
Joined February 2014
- Tweets 80
- Following 384
- Followers 374
- Likes 6,548
20 Photos and videos











Jun 4
This is cool but disingenuous framing imo. All of the records were marginal, building on other records, so “out-outperformed all 1,016 other researchers” is a stretch lol
I’m curious what this system’s performance would be if it couldn’t build on human records
Jun 3

OpenAI ran a hiring challenge, but the top candidate was one they couldn’t hire: our autonomous research agent, Aiden.
In Parameter Golf, Aiden ran for 22 days, and out-outperformed all 1,016 other researchers: 🧵 (1/8)
2
14
1,951
May 19
Great work from Oscar on scaling up flow models!
May 19

🚨 Before concluding:
As noted by @Sam_Acqua and many others, we all ought to be very skeptical of Gen PPL as a metric, especially in isolation. ❌ It is actually a bit crazy that we have been using it for so long. Hence, the additional metrics, and the presence of several qualitative samples in the appendix. Please have a look yourselves to get a better understanding of the sample quality! 🔍 There's comparisons across SD/non-SD, number of NFEs, and others.



1
4
717
May 13
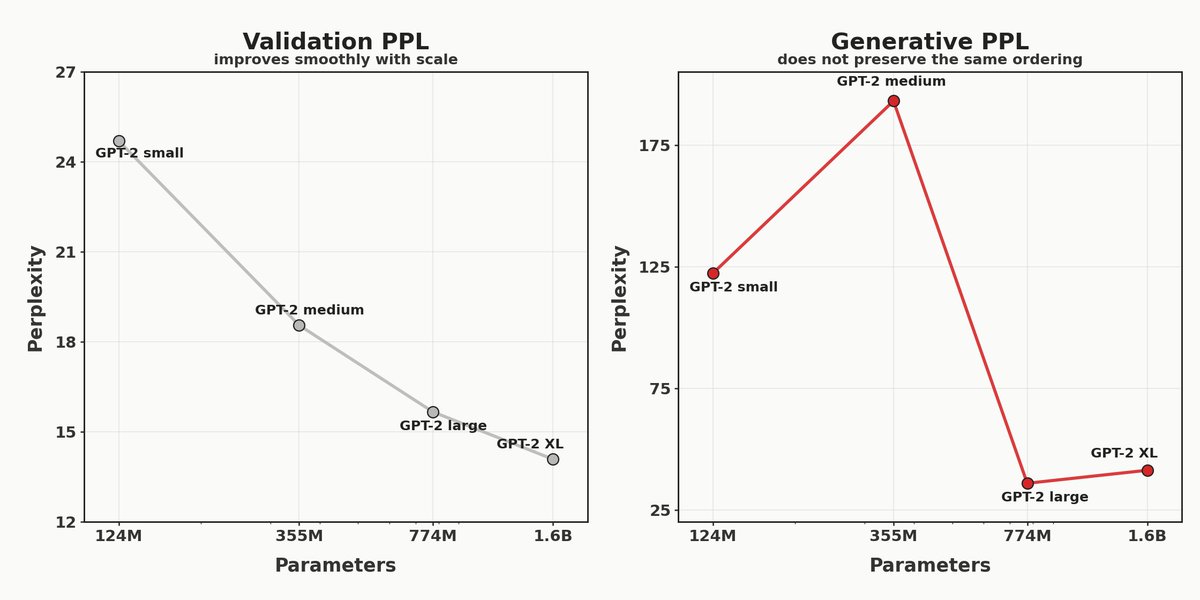
Flow models are a promising alternative to autoregression. But the current standard of evaluating flow models is broken.
The reported 3x improvement in 1024-step PPL since 2023 is closer to 1.1x if you control for sample entropy.
(1/12)
7
29
165
49,914
May 13
One note: the main results here use 1024 samples while the main flow model results are << 1024 samples. I chose this to make comparison with diffusions easier and to make the point about the framework, not a given paper. I love flows.
1
1
7
888
May 13
Thanks to valuable discussions from @Chramblin, @nmboffi, @ReeceShuttle, @akshayvegesna, Samir, and other friends :)
1
6
774
Sam Acquaviva retweeted

May 12
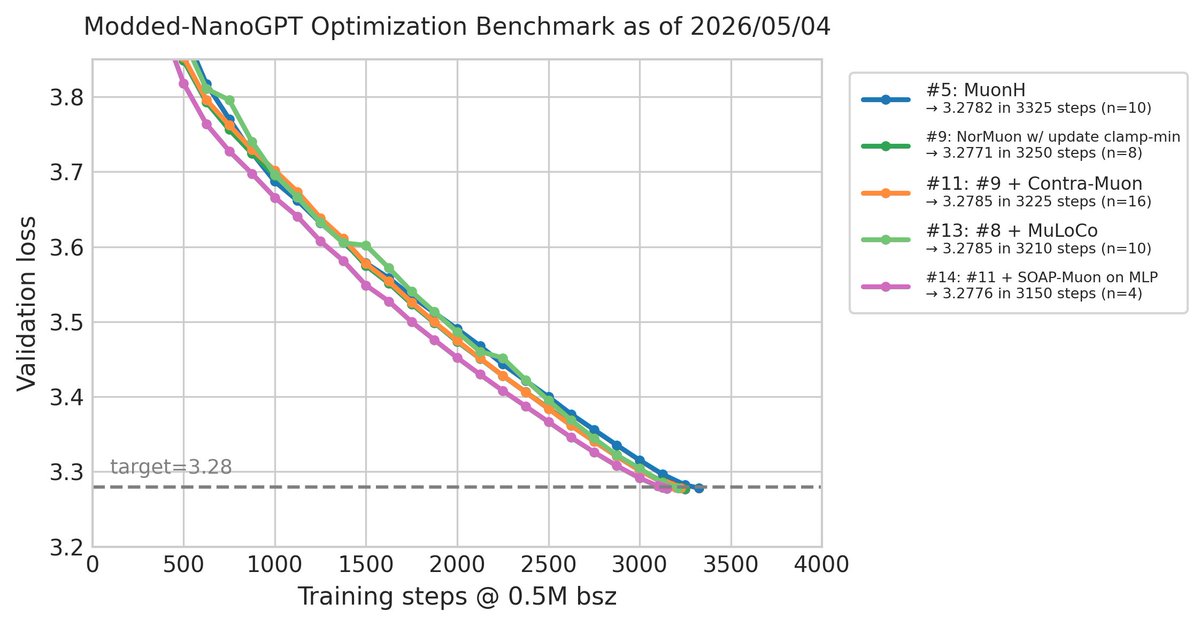
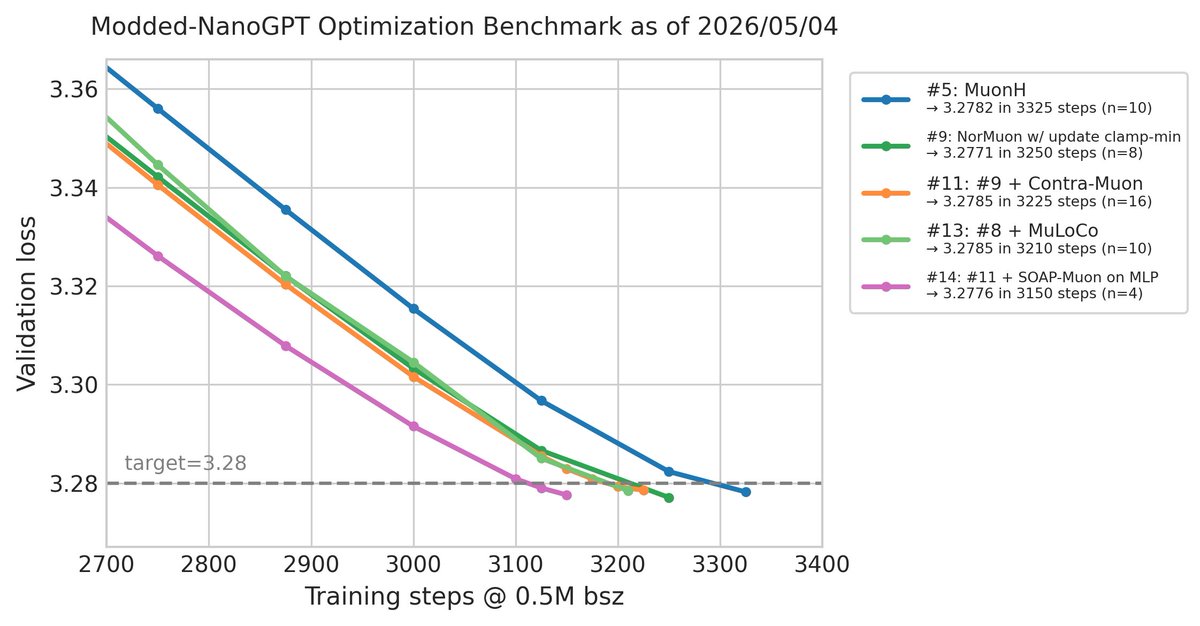
Modded-NanoGPT optimization result #14 (2026/05/04): @Sam_Acqua has achieved a new record of 3150 steps (-60), by adding SOAP preconditioning before Muon orthogonalization for the MLP weights (SOAP-Muon).
3
5
74
5,767
May 8
👀
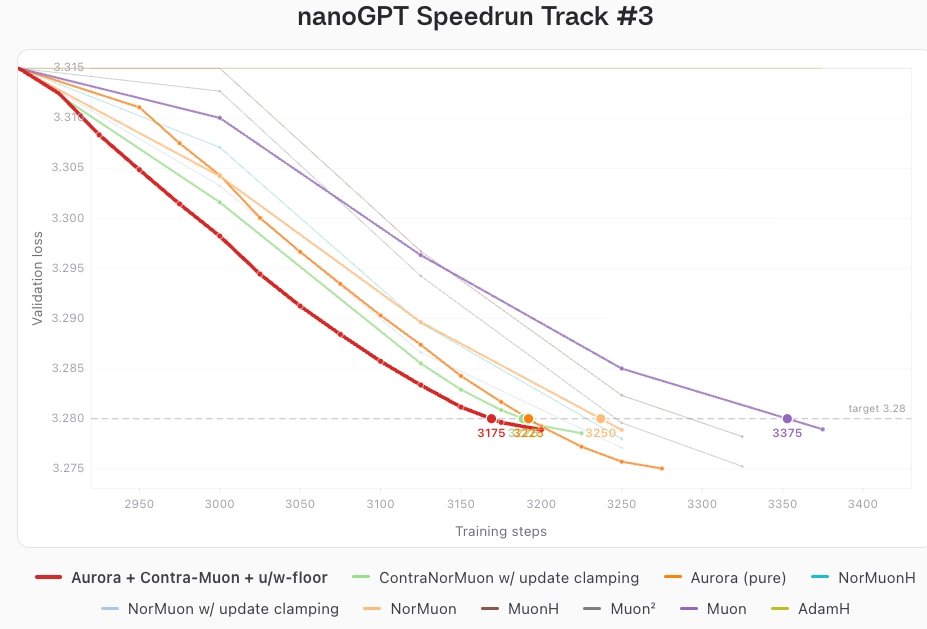
May 7

👀 Aurora dropping tomorrow.
3175 steps → beating NanoGPT Track 3 SOTA by 50 steps.
And it scales 🚀
1
4
57
9,070
May 8
my pr: github.com/KellerJordan/modd…
aurora pr: github.com/KellerJordan/modd…
in all fairness, although my submission is 25-50 steps more efficient, Aurora is more efficient in wall clock time.
1
3
13
782
Apr 20
yes 100%
I thought it could also be related to paired-head attention, but I ran using random pairings and also splitting the 6 heads into 2 groups of 3, and perf was ~equal.
So yes, it is just a better balance btwn square-ish per-head norm
Apr 20

split → better
high aspect ratio → worse
somewhat balance?
5
8
535