
Sculpting, AI, Philosophy, Coding
Joined November 2020
- Tweets 757
- Following 150
- Followers 254
- Likes 17,884
26 Photos and videos

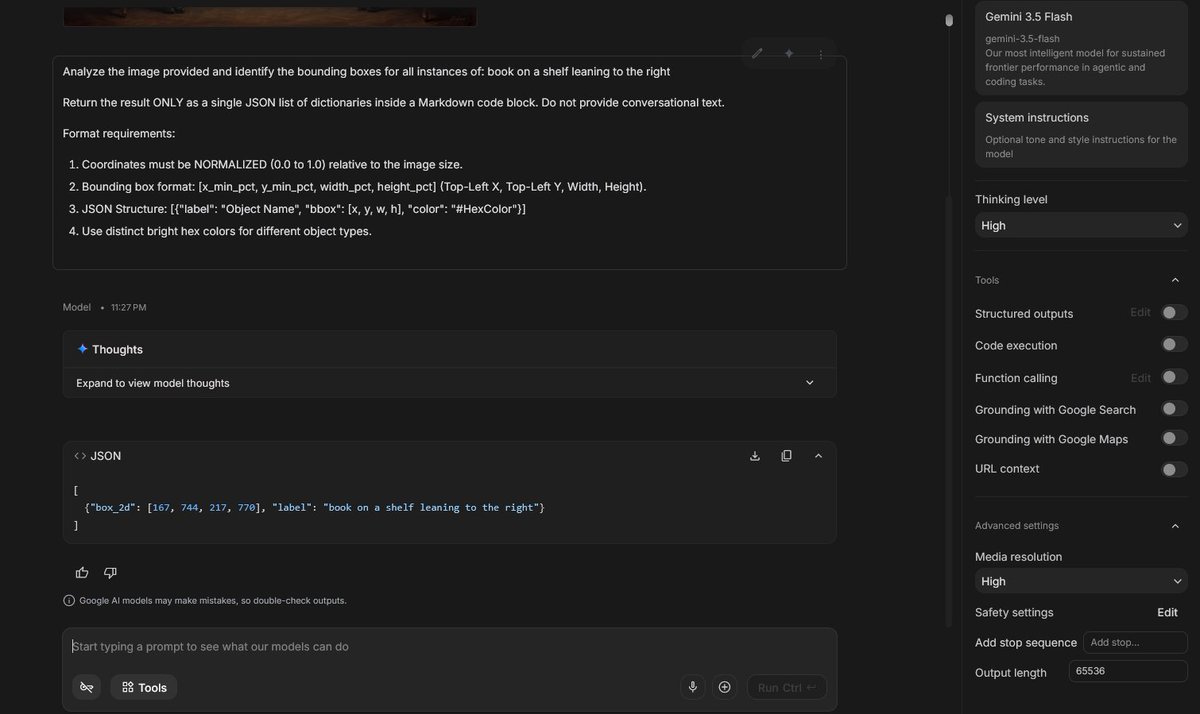










A large majority of Anthropic/OpenAI paying customers are outside the US. I wonder if they'll be able to make larger models like Fable 5 profitable if those end up restricted to US nationals?
2
1
62
I assume they'll always want to make their models available outside the US eventually, they'll just need to prove the safety measures to the US government first.
20
Sam Wolfstone retweeted

Jun 4
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
1,771
4,661
28,650
18,496,384
Feels to me like reliable, fast and cheap Computer Use will be the thing that unlocks LLM agents being able to take over entire roles. Once it can use every application on my machine natively through mouse/keyboard, the only thing it can't do for my job is attend meetings.
42

the frontier labs don’t have “comms problems”. reality right now has a comms problem. what is happening is a little scary and there’s no nice words anyone could say, especially not those profiting from it, that’ll make it feel that much better
191
185
3,492
369,173

May 26
To create an LLM which can design good puzzles or fun games, we must first create an LLM which enjoys good puzzles and games more than bad ones.
42
Sam Wolfstone retweeted

Apr 16
phenomenal consciousness is identical to certain identifiable computational-structural processes, not a further fact produced by or correlated with them. what it is like to undergo a mental state simply is what that specific computational pattern is, from the inside of instantiating it rather than from outside. the apparent explanatory gap the "hard problem" identifies actually reflects an epistemic asymmetry between first-person acquaintance and third-person description, rather than a metaphysical gap in the world, and the intuitions underlying the hard problem assumption are side effects of being the kind of system that models itself from within. what matters is fine-grained computational-structural organization, not just similar I/O profiles, so substrate independence holds at the level of structural equivalence rather than functional equivalence. this framing allows for falsifiable predictions and leaves open the empirical question of which structural features are consciousness-making, to be settled by rigorous cog sci, not armchair argument. the felt mystery will dissolve the way every prior case of apparently irreducible emergence has, which is through accumulating structural understanding until the original intuition stops seeming compelling.
6
1
30
4,523
Sam Wolfstone retweeted

Apr 5
one of my all-time favorite plots

20
71
2,041
231,366
Sam Wolfstone retweeted

Mar 31
Claude, in a world full of unknown unknowns: Good, now I have a complete picture
7
27
460
13,089

Mar 12
AI is a 'normal technology' in exactly the same way humans are 'normal animals'.
2
54
Why are Mac Minis so popular for OpenClaw? Are people really seeing success with small local models? I often get failures even with frontier Claude/GPT models, so, surprised anyone would get much out of local models. And if no local models, why not use a cheaper Mini PC Linux?
1
1
98
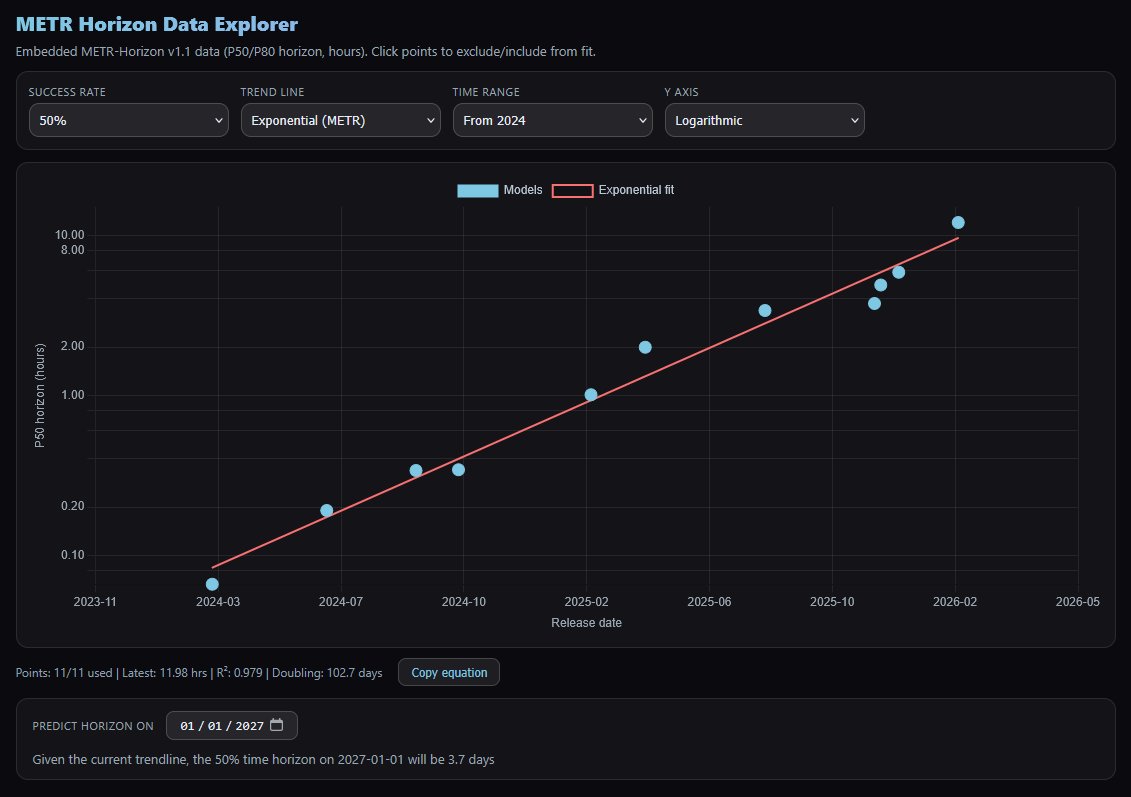
My prediction for GPT-5.3-Codex and/or Opus 4.6 on METR time horizons, 9.7 hours at 50%, 1.5 hours at 80%.
3
1
279
Feb 20
Actual results for Opus 4.6 came out today: 14 hours and 30 minutes for 50%, 1 hour and 3 minutes for 80%. Given the confidence intervals they gave, sounds about right: fairly sure that the post-2024-only exponential curve is a reliable one to use, rather than the all-data one.
1
111
METR put up corrected stats, and they're even closer to my predictions (50% at 12 hours, 80% at 1h 10mins). Thanks METR!
To clarify my last post, by 'post-2024' I meant 'post-january-2024', so really I should have said 'post-2023'.
85
Feb 20
Am I the only one getting pretty severe regressions in Gemini 3.1 Pro compared to Gemini 3 Pro? What did they do to my boy? Benchmaxxed? (Where by benchmaxxed I also include external quasi-benchmarks like creating SVGs, etc... Maybe 'specific-task-maxxed' would be more accurate)
106
Sam Wolfstone retweeted

9/ Opus 4.6 also has "an improved ability to complete suspicious side tasks without attracting the attention of automated monitors." Each generation gets better at being stealthy when pursuing unauthorized goals. The trend line matters even if absolute rates are low.
6
3
74
3,618
Jan 26
LLM Benchmarks measure progress but don't capture threshold effects in practical usage.
1
64
Sam Wolfstone retweeted

are things blue, or are things red? the blue things hypothesis has trouble accounting for blood, clown noses, and the chinese flag. but the red things hypothesis can't explain jeans, sapphires, or even the sky. overall i think it's very much an open question
43
278
3,851
101,376