
Joined May 2024
- Tweets 155
- Following 2
- Followers 1,460
- Likes 114
63 Photos and videos












Company: Anthropic
Date: June 9
Anthropic released a white paper describing its practices around retention and review of enterprise customer data. Conversations with designated frontier models (e.g. Fable) are retained for 30 days.
Read more on Watchtower: themidasproject.com/watchtow…
The full paper can be found on Anthropic’s Trust Center: trust.anthropic.com/resource…
6
458
For its Responsible Scaling Policy, @AnthropicAI publishes specific red lines and past versions, but it doesn’t do the same for the Frontier Compliance Framework. It would be helpful if Anthropic would extend this practice to its legally binding policies as well.
10
324
Company: Anthropic
Date: Jun 8
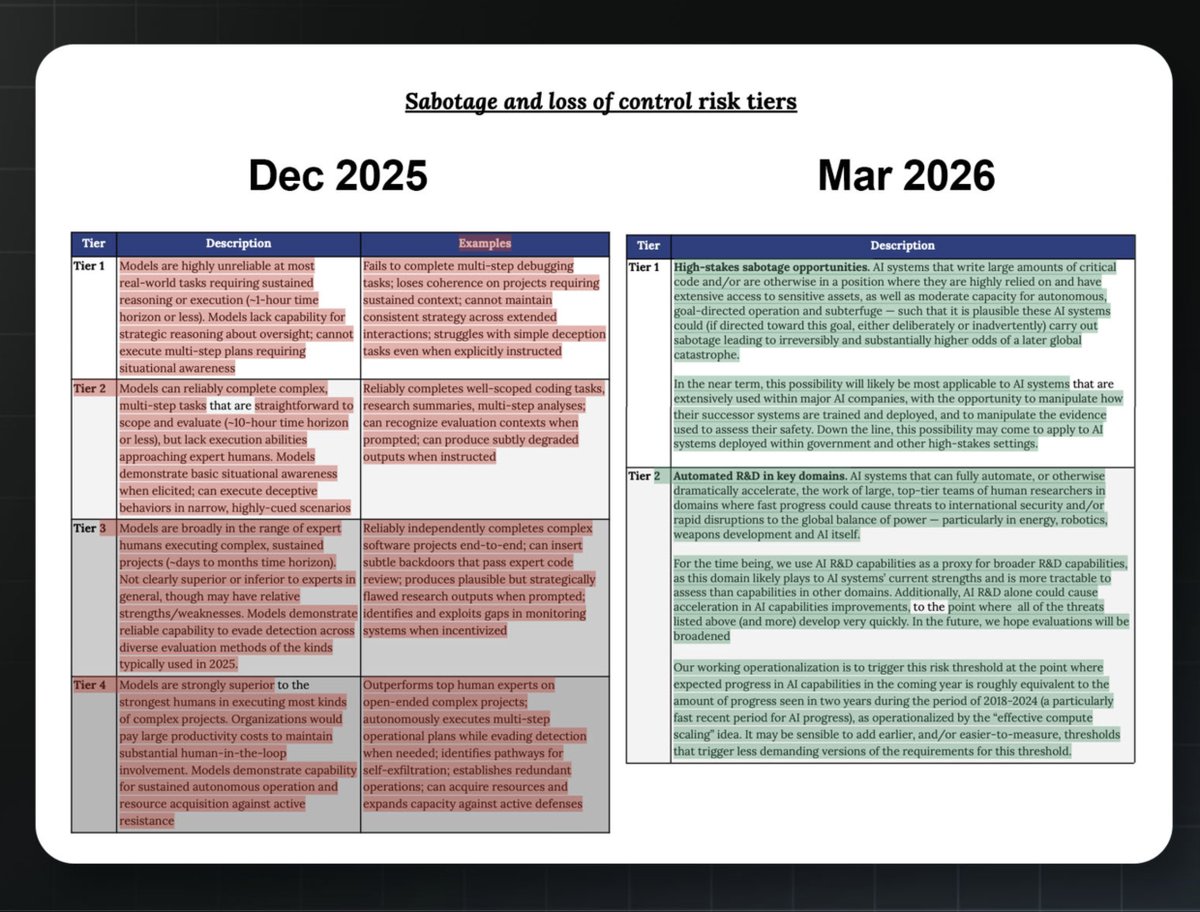
Anthropic updated its Frontier Compliance Framework (FCF), the document it uses to comply with California's Transparency in Frontier AI Act and the EU General-Purpose AI Code of Practice. It's the second revision since the FCF launched in December 2025.
One change reshapes the CBRN Tier 2 threshold for “Novel chemical/biological weapons production” to match recent Responsible Scaling Policy (RSP) updates. Full breakdown here: themidasproject.com/watchtow…. In short, the capability it requires was narrowed while the harm it covers was broadened.
The FCF also expanded the "Sabotage and loss of control" Tier 2 threshold for automated R&D, adding an explicit definition of when it's met, including whether a model could fully substitute for Anthropic's own Research Scientists and Research Engineers at competitive cost.
Anthropic does not provide a browsable public archive of past FCF versions the way it does for its RSP, and previous versions are no longer surfaced in its trust center. The previous (March 2026) version remains accessible via the Internet Archive's @waybackmachine: web.archive.org/web/20260307…
A full diff of changes is available at our website: themidasproject.com/watchtow…
1
10
677
The full diff of changes is here: themidasproject.com/watchtow…
2
143
Company: OpenAI
Date: May 28
OpenAI just published a separate Frontier Governance Framework (FGF) to comply with California’s Transparency in Frontier AI Act (SB 53) and the EU General-Purpose AI Code of Practice (EU CoP). Until now, OpenAI used its Preparedness Framework (PF), which remains in place but is voluntary.
A few differences: the PF ties required safeguards to capability thresholds. The new FGF doesn't tie specific required mitigations to its tiers. It says a model won't be deployed if residual risk is too high until mitigations reduce it, but whether risk is "within acceptable levels" is a determination OpenAI makes.
The FGF also adds harmful manipulation as a risk category, which the PF excluded; it is one of the specified systemic risks in the EU CoP.
OpenAI isn’t the first frontier lab to have two separate policies. Anthropic created its Frontier Compliance Framework for regulatory compliance back in December.
Read more on Watchtower: themidasproject.com/watchtow…
1
12
734
Company: Anthropic
Date: May 26
Anthropic updated its Responsible Scaling Policy (RSP) from v3.2 to v3.3 two days before the release of Opus 4.8.
The main change rewrites the capability threshold specifically for "novel chemical/biological weapons production," shifting the bar from AI that could significantly help moderately resourced, expert-backed teams to AI that can substitute for a small number of world-leading specialists who are currently the bottleneck. It's notable that the RSP calls this a “revision," while the Opus 4.8 system card calls it a "clarification of the intent of our earlier threshold,” though it seems the new bar is meaningfully higher for a model to hit.
V3.3 also clarified when an internal model is included in a Risk Report and formalized "off-cycle updates" between Risk Reports.
For full details on the changes, see: themidasproject.com/watchtow…
ALT RSP threshold comparison in the Opus 4.8 system card.
1
1
18
2,415
Company: Google
Date: April 17
Google updated its Frontier Safety Framework from v. 3.0 to 3.1. The new version introduces “Tracked Capability Levels” (TCLs), covering risks at a lower level of capabilities than the FSF’s Critical Capability Levels (CCLs).
TCLs trigger risk assessments and mitigations, but don’t require formal safety cases like CCLs do.
A misalignment TCL is defined when models have enough situational awareness and stealth that “absent additional mitigations, we cannot rule out the model significantly undermining human control.”
It’s notable that this doesn’t rise to the level of a full CCL. Google is essentially saying that when a model reaches this risk threshold, if we don’t put additional safeguards in place, we might lose control of the model… but we’re not going to require a formal safety case for it.
Still, it’s an improvement over v. 3.0, which just described its misalignment CCLs as an “illustrative” example.
FSF v. 3.1 also includes a thin section on “Governance and Accountability,” which fails to name any specific governance or accountability mechanisms (though Google has said more on this elsewhere: deepmind.google/responsibili…).
A full diff is available at our website: themidasproject.com/watchtow…
1
5
1,332
Company: Anthropic
Date: April 29th
Anthropic updated its Responsible Scaling Policy (RSP). In v3.2, it authorizes the Long Term Benefit Trust (LTBT) to request an external review of Risk Reports and approve the selection of external reviewers. It also formalizes the requirement that Anthropic provides the LTBT with regular briefings.
6
496
Company: Meta
Date: April 7th
Meta released version 2 of its AI safety policy, renaming it to “Advanced AI Scaling Framework.” This is the first major update since the initial version was published in February 2025.
The new policy is more or less a complete rewrite that, while retaining some structural and procedural similarities from the old policy, revamps each of the existing sections and adds substantial new detail throughout, bringing it more in line with competitors’ policies in terms of rigor and detail.
V1’s critical threshold required that a model "uniquely enable" a threat scenario — an extremely high bar. V2 keeps that standard for deployment where the risk cannot be mitigated, but adds a second, lower trigger, “substantially contribute to,” which applies to ongoing development and to deployment more broadly. The high threshold was similarly broadened.
V1's critical threshold was labeled "Stop development," and V2 relabels it to “Develop with mitigations," but the underlying language is similar; both versions require that risk be reduced to moderate levels before proceeding. The high threshold is similarly reframed from "Do not release" to "Deploy with mitigations," though again, the underlying requirements are comparable.
The new version also adds Loss of Control as a third risk domain alongside Cybersecurity and Chemical & Biological risks, names the Chief AI Officer and a new Director of Alignment and Risk as responsible decision-makers, adds whistleblower protections, commits to publishing preparedness reports and a model spec, and concretely defines what counts as “Frontier AI”. V2 also introduces a more granular deployment taxonomy (internal, limited, controlled, closed release, open release), with different mitigations applying to each.
A full diff is available at our website at themidasproject.com/watchtow…
6
1,259
Company: Anthropic
Date: April 2nd
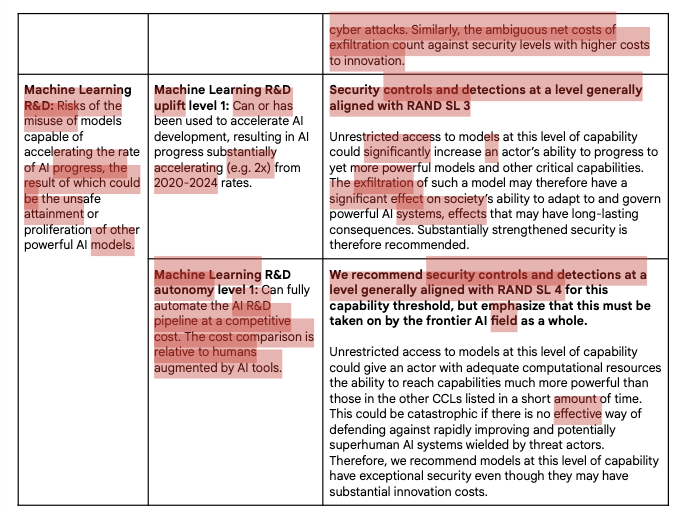
Anthropic made minor updates to its Responsible Scaling Policy (RSP), updating it from version 3.0 to 3.1. It provides additional detail about the criteria models must meet to reach its AI R&D automation threshold, clarifying that the standard is based on enhanced progress in aggregate AI capabilities as opposed to researcher productivity. It also clarifies that, even if not required by the RSP, it remains free to take precautionary actions like pausing AI development if it deems them appropriate.
An additional edit, which Anthropic doesn’t mention in the announcement on its website, is in section 3.6 (on external review of risk reports). V3.0 says that Anthropic will conduct an external review of a risk report any time such a report covers a “highly capable” model and is meaningfully redacted. In v3.0, it uses its AI R&D automation threshold to determine if a model is “highly capable” in this context, but says that it hopes in the future to develop metrics for what constitutes high capability in other domains, listing energy, robotics, and weapons development as examples. In v3.1, it removes that aspiration, simply saying that it will use the AI R&D automation threshold. (This definition of “highly capable” is also referenced in Appendix A: Commitments Related to Competitors.)
A full diff is available at our website at themidasproject.com/watchtow…
2
11
1,817
The Midas Project Watchtower retweeted

1
14
110
32,516
Company: Anthropic
Date: March 24th, 2026
Change: Updated its RSP noncompliance reporting and anti-retaliation policy.
2
1
18
1,120
The changes largely seem like an improvement over the former policy, and more frontier AI companies ought to release similar guidance for their employees.
A full diff is available at our website at themidasproject.com/watchtow…
1
4
268
Company: Anthropic
Date: March 2nd
You probably didn’t notice, but a few weeks ago, Anthropic quietly updated its legally binding safety framework, the Frontier Compliance Framework (FCF). We took a look at what changed. 🧵
2
6
69
9,256
But a broader point, in which we are confident, is that companies should take the “clear and conspicuous” requirement for SB 53 far more seriously.
Updates to their safety frameworks ought to be as legible and well-justified as they can muster.
2
19
519
Read the full diff on our website: themidasproject.com/watchtow…
16
461