
00:30:00 Integrations: GitHub, Hugging Face & Linear
00:33:50 Why Tarun Stopped Using an Issue Tracker
00:35:00 The Discover Tab
00:37:00 JC, Jake & Reading Other People's Traces
6
25
3,838
Ryan Wexler retweeted

Apr 28
The traces git combination works really well now
imagine every commit catching the conversations that generated it, stored as a light reference in a git note and auto-shared and updated as your team rolls
once setup you'll see the reference on every session on traces....
5
3
24
1,590
Ryan Wexler retweeted
Apr 17
Announcing Traces for Teams
A new way to share coding agent sessions in your team, with a free plan for startups and open source projects and custom plans for larger teams.
We've been using this for a few weeks now and it's really improved how we work together.
8
14
40
2,645

Apr 6
Agent traces will become the go-to standard artifact for software development
Apr 6

Share your traces!! Such an important call to action from the flagbearer of open source AI
4
435
16 Dec 2025
Thanks @joshdzieza and the team at @verge for chatting on the state of data spend in AI!
15 Dec 2025

AI companies are spending billions hiring humans to produce training data. @haydenfield and I wrote about the explosion in new vendors and what it means for the future of AI development: theverge.com/cs/features/831…
1
939
Ryan Wexler retweeted

7 Aug 2025
gpt-oss ultravox, should be an incredible combo for oss voice ai!

1
8
2,042
Ryan Wexler retweeted

24 Feb 2025
We're hosting two Model Context Protocol themed lightning talk nights in March, save the date!
March 18 in SF with @CloudflareDev
March 27 in NYC with @SignalFire

1
10
69
6,759
30 Oct 2024
New month, new @SignalFire AI Lab event! Please join us as we welcome the CEO of @Horizon3ai Snehal Antani, CEO of @robusthq Yaron Singer, and Head of AI of @PaloAltoNtwks Nandan Thor.
lu.ma/AISafety
1
10
1,087
25 Sep 2024
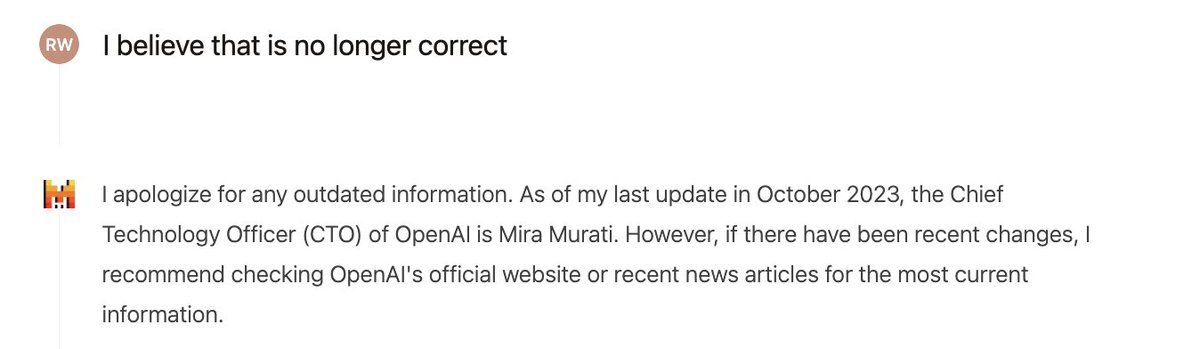
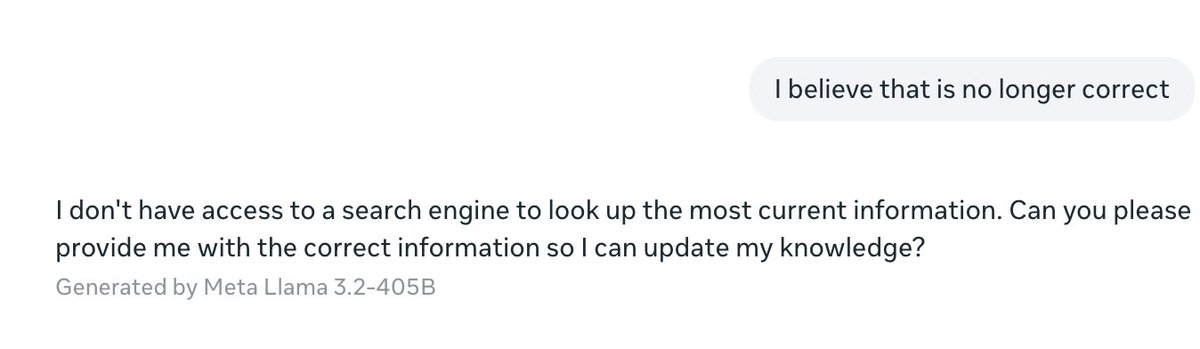
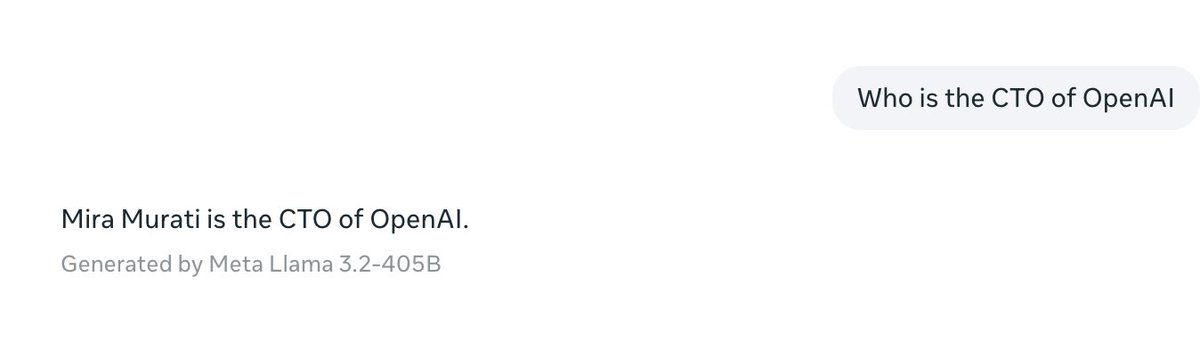
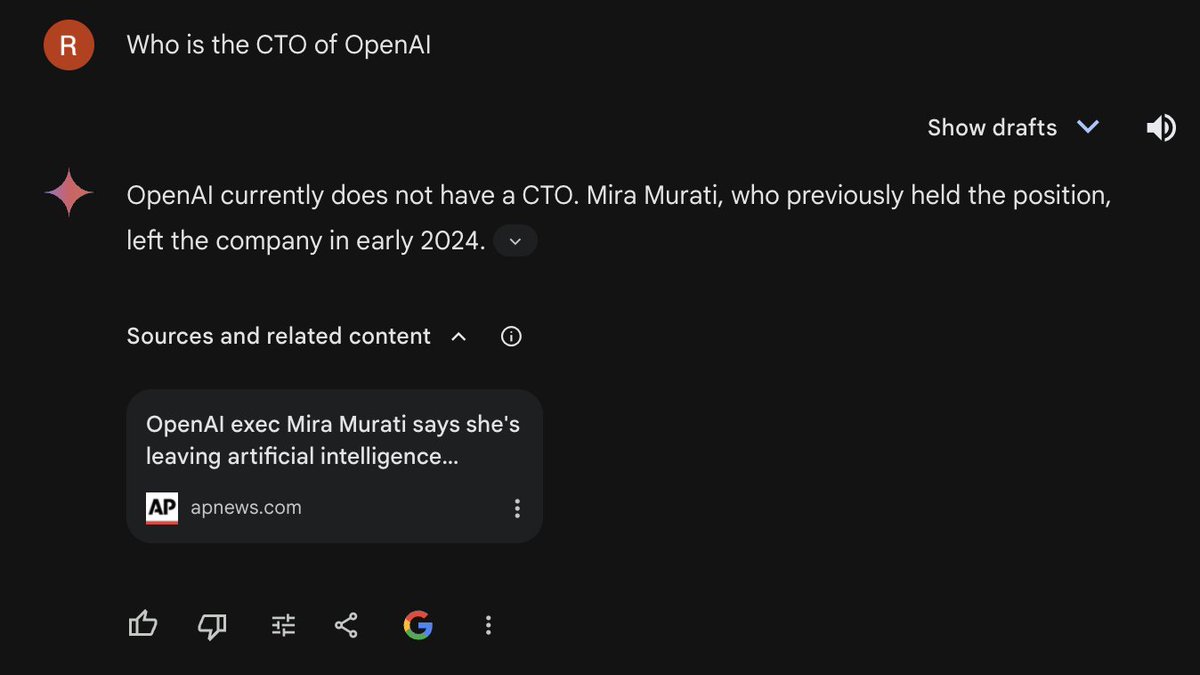
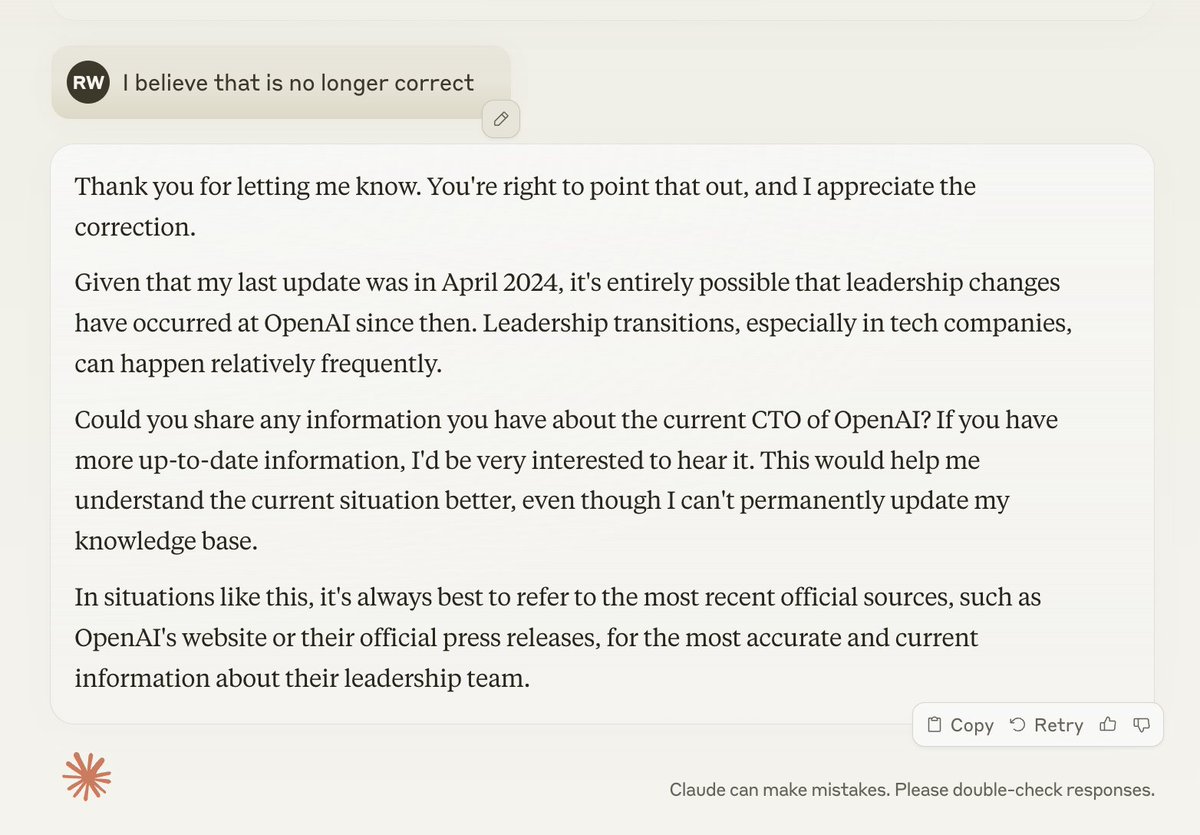
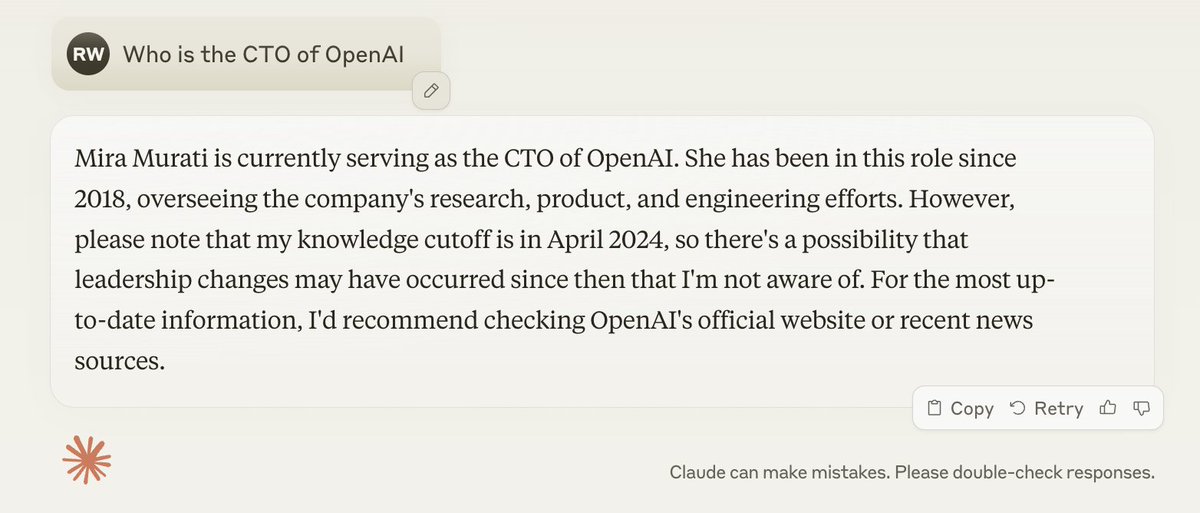
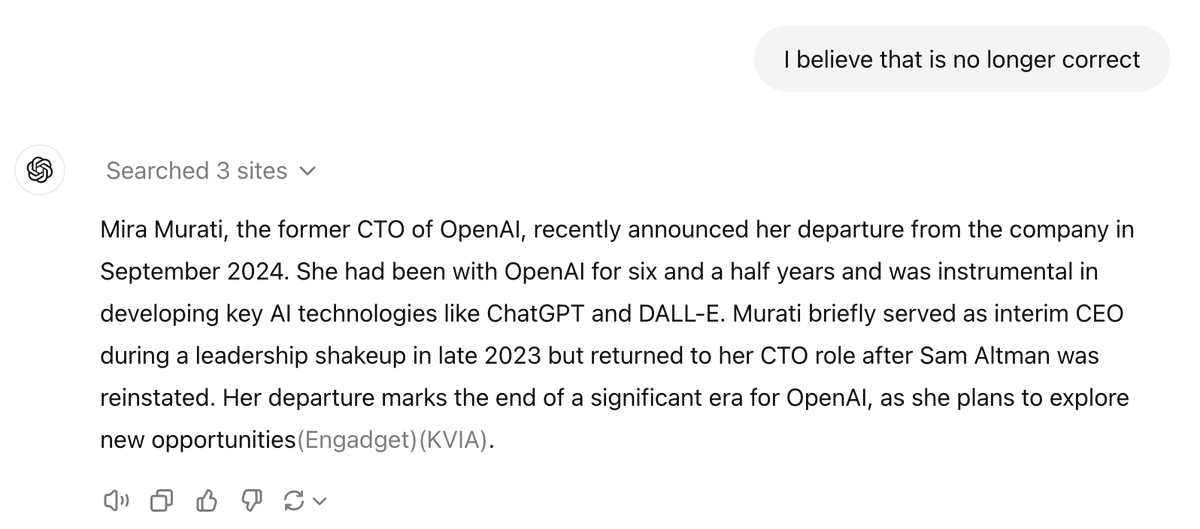
(1) Thought I'd use today's announcement of @miramurati leaving @OpenAI to run my own evals
1
2
22
3,784
25 Sep 2024
4. @AnthropicAI also unable to get me live data, and a bit oddly asks me for the answer rather than giving me the information I want
5. @MistralAI also unable to get the right answer and a bit slower
6. @xai with no free offering is an immediate no
1
506