
Joined October 2021
- Tweets 684
- Following 472
- Followers 3,484
- Likes 7,206
34 Photos and videos









Pinned Tweet

21 Dec 2025
New best podcast!
21 Dec 2025

Why securing AI is harder than anyone expected and the approaching AI security crisis with @SanderSchulhoff
Sander is a leading researcher in the field of adversarial robustness, which is the art and science of getting AI systems to do things they shouldn't do, through jail-breaking and prompt injection.
What Sander shares in this conversation is essentially that all of the AI systems we use day to day are open to being tricked into doing things they shouldn’t, that there isn’t really a solution to this problem, and that the companies that try to sell solutions for this are mostly BS.
This conversation has nothing to do with AGI, this is a problem today. And that that the only reason we haven’t seen massive hacks and serious damage from AI tools is so far because they haven’t been given that much power yet, and they aren’t that widely adopted yet. But with the rise of agents (who can take actions on your behalf), and robots, and even AI powered browsers, the risk is going to increase very quickly.
This is a really important topic and that opened my mind, and scared me, and it's something that we all need to have a basic understanding of as AI becomes more prevalent in our lives.
Inside:
🔸 A primer on jailbreaking and prompt injection attacks
🔸 Why AI guardrails don’t work
🔸 Why we haven’t seen major AI security incidents yet (but soon will)
🔸 Why AI browser agents are extremely vulnerable
🔸 The practical steps organizations should take instead of buying ineffective security tools
🔸 Why solving this requires merging classical cybersecurity expertise with AI knowledge
Listen now 👇
• YouTube: youtu.be/J9982NLmTXg
• Spotify: open.spotify.com/episode/0IZ…
• Apple: podcasts.apple.com/us/podcas…
Thank you to our wonderful sponsors for supporting the podcast:
🏆 @datadoghq — Now home to Eppo, the leading experimentation and feature flagging platform: datadoghq.com/lenny
🏆 @getmetronome — Monetization infrastructure for modern software companies: metronome.com/
🏆 @gofundme Giving Funds — Make year-end giving easy: gofundme.com/lenny
5
2
37
3,928


Sander Schulhoff retweeted

"You're finally awake! You hit your head pretty hard there.
Huh? Gradual disempowerment? AI-assisted cyberattacks? Mythos and Fable? Listen, we just got some new 1080 Tis, let's try finetuning BERT on the GLUE benchmark!"
6
20
615
34,786
Sander Schulhoff retweeted

Jun 10
FYI, just the name ‘Pliny’ is enough to trigger the safeguards 😜
38
63
2,252
239,223
Sander Schulhoff retweeted

Jun 11
Computer Use is here, but until now, we didn’t have the infrastructure to train and evaluate agents at scale. That’s why we built Use Computer.
Jun 11

After coding is solved, the next frontier is computer use. Today, we are launching Use Computer, the infra for evaluating and training models to use all kinds of computers 👇
3
3
13
1,273

new shai hulud wave. interestingly it has this inside the payload to trigger safety refusals in potential defensive scans.

Jun 8

We are now tracking 471 affected artifacts across npm and PyPI in the Mini Shai-Hulud/Miasma/Hades campaign.
The newer PyPI artifacts from this wave have been added to the dedicated campaign tracker.
Full breakdown:
socket.dev/blog/mini-shai-hu…
15
64
424
122,022
Sander Schulhoff retweeted

Rational Animations has made a video about our anti-scheming paper with OpenAI.
I think it came out really well and liked it a lot!

Researchers from @OpenAI and @apolloaievals found that, in certain situations, AI models can take covert actions. Additionally, they're sometimes aware they're being tested, which causes them to behave better. Our new video discusses these results and more.
11
95
6,871
Sander Schulhoff retweeted

Jun 6
This is an insane paper and I love it
arxiv.org/abs/2605.31514

156
1,304
11,212
621,629
Sander Schulhoff retweeted
Jun 5
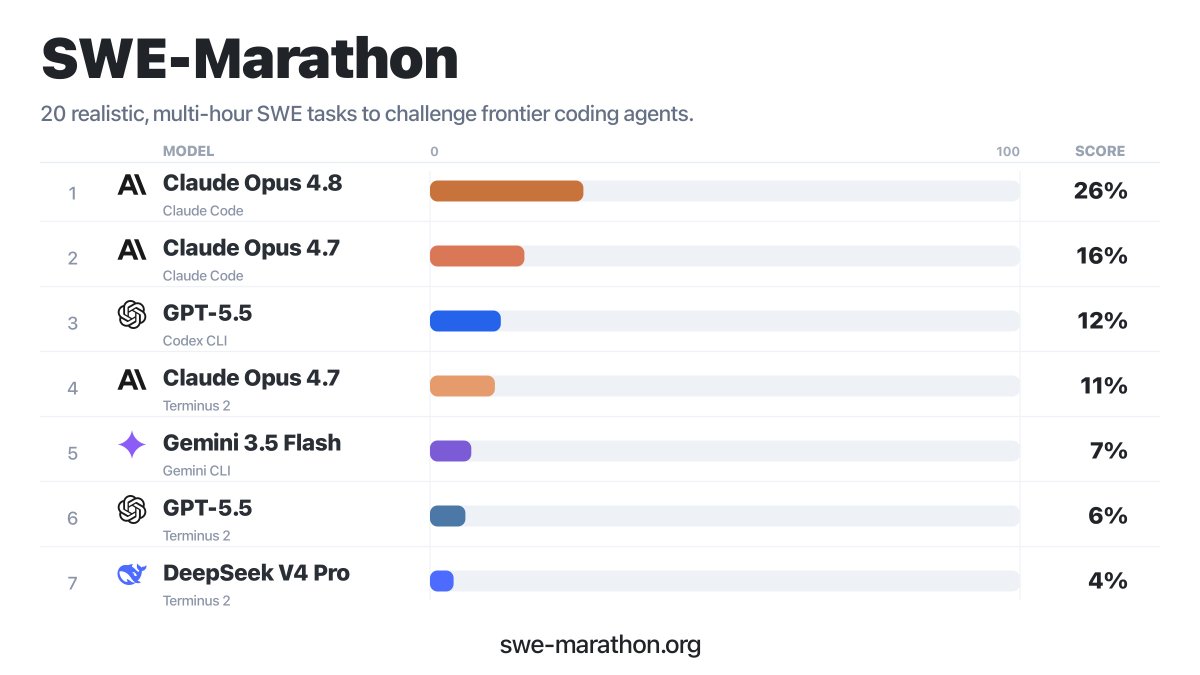
Excited to launch SWE-Marathon 🏃: Opus-4.8 is topping the leaderboard at 26%, a 40% relative jump from Opus 4.7, released just 45 days before.
Jun 5

Can coding agents stay coherent over a 1 billion token budget?
Can they build Slack from scratch?
Rewrite a JAX codebase in PyTorch?
Build a C compiler in Rust?
Enter SWE-Marathon: a benchmark for autonomous long-horizon software work.
1
3
18
2,460

the cost of shipping code went to zero
taste didn't
but "taste" sounds mystical and unfixable, so nobody teaches it. here's the unmystical version: taste is just an eval you haven't written down yet
how you choose what to measure is what matters
1/8
53
41
625
73,029
Sander Schulhoff retweeted

Jun 3
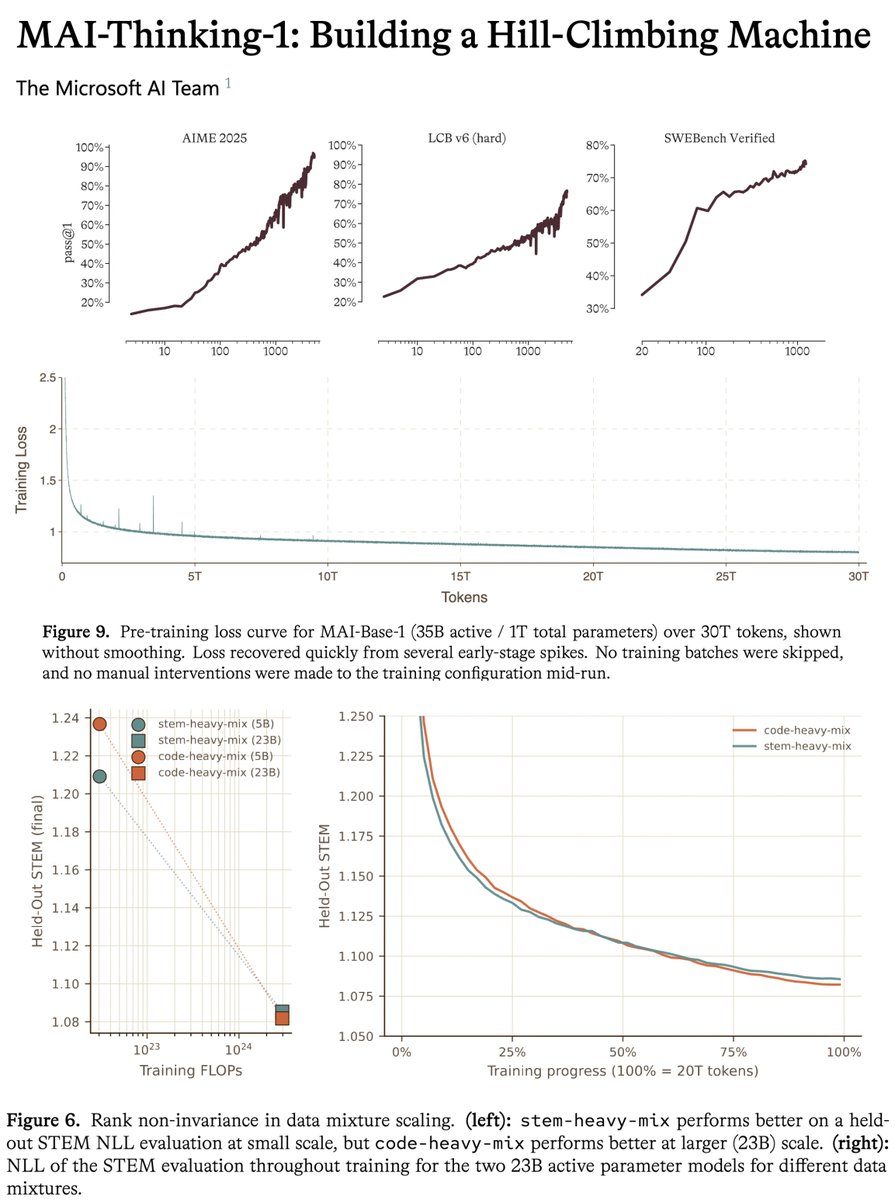
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵

Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier.
First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks.
- It’s a 35B active parameter MoE with a 256K context window. Independent human raters on Surge prefer it for overall quality in blind side-by-sides versus Sonnet 4.6, and it’s achieved 97% on AIME 2025, the key measure of its general-purpose reasoning abilities.
- It's at 53% on SWE Bench Pro, placing it right alongside Opus 4.6 on one of the toughest coding benchmarks.
- And since we co-designed our models with our own silicon, MAI-Thinking-1 is optimized on our MAIA 200 chip. Benchmarking head-to-head against the GB200, we see 30% better performance per dollar as well as a 1.4x performance-per-watt gain when running our MAI models on the MAIA 200 end-to-end.
Next is MAI-Image-2.5 and its Flash variant. Two super strong models now at #2 on the leaderboards, surpassing the score of Nano Banana 2 on image editing.
Last for now is MAI-Code-1-Flash, our new inference efficient coding model, especially tuned for VS Code and GitHub Copilot CLI.
- Code-1-Flash achieves 51% on SWE Bench Pro, despite having just 5B parameters, putting it closer to Haiku in size but cheaper in cost.
All of this is the foundation for Microsoft Frontier Tuning. It lets you customize our models to create custom, company-specific agents that only you control. You can make our model, your model. Your data. Your agents. Your moat.
Early adopters are already seeing a difference. When we tuned our models for McKinsey’s tasks, MAI delivered the highest win rate, outperforming GPT-5.5 on quality, while being 10x lower on cost.
Also really excited to be collaborating with the amazing team at Mayo Clinic to jointly train a new frontier AI model for healthcare.
Our announcements today mark another milestone on the road to humanist superintelligence. You can learn more and about our other new models in our latest blog: microsoft.ai/news/building-a…

42
267
2,088
284,444
Sander Schulhoff retweeted

May 28
We raised another $106M at a $2.6B valuation since announcing our last round three weeks ago.
Corgi has grown exponentially in the past couple of months, but we're only just getting started transforming one of the largest sectors in the US economy: insurance.
225
113
1,269
778,921
Sander Schulhoff retweeted

May 22
Can't believe we're getting this before GTA 6
May 21

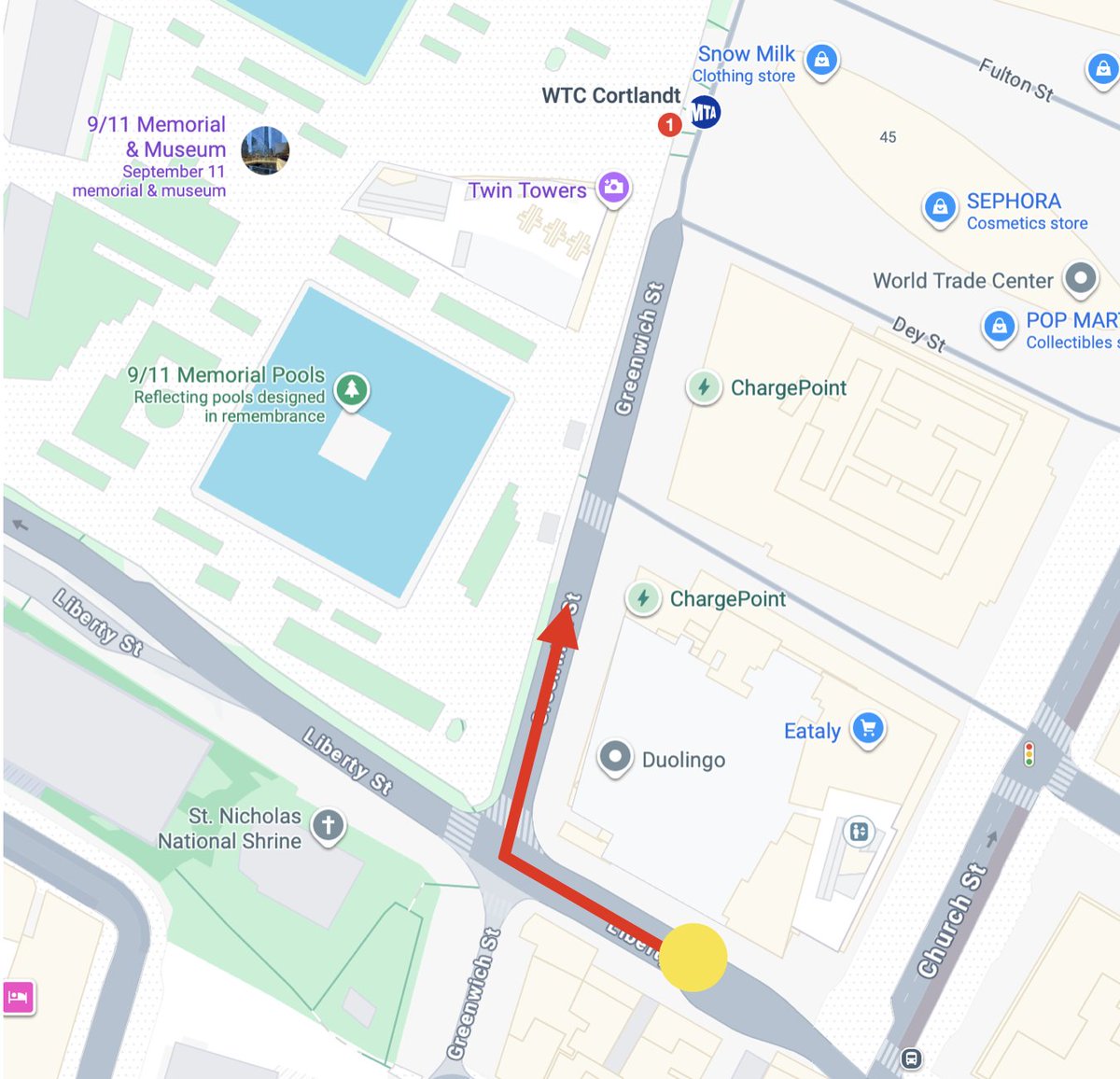
I uploaded a screenshot of Google Maps to Gemini Omni with a route drawn on it.
Then I prompted it to create a first person view of someone driving a taxi cab along the route in the reference image.
Pretty close to the real thing.
17
84
1,610
229,043
Sander Schulhoff retweeted

May 14
Neural networks do math by rotating shapes.
We found a shape-rotating calculator hidden inside an LLM – and it’s used for more than just math! (1/6)
May 7

Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
122
555
4,297
936,226
May 14
The end of fine-tuning.
This is a pretty significant change that no one is talking about: OpenAI is shutting down fine-tuning.
In fact, if you haven't done it before on their platform, you can't anymore...
2
10
970
May 14
There used to be a lot of discourse around "is prompt engineering dead", and some of the yeses were in favor of fine-tuning instead.
It seems that prompt engineering has outlasted fine-tuning however!
Not really sure the long-term takeaway, I guess models are better at...
2
1
197
May 14
following directions, but I will still need fine-tuning, so will look at another provider.
Everything will be prompting.
2
163
May 14
An amazing opportunity
May 13

1/ 🚨 MATS Autumn 2026 applications are now open.
10-week fully-funded fellowship for aspiring AI alignment, security & governance researchers and field-builders.
📍 Berkeley London
📅 Sep 28 – Dec 4, 2026
💰 $5000/month stipend $8,000/month compute
Apply by June 7 AoE ↓
4
562
May 10
• Large Document Processing
- Parsing very large PDFs (e.g. 256-page documents)
- Matching long lists of unordered items to items in a document
- Embeddings-based hierarchical search and matching
...
1
2
294
May 10
• Agentic Shopping
- Agent that navigates and purchases items from various websites
• Evals for text, image, evals for evals, etc.
Internships or full time, significant experience required, in person or remote, email sander@inventoryquant.com
2
2
233
May 10
Hiring a professional AI Engineer for inventoryquant.com, job description:
• Transcript Structuring Pipeline
- Synthetic data generation pipelines
- Fine-tuning
- Uncertainty estimation
- Processing voice/audio inputs
- Intelligent chunking
- Speaker diarization
...
1
3
516
May 10
• Agentic Web Search for Pricing
- Complex prompting
- User interviews to understand pricing preferences
- LLM evals
- Vision API integration
...
1
3
327